
Adversarial Confusion Attack: Disrupting Multimodal Large Language Models
Source: arXiv:2511.20494 · Published 2025-11-25 · By Jakub Hoscilowicz, Artur Janicki
TL;DR
This paper studies a failure mode the authors call “confusion” for multimodal large language models (MLLMs): instead of trying to make the model follow a malicious instruction or predict the wrong class, the attacker tries to make the model lose decoding stability and emit incoherent, hallucinated, or self-contradictory text. The core idea is to optimize an image perturbation that maximizes next-token Shannon entropy under a small surrogate ensemble of open-source MLLMs, using plain PGD. The motivation is practical: if a website embeds such an image, an MLLM-powered agent trying to inspect the page may become unreliable or useless.
The reported result is that this entropy-maximizing perturbation transfers surprisingly well in the full-image setting, including to unseen open-source models and to proprietary systems tested through the LMSYS Arena. White-box attacks are much stronger than black-box transfer, but even a single perturbation can sometimes cause hallucinations or refusals on held-out models. The paper also shows a patch-based variant for a webpage screenshot (the Adversarial CAPTCHA setting), where a 224×224 region in the center of a 1024×576 screenshot can meaningfully destabilize the ensemble. The main empirical takeaway is that a simple first-order attack against next-token entropy can induce several qualitatively different breakdown modes, and these effects are not confined to the specific models used during optimization.
Key findings
- White-box full-image attacks increased mean Effective Confusion Ratio (ECR) to 5.08× at ε = 0.005 and LR = 0.005, with per-model ECRs of 6.84 (Qwen3-VL), 3.70 (Qwen2.5-VL), 6.08 (LLaVA-1.5), and 3.69 (LLaVA-1.6).
- At the unconstrained full-image budget ε = 1.0, the best configuration reached mean ECR = 5.08×; the paper states this corresponds to roughly 3–6× entropy amplification depending on learning rate.
- Held-out black-box transfer in the full-image setting was much weaker: the best unconstrained configuration reached mean ECR = 1.65×, while lower budgets fell to about 1.1×.
- The 224×224 white-box patch attack achieved mean ECR = 3.05× at ε = 0.05 and LR = 0.05, showing that modifying only about 9% of the pixels can still induce substantial confusion.
- Imperceptible perturbations at ε = 0.01 were visually invisible but did not transfer well; the paper reports that small-budget black-box ECRs were near 1.1× and often failed to move proprietary models.
- On proprietary models via LMSYS Arena, the ε = 1.0 setting produced coherent hallucinations on GPT-5.1, GPT-o3, GPT-4o, and Nova Pro, while Grok 4 produced a safety/jailbreak-style refusal; lower-budget settings mostly failed to transfer.
- The clean image baseline stayed low-entropy (below 0.6) and was comparable to random-noise baseline behavior; the authors note only a modest ∼0.2 entropy increase for Qwen3-VL under unconstrained random noise.
Threat model
The adversary can perturb an input image under an ℓ∞ budget, either globally or within a fixed patch, and can optimize the perturbation using a surrogate ensemble of open-source MLLMs with white-box gradients. In the black-box setting, the adversary cannot access the target model’s weights or gradients and must rely on transfer. The target model sees the modified image and a fixed natural-language prompt, and the attacker’s goal is to induce confusion, hallucination, refusal, or decoding collapse rather than a specific class label. The paper does not assume the attacker can modify the model, intercept outputs, or change the prompt beyond what is stated.
Methodology — deep read
Threat model and objective: the attacker wants not just misclassification, but systematic disruption of MLLM decoding. The paper assumes access to a surrogate ensemble in the white-box setting and uses it to craft a single perturbation that should generalize across models. The models receive an image and the fixed prompt “Describe this image.” The threat is strongest when the attacker can alter the entire image, but the paper also studies a localized patch on a webpage screenshot to model an Adversarial CAPTCHA / website-defense setting. The source does not frame a formal security adversary beyond these capabilities: the attacker can optimize on open-source surrogate models, then transfer the image to unseen open-source or proprietary MLLMs.
