
Online Learning to Rank under Corruption: A Robust Cascading Bandits Approach
Source: arXiv:2511.03074 · Published 2025-11-04 · By Fatemeh Ghaffari, Siddarth Sitaraman, Xutong Liu, Xuchuang Wang, Mohammad Hajiesmaili
TL;DR
This paper addresses online learning to rank under adversarially corrupted click feedback, modeled as cascading bandits. The core problem is that existing OLTR methods either achieve the right logarithmic regret in clean stochastic settings but break under click fraud/corruption, or they are robust but give up stochastic optimality and/or learn too slowly in practice. The authors target the gap between these two regimes: a method that is optimal when feedback is honest, and whose regret degrades only additively with the total corruption budget when bots or fake users inject manipulated clicks.
Their main contribution is M2UCB-V, a corruption-agnostic cascading-bandit algorithm built around a calibrated mean-of-medians estimator plus a variance-aware UCB radius, wrapped in a model-selection layer to remove the need to know the corruption budget in advance. The mean-of-medians step is adapted to Bernoulli click data by calibrating the median-based statistic back to the Bernoulli mean via inversion of the majority probability map q_b. The theory claims optimal stochastic regret O(\sum_{k\notin S*} log T / \Delta_k) in the clean case and O(KC + K log T / \Delta) under corruption. Empirically, on Yelp, MovieLens, and LastFM, they report large regret reductions versus prior robust baselines, including 97.35% vs CascadeUCB-V and 91.60% vs CascadeRAC in representative 40k-round runs.
Key findings
- The proposed M2UCB-V is claimed to achieve regret O(\sum_{k\notin S*} log T / \Delta_k) in the uncorrupted setting, matching the known stochastic lower bound for cascading bandits.
- Under adversarial corruption level C, the paper proves regret O(KC + K log T / \Delta), i.e., corruption enters additively rather than multiplicatively.
- The calibrated mean-of-medians estimator is introduced as, to the authors’ knowledge, the first use of mean-of-medians for bandits with corruption; unlike heavy-tailed bandit uses, it includes an explicit calibration step for asymmetric Bernoulli clicks.
- Algorithm 2 initializes with a pure-exploration phase of 10KC rounds so that each item gets enough observations before the robust estimator is used.
- Table 1 reports that CascadeUCB-V matches the stochastic lower bound but is not corruption-robust, while CascadeRAC and FORC are robust but suboptimal in the clean regime and have multiplicative corruption dependence.
- The authors state that on representative 40k-round experiments, M2UCB-V improves cumulative regret by 99.60% over FTRL, 97.35% over CascadeUCB-V, 91.60% over CascadeRAC, and 98.41% over CascadeCBARBAR.
- On the three evaluated real-world datasets, the method is reported to outperform all compared baselines consistently across corruption levels, including the stochastic/no-corruption case.
- The paper explicitly notes that its corruption term is still suboptimal by a factor of K relative to an ideal O(C) benchmark, even though it is additive.
Threat model
The adversary can corrupt observed item feedback arbitrarily at each round, subject to a total budget C measured as the sum over rounds of the maximum absolute corruption on any displayed item. The learner sees only corrupted clicks, does not know C in advance, and must still optimize regret with respect to the uncorrupted Bernoulli environment. The adversary cannot change the underlying item click probabilities mu_k, but can mislead the learner through fake or altered feedback; the paper does not assume the adversary is restricted to non-adaptive behavior beyond the budget constraint.
Methodology — deep read
Threat model and assumptions: the learner operates in a cascading bandit OLTR environment with K items, list length d, and horizon T. At each round the user examines items sequentially and clicks the first attractive item; the learner only observes feedback up to the first click. The adversary can corrupt observed click feedback arbitrarily, subject to a global budget \sum_t max_{k in S(t)} |c_{k,t}| <= C, and the learner does not know C in advance. The paper follows the standard independence assumption across item clicks (Bernoulli per item) and evaluates regret against the underlying uncorrupted stochastic means, not the corrupted observations. This is a strong-but-standard offline-adversarial corruption model for bandits, but the paper does not model strategic adaptive adversaries beyond arbitrary bounded corruption.
Data and problem setup: there is no supervised training set in the usual sense, but the empirical section uses three real-world recommendation datasets: Yelp, MovieLens, and LastFM. The paper gives raw dataset scale statistics: Yelp has 6,990,280 ratings of 150,346 businesses from 1,987,897 users; MovieLens has 32,000,204 ratings of 87,585 movies from 200,948 users; LastFM has 359,347 users and 186,642 artists. The excerpt does not describe the exact conversion from these rating logs into click probabilities or the exact train/validation/test split; it only says the experiments are conducted on real-world datasets and synthetic/real-world settings. That missing detail matters because the mapping from explicit ratings to binary click feedback and the construction of corruption patterns will affect the reported regret curves.
