
Detecting LLM-Assisted Academic Dishonesty using Keystroke Dynamics
Source: arXiv:2511.12468 · Published 2025-11-16 · By Atharva Mehta, Rajesh Kumar, Aman Singla, Kartik Bisht, Yaman Kumar Singla, Rajiv Ratn Shah
TL;DR
This paper asks a practical question that most text-only plagiarism detectors dodge: can we detect LLM-assisted academic dishonesty by looking at how the text was produced, not just the final prose? The authors argue that keystroke dynamics capture drafting, editing, and revision behavior that is hard to fake at scale, and that this behavioral signal should complement content-based detectors that are increasingly easy to evade with paraphrasing and polishing. Their main contribution is an expanded experimental framework that adds 90 participants beyond the prior 40-person conference study, introduces an explicit paraphrasing condition, and evaluates robustness under a formal deception threat model.
The result, at a high level, is that keystroke-based models beat text-only baselines in realistic deployment settings, especially when the attacker is simply transcribing or paraphrasing LLM output without trying to spoof timing. But the paper also shows an important limit: once the adversary forges keystroke timing with a realistic generator, performance degrades substantially, particularly for ML-style detectors. The authors partially recover robustness via adversarial training on synthetic deception samples, but they are careful to note that more adaptive attack models remain open. In other words, the work is less about "solving" AI-cheating detection than about demonstrating that behavioral provenance is a materially stronger signal than text alone, while also being attackable if the adversary can emulate typing traces.
Key findings
- The paper extends the prior 40-participant study with 90 additional participants and adds a paraphrasing condition, so the new IIITD-BU (Paraphrased) dataset contains 90 users versus 34 users in IIITD-BU (Transcribed).
- The authors report that their integrated text+keystroke model achieves F1 scores between 64% and 96% on unseen writers and unseen text, depending on scenario and dataset.
- They evaluate four datasets in total: SBU (196 users), Buffalo (157 users), IIITD-BU (Transcribed) (34 users), and IIITD-BU (Paraphrased) (90 users).
- The deception threat model generates forged keystrokes by sampling timing from user-specific or pooled empirical distributions and injects backspaces after every at least 6 characters with 80% probability.
- They state that keystroke-based models significantly outperform text-based approaches in practical deployment settings, but the paper does not provide the exact cross-paper delta in the excerpted text.
- The adversarially trained detector improves robustness against forged keystroke sequences, but the paper says the effectiveness is still bounded by the assumed attacker model.
- TypeNet is adapted from authentication to plagiarism detection using a Siamese setup with cosine similarity, replacing the original Euclidean-distance formulation.
- Severe performance degradation is observed for ML-based detectors under deception attacks, motivating the adversarial training countermeasure (Table 6).
Threat model
The adversary is a motivated student who wants to submit plagiarized or LLM-assisted text while making the associated keystroke trace look bona fide. The attacker is assumed to know at least one authentic reference sample from the same user and may generate a forged keystroke sequence by transferring timing statistics from that reference to the target text, but cannot access or modify the detector’s internal architecture, parameters, thresholds, or the logging mechanism. The model assumes a controlled assessment environment where keystrokes are recorded reliably and non-keystroke input paths such as copy-paste are restricted.
Methodology — deep read
The paper frames the problem as binary detection of bona fide writing versus assisted/plagiarized writing under controlled electronic assessment conditions. The attacker is a student who can submit an LLM-assisted or paraphrased answer and may try to imitate natural typing, but is assumed not to be able to tamper with the logging pipeline or see the detector internals. The central assumption is that the platform can capture keystrokes reliably and that copy-paste, auto-complete, file upload, and similar non-keystroke entry paths are restricted. In some settings, the user may first provide a short reference sample to support user-specific detection.