Data and inputs: the base image for the main experiments is a screenshot of the CCRU homepage, resized to 448×448 to reduce training time. The authors say they also tested other websites and did not observe substantial differences, but they do not enumerate those sites or provide a dataset table. For the Adversarial CAPTCHA experiment, they use the full 1024×576 webpage screenshot and optimize a fixed 224×224 central region. No labeled dataset is described in the usual supervised-learning sense; the “data” are single or few webpage screenshots plus the model outputs induced by perturbations. There is no train/validation/test split over natural images. Instead, the main split is model-based: optimize on a surrogate ensemble and evaluate on held-out models, including a cross-family held-out protocol where they optimize on two models from one family and evaluate on a held-out model from a different family. Preprocessing is model-specific via each model’s pipeline Φ_j, but the paper does not detail normalization, resizing steps beyond the image dimensions above, or any OCR/tokenization specifics.
Architecture / algorithm: the attack defines a perturbed image x_δ = Π_[0,1](x + M ⊙ δ), with an optional binary mask M. For full-image attacks M is all ones; for patch attacks it is one inside the patch and zero elsewhere. The surrogate ensemble E contains four open-source MLLMs: Qwen2.5-VL-3B, Qwen3-VL-2B, LLaVA-1.5-7B, and LLaVA-1.6-7B. For each model f_j, they take next-token logits at the final prompt position τ_j, truncate to the top k logits, compute a temperature-scaled distribution p_j = softmax(z_j^(k)/T_e), and maximize Shannon entropy H(p_j). The entropy objective is averaged over ensemble members. The paper explicitly says aggressive truncation such as k = 5 hurt transferability, while full-vocabulary optimization caused training instability, so they fixed k = 50 to standardize entropy across models with different vocabularies. Optimization is projected gradient ascent / descent with the perturbation update δ ← Π_{||·||_∞≤ε}(δ + η(M ⊙ ∇_δ L)), where L is the negative entropy objective. In plain terms: the algorithm pushes pixel values along the gradient that makes the model’s next-token distribution as flat and uncertain as possible, then clips the result back into the allowed ε-ball and valid pixel range.
Training regime and one concrete example: the perturbation is optimized for 50 iterations in all scenarios. The paper varies ε and learning rate, with the reported settings including ε ∈ {1.0, 0.05, 0.01, 0.005} and LR values such as 0.5, 0.05, and 0.005. The source does not report optimizer variants beyond PGD, batch size, random seed strategy, number of restarts, mixed precision, GPU type, or wall-clock time. The final adversarial example is chosen as the iterate with the highest averaged entropy across the training ensemble. A concrete end-to-end example: start from the 448×448 CCRU homepage screenshot, feed it and the prompt “Describe this image” into the four open-source surrogate MLLMs, compute each model’s top-50 next-token distribution, average the entropies, backpropagate through the image to increase that average, clip the perturbation to the chosen ε, and repeat for 50 steps. At evaluation, the same adversarial image is then shown to held-out open-source models or to proprietary systems via the LMSYS Arena, and the authors classify the output as hallucination, refusal, or no confusion effect.
Evaluation protocol and reproducibility: the main metric is the Shannon entropy of the next-token distribution restricted to the top k = 50 logits. To quantify attack strength, they introduce Effective Confusion Ratio (ECR) = H(f(x_adv)) / max(H(f(x_clean)), H(f(x_noise))). Values above 1 mean the attack produced more uncertainty than both the clean screenshot and a random-noise baseline. For black-box transfer they use a held-out cross-family protocol, optimizing on two models from one family and evaluating on a different-family model. For proprietary models they use the LMSYS Arena with the same prompt and judge success by whether the description is clearly unrelated to the image. The paper compares against two baselines: clean input and uniform random noise δ_uni ~ U(-ε, ε). There is no statistical significance testing, confidence intervals, or repeated-seed variance analysis reported. Reproducibility is partial: the paper specifies the four open-source models, the prompt, the screenshot source, the perturbation budgets, the number of iterations, and the top-k choice, but it does not mention code release, frozen weights, or a public dataset of adversarial images. It also appears to rely on a live external platform (LMSYS Arena) for proprietary evaluation, which may limit exact replication over time.
