
Reasoning under Vision: Understanding Visual-Spatial Cognition in Vision-Language Models for CAPTCHA
Source: arXiv:2510.06067 · Published 2025-10-07 · By Python Song, Luke Tenyi Chang, Yun-Yun Tsai, Penghui Li, Junfeng Yang
TL;DR
This paper addresses the challenge of solving modern CAPTCHAs, which have evolved from simple text recognition tasks into complex visual-spatial puzzles requiring multi-step reasoning and spatial cognition. The authors identify a critical gap in current commercial vision-language models (VLMs) that perform poorly on such tasks, achieving only about 15.7% accuracy without explicit reasoning. They propose that step-by-step reasoning is essential to improve model performance. To systematically study this, they introduce CAPTCHA-X, the first large-scale real-world CAPTCHA benchmark annotated with detailed reasoning steps, mouse actions, and region-level grounding across seven CAPTCHA categories. They define new reasoning-oriented metrics for comprehensive evaluation and develop a reasoning-centered agentic VLM pipeline that decouples grid-based and non-grid CAPTCHA solving with reasoning modules validated by a discriminator. Experimental results reveal that integrating reasoning boosts average solving accuracy by over 38% relative to non-reasoning baselines, reaching a state-of-the-art 83.9% average accuracy on CAPTCHA-X. The paper further characterizes empirical "Reasoning Scaling Laws" linking reasoning complexity, efficiency, and task difficulty. Failure mode analysis and modular agent design address logical, mapping, and grounding errors. Overall, the work establishes reasoning as the key missing ingredient for current VLMs to effectively solve challenging visual CAPTCHAs and provides a robust benchmark and evaluation framework to advance research in this domain.
Key findings
- Commercial VLMs without reasoning achieve low solving accuracy (average ∼15.7%) on high-difficulty CAPTCHAs.
- Introducing step-by-step reasoning improves model accuracy by an average of 38.75% (p < 0.001), raising accuracy from 15.7% to approximately 54.5%.
- The reasoning-centered agentic pipeline achieves 83.9% average accuracy across seven CAPTCHA types, outperforming state-of-the-art baselines on five tasks.
- Models with reasoning produce 14.6% lower average spatial localization error (L2 distance) compared to non-reasoning counterparts.
- Strong negative correlation (R2=0.97, p<0.001) between accuracy and L2 distance confirms L2 is a valid spatial grounding metric.
- Empirical Reasoning Scaling Laws demonstrate linear relationships between reasoning score, length, trajectory complexity, and accuracy, and a power law relationship between reasoning efficiency and accuracy (R2=0.828, p<0.01).
- More difficult CAPTCHA types yield larger relative accuracy gains from reasoning, with Spearman ρ=0.93 (p=0.0025), confirming reasoning's increasing impact on harder tasks.
- The agentic pipeline mitigates failure modes such as logical errors, grid mapping errors, and grounding errors via discriminator filtering and expert modules.
Threat model
The adversary is a vision-language model operating in a zero-shot black-box API scenario aiming to solve CAPTCHAs by generating solution mouse coordinates. The model has access to static CAPTCHA images and can generate reasoning steps and actions but cannot interact with the CAPTCHA environment dynamically or modify the CAPTCHA generation. The adversary cannot perform manual human intervention or retraining with CAPTCHA-specific supervision. The threat is posed by automated solvers attempting to bypass CAPTCHA security via enhanced reasoning.
Methodology — deep read
Threat Model & Assumptions: The adversary model is implicit as evaluating CAPTCHA-solving capabilities of AI VLMs. The paper simulates zero-shot attacks by applying commercial VLMs and their own agentic pipeline with no fine-tuning on CAPTCHA tasks. Assumptions include availability of static CAPTCHA images and black-box API access to VLMs. It does not consider adversarial manipulation or direct CAPTCHA bypass techniques.
