
Multimodal Wireless Foundation Models
Source: arXiv:2511.15162 · Published 2025-11-19 · By Ahmed Aboulfotouh, Hatem Abou-Zeid
TL;DR
This paper tackles a concrete limitation in wireless foundation models: most prior WFMs are modality-specific, even though wireless systems expose multiple views of the same propagation event, including raw IQ streams and image-like representations such as spectrograms and CSI. The authors argue that the “best” modality depends on the task and operating condition, so a single-modality foundation model leaves performance on the table and limits robustness. Their main contribution is a multimodal WFM that can ingest both raw IQ and image-like wireless inputs through a shared ViT backbone with modality-specific front ends.
What is new is not just a multi-input encoder, but a masked autoencoding pretraining recipe adapted to this wireless setting (“masked wireless modeling”). They pretrain the shared encoder on two unlabeled pools, one spectrogram-based and one IQ-based, then evaluate transfer on five downstream tasks spanning both modality families: RF fingerprinting, interference detection/classification, human activity sensing, RF signal classification, and 5G NR positioning. The reported result is that the multimodal model is competitive with single-modality WFMs and, on several IQ-centric tasks, exceeds the IQ baseline; with LoRA fine-tuning it improves further on four of five tasks while keeping the backbone shared.
Key findings
- Pretraining uses 800 epochs with a 40-epoch linear warm-up, Adam at learning rate 1e-3, cosine annealing, and a fixed 70% mask ratio for both modalities.
- The multimodal WFM is pretrained on two unlabeled datasets of equal size: 3200 spectrogram samples and 3200 IQ samples.
- Under linear probing, the multimodal WFM reaches 98.65% on RF fingerprinting and 96.40% on interference detection, compared with IQFM at 91.41% and 95.00%, respectively.
- Under linear probing, the multimodal WFM is competitive on image-like tasks but not universally better: on RF signal classification it gets 63.59% versus WavesFM at 68.10%, and on 5G NR positioning it gets 2.11 versus 3.90 mean localization error.
- Under FT2 (partial fine-tuning of 2 blocks), the multimodal WFM improves RF fingerprinting to 99.69% and interference detection to 98.74%, while RF signal classification rises to 84.14% from 63.59% under LP.
- LoRA with rank R=32 and alpha=32 uses about 0.3M task-specific parameters versus about 1.65M for FT2, and improves 4 of 5 tasks over FT2 (e.g., RF signal classification 84.14% -> 89.41%).
- The paper explicitly states the multimodal WFM has about 7M total parameters, while IQFM is about 0.3M and WavesFM is about five times larger than the multimodal WFM.
- The authors claim the model maintains strong and balanced performance across both modality families, but also note that WavesFM likely benefits from larger and more diverse pretraining data (spectrograms plus CSI) and higher parameter count.
Methodology — deep read
Threat model and problem setting: the paper is not a security paper in the adversarial sense, but it does define a wireless representation-learning setting where the same physical transmission can be observed through different modalities. The implicit assumption is that the foundation model should support downstream tasks on labeled data after self-supervised pretraining on unlabeled pools. There is no explicit attacker model, no adversarial perturbation analysis, and no assumption of malicious data poisoning or evasion beyond the general need for robustness across tasks and operating conditions.
Data and provenance: pretraining uses two datasets, each with 3200 samples. The image-like dataset is a spectrogram corpus containing signals from WiFi, LTE, Bluetooth, 5G-NR, and ISM bands, collected over the air using SDRs at sub-6 GHz center frequencies and 10–60 MHz sampling rates, then converted to spectrograms using the method from [1]. The IQ dataset is a 4-antenna MIMO indoor testbed with baseband recordings under various modulation/technology and antenna/location configurations, described by reference [7]. Preprocessing differs by modality: spectrograms are mapped to log scale, normalized to [0,1] with dataset-wide statistics, resized to 224x224, then standardized; IQ is standardized on its in-phase and quadrature components using dataset-wide statistics. Downstream evaluation spans five tasks: RF fingerprinting on LTE/5G-NR IQ traces from four base stations [12], interference detection/classification on LTE IQ with DSSS interference [13], human activity sensing on Wi-Fi CSI from two APs with three antennas each [14], RF signal classification on spectrograms with 20 classes [15], and 5G NR positioning from CSI sounding reference signals [16]. The paper does not report train/val/test sample counts, class balancing, or whether splits are subject-disjoint, transmitter-disjoint, or location-disjoint beyond the task descriptions.