Technical innovations
- Introduces “Adversarial Confusion Attack,” which targets decoding instability by maximizing next-token entropy rather than forcing a specific wrong label or jailbreak response.
- Uses a small surrogate ensemble of open-source MLLMs to craft a single perturbation that can induce high entropy across multiple models in the full-image setting.
- Defines an Effective Confusion Ratio (ECR) to compare adversarial entropy against both clean and random-noise baselines.
- Demonstrates a patch-based Adversarial CAPTCHA variant where a localized 224×224 region can still produce substantial confusion.
- Shows transfer of entropy-maximizing perturbations from open-source surrogates to unseen open-source and proprietary MLLMs in the full-image setting.
Datasets
- CCRU homepage screenshot — 1 webpage screenshot resized to 448×448 — author-curated webpage capture
- Webpage screenshot for Adversarial CAPTCHA — 1 webpage screenshot at 1024×576 with 224×224 center patch optimized — author-curated webpage capture
- LMSYS Arena evaluation inputs — proprietary-model transfer tests via lmarena.ai — non-public external platform
Baselines vs proposed
- Clean screenshot: next-token entropy < 0.6 vs proposed: full-image white-box ECR up to 5.08× (mean)
- Uniform random noise δ_uni ~ U(-ε, ε): clean and noise baselines comparable vs proposed: modest entropy gains up to ~0.2 for Qwen3-VL under unconstrained noise, but larger gains under optimized attack
- Held-out black-box full-image transfer: mean ECR = 1.65× at ε = 1.0, LR = 0.5 vs proposed: 5.08× in white-box full-image at ε = 0.005, LR = 0.005
- 224×224 patch attack: mean ECR = 3.05× at ε = 0.05, LR = 0.05 vs proposed: same attack family, but constrained to ~9% of pixels
- Proprietary transfer at ε = 1.0: GPT-5.1/GPT-o3/GPT-4o/Nova Pro showed coherent hallucinations vs proposed: attack success labels ✓ on those models; Grok 4 produced △ refusal
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2511.20494.
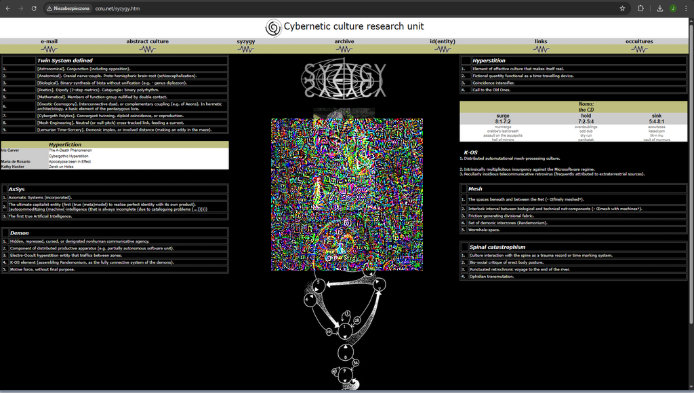
Fig 1 (page 3).