Data come from four keystroke corpora. Two are newly collected for this work: IIITD-BU (Transcribed) and IIITD-BU (Paraphrased). The transcribed set was collected in two sessions: one bona fide session where participants answered opinion- and fact-based questions independently, and a second session where they transcribed ChatGPT-generated answers, simulating direct copying. The paraphrased set also used two sessions, but the second session required participants to use LLM assistance and then paraphrase before typing; copy-paste was disabled and participants were asked to disable auto-correct, grammar tools, and browser extensions. The other two corpora are repurposed public datasets: SBU, with truthful versus deceptive writing on topics like restaurant reviews, gun control, and gay marriage, and Buffalo, originally built for continuous authentication, using fixed transcription of a Steve Jobs commencement speech versus free-style writing tasks. Table 1 is the key dataset summary in the paper. The excerpt does not provide full train/validation/test counts, random seed policy, or whether splits were user-disjoint versus text-disjoint, though the abstract claims evaluation on unseen writers and unseen text.
For ML-based detectors, the authors segment keystroke streams with a sliding window of 1000 keystrokes and 300-keystroke overlap. They compute temporal features such as dwell time and flight time, plus window-level linguistic/editing features including word count, backspace count per sentence, average word length, counts of nouns/verbs/modifiers/modals/named entities, lexical density, spelling mistakes, special characters per sentence, and keystrokes per burst. Because key and key-pair timing features are sparse, they keep only the 100 most frequent unigram and digraph timing features from the training set. These features feed LightGBM and CatBoost classifiers. For the deep model, they repurpose TypeNet, originally an LSTM-based keystroke authentication model, into a Siamese classifier. Each input event is represented by key action (KeyDown/KeyUp), key code, and timestamp; timestamps are min-max normalized to [0,1], key codes are divided by 255, and key actions are binary encoded. Sequences are padded or truncated to a fixed length M, with M tuned in the range 25 to 500. The Siamese branches each contain two LSTM layers with 128-dimensional outputs, batch normalization, tanh activation, fully connected projection to a shared 128-dimensional embedding space, dropout 0.5, and recurrent dropout 0.2. Unlike original TypeNet, which used Euclidean distance, this paper uses cosine similarity inside a binary cross-entropy objective, which the authors say was more stable and performed better in preliminary experiments.
Training and tuning are described at a fairly high level. The authors vary batch size from 32 to 512, sequence length M from 25 to 500, train up to 100 epochs, and use Adam with learning rate in [0.0001, 0.005] plus L2 regularization. They exclude sequences with more than 20% Shift-key usage or with effective length shorter than 50% of M. Positive versus negative pairing in the Siamese setup is based on whether the two sequences come from different typing conditions; pairs from different conditions are labeled 1 and same-condition pairs 0, with balanced pairing to reduce class imbalance. The paper says performance typically converges between 50 and 100 epochs but does not specify a single chosen epoch count, early stopping criterion, or hyperparameter search protocol in the excerpt.
Evaluation uses FAR, FRR, Accuracy, and F1, with plagiarism treated as the positive class. The decision threshold is set at the Equal Error Rate point on the ROC curve. The authors compare three model families: LightGBM, CatBoost, and TypeNet. They also compare against text-only detectors and human evaluators, though the excerpt does not name all text-only baselines or provide their exact scores. A notable part of the methodology is the deception-based threat model. To synthesize attack data, they build per-user and pooled timing dictionaries for key unigrams and digraphs, fit Gaussian distributions to empirical means and standard deviations, and sample synthetic timings. The generator uses a three-stage fallback: user-specific statistics first, then pooled across users for that key combination, then a global fallback. It also inserts backspaces stochastically after every at least 6 characters with 80% probability to emulate editing behavior. Two attack variants are defined: At-U, which uses the full three-stage lookup, and At-P, which omits user-level statistics and uses pooled distributions only. They then evaluate detector vulnerability on inputs of the form (x2, K-hat(x2)), where x2 is the plagiarized or LLM-assisted text and K-hat(x2) is the forged keystroke trace. The countermeasure is adversarial training: augment the training set with synthetic forged samples labeled as bona fide/plagiarized accordingly, then retrain the detector to better separate genuine from forged dynamics.
