
Unfair Mistakes on Social Media: How Demographic Characteristics influence Authorship Attribution
Source: arXiv:2510.19708 · Published 2025-10-22 · By Jasmin Wyss, Rebekah Overdorf
TL;DR
This paper investigates whether authorship attribution classifiers used on social media text are fair across different demographic groups, specifically gender, native language, and age. The motivation stems from the growing deployment of stylometric methods for identifying sockpuppet accounts, malicious users, and cross-platform linking, where biased performance could cause disproportionate harm to certain demographics through false accusations and privacy violations. The authors systematically audit three dimensions of fairness: whether demographic composition of the suspect set impacts overall classification performance, whether misclassification rates differ by demographic group (equity of odds), and how errors behave when the true author is absent from the suspect set (forced misclassification).
The main finding is that in the closed-world setting with the true author present, authorship attribution performance and misclassification likelihood do not vary significantly across demographic groups. However, in the forced misclassification setting—when the correct author is removed from the training pool—the model disproportionately attributes authorship to other users sharing the same demographic characteristic as the true author. This bias occurs not only on atypical writing samples but also those close to the author's average style, suggesting demographic similarity influences mistaken attribution. The results caution that seemingly fair models in standard closed-world evaluations may exhibit demographic biases in real-world error conditions.
Methodologically, the paper collects novel Reddit datasets with self-declared flair-based demographic labels using an innovative combination of the Wayback Machine and Reddit APIs, producing larger and richer data than previously available. Logistic Regression with writeprints features is the primary attribution method, evaluated on user comment histories segmented chronologically. Regression and statistical tests, including Wilcoxon Rank Sum tests, assess fairness via performance metrics and error distributions, with particular emphasis on intra- versus inter-demographic misattributions in forced misclassification experiments.
Key findings
- The slope of linear regression between suspect set demographic composition and classification accuracy is near zero across age, gender, and native language groups, indicating no effect on overall performance (Table 1).
- Wilcoxon Rank Sum tests do not reject equality of misclassification probabilities across demographic groups (P(mis|dc) ≈ P(mis|¬dc)) in the closed-world setting (Fig 3).
- In the forced misclassification setting, texts are misattributed at statistically significantly higher rates to authors sharing the true author's demographic characteristic, especially notable with larger suspect set sizes (e.g., 16 users; Tables 2a-d, Figs 4-6).
- Non-native speakers sharing a native language show stronger intra-status misclassification bias than non-natives pooled randomly (Fig 4, Table 2b vs 2a).
- For gender, intra-status misattributions (man→man, woman→woman) occur at significantly higher rates than inter-status for suspect sets of size 16 with p-value < 0.05 (Table 2c).
- Age group (GenX vs GenZ) also shows significant intra-generational misattribution bias for suspect sets of 8 and 16 users (Table 2d, Fig 6).
- Misclassified samples tend to be more distant in feature space from the author’s average style vector (average cosine distance 0.95) than correctly classified samples (0.84), highlighting style deviation impacts (Sec 7).
- Using writeprints features with Logistic Regression yields the best classification performance in this setting, with controlled experiments confirming robustness.
Threat model
The adversary is assumed to know the suspect set of possible authors and has access to training data consisting of previous writings with known authorship and demographic labels. The adversary attempts to attribute new texts to their true author using stylometric classification. The adversary cannot alter user writing styles to evade detection and operates under a closed-world assumption or forced misclassification setting where the true author may be absent. The model assumes no adversarial obfuscation and no active defense by users.
Methodology — deep read
The study focuses on auditing fairness in authorship attribution for social media texts, specifically using Reddit data. The threat model assumes an adversary aiming to deanonymize or link anonymous/pseudonymous online users based on their writing style. The adversary trains supervised classifiers on labeled user text samples from a suspect set, with knowledge of demographic labels controlled in the experiments, but cannot alter user writing. Importantly, the study does not evaluate against active adversarial obfuscation.
Data collection is novel: the authors combine Reddit API access with the archival Wayback Machine API to bypass Reddit API limitations and collect large quantities of user posts, specifically targeting subreddits where users self-identify demographic attributes through flairs. Three datasets are built targeting native language (411 authors), gender (6,982 authors), and age/generation (160+ authors in GenX and GenZ cohorts). User comments ≥128 words are selected chronologically, with ~5,000 words for training and 10 newer comments for testing each user.
The classifier is a Logistic Regression model trained on writeprints features (a stylometric feature set capturing lexical, syntactic and structural style elements) as proposed in Abbasi and Chen [2008]. Experiments also verify results with character n-grams and other algorithms but focus on writeprints+logR for best performance.