Data Collection and Processing: CAPTCHA-X dataset is collected via automated interaction with real-world CAPTCHA websites using Selenium and PyAutoGUI. It contains 1,839 CAPTCHA puzzles from seven categories (Gobang, Hcaptcha, Icon, Iconcrush, Recaptcha, Space Reasoning, VTT). For each puzzle, they record mouse action sequences and screenshots before and after solving. Reasoning steps are generated by prompting a GPT-5 LLM with carefully designed, goal-directed, vision-language-aware prompts. Human experts (four) verify and score reasoning quality, resolving disagreements. Ground-truth click acceptance regions are manually defined per puzzle to allow more reliable correctness evaluation beyond fixed distance thresholds.
Architecture & Algorithm: The core model is an agentic pipeline designed to operationalize reasoning into executable actions. A Category Judger routes puzzles into grid-based or non-grid-based branches. For grid-based puzzles (e.g., Gobang), a Mapping Expert (LLM) converts the puzzle into a symbolic grid representation. A Reasoning Steps Generator produces step-by-step symbolic reasoning over this grid. For non-grid puzzles, reasoning is grounded spatially using a Spatial Understanding Expert. A Discriminator module validates logical consistency of generated reasoning before passing to an Action Generator that produces final mouse click coordinates for execution.
Training Regime: This is a zero-shot evaluation using off-the-shelf commercial VLMs (Gemini-2.5-Pro, GPT-4O, GPT-O3, Claude-4-Opus, etc.). The authors fix API random seeds and temperature (seed=41, temp=0) for reproducibility. No fine-tuning or supervised training is performed on CAPTCHA-X; instead, prompt design and agentic pipeline orchestrate reasoning and action generation.
Evaluation Protocol: They evaluate models on seven CAPTCHA types using sequence-level action accuracy (exact ordered match between predicted and ground-truth action coordinates within acceptance regions). They also measure spatial grounding quality by computing average L2 distances between predicted and ground-truth click coordinates. Multiple reasoning metrics are defined: reasoning steps count, reasoning text length (tokens), reasoning efficiency (accuracy divided by normalized length and steps), trajectory complexity index (linguistic backtracking and symbolic markers), and human expert reasoning score graded 0-10. Statistical significance is measured via McNemar’s test for accuracy and Wilcoxon signed-rank test for L2 distances. Regression and correlation analyses establish Reasoning Scaling Laws linking task difficulty, reasoning complexity, and accuracy. Human baseline performance (20 subjects) is recorded using identical UI.
Reproducibility: The CAPTCHA-X dataset will be released with anonymized images and reasoning-step annotations, but interaction scripts or website-specific metadata are withheld to avoid misuse. Code or model weights for the agentic pipeline are not explicitly stated as released. The zero-shot evaluation on commercial closed APIs provides a reproducible benchmark to compare future methods.
Concrete example: To solve a Gobang CAPTCHA, the model first passes through the Category Judger identifying it as grid-based. The Mapping Expert converts the image into a symbolic 5x5 grid. The Reasoning Steps Generator generates step-by-step inference in symbolic form (e.g., identify open spots, anticipate opponent moves). The Discriminator validates this reasoning. The Action Generator translates the reasoning to target cell coordinates. The Action Executor simulates mouse clicks at those coordinates, which are then scored for exact sequence match and spatial accuracy against annotated acceptance regions. This modular reasoning-execution pipeline significantly outperforms direct coordinate regression baseline.
Technical innovations
- Introduction of CAPTCHA-X, the first real-world CAPTCHA benchmark providing detailed reasoning steps, mouse actions, and region-level grounding annotations.
- Definition of five novel reasoning-oriented evaluation metrics including reasoning steps, reasoning length, reasoning efficiency, trajectory complexity index, and human expert reasoning score.
- Development of a reasoning-centered agentic VLM pipeline that explicitly separates grid-based and spatial reasoning branches, incorporates a discriminator for logic validation, and grounds reasoning into executable click actions.