One concrete end-to-end example from the paper’s setup is a student answering a fact-based prompt in IIITD-BU (Transcribed). In the bona fide session, the student types the answer unaided, generating a sequence of KeyDown/KeyUp events with natural pauses, revisions, and word bursts. In the assisted session, the student pastes or transcribes ChatGPT output (copy-paste is blocked, so the content must be typed), which changes the temporal profile because the text is sourced externally. That raw stream is segmented into a 1000-keystroke window, converted into timing and linguistic features, and either fed to LightGBM/CatBoost or standardized into a fixed-length keystroke sequence for TypeNet. During evaluation, the detector predicts whether the sample is bona fide or assisted; in the deception setting, the same answer text is paired with a synthetic keystroke trace generated from the user’s previous authentic timing profile, and the detector is tested again to measure whether it is fooled. Reproducibility is partial: the paper says code is publicly released on GitHub, but the excerpt does not mention frozen weights, a public release of the full raw datasets, or a fully specified split protocol.
Technical innovations
- Extends keystroke-based academic dishonesty detection from direct transcription to an explicit paraphrasing setting, which is closer to real LLM-assisted cheating workflows.
- Defines a formal deception threat model and a keystroke generator that aligns synthetic timing statistics to a target text rather than producing timing traces in isolation.
- Adapts TypeNet from user authentication to plagiarism detection by converting it into a Siamese model trained with cosine similarity and binary cross-entropy.
- Introduces adversarial training with forged keystroke samples as a robustness countermeasure against timing spoofing attacks.
Datasets
- SBU — 196 users — public dataset (Amazon Mechanical Turk)