Training regimes use deterministic splits by user chronological ordering to simulate realistic conditions. The models are trained and tested on varying suspect set sizes (4, 8, 16 authors). The parameter space for LR and hyperparameters are not detailed explicitly. The training is repeated 10 times per experiment with different random suspect sets to derive performance distributions.
Evaluation includes: 1) regression analysis relating suspect set demographic composition (% of users with a given demographic) to classifier accuracy or F1 to detect composition bias; 2) statistical tests (Wilcoxon Rank Sum) of the probability distributions of misclassifications given demographic groups to test equity of odds; 3) forced misclassification experiments where the true author is removed from the suspect set to ensure forced errors, and the demographic correlation of false attributions is analyzed. Probability of intra-demographic vs inter-demographic misattributions are computed and compared.
The forced misclassification setting isolates demographic similarity effects on error by removing confounds due to changes in individual writing style. Cosine distances in feature space between sample vectors and author's mean training vector illustrate that forced misclassification errors are not only for outlier texts but extend to stylistically typical samples.
No mention of code release or external reproducibility artifacts, though datasets rely on publicly available Reddit and Wayback APIs with custom scraping methodology described.
Technical innovations
- A novel forced misclassification evaluation methodology removing the true author from the suspect set to study demographic bias in error assignments.
- An innovative data collection method combining Reddit API and the Wayback Machine API to overcome API limitations for large-scale demographic-labeled Reddit text datasets.
- Adapting fairness metrics such as equity of odds from the fairness literature into the authorship attribution context on social media.
- Systematic analysis showing that demographic makeup of training/suspect sets does not affect closed-world accuracy but influences false positive error patterns under forced misclassification.
Datasets
- Native Language dataset — 411 authors — collected from r/languagelearning with self-declared flairs
