
Cross-dataset Multivariate Time-series Model for Parkinson's Diagnosis via Keyboard Dynamics
Source: arXiv:2510.15950 · Published 2025-10-10 · By Arianna Francesconi, Donato Cappetta, Fabio Rebecchi, Paolo Soda, Valerio Guarrasi, Rosa Sicilia
TL;DR
This paper addresses the challenge of early, non-invasive diagnosis of Parkinson's disease (PD) using keystroke dynamics (KD) as a digital biomarker. Traditional clinical diagnosis is hampered by late emergence of motor symptoms and subjective neuropsychological tests, motivating scalable AI-based analysis of everyday typing behavior. The authors present a novel, cross-dataset pipeline analyzing four temporal keystroke signals (Hold Time, Flight Time, Press-Press, Release-Release) collected across four heterogeneous public datasets varying in size, typing task (free vs fixed text), and acquisition context (clinic vs wild). They extensively benchmark eight state-of-the-art deep learning architectures spanning recurrent, convolutional, hybrid, and transformer models. The pipeline uses a three-stage process of: (i) dataset-specific preprocessing and addressing class imbalance via comparison of three techniques including a novel ensemble undersampling method called IMBALMED; (ii) pre-training models on the two largest datasets separately; and (iii) fine-tuning on an intermediate-sized set before external validation on the smallest independent cohort. Results demonstrate robust generalization across data sources with top models reaching over 91% AUC-ROC on the external set—a notable improvement over prior PD KD work that mostly lacked cross-dataset validation. Hybrid convolutional-recurrent and temporal convolutional models showed strongest performance, and the ensemble-based imbalance method proved beneficial on larger samples. This study validates KD as a promising scalable biomarker for early PD screening and telemonitoring beyond lab environments.
Key findings
- Temporal Convolutional Network (TCN) model achieved 91.14% AUC-ROC and 79.39% F1-Score on external validation dataset (DB1).
- Hybrid recurrent-convolutional models (e.g., LSTM-FCN) consistently outperformed pure RNN or CNN models on internal and external datasets.
- IMBALMED ensemble-based class balancing outperformed random undersampling and unbalanced baseline on larger fixed-text dataset DB4, improving AUC-ROC from ~67% to over 73%.
- Pre-training on large fixed-text dataset DB4 followed by fine-tuning on free-text dataset DB2 yielded better transfer performance (AUC-ROC up to ~89%) than pre-training on free-text DB3 (AUC-ROC up to ~66%).
- Early stopping with a patience of 5 epochs and focal loss led to better model convergence than no patience or longer patience and binary cross-entropy loss.
- Transformer-based models (TSTPlus) initially underperformed but gained substantial performance (up to 90.59% AUC-ROC externally) after fine-tuning.
- Window size and stride hyperparameters differed by dataset and architecture, e.g., shorter windows for free-text noisy data, longer windows for fixed-text structured tasks.
- External validation on DB1 was performed on the smallest dataset, emphasizing generalization capability to independent, clinically acquired data.
Threat model
n/a — This work is focused on machine learning methodology for medical diagnosis rather than security threat models. No adversarial attacks or data poisoning scenarios are considered.
Methodology — deep read
Threat Model & Assumptions: The adversary in this context is not explicit in terms of security threats but can be viewed as data variability and distributional shift across heterogeneous datasets reflecting real-world diverse typing behaviors. The model assumes access only to keystroke timing signals and no invasive clinical data, aiming to generalize across typing contexts and devices. No adversarial attack evaluation was performed.
Data: Four public datasets used — TyPD (33 subjects), neuroQWERTY MIT-CSXPD (85), Tappy (103), and Online English (230). Each dataset contains keystroke signals HT, FT, PP, RR with varying task types (free vs fixed text) and acquisition contexts (clinic vs wild). Data preprocessing involved signal extraction, outlier removal for fixed-text data, segmentation into sessions, and on-the-fly windowing to create time-series samples. Due to class imbalance (often fewer PD than controls), three balancing strategies were compared: unbalanced baseline, random undersampling, and IMBALMED ensemble undersampling.
Architecture / Algorithm: Eight DL architectures from the tsai time-series library were benchmarked: GRU, LSTM (pure RNNs); GRU-FCN, LSTM-FCN (hybrid RNN + CNN); Temporal Convolutional Network (TCN), Explainable CNN (XCM) (pure CNNs); and two transformer variants (TSiT, TSTPlus). Inputs were multivariate time-series windows of keystroke signals. Models output binary PD/non-PD predictions via sigmoid activation. Loss functions tested included binary cross-entropy and focal loss, the latter to mitigate class imbalance.