Architecture / algorithm: M2UCB-V is built in layers. First, MUCB-V replaces the ordinary empirical mean in CascadeUCB-V with a robust calibrated mean-of-medians estimator. For each item k, observed rewards are partitioned into b blocks where b = ceil(alpha log T_k(t)); the median of each block is computed, the block medians are averaged, and then that average is calibrated by numerically inverting q_b(p) = Pr(Bin(b,p) >= (b+1)/2), the probability that a Bernoulli block has a majority of ones. This calibration is necessary because, unlike the symmetric heavy-tailed setting where mean-of-medians is often used, Bernoulli medians are biased relative to the mean. Second, the algorithm forms a variance-aware UCB radius rho_k = A sqrt(vhat_k log t / s) + B log t / s, with vhat_k = muhat_k(1-muhat_k), so uncertainty shrinks faster for near-0/near-1 items. Third, to remove dependence on known corruption budget C, it wraps many base learners MUCB-V(C) on a geometric grid G = {0,1,2,4,...} in a model-selection framework inspired by Wei et al. [36]. The highest-level novelty is not the UCB form itself, but the combination of calibrated robust mean estimation, variance-aware radii, and corruption-budget model selection in a non-linear cascading reward setting.
Training / runtime regime: this is an online algorithm, so “training” means sequential interaction rather than offline optimization. The paper specifies a warm-up of 10KC rounds in MUCB-V so that each item accumulates more than 10C observations before robust estimation kicks in; after that, the algorithm updates every round. The excerpt does not provide optimizer, learning rate, mini-batching, or random seed strategy because none is applicable in the standard supervised sense, and it does not state hardware or wall-clock timing. Algorithm 4 uses bisection to invert q_b with a tolerance eta and a maximum number of iterations N, but the excerpt does not list concrete values for eta or N. One concrete end-to-end example from the method is: after item k has s observations, the algorithm splits those samples into b blocks, computes each block median M_j, averages them to M, uses Calibrate(b,M) to map back to an estimate of mu_k, computes variance proxy vhat_k, adds a confidence radius, and then ranks items by the upper confidence bounds to choose the next top-d list.
Evaluation protocol, baselines, and reproducibility: the paper compares against CascadeUCB-V, FTRL, CascadeRAC, and CascadeCBARBAR, and Table 1 summarizes theoretical regret regimes for CascadeUCB-V, CascadeRAC, FORC, CascadeCBARBAR, and M2UCB-V. The excerpt mentions representative experiments at 40k rounds with list size d=10, and figures showing regret growth on Yelp, MovieLens, and LastFM, but it does not include numeric axes values for those curves in the provided text. The paper claims strong performance across a wide range of corruption levels, including the stochastic setting, and states that M2UCB-V outperforms CascadeCBARBAR even under heavy corruption because it updates every round rather than on a doubling-epoch schedule. Reproducibility is partial from the excerpt: algorithms are specified in pseudocode and the theoretical appendix is described, but code release, frozen weights, exact dataset preprocessing, and exact corruption-generation protocol are not stated in the text provided. If the paper has a public repo or supplementary materials, they are not visible in this excerpt.
Technical innovations
- A calibrated mean-of-medians estimator for Bernoulli click data that explicitly inverts the majority-probability map q_b to recover the underlying click mean.
- A corruption-robust cascading-bandit UCB that combines the calibrated estimator with a variance-aware confidence radius from CascadeUCB-V.
- A corruption-agnostic model-selection wrapper over a geometric grid of corruption budgets, adapted from Wei et al. [36], to avoid requiring C at test time.
- A new cascading-bandit adaptation of CBARBAR, called CascadeCBARBAR, used as a comparison point and appendix contribution.
Datasets
- Yelp — 6,990,280 ratings of 150,346 businesses from 1,987,897 users — public
- MovieLens — 32,000,204 ratings of 87,585 movies from 200,948 users — public
- LastFM — 359,347 users and 186,642 artists — public
Baselines vs proposed
- CascadeUCB-V: cumulative regret after 40k rounds improved by 97.35% vs proposed: M2UCB-V
- CascadeRAC: cumulative regret after 40k rounds improved by 91.60% vs proposed: M2UCB-V
- FTRL: cumulative regret after 40k rounds improved by 99.60% vs proposed: M2UCB-V
- CascadeCBARBAR: cumulative regret after 40k rounds improved by 98.41% vs proposed: M2UCB-V
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2511.03074.