Architecture and algorithm: the model is a masked autoencoder with a shared ViT encoder/decoder backbone, adapted to two very different input families through modality-specific tokenization. For image-like inputs, the model splits the CxHxW tensor into P x P flattened patches (patch size 16x16 in Table I), then linearly projects each patch into the encoder embedding dimension. For IQ, the complex time series over M antennas and T samples is segmented into fixed-length segments of length S (S=16 in Table I), linearly projected, and then given a modality-specific feature-wise affine transform (separate gamma/beta for IQ and image-like streams). After that, the image-like modality receives 2D sinusoidal positional embeddings; IQ receives 1D sinusoidal temporal embeddings plus learned antenna embeddings that explicitly encode the source antenna for each token. The novelty here is that the shared encoder is intended to learn a common latent space while still preserving modality-specific structure via lightweight front-end conditioning. The decoder is asymmetric and used only during pretraining; it reconstructs masked patches/segments through separate output projection heads for each modality. The self-supervised objective is mean squared error on masked tokens only, computed separately for image-like and IQ inputs and summed. Algorithm 1 alternates paired mini-batches from the two datasets, computes both modality losses, averages them, and updates the shared model.
Training regime and concrete example: pretraining runs for 800 epochs with a 40-epoch warm-up, Adam optimizer at 1e-3, cosine annealing, and a fixed 70% masking ratio for both modalities. The model configuration in Table I is a 6.32M-parameter ViT encoder with 8 blocks, embed dim 256, hidden dim 1024, and 8 attention heads; the decoder has 4 blocks, embed dim 128, hidden dim 512, 16 heads, and 0.79M parameters. Sampling alternates strictly between modalities: one step is taken only after processing a minibatch from each modality, and the gradients are aggregated. For a concrete end-to-end example, an IQ sample from the 4-antenna dataset is segmented into 16-length chunks, projected into tokens, augmented with antenna identity and temporal position, masked at 70%, passed through the shared encoder/decoder, and reconstructed only on masked segments using MSE. The same pipeline is applied to a spectrogram sample, except that patchification and 2D spatial positional encoding are used instead of antenna embeddings.
Evaluation protocol and reproducibility: downstream tasks are evaluated under three adaptation regimes—linear probing, partial fine-tuning of the last 2 ViT blocks (FT2), and LoRA. Linear probing freezes the encoder end-to-end and trains only the task head plus modality-specific input projections; FT2 unfreezes the last two transformer blocks while keeping earlier blocks frozen; LoRA inserts low-rank adapters into query and value projections of each encoder block, with the original encoder frozen. The paper reports mean per-class accuracy for classification tasks and mean localization error for positioning. Baselines are modality-specific WFMs: WavesFM for image-like tasks and IQFM for IQ tasks. Results are summarized in Tables II and III; no statistical significance tests, confidence intervals, or multiple-seed averages are reported in the excerpt. Reproducibility is relatively strong for this area: the authors say model weights, fine-tuning code, and instructions are available at wavesfm.waveslab.ai, but the pretraining datasets themselves appear to be assembled from prior sources and are not fully described as public or frozen here.
Technical innovations
- A single ViT backbone is adapted to both raw IQ and image-like wireless inputs using modality-specific patch/segment embeddings, affine conditioning, and antenna embeddings for multi-antenna IQ.
- The paper introduces masked wireless modeling for the multimodal case, extending MAE-style reconstruction to jointly pretrain on IQ streams and spectrogram/CSI-like inputs.