Training Regime: Pre-training on largest datasets (DB3 and DB4) was done independently for each dataset and model with early stopping (patience of 5 epochs) and focal loss yielding best results. Hyperparameters (window size, stride, learning rate, batch size) were optimized sequentially. Pre-training used a leave-20%-subjects-out (approx. 10-fold) cross-validation.
Fine-tuning involved training on DB2 (intermediate size), adapting pre-trained weights with a lower learning rate and two weight freezing strategies: fully trainable or freezing all but last layer. Validation 10-fold cross-validation was used to select best model checkpoint.
Evaluation Protocol: Metrics were AUC-ROC and F1-Score computed at the patient level by aggregating window predictions. External validation was performed on DB1, the smallest dataset, previously unseen during training or fine-tuning, to measure model generalization across independent cohorts. Comparisons across balancing techniques and architectures were performed within datasets.
Reproducibility: The paper mentions use of kbtsai library and prior published datasets that are public. Code release status is not explicitly stated. Details on random seed handling or frozen weights beyond fine-tuning strategies are not specified. Overall, the methodology is well-documented to enable replication with the same datasets and architectures.
Concrete end-to-end example: The best setting uses the fixed-text largest dataset DB4 for pre-training the TCN model with focal loss, early stopping patience 5, IMBALMED balancing, 60-keystroke windows with 20-keystroke stride. This model is then fine-tuned on free-text DB2 at a reduced learning rate with all weights trainable, selected via 10-fold CV using AUC-ROC. The trained model is finally tested in external validation on DB1, producing 91.14% AUC-ROC and 79.39% F1-Score, confirming strong generalization across text conditions and datasets.
Technical innovations
- Application of a cross-dataset pipeline leveraging multiple heterogeneous public keystroke datasets with diverse typing tasks and acquisition contexts.
- Extensive benchmarking of eight state-of-the-art deep learning architectures for multivariate time-series modeling of keystroke signals in PD detection.
- Use and comparative analysis of three class imbalance strategies, notably introducing IMBALMED ensemble undersampling, which generates diverse sub-datasets to improve model robustness.
- A pre-training on large fixed-text data followed by fine-tuning on intermediate free-text data and external validation on independent clinic data, demonstrating strong cross-protocol transfer learning.
- Hyperparameter tuning tailored per dataset and model architecture to optimize temporal windowing strategies for variable typing environments.
Datasets
- TyPD — 33 participants — public
- neuroQWERTY MIT-CSXPD — 85 participants — public
- Tappy — 103 participants — public
- Online English — 230 participants — public
Baselines vs proposed
- Unbalanced baseline on DB4: Highest AUC-ROC around 67% (e.g., GRU-FCN 67.63%) vs IMBALMED: 75.47% (GRU-FCN)
- Pre-training on DB3/DB4 with IMBALMED and fine-tuned on DB2: AUC-ROC for LSTM-FCN rises from ~40% (DB3 pretrain) to 88.94% (DB4 pretrain)
- External validation on DB1 after fine-tuning: TCN AUC-ROC 91.14% vs pre-training only 81.85%
- Transformer TSTPlus improves from 62.75% to 90.59% AUC-ROC after fine-tuning on DB2 in external validation
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2510.15950.