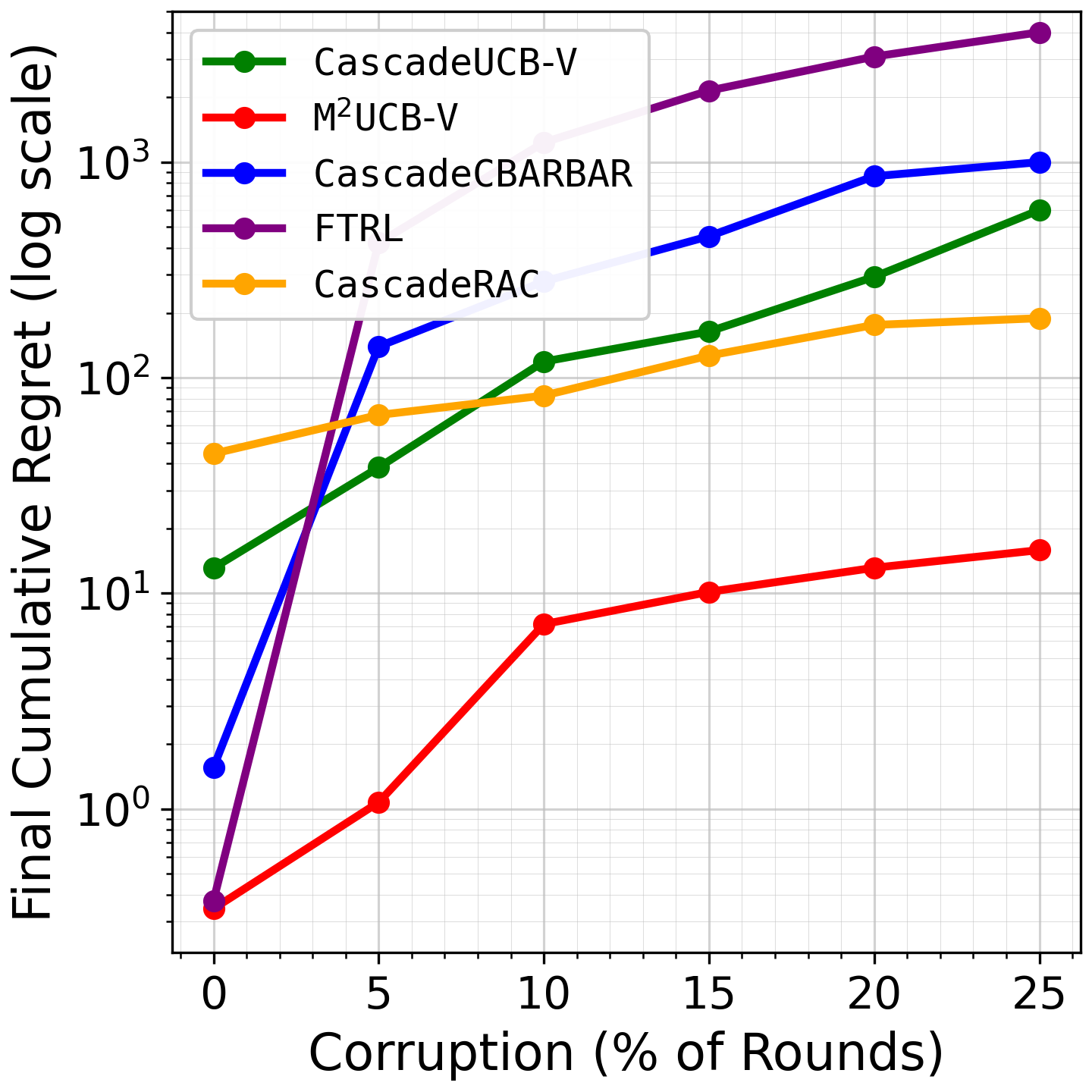
Fig 1: Comparing final cumulative regret of the algorithms after 40K rounds with list size 𝑑= 10.
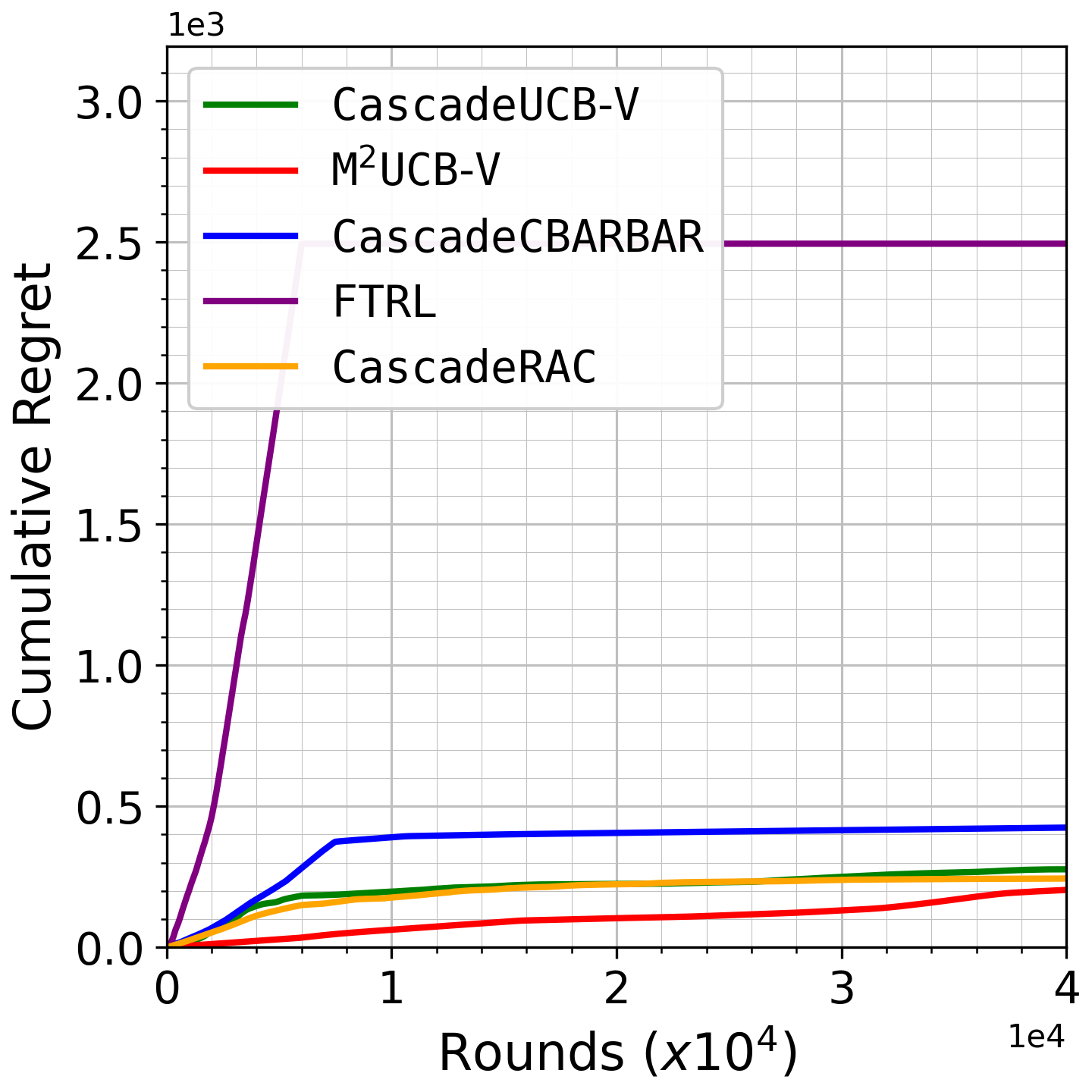
Fig 2: Growth of cumulative regret as a function of rounds for the Yelp dataset, with list size 𝑑= 10.