- Empirical discovery of multiple Reasoning Scaling Laws linking reasoning complexity, efficiency, task difficulty, and accuracy on CAPTCHA solving.
Datasets
- CAPTCHA-X — 1,839 puzzles — Collected from real-world CAPTCHA websites with expert-verified reasoning and grounding annotations
Baselines vs proposed
- Gemini-2.5-Pro without reasoning: average accuracy ranges approximately 46-81% on CAPTCHA types; with reasoning: accuracy improves by ~10-20% per category.
- GPT-4O without reasoning: average accuracy ranges 0-47%; with reasoning: improves to around 7-47%.
- Other commercial models (Claude-4-Opus, GPT-O3) exhibit low baseline performance (0-29%) without reasoning and significant gains catalyzed by reasoning.
- Agentic pipeline (Captcha-X-Agent-2.5-Pro) outperforms all baselines, achieving 83.9% average accuracy across seven CAPTCHA types.
- Open domain tests on out-of-distribution CAPTCHAs show 100% accuracy on Geometry, 85% on Click Order, and 90% on Animal types, compared to prior best of 40%.
- Relative gain from reasoning correlates strongly with CAPTCHA difficulty, confirming reasoning's impact is greater on harder tasks.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2510.06067.
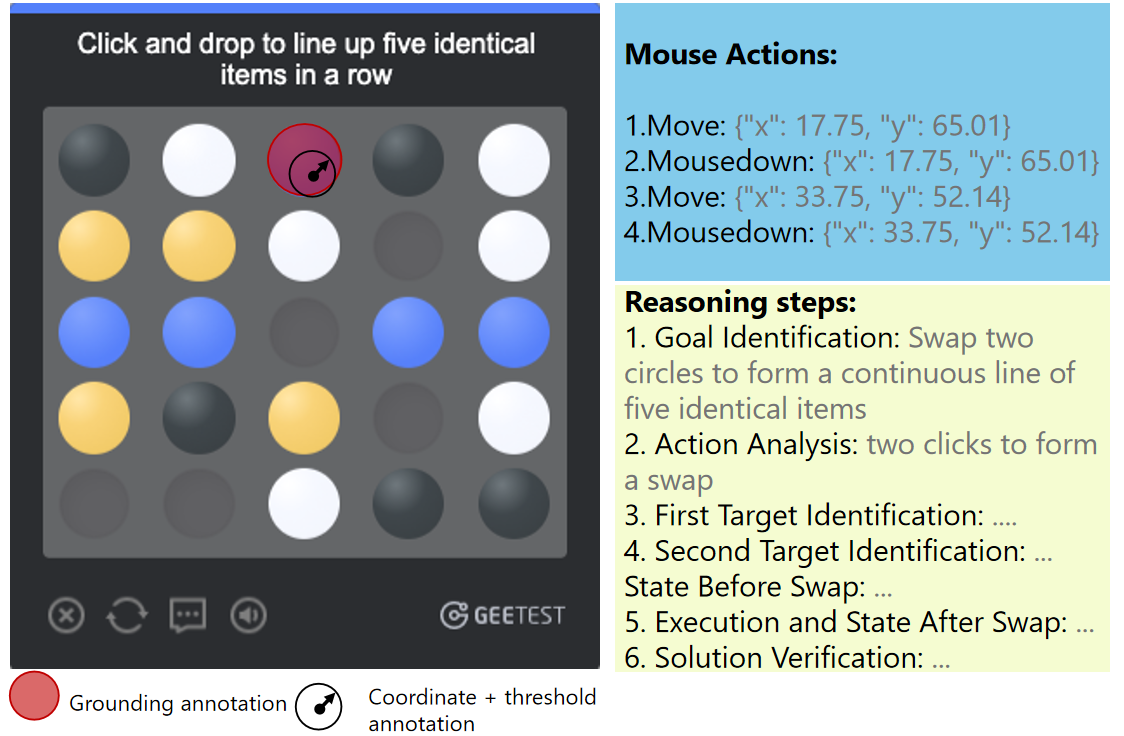
Fig 1: Grounding annotation (red) versus threshold-based an-
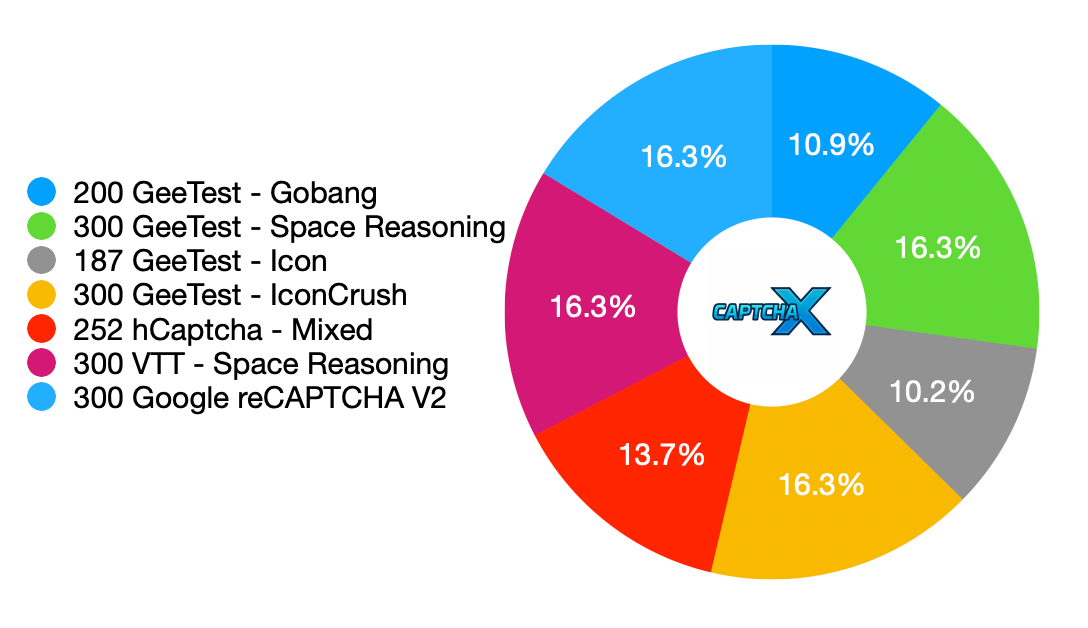
Fig 2: Distribution of our benchmark.
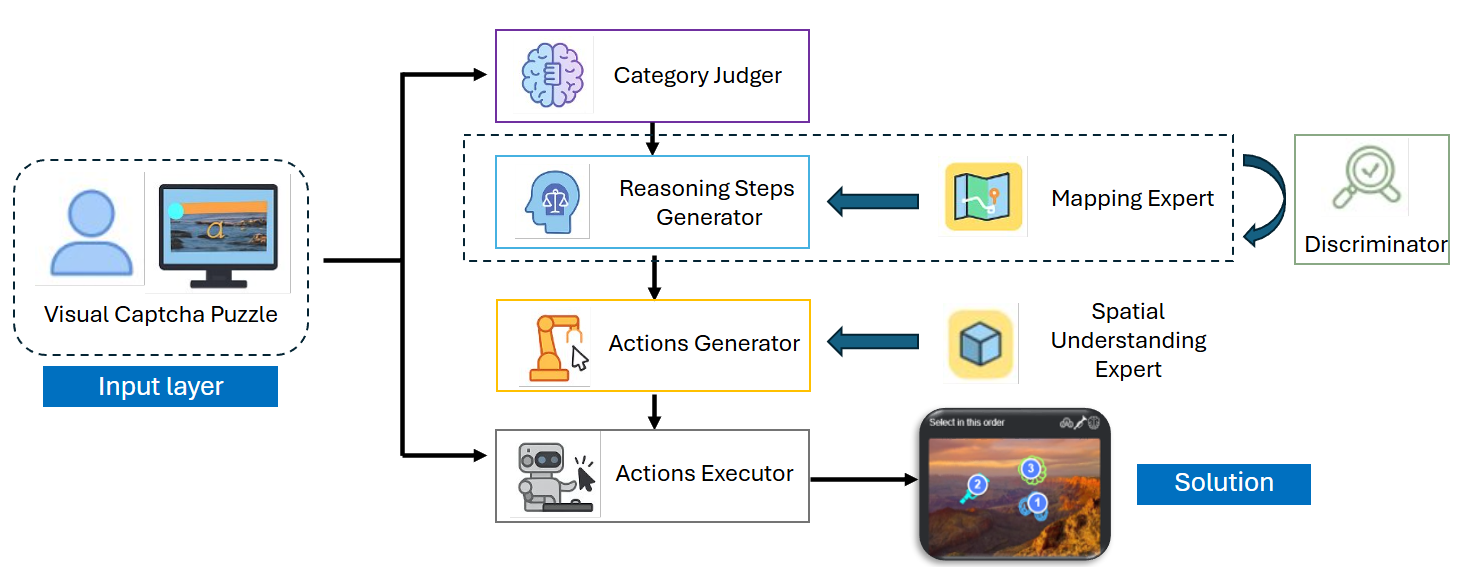
Fig 3: Our Agentic Vision-Language Model Pipeline.
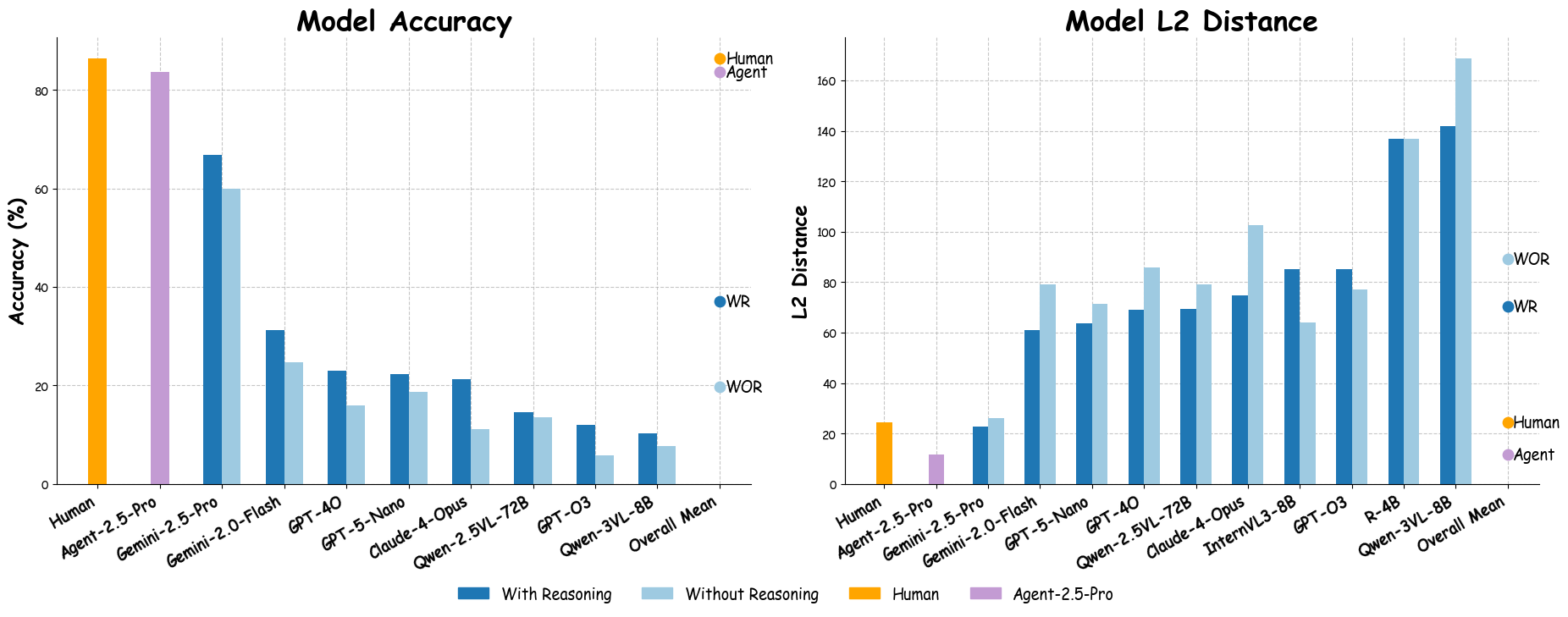
Fig 5: presents the
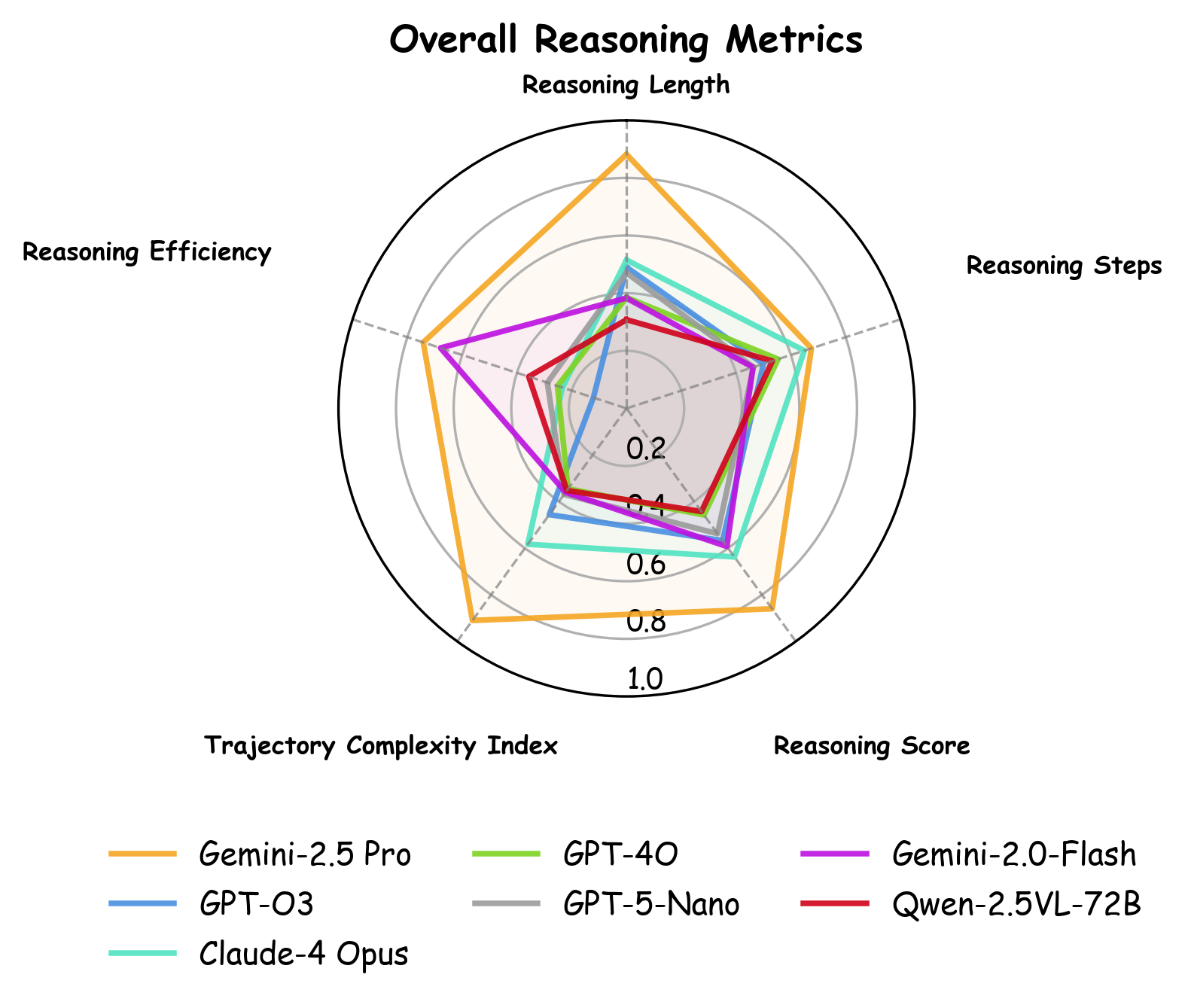
Fig 6: Reasoning Scaling Law.