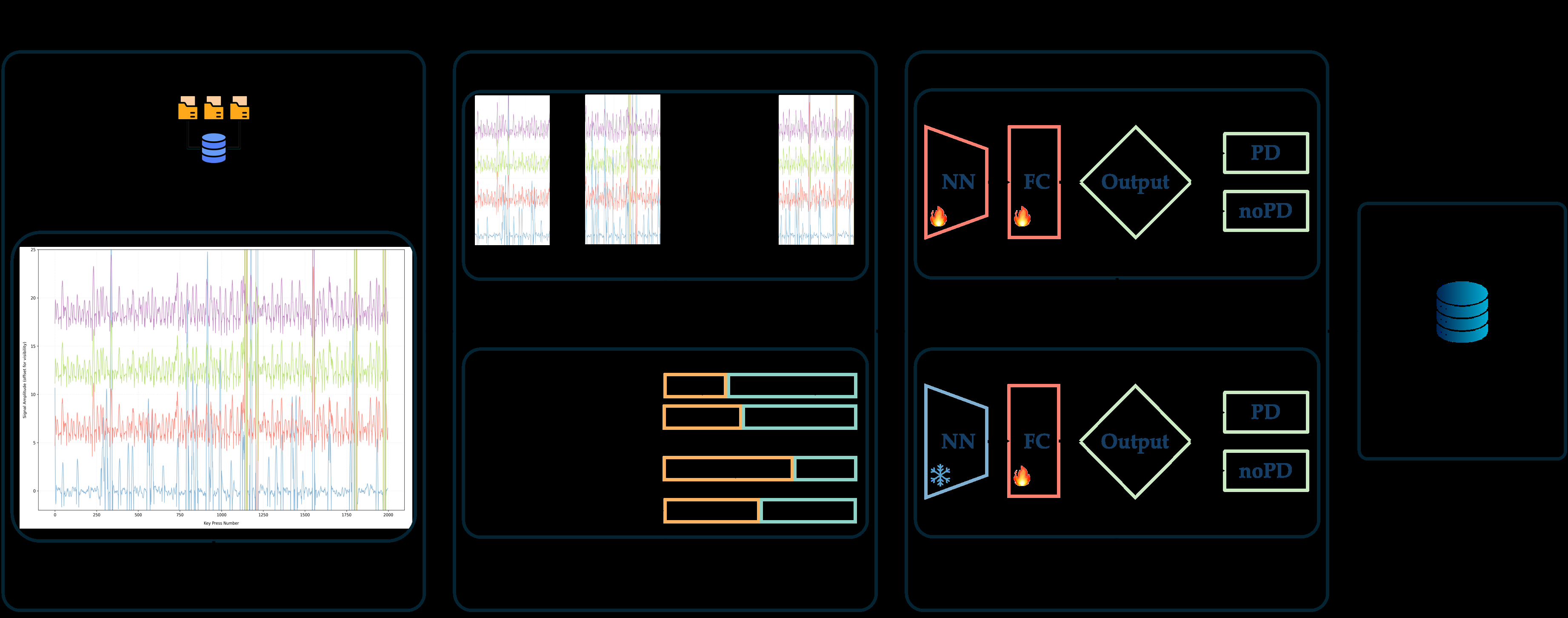
Fig 1: Schematic representation of the proposed method, comprising four steps:
Limitations
- External validation was limited to the smallest dataset with fixed-text protocol, limiting assessment of wider generalizability.
- No adversarial or real-world attack robustness testing was performed; robustness beyond distributional shifts unknown.
- The impact of demographic or clinical variability in PD severity/stage on model performance was not explored.
- Code release and full reproducibility details are not explicitly provided, which may challenge independent verification.
- Data augmentation or generative approaches for handling data scarcity or imbalance were not assessed beyond undersampling strategies.
- Evaluation focused on keystroke timing signals; integration with other modalities like accelerometry or voice was proposed but not implemented.
Open questions / follow-ons
- How do models perform on larger and more diverse populations with varying PD stages and comorbidities?
- Can multi-modal inputs (combining keystroke dynamics with accelerometer or voice data) improve early PD detection further?
- What explainability techniques best reveal model decision logic and biomarkers to clinicians?
- How robust are the models to deliberate adversarial perturbations or noisy/erroneous input data?
Why it matters for bot defense
Bot-defense and CAPTCHA practitioners can draw insights from this work on modeling multivariate time-series behavioral biometrics across heterogeneous data sources with class imbalance—an ongoing challenge in bot detection. The demonstrated benefit of pre-training on large diverse datasets then fine-tuning for target domains parallels transfer learning strategies common in bot detection when labeled data scarcity exists in new attack scenarios. The analysis of balancing strategies like IMBALMED to handle skewed class distributions may inform defenses when genuine user data vastly outnumber bots, helping maintain high detection sensitivity without overfitting majority class patterns. Additionally, the robust external validation protocol highlights the importance of testing bot-defense models on truly independent datasets covering varied contexts, a best practice often overlooked in CAPTCHA and behavioral biometrics research. While keystroke timing for PD diagnosis differs in objective from bot detection, the underlying challenges of temporal feature extraction, time-series modeling, and domain generalization provide potentially transferable methodologies. However, considerations around security adversaries such as adversarial attacks, data poisoning, or adaptive spoofing remain open in the bot-defense space unlike here.
Cite
@article{arxiv2510_15950,
title={ Cross-dataset Multivariate Time-series Model for Parkinson's Diagnosis via Keyboard Dynamics },
author={ Arianna Francesconi and Donato Cappetta and Fabio Rebecchi and Paolo Soda and Valerio Guarrasi and Rosa Sicilia },
journal={arXiv preprint arXiv:2510.15950},
year={ 2025 },
url={https://arxiv.org/abs/2510.15950}
}