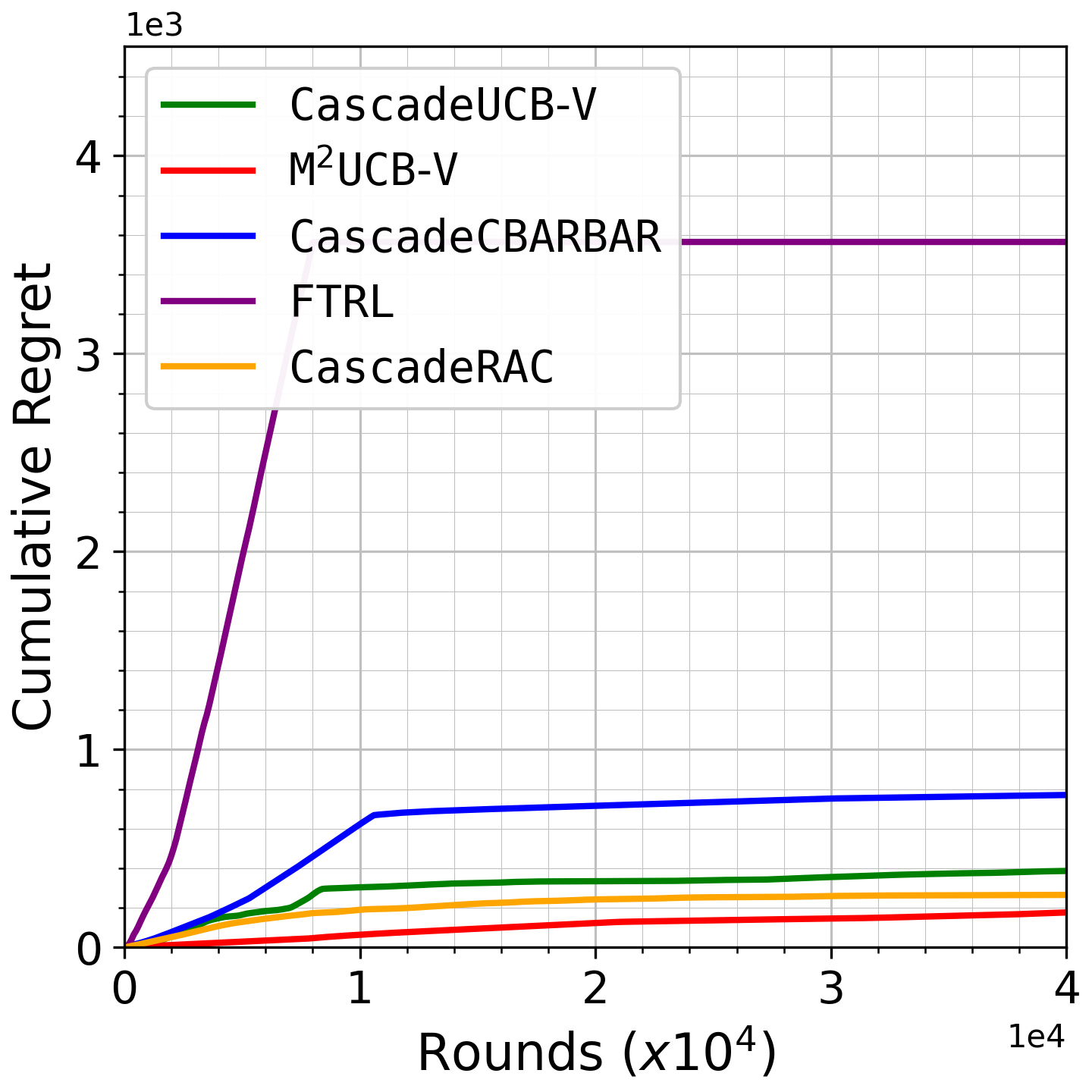
Fig 3: Growth of cumulative regret as a function of rounds for the MovieLens dataset, with list size 𝑑= 10.