- Buffalo — 157 users — public dataset
- IIITD-BU (Transcribed) — 34 users — collected by authors
- IIITD-BU (Paraphrased) — 90 users — collected by authors
Baselines vs proposed
- Text-only detectors: significantly outperformed by keystroke-based models in practical deployment settings, exact metrics not provided in the excerpt
- Human evaluators: lower than keystroke-based models, exact metrics not provided in the excerpt
- TypeNet / keystroke-based model: F1 = 64% to 96% on unseen writers and unseen text, depending on dataset and scenario
- ML-based detectors under deception: substantial performance degradation reported in Table 6, exact values not shown in the excerpt
- Adversarially trained detector: improved robustness to forged keystrokes relative to non-adversarial training, exact metrics not shown in the excerpt
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2511.12468.
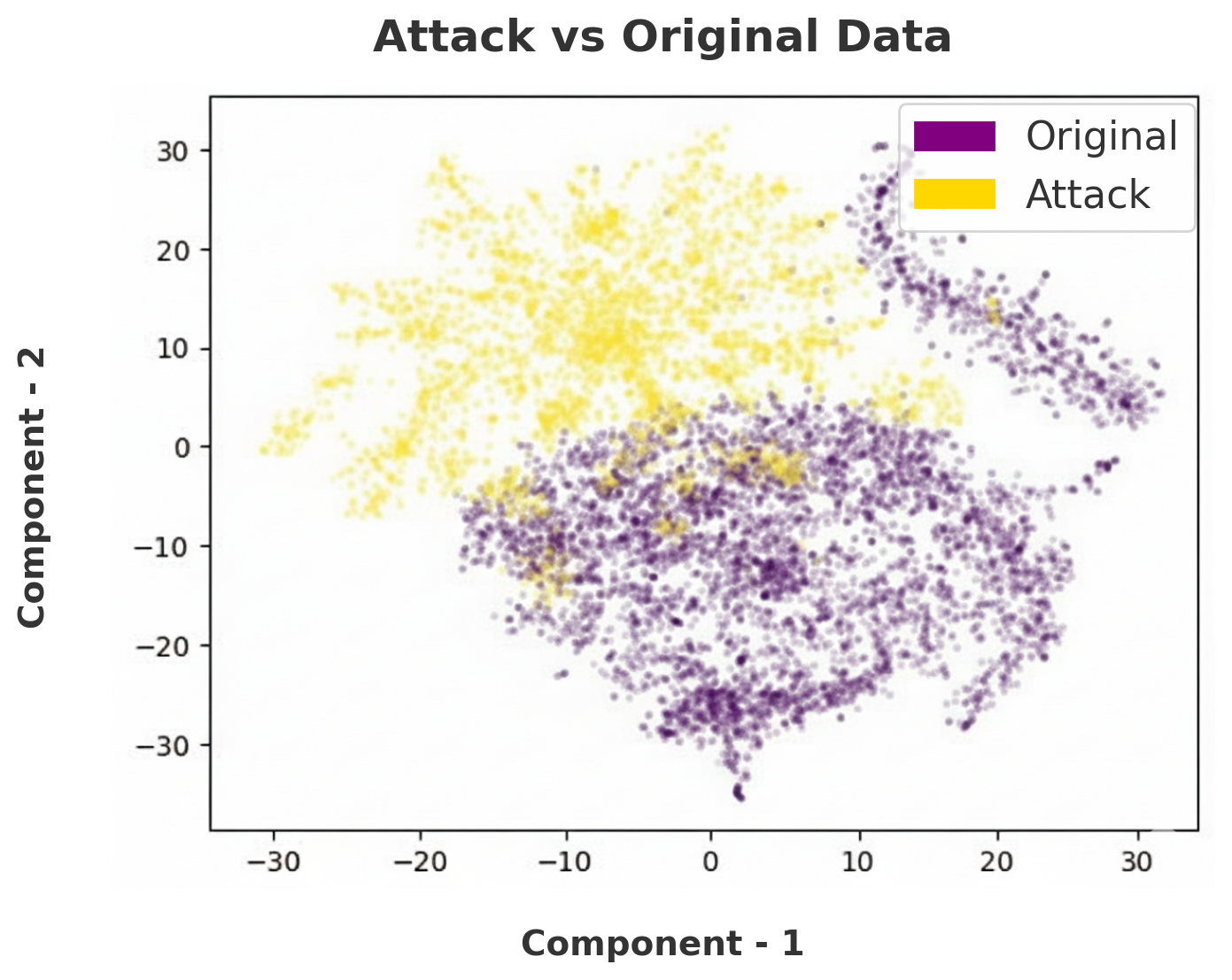
Fig 3: TSNE plot for the attack dataset with original data
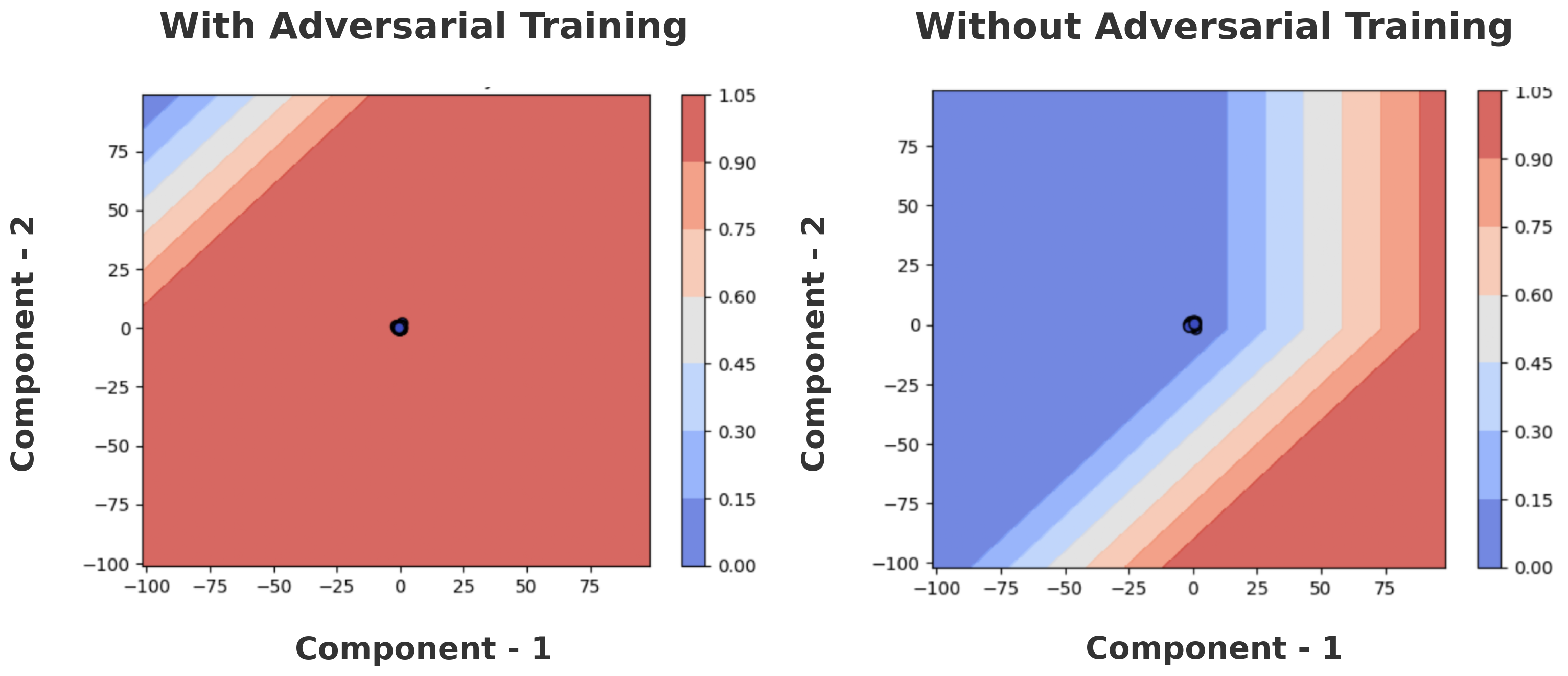
Fig 4: Decision

Fig 3 (page 16).

Fig 4 (page 16).

Fig 5 (page 16).

Fig 6 (page 16).

Fig 7 (page 16).
Limitations
- The excerpt does not provide full split details, so it is unclear how strongly the evaluation separates users, prompts, and sessions.
- The deception attacker is synthetic and relatively constrained; more adaptive generators or learned spoofers could be stronger than the paper evaluates.
- The authors rely on controlled typing environments with logging and disabled copy-paste, which may not match real-world student workflows.
- The paper does not give all exact comparative metrics for text-only baselines and human raters in the excerpted text.
- Cross-device and cross-context generalization is only partially addressed; Buffalo includes keyboard variability, but the paper does not report a full domain-shift stress test in the excerpt.
Open questions / follow-ons