- The encoder is trained to support multiple downstream wireless tasks with one shared representation while keeping task adaptation lightweight via linear heads, partial fine-tuning, or LoRA.
- The work provides an empirical argument that directly masking and reconstructing raw IQ streams yields transferable features for unseen IQ-centric tasks, not just image-like wireless modalities.
Datasets
- Spectrogram dataset — 3200 samples — collected over the air with SDRs across WiFi, LTE, Bluetooth, 5G-NR, and ISM bands; converted to spectrograms
- IQ dataset — 3200 samples — 4-antenna indoor MIMO testbed IQ recordings (source described in [7])
- RF Fingerprinting (RFP) — not specified in excerpt — LTE and 5G-NR IQ traces from four base stations [12]
- Interference Detection/Classif. (INTD/INTC) — not specified in excerpt — LTE IQ recordings with DSSS interference [13]
- Human Activity Sensing (HAS) — not specified in excerpt — Wi-Fi CSI from two APs with three antennas each [14]
- RF Signal Classification (RFS) — not specified in excerpt — CommRad RF spectrogram dataset with 20 classes [15]
- 5G NR Positioning (POS) — not specified in excerpt — CSI sounding-reference-signal dataset [16]
Baselines vs proposed
- IQFM (LP): RFP accuracy = 91.41% vs proposed = 98.65%
- IQFM (LP): INTD accuracy = 95.00% vs proposed = 96.40%
- IQFM (LP): INTC accuracy = 61.72% vs proposed = 58.25%
- WavesFM (LP): HAS accuracy = 97.7% vs proposed = 95.58%
- WavesFM (LP): RFS accuracy = 68.10% vs proposed = 63.59%
- WavesFM (LP): POS mean localization error = 3.90 vs proposed = 2.11
- IQFM/WavesFM (FT2): RFP accuracy = 96.47% vs proposed = 99.69%
- IQFM/WavesFM (FT2): INTD accuracy = 96.40% vs proposed = 98.74%
- IQFM/WavesFM (FT2): INTC accuracy = 62.24% vs proposed = 64.15%
- IQFM/WavesFM (FT2): HAS accuracy = 98.86% vs proposed = 98.73%
- IQFM/WavesFM (FT2): RFS accuracy = 86.05% vs proposed = 84.14%
- IQFM/WavesFM (FT2): POS mean localization error = 0.41 vs proposed = 1.27
- FT2 -> LoRA (proposed model): RFP accuracy = 99.69% vs 99.77%
- FT2 -> LoRA (proposed model): INTD accuracy = 98.74% vs 99.60%
- FT2 -> LoRA (proposed model): INTC accuracy = 64.15% vs 66.93%
- FT2 -> LoRA (proposed model): HAS accuracy = 98.73% vs 98.10%
- FT2 -> LoRA (proposed model): RFS accuracy = 84.14% vs 89.41%
- FT2 -> LoRA (proposed model): POS mean localization error = 1.27 vs 1.06
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2511.15162.