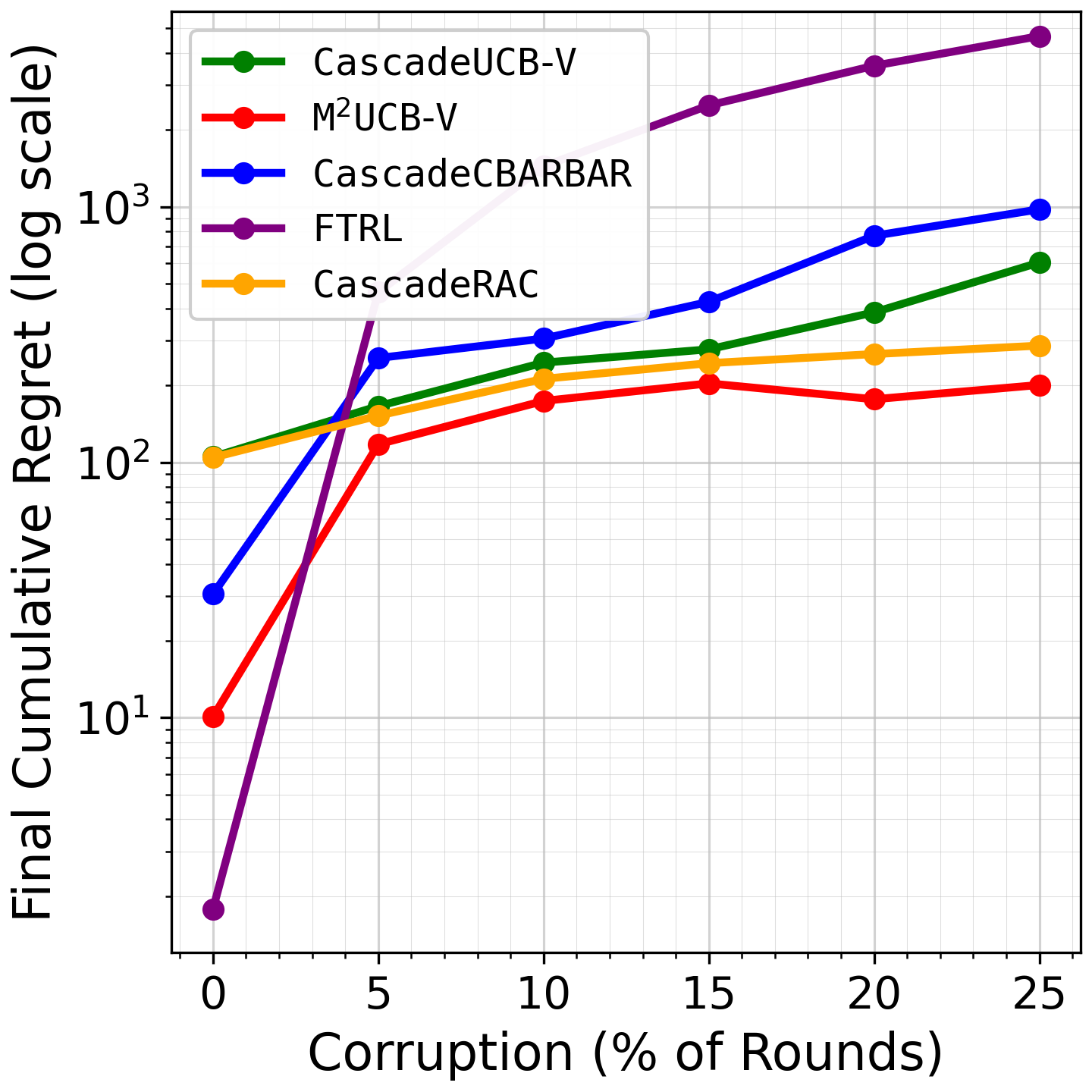
Fig 4: Growth of cumulative regret as a function of rounds for the LastFM dataset, with list size 𝑑= 10.