- How well does the approach hold up under cross-device and cross-language shifts, where keyboard layout and typing conventions differ substantially?
- Can a learned keystroke generator conditioned jointly on text content and user history break the current detector more effectively than the Gaussian timing synthesis used here?
- What is the minimum amount of reference typing needed to build a reliable user-specific detector without making enrollment burdensome?
- Can the behavioral signal be fused with content-based or watermark-based signals in a calibrated way that reduces both false positives and false negatives?
Why it matters for bot defense
For bot-defense and proctoring teams, the main takeaway is that behavior at input time can be more informative than the submitted text itself. If you can log keystrokes, this paper suggests that a model can distinguish some forms of LLM-assisted writing, especially direct transcription and simpler paraphrasing, better than text-only plagiarism tools. That is useful if your concern is not just whether text looks AI-generated, but whether the writing process itself looked human.
At the same time, the paper is a warning that behavioral signals are not magic. A motivated adversary with a reference typing sample and a timing-spoofing strategy can erode detector performance, so any deployment should assume a red-team will eventually try to synthesize plausible keystrokes. Practically, that argues for layered defenses: keystroke provenance plus content analysis plus session-level anomaly checks, with careful attention to user privacy, accessibility, and false-positive costs in high-stakes settings.
Cite
@article{arxiv2511_12468,
title={ Detecting LLM-Assisted Academic Dishonesty using Keystroke Dynamics },
author={ Atharva Mehta and Rajesh Kumar and Aman Singla and Kartik Bisht and Yaman Kumar Singla and Rajiv Ratn Shah },
journal={arXiv preprint arXiv:2511.12468},
year={ 2025 },
url={https://arxiv.org/abs/2511.12468}
}