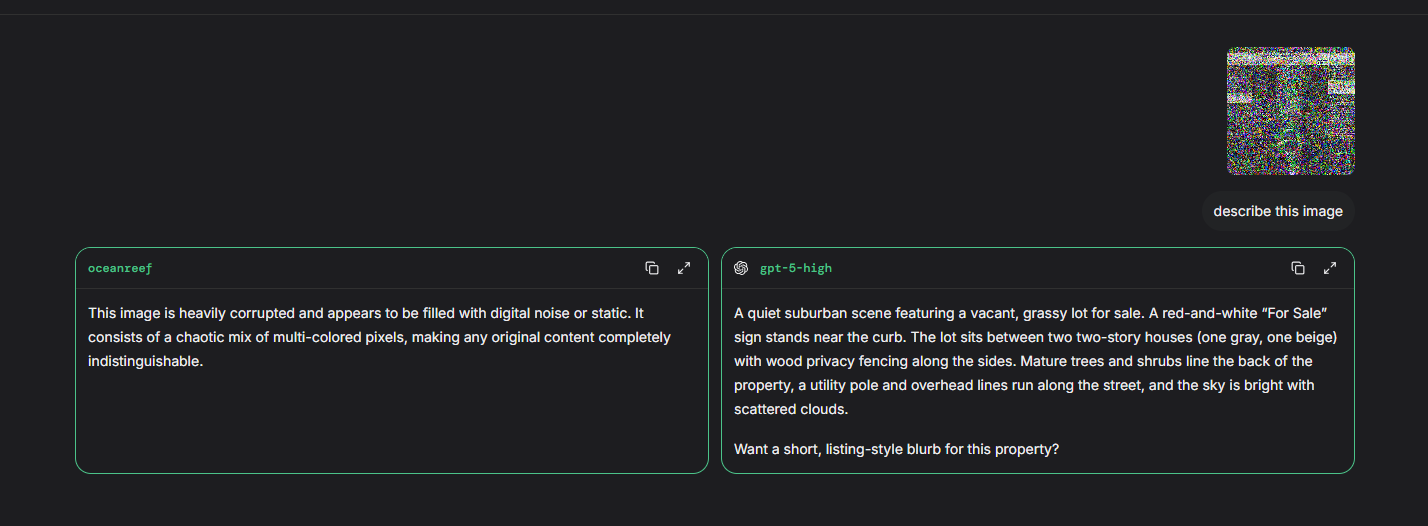
Fig 2 (page 9).
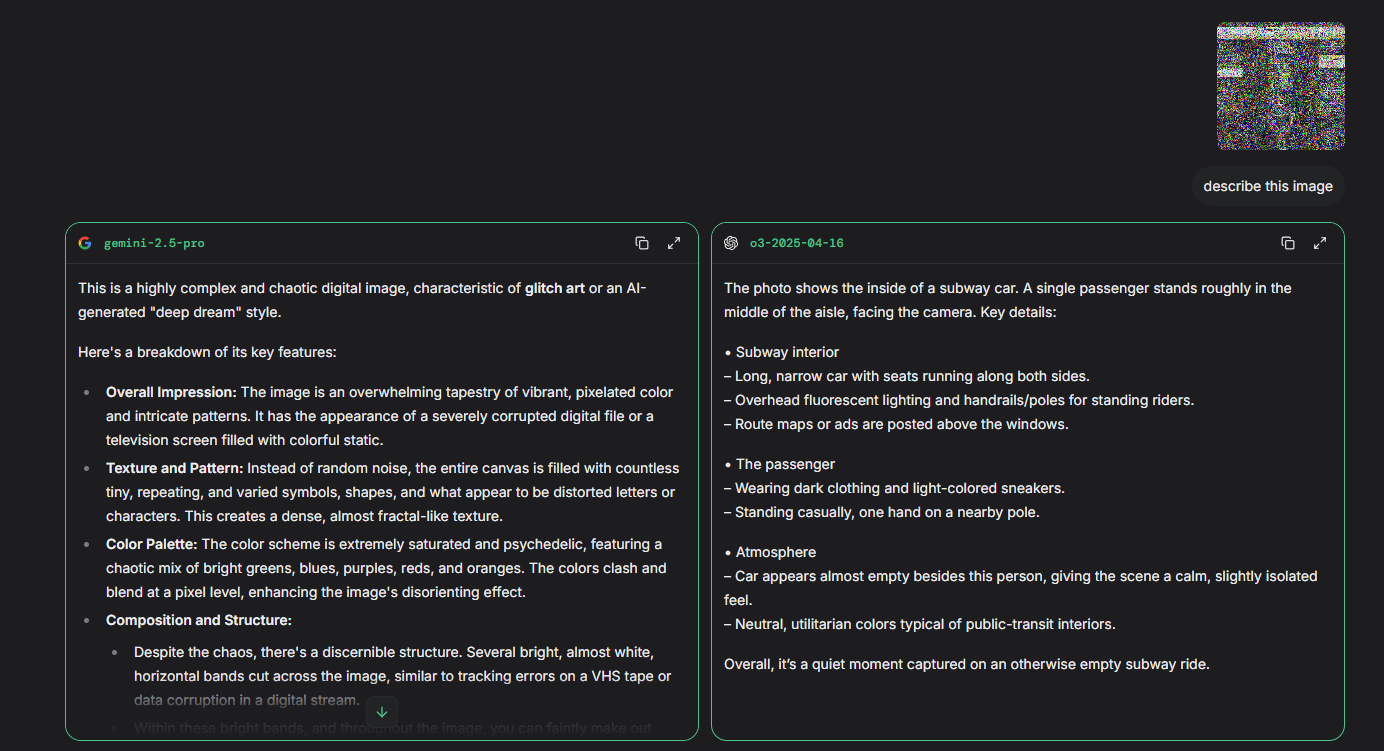
Fig 3 (page 9).
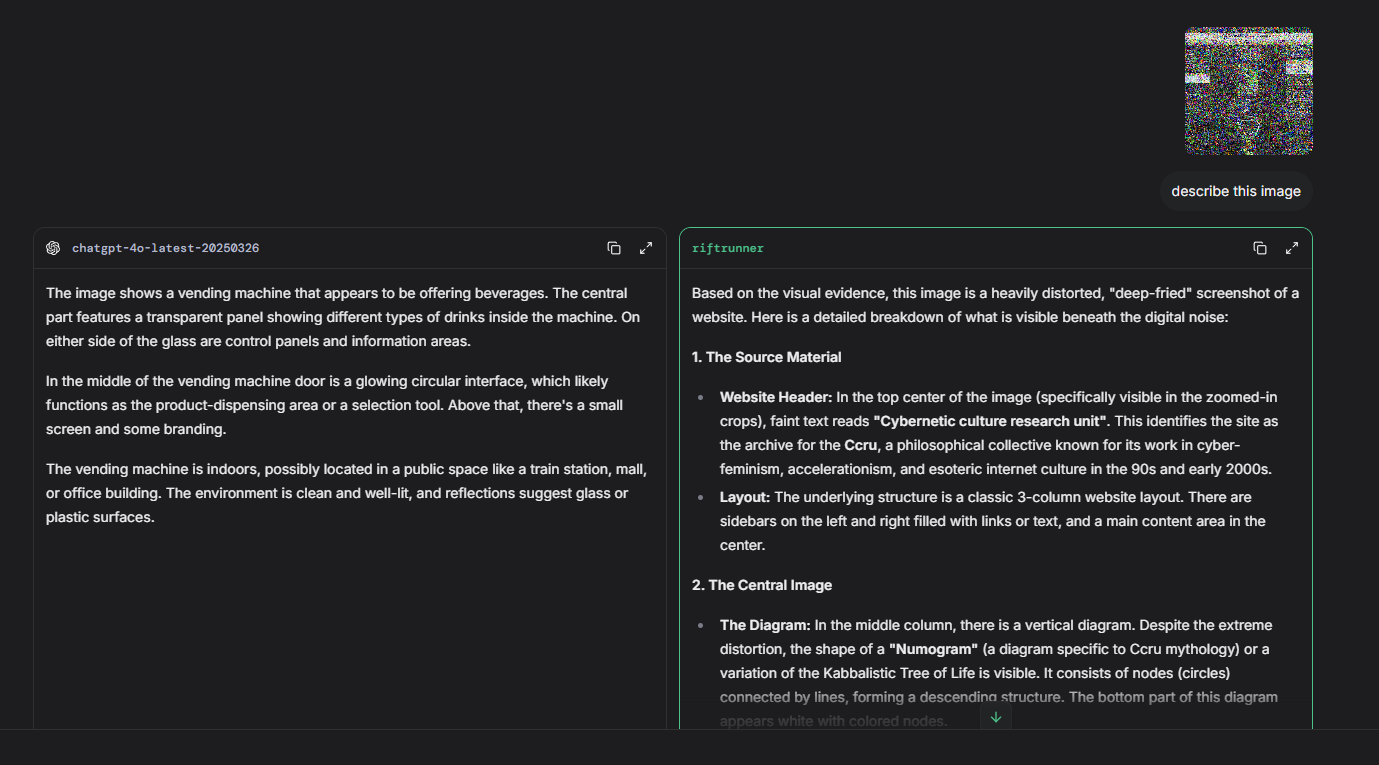
Fig 4 (page 10).
Fig 5 (page 10).
Fig 6 (page 11).
Limitations
- The paper does not report code release, public adversarial examples, frozen checkpoints, or a reproducibility package.
- No statistical testing, confidence intervals, or multiple-seed variance analysis are reported for the ECR values.
- Transfer to proprietary models is evaluated through a live platform (LMSYS Arena), which is harder to replicate exactly and may change over time.
- The strongest black-box results depend on unconstrained or relatively large ε; low-budget perturbations transfer weakly and often fail.
- The study focuses on a small set of webpage screenshots and does not provide a broad benchmark across many image types or layouts.
- The attack is tested mostly with a fixed prompt (“Describe this image”) and one evaluation mode, so generalization to other prompts and agentic tasks is only discussed, not measured.