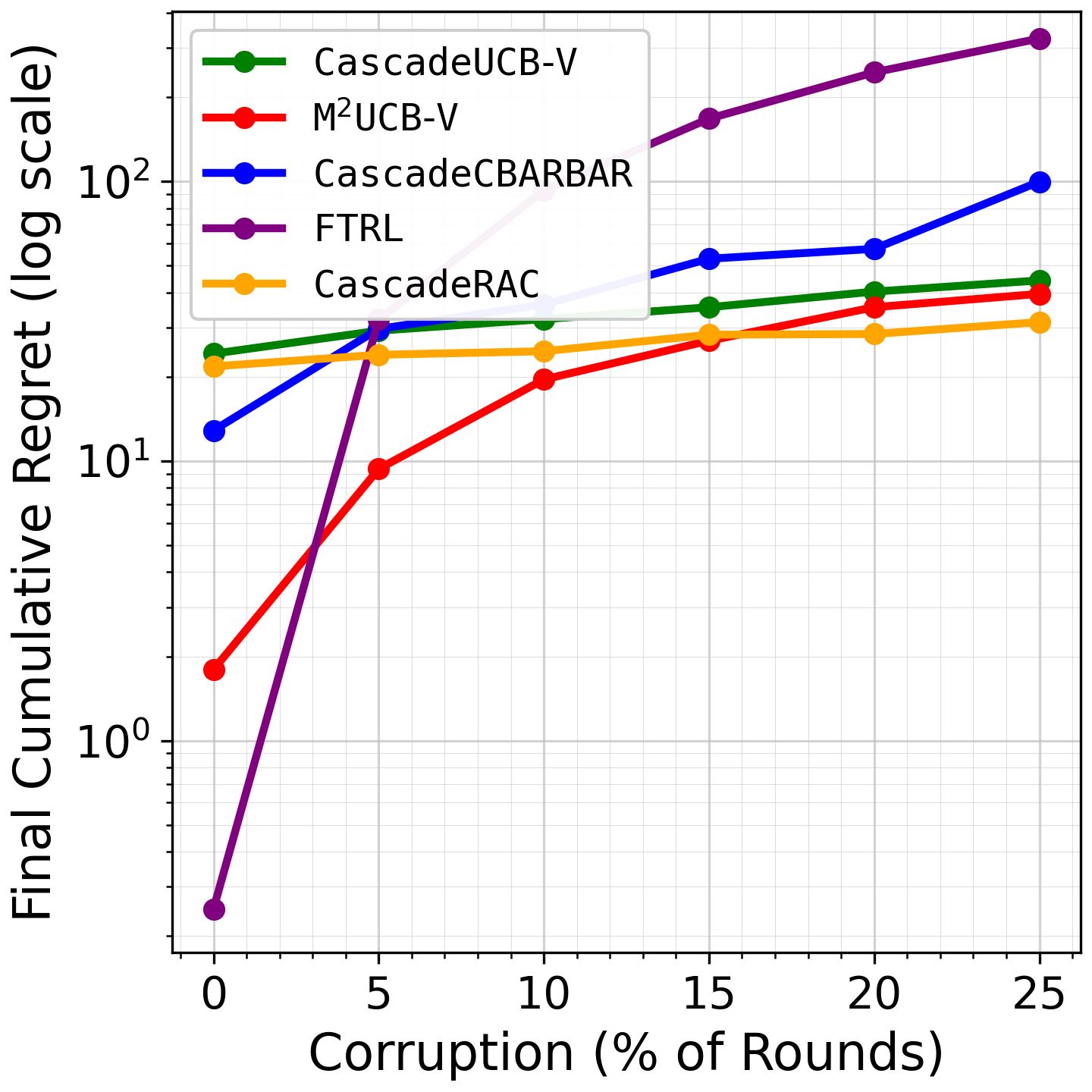
Fig 5 (page 8).
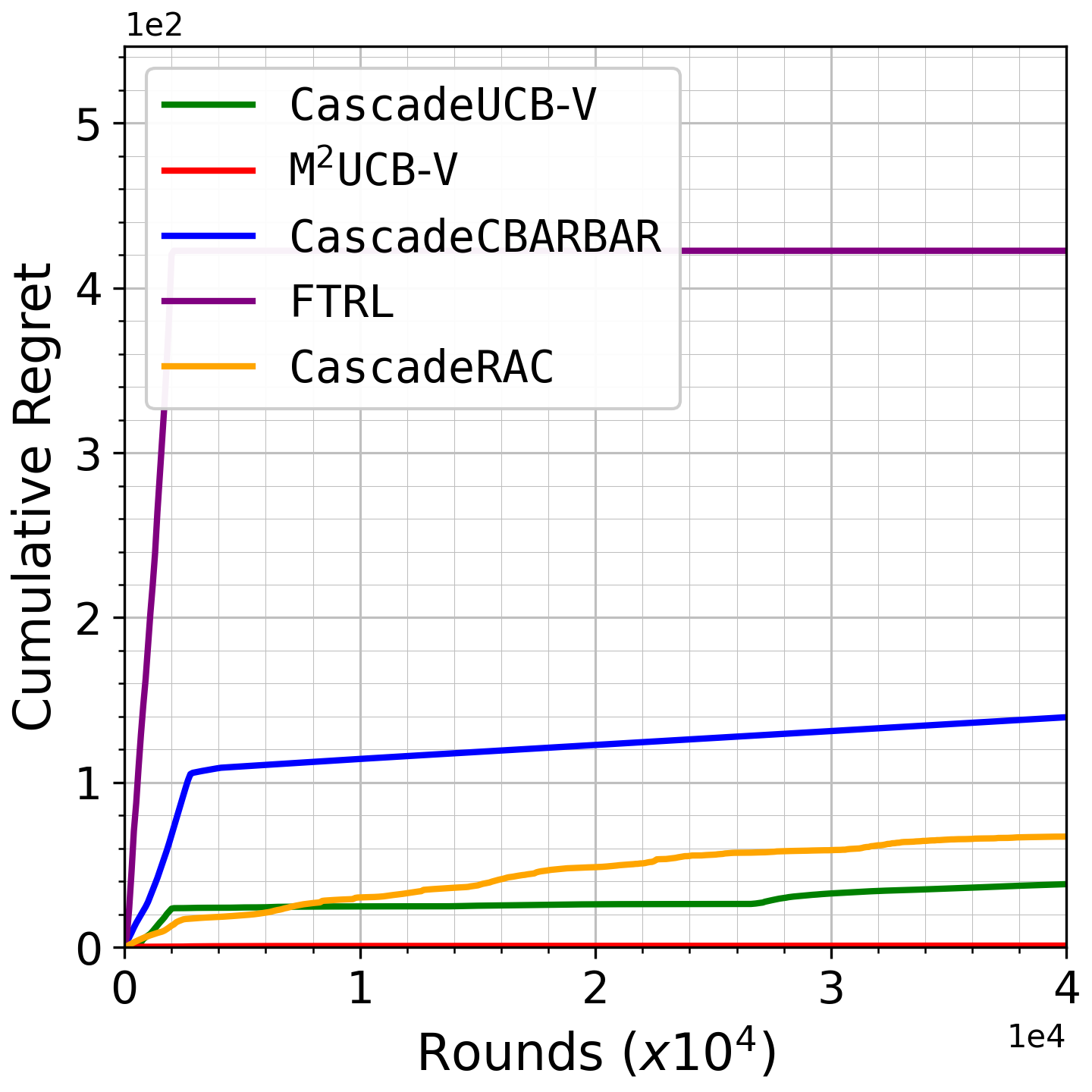
Fig 6 (page 8).
