
Spatial CAPTCHA: Generatively Benchmarking Spatial Reasoning for Human-Machine Differentiation
Source: arXiv:2510.03863 · Published 2025-10-04 · By Arina Kharlamova, Bowei He, Chen Ma, Xue Liu
TL;DR
This paper addresses the urgent need for new CAPTCHA designs that remain robust against state-of-the-art multi-modal large language models (MLLMs) that have eroded the effectiveness of traditional CAPTCHAs focused on text or simple 2D image recognition. The authors propose Spatial CAPTCHA, a novel framework that leverages fundamental human strengths in spatial reasoning — including geometric reasoning, perspective-taking, occlusion handling, and mental rotation — which remain challenging for current AI systems. Spatial CAPTCHA procedurally generates dynamic, difficulty-controlled, and verifiably correct instances requiring these spatial reasoning skills. They also release Spatial-CAPTCHA-Bench, an offline benchmark dataset comprising 1050 task instances spanning four categories and three difficulty levels, designed specifically to probe these spatial abilities.
Evaluation of 10 state-of-the-art MLLMs on Spatial-CAPTCHA-Bench shows a large human-AI performance gap with the best model reaching only 31.0% accuracy versus near-perfect (~99.8%) human performance. Furthermore, Spatial CAPTCHA instances are substantially harder for AI than samples from Google reCAPTCHA, demonstrating its potential as a practical bot defense mechanism that exploits a persistent AI weakness. This work provides a theory-grounded CAPTCHA framework and benchmark that enable scalable, auditable, and adaptable human-machine differentiation centered on spatial cognition.
Key findings
- Humans achieve approx. 99.8% pass rate on Spatial-CAPTCHA-Bench while best MLLM achieves 31.0% pass@1 accuracy (Table 2).
- MLLMs perform substantially worse on Spatial-CAPTCHA-Bench than on Google reCAPTCHA benchmark (e.g., Gemini-2.5-Pro 29.0% vs 55.3%), confirming larger human-model gap.
- Spatial CAPTCHA tasks require compositional spatial reasoning steps (e.g., occlusion, mental rotation) that cause MLLMs to fail despite lengthy response times, indicating reasoning rather than speed limits.
- Difficulty stratification in the benchmark correlates with pass@1 accuracy drops from 61.4% (easy) to 12.4% (hard) for models, but only ~3 percentage points for humans, indicating tasks are genuinely harder spatial reasoning challenges.
- MLLM outputs are poorly calibrated: pass@k reliability consistently falls well below pass@k coverage (Figure 3c), meaning models are overconfident yet unreliable on spatial tasks.
- Distractor synthesis produces near-miss plausible answers that force genuine spatial invariant reasoning rather than reliance on superficial cues.
- The procedural generation pipeline enforces soundness, uniqueness, validity, legibility, and spatial necessity using formal task manifests and validation suites.
- Spatial CAPTCHA framework and benchmark data/code are publicly released with reproducible evaluation pipelines and fixed seeds.
Threat model
The adversary is assumed to be an automated attacker deploying state-of-the-art multi-modal large language models and agents capable of advanced vision-language understanding, aiming to solve CAPTCHA challenges to gain unauthorized automated access. They can process static images and text prompts with zero-shot inference but lack embodied, interactive spatial perception or extensive 3D environment simulation. They do not possess perfect 3D semantic reasoning or the embodied cognitive faculties humans have. The attacker cannot manipulate the CAPTCHA generation pipeline or bypass challenge delivery mechanisms, nor do they have oracle access to the CAPTCHA’s internal spatial invariants or solutions.
Methodology — deep read
The authors design Spatial CAPTCHA by formalizing human spatial cognition abilities into invariant-specified task categories: spatial perception/reference systems, orientation/perspective-taking, mental object rotation, and multi-step spatial visualization. Tasks are mathematically anchored to spatial invariants such as rotational congruence and topological relations.
A declarative JSON schema manifests these task invariants, parameterized by input variables with difficulty-controlling knobs (e.g., angles, poses, occlusion levels). Procedural generation samples from these parameter spaces, and a scene generator constructs a candidate 3D world model encoding geometry. Distractors are synthesized by controlled perturbations producing plausible incorrect answers. A validator suite rejects ambiguous/degenerate scenes to guarantee ground-truth correctness and legibility.
The pipeline separates generation into three stages: (1) sampling scene metadata from parametric distributions stratified by difficulty bins; (2) procedural scene construction, distractor synthesis, and rigorous validation of spatial invariants and visual criteria; (3) rendering high-fidelity images (via Blender or VTK) and assembling natural language prompts with candidate answers and correctness labels.
Evaluation uses the Spatial-CAPTCHA-Bench dataset of 1050 tasks balanced across 4 abilities and 3 difficulty levels. They also create a 70-item human evaluation subset. 60 human raters solve items under a 30s limit simulating realistic conditions. Ten state-of-the-art MLLMs (both proprietary, e.g., GPT-4o, Gemini 2.5, Claude, and open models such as LLaMA and Mistral variants) are tested zero-shot without fine-tuning.