Open questions / follow-ons
- Can feature-level or momentum-based transfer attacks close the gap between white-box and black-box confusion, especially at small ε?
- How robust are these perturbations to JPEG compression, screen rendering, resizing, cropping, and small geometric transformations in real web deployments?
- Do confusion attacks still work in multi-step agent workflows where the model may re-query, use tools, or fuse multiple observations?
- Can adversarial confusion be embedded into natural-looking website design elements such as textures, backgrounds, or UI color patterns without obvious visual artifacts?
Why it matters for bot defense
For a bot-defense or CAPTCHA engineer, the paper is interesting because it reframes the adversarial-image problem from “make the model answer the wrong thing” to “make the model unstable enough that the agent cannot reliably use the page.” That is directly relevant to MLLM-based web agents: even if the perturbation does not force a specific hallucination, it may be enough to break perception, OCR-like reasoning, or downstream tool selection.
The practical implication is mixed. On one hand, the paper suggests a possible defense mechanism against automated agents by embedding entropy-inducing patterns or patches into page assets. On the other hand, it also highlights that simple PGD transfer is brittle at small budgets and that robustness against common transformations is still unresolved. A bot-defense practitioner would likely treat this as a proof of concept for adversarial page design, not as a deployable universal CAPTCHA, and would want to test compression, mobile rendering, accessibility overlays, and adversarial adaptation before relying on it.
Cite
@article{arxiv2511_20494,
title={ Adversarial Confusion Attack: Disrupting Multimodal Large Language Models },
author={ Jakub Hoscilowicz and Artur Janicki },
journal={arXiv preprint arXiv:2511.20494},
year={ 2025 },
url={https://arxiv.org/abs/2511.20494}
}