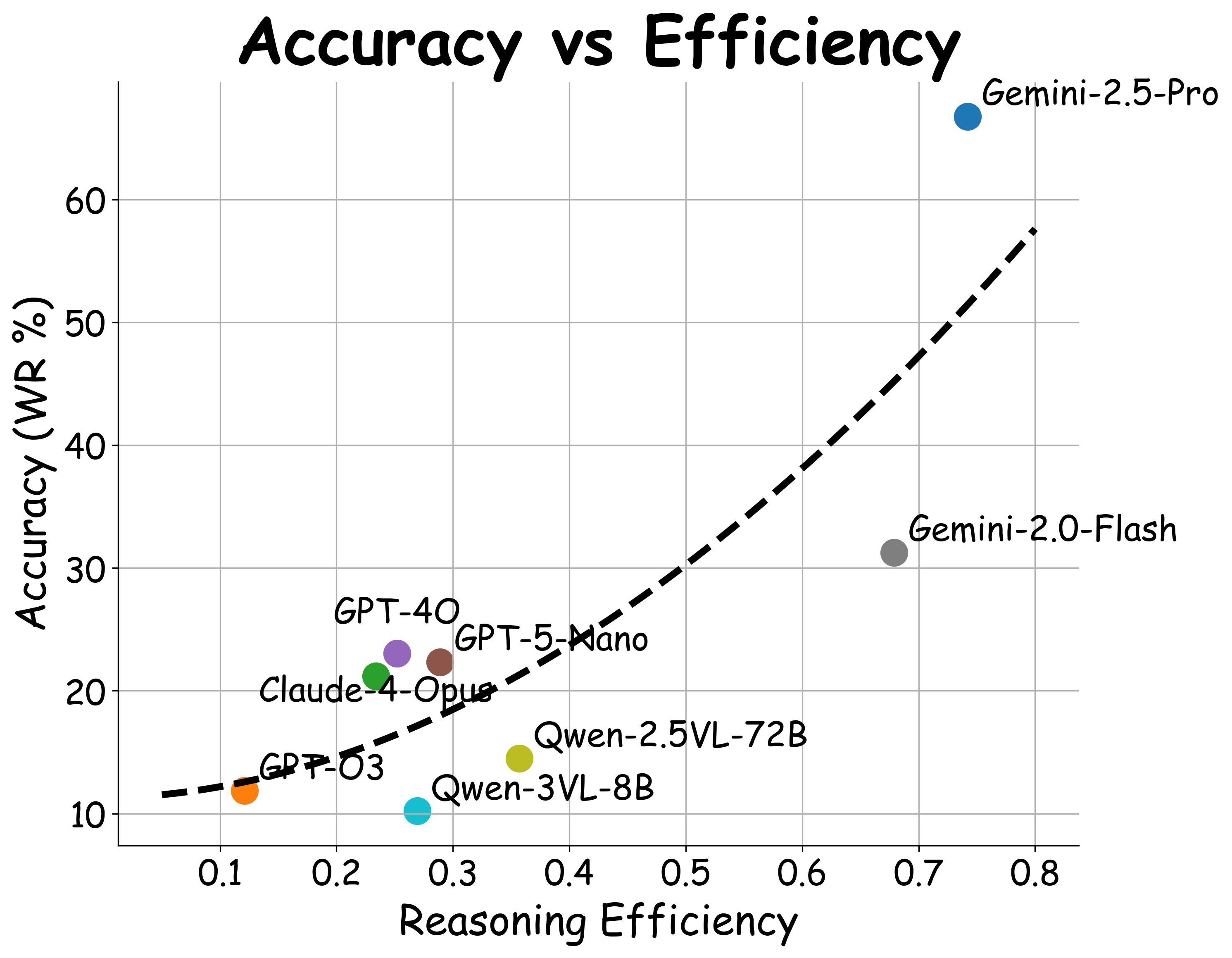
Fig 4: Model Accuracy and L2 Distance with and without reasoning. We averaged over multiple evaluation runs to reduce randomness.