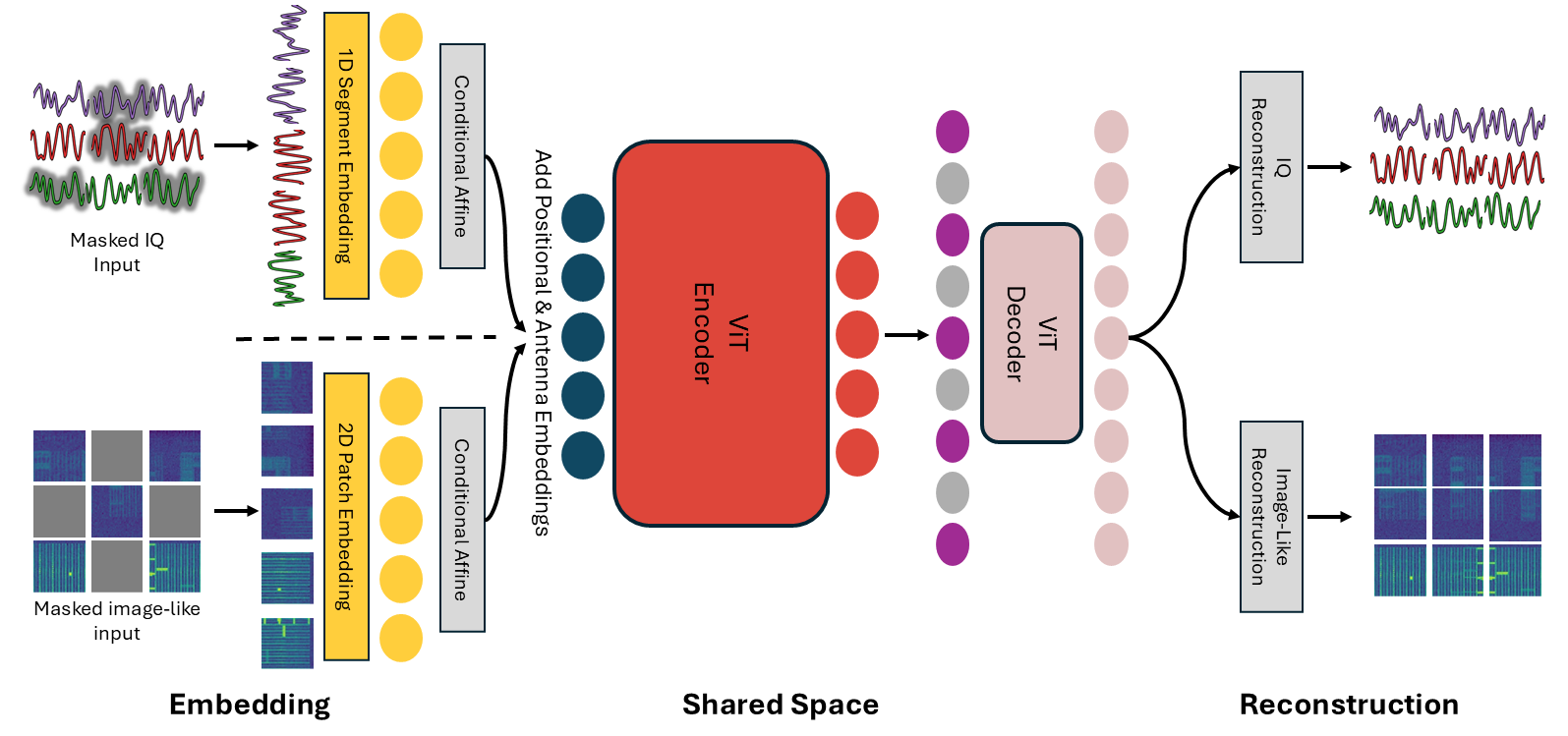
Fig 1: The Proposed Multimodal Wireless Foundation Model.