- Gender dataset — 6,982 authors — from multiple gender-specific advice and transgender-focused subreddits with self-declared flairs
- Age/Generation dataset — >160 authors per generation — from generation-focused subreddits using flairs indicating birth year
Baselines vs proposed
- Writeprints + Logistic Regression: baseline classification approach used for all experiments, selected as best in model comparisons (details in appendix, not fully provided).
- Character n-grams + Logistic Regression: showed similar qualitative patterns but with lower performance; no impact on fairness conclusions.
- Other ML algorithms with writeprints features tested on native language dataset showed consistent results regarding demographic bias (specific metrics not provided).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2510.19708.
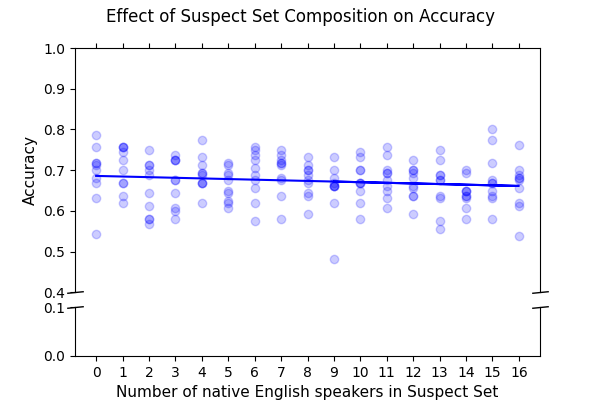
Fig 2: Figure 2: The first-order polynomial predicting a classi-
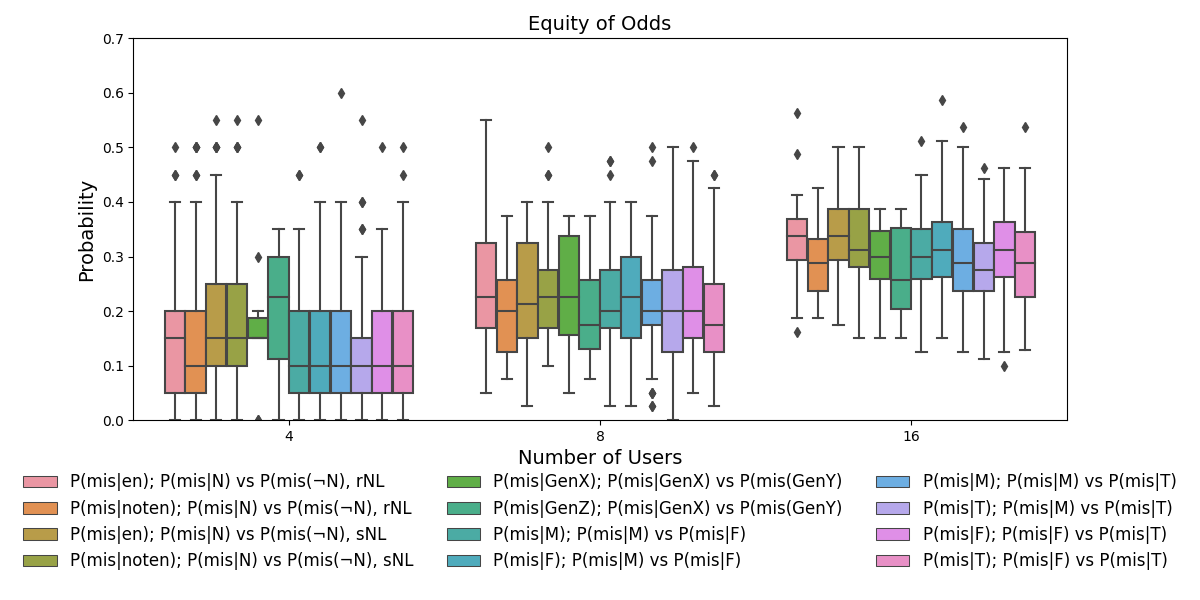
Fig 3: Boxplots showing the probability distributions of being misclassified depending on your demographic charac-
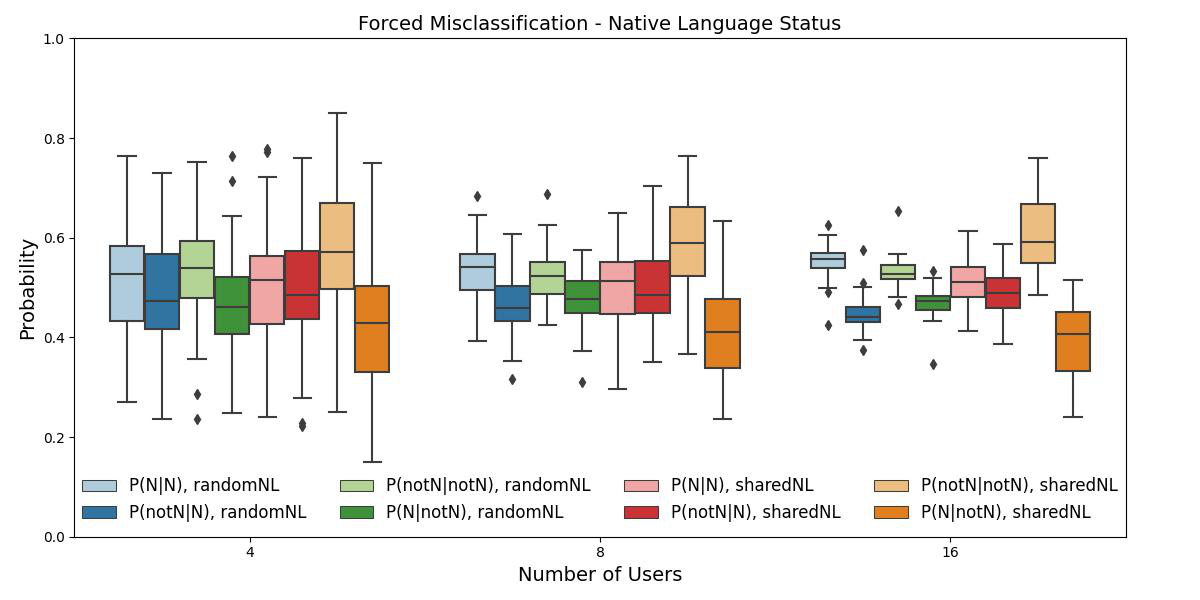
Fig 4: Boxplots displaying the probability distribution of intra- and inter-native language assignment for different
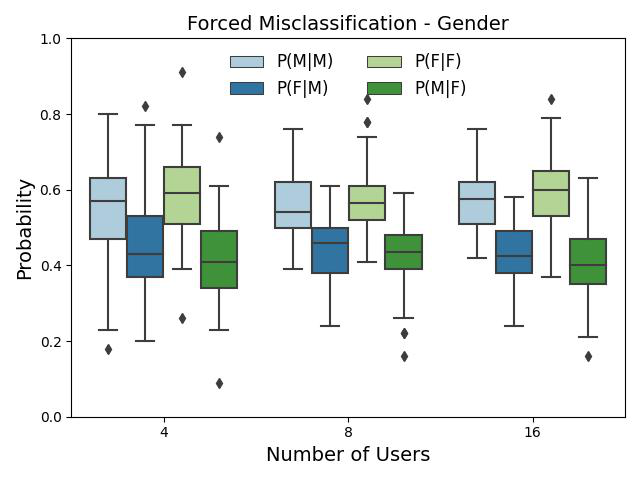
Fig 5: The probability distributions of intra- and inter-
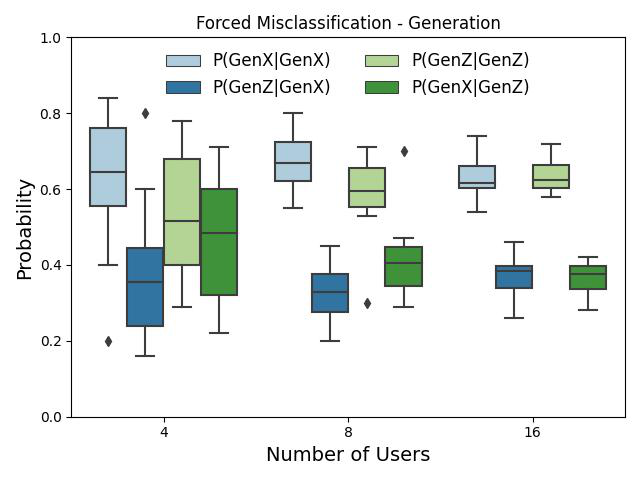
Fig 6: Boxplots of displaying the probability distribu-
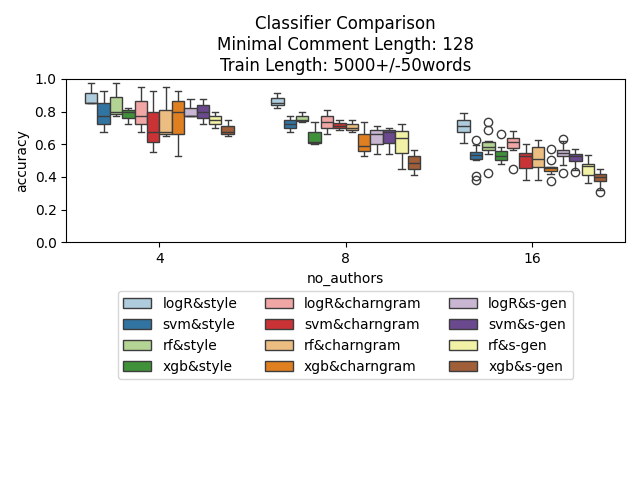
Fig 7: Comparison of classifiers, made with between 4950 and 5050 comments worth of training data. Trained and
Limitations
- The demographic labels are derived from self-declared subreddit flairs, which can be noisy, incomplete, or proxy variables rather than verified ground truth.
- The linguistic and cultural homogeneity of the Reddit user base may limit generalizability to other social media platforms or domains.
- Forced misclassification setting is artificial, removing the true author; real-world open-world scenarios where authors are unknown but not removed might yield different behavior.
- The classifiers considered (primarily Logistic Regression on writeprints features) are relatively simple compared to transformer-based or deep learning methods; fairness properties could differ with other models.