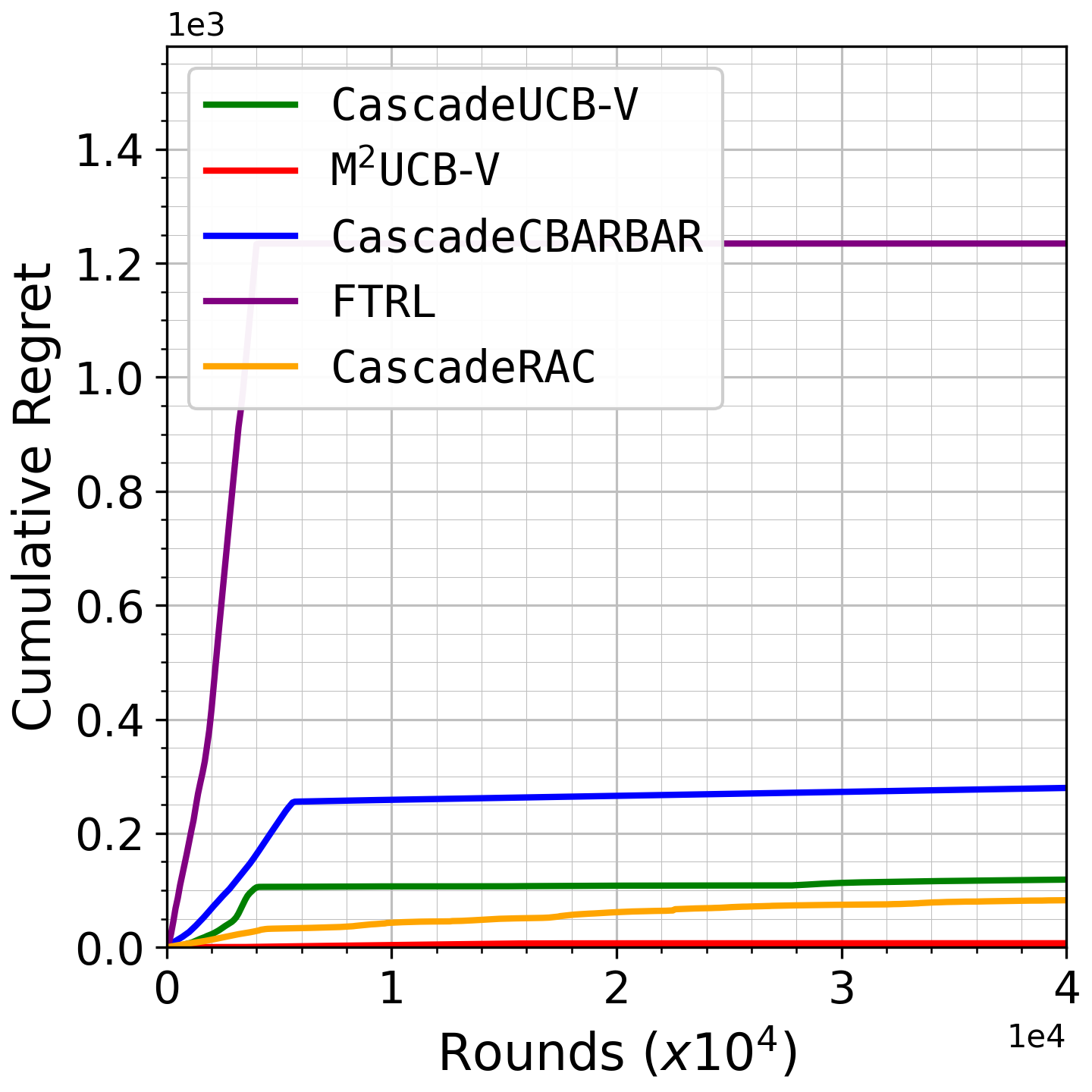
Fig 7 (page 8).