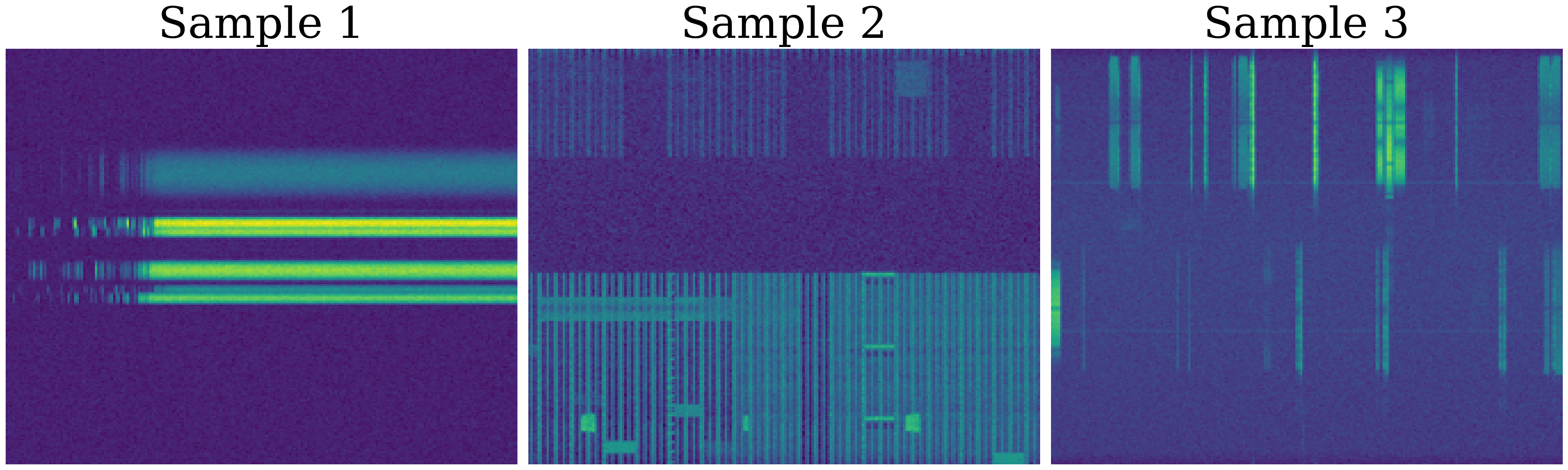
Fig 2: Pretraining Datasets.
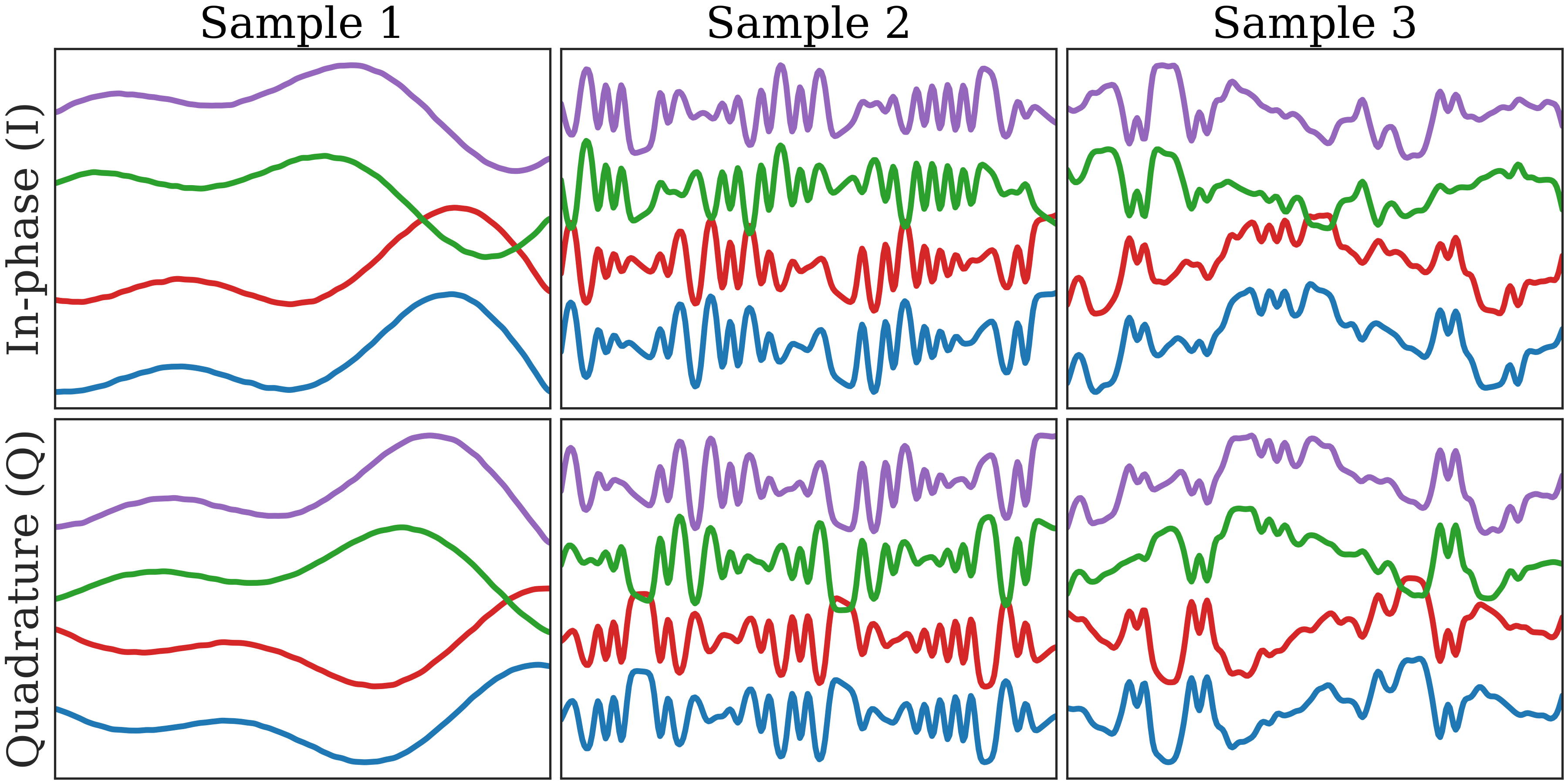
Fig 3: Reconstruction examples at different masking ratios.
Fig 4 (page 5).
Limitations
- The pretraining corpora are small by foundation-model standards: only 3200 spectrogram samples and 3200 IQ samples.
- The excerpt does not report multi-seed variance, confidence intervals, or significance testing, so the robustness of the numeric gaps is unclear.
- There is no explicit adversarial evaluation, distribution-shift benchmark, or held-out attacker model; claims about robustness are indirect.
- The image-like pretraining corpus appears to omit CSI, even though CSI is included in downstream tasks and in the motivation; the authors themselves suggest adding CSI would likely improve results.
- Some baselines differ substantially in parameter count: the multimodal model is about 7M parameters, IQFM is about 0.3M, and WavesFM is about five times larger, so raw performance gaps are partly confounded by scale.
- The paper does not provide full dataset split details for the downstream tasks, making it hard to assess leakage risks or exact comparability with prior work.
Open questions / follow-ons
- Would joint pretraining on spectrograms, CSI, and raw IQ produce a single backbone that closes the remaining gaps on image-like tasks without hurting IQ performance?
- How well does the shared representation transfer under domain shift, such as different hardware, channel conditions, bandwidths, or unseen interference types?