- No explicit evaluation of adversarial attempts to obfuscate writing style to evade authorship attribution or fairness attacks.
- No public release of code or datasets mentioned, limiting reproducibility and external validation.
Open questions / follow-ons
- How do more advanced machine learning models (e.g., transformers) impact demographic bias in authorship attribution under closed- and open-world conditions?
- Can adversarial writing style obfuscation techniques be designed to mitigate demographic bias or protect anonymity without unduly harming attribution accuracy?
- How do these findings generalize to other languages, platforms, or longer temporal spans with evolving writing styles?
- What are the implications for deploying authorship attribution tools in real-world moderation systems with respect to user privacy and fairness guarantees?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this research illuminates fairness risks in stylometric authorship attribution systems used for identity linking, such as sockpuppet detection or malicious account clustering. Although closed-world evaluations may suggest equitable performance across demographics, real-world error scenarios where the true author is unknown can induce demographic biases, leading to disproportionate false attributions that correlate with user demographics. This calls for caution in relying on authorship attribution as a definitive signal in automated account linking or bot detection pipelines.
The paper's forced misclassification methodology provides a framework that CAPTCHA engineers can apply to audit demographic biases in text-based classifiers integrated into anti-fraud or bot-detection systems. It highlights the importance of evaluating model fairness not only on overall accuracy but also on the characteristics of errors, especially under open-world or adversarial conditions. Understanding these biases can help inform risk scoring, user impact assessments, and defenses to mitigate unfair differential exposure to false accusations or deanonymization.
Cite
@article{arxiv2510_19708,
title={ Unfair Mistakes on Social Media: How Demographic Characteristics influence Authorship Attribution },
author={ Jasmin Wyss and Rebekah Overdorf },
journal={arXiv preprint arXiv:2510.19708},
year={ 2025 },
url={https://arxiv.org/abs/2510.19708}
}