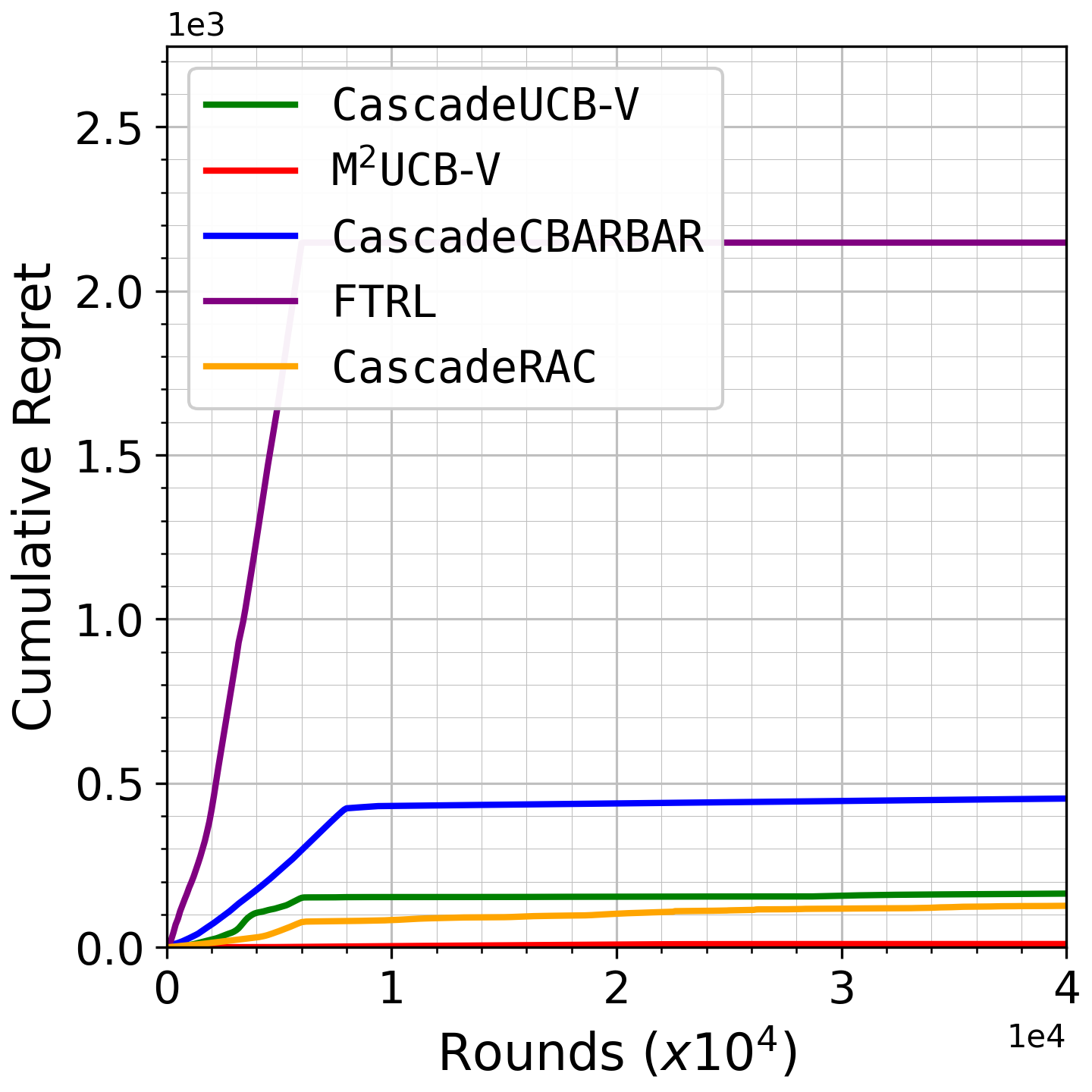
Fig 8 (page 8).
Limitations
- The paper’s corruption guarantee is additive in KC, but the authors note this is still suboptimal by a factor of K relative to an ideal O(C) dependence.
- The excerpt does not specify the exact real-world preprocessing from ratings to binary clicks, which is important for interpreting the experiments.
- The provided text does not include the full numeric results curves from Figures 1-4, only qualitative claims and improvement percentages.
- The model-selection wrapper inherits complexity from the grid of candidate corruption levels; the runtime/memory overhead is not quantified in the excerpt.
- The analysis assumes independent Bernoulli item clicks and the standard cascade stopping model, which may not hold in more complex UI or correlated-feedback settings.
Open questions / follow-ons
- Can the additive KC corruption term be reduced to O(C) without sacrificing the clean stochastic lower bound?
- How sensitive is the calibrated mean-of-medians estimator to misspecification of the Bernoulli assumption or to non-binary feedback?
- What is the runtime and practical overhead of the model-selection wrapper compared with a single-budget learner in production-scale ranking systems?
- Can similar calibration ideas be extended to contextual or position-biased click models beyond the pure cascade setting?
Why it matters for bot defense
For bot-defense and anti-fraud systems, the paper is relevant because it treats corrupted feedback as the core learning failure mode rather than an edge case. The algorithmic takeaway is that a recommender/ranker can be made less brittle to fake-user traffic by using robust estimators that suppress outliers and by explicitly separating clean performance from corruption handling. In practice, a CAPTCHA or fraud-defense engineer would read this as evidence that online ranking systems should not trust raw click signals at face value; robust aggregation and budgeted anomaly handling can materially improve stability when bots inject biased interaction traces.
From a defensive design perspective, the useful idea is not the specific cascade-bandit math, but the principle of calibrating robust statistics to the data distribution at hand. The paper also highlights a deployment pattern: if the defender does not know the attack rate, use a model-selection layer over multiple contamination assumptions rather than hard-coding one threshold. For CAPTCHA-adjacent systems, that suggests adaptive defenses that keep several contamination hypotheses alive and eliminate those that no longer fit the stream, instead of tuning to a fixed fraud rate that attackers can exploit.
Cite
@article{arxiv2511_03074,
title={ Online Learning to Rank under Corruption: A Robust Cascading Bandits Approach },
author={ Fatemeh Ghaffari and Siddarth Sitaraman and Xutong Liu and Xuchuang Wang and Mohammad Hajiesmaili },
journal={arXiv preprint arXiv:2511.03074},
year={ 2025 },
url={https://arxiv.org/abs/2511.03074}
}