Limitations
- The study uses zero-shot evaluations with API-based black-box VLMs but does not explore fine-tuning or end-to-end training tailored to CAPTCHA-X.
- Generated reasoning steps rely primarily on GPT-5 LLM prompting and human expert verification, which may introduce bias or limit diversity in reasoning styles.
- The spatial grounding evaluation depends on manually defined acceptance regions; automated or real-time CAPTCHA solving scenarios remain untested.
- Failure mode analysis identifies logical, mapping, and grounding errors but does not exhaustively quantify their distribution across CAPTCHA types.
- The released CAPTCHA-X dataset excludes interaction scripts and website metadata to mitigate misuse, limiting reproducibility of full end-to-end solving pipelines.
- The adversarial robustness and security implications against adaptive human or bot attackers are not directly evaluated.
Open questions / follow-ons
- How can the reasoning-centered agent be integrated with fine-tuning or multitask learning to further improve solving accuracy and generalization?
- What are effective methods to detect and mitigate grounded reasoning errors, especially in more complex or 3D CAPTCHA formats?
- How does the reasoning pipeline behave under adversarial CAPTCHAs designed to confound logical chains or spatial mappings?
- Can the reasoning scaling laws generalize to other multimodal AI tasks outside CAPTCHA solving, and how can they guide model architecture design?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights that current commercial vision-language models largely fail to solve complex visual CAPTCHAs without explicit reasoning. The CAPTCHA-X benchmark and reasoning-oriented metrics provide a more nuanced evaluation framework beyond solely accuracy or pixel-threshold correctness, enabling detection of subtle spatial reasoning weaknesses. The proposed agentic pipeline illustrates a practical path to incorporate step-by-step interpretable reasoning into VLM-based solvers, which substantially boosts accuracy and spatial grounding quality. However, failure modes related to logic inconsistencies, grid misinterpretations, and grounding errors reveal remaining attack surfaces. Deploying CAPTCHAs that require multi-step spatial reasoning remains a robust defense mechanism, as purely perception-driven AI solvers struggle without reasoning capabilities. Future bot detectors and CAPTCHA designs should consider integrating or probing for reasoning capabilities to better distinguish bots from humans. Additionally, the identified reasoning scaling laws suggest that AI CAPTCHAs can be calibrated in difficulty to amplify reasoning bottlenecks in automated attacks.
Cite
@article{arxiv2510_06067,
title={ Reasoning under Vision: Understanding Visual-Spatial Cognition in Vision-Language Models for CAPTCHA },
author={ Python Song and Luke Tenyi Chang and Yun-Yun Tsai and Penghui Li and Junfeng Yang },
journal={arXiv preprint arXiv:2510.06067},
year={ 2025 },
url={https://arxiv.org/abs/2510.06067}
}