- Can modality dropout or missing-modality training make the model robust when only one wireless view is available at deployment time?
- Would explicit cross-modal prediction objectives outperform the current shared masked reconstruction objective for aligning IQ and image-like representations?
Why it matters for bot defense
For bot-defense practitioners, the main takeaway is architectural rather than application-specific: the paper shows that a shared backbone can learn across heterogeneous input views when the front end is modality-aware and the pretraining objective forces reconstruction under heavy masking. In captcha or abuse-detection systems, that suggests a practical pattern for fusing multiple weak signals—e.g., raw event streams, rendered artifacts, and telemetry—without maintaining separate encoders for each view.
The results also reinforce an important caution: balanced multimodal training does not automatically beat the best single-modality specialist on every task. The multimodal model is strongest where its pretraining matches the downstream signal family, but it still trails a larger, more targeted baseline on some image-like tasks. A bot-defense team would likely use this as guidance to justify a shared backbone for efficiency and transfer, while still budgeting for modality-specific tuning or LoRA-style adaptation when one modality dominates performance.
Cite
@article{arxiv2511_15162,
title={ Multimodal Wireless Foundation Models },
author={ Ahmed Aboulfotouh and Hatem Abou-Zeid },
journal={arXiv preprint arXiv:2511.15162},
year={ 2025 },
url={https://arxiv.org/abs/2511.15162}
}