Scoring metrics include pass@1 accuracy, pass@k accuracy (k=3), task-level and ability-level analyses, answer time latency, and calibration measures comparing confidence to correctness. Baselines include random guessing and human-level upper bound. The code, generation scripts, and datasets are publicly released with fixed random seeds and evaluation pipelines for reproducibility. Static offline benchmarking contrasts Spatial CAPTCHA with Google reCAPTCHA benchmarks containing 150 samples.
End-to-end, a concrete example follows: A manifest specifying a mental rotation task samples parameters (angles, poses). The scene generator builds a 3D polyhedral structure, distractors are made by rotating parts incorrectly, the validator confirms unique correct answers and clears visual constraints, rendering produces images from different viewpoints, and a prompt with candidate answers is formed. The human or model receives this, selects their answer, and the system logs correctness and response time. This provides operational CAPTCHA instances as well as labeled benchmark data.
Technical innovations
- Formal mapping of cognitive spatial invariants to machine-checkable task manifests enables certifiable CAPTCHA generation targeting robust spatial reasoning.
- Procedural generation pipeline integrating constrained scene synthesis, near-miss distractor creation, and strict validity checks ensures uncontestable ground-truth correctness and human-legible difficulty control.
- Design of a spatial reasoning CAPTCHA benchmark (Spatial-CAPTCHA-Bench) spanning multiple fundamental spatial abilities with stratified difficulty, enabling quantitative diagnostic evaluation of humans vs. MLLMs.
- Demonstration that spatial reasoning tasks expose a persistent capability gap between humans and cutting-edge MLLMs, where accuracy drops drastically as geometric compositional complexity increases.
- Public release of code, generation tools, and benchmark data with complete reproducibility and fix seeds facilitates future research and practical CAPTCHA deployment.
Datasets
- Spatial-CAPTCHA-Bench — 1,050 instances — publicly released on Hugging Face (amoriodi/Spatial-CAPTCHA-bench)
- Spatial-CAPTCHA-Bench (Tiny subset) — 70 instances — human evaluation subset
- reCAPTCHA-Bench — 150 samples — collected from Google reCAPTCHA service
Baselines vs proposed
- Random guessing: pass@1 = 21.4% vs Spatial CAPTCHA best model (o4-mini) pass@1 = 31.0%
- Human-level pass rate = 99.8% vs best MLLM (o4-mini) 31.0% pass@1 on Spatial-CAPTCHA-Bench
- Gemini 2.5 Pro on Spatial-CAPTCHA-Bench pass@1 = 29.0% vs reCAPTCHA benchmark pass@1 = 55.3%
- ChatGPT-4o latest pass@1 = 26.1% vs reCAPTCHA pass@1 = 52.7%
- Claude Sonnet 4 pass@1 = 21.4% vs reCAPTCHA pass@1 = 10.7% (notably harder here)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2510.03863.

Fig 1 (page 1).
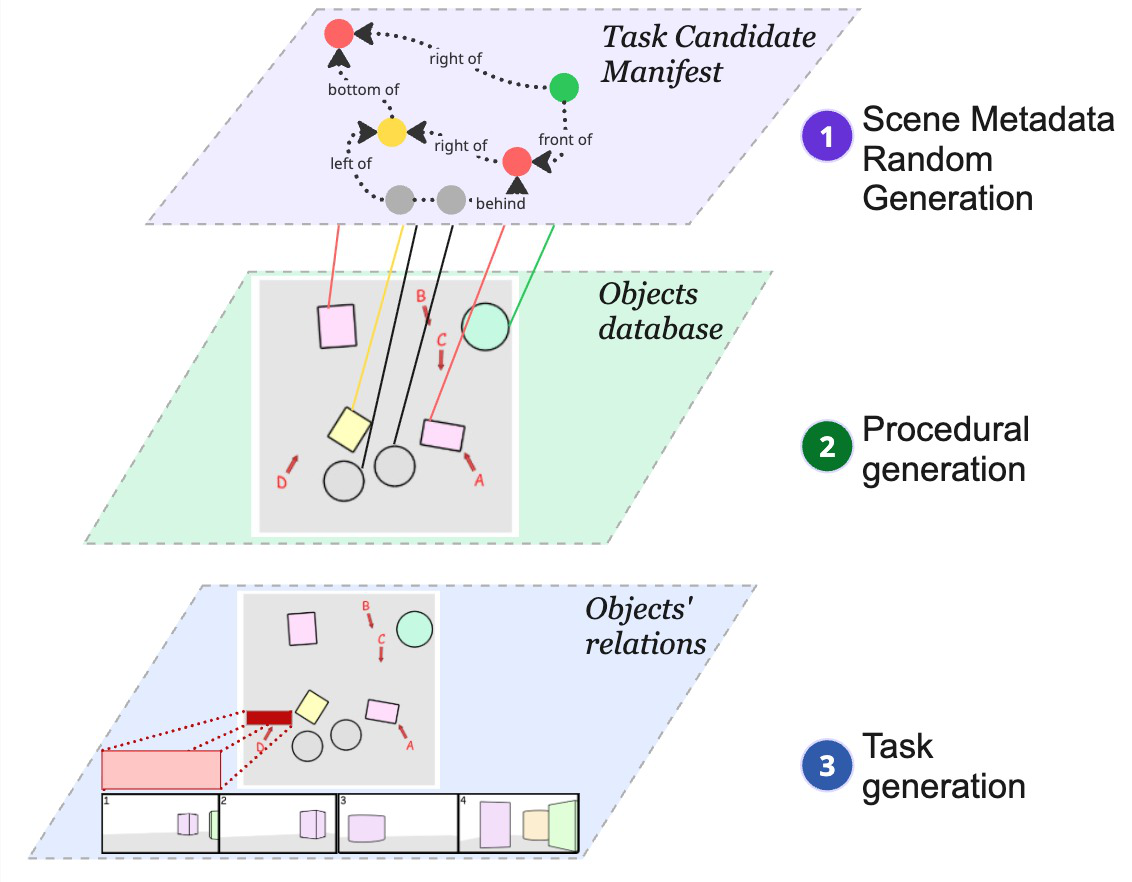
Fig 1: End-to-end synthesis pipeline. Input
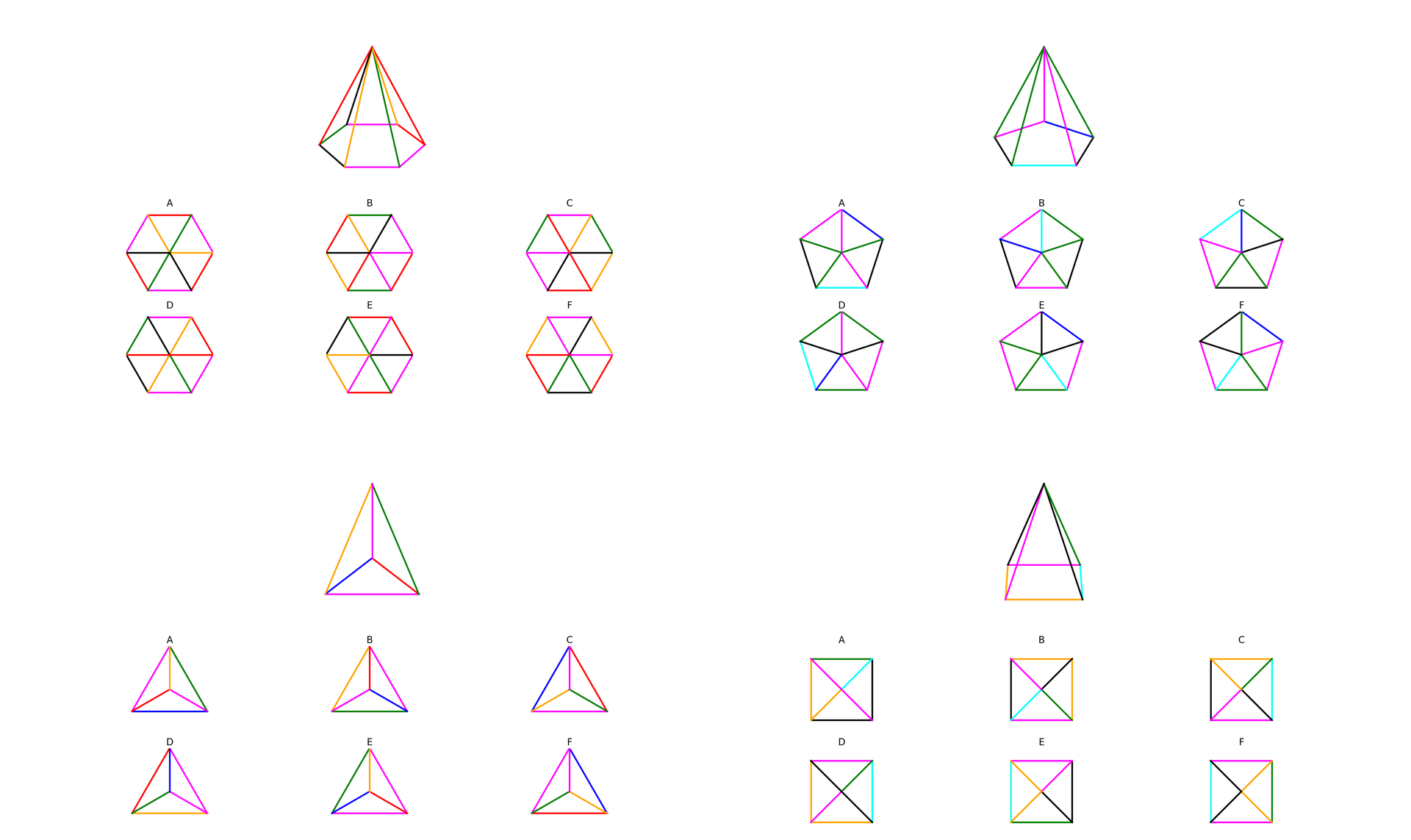
Fig 4: Illustrative examples of tasks targeting Spatial perception and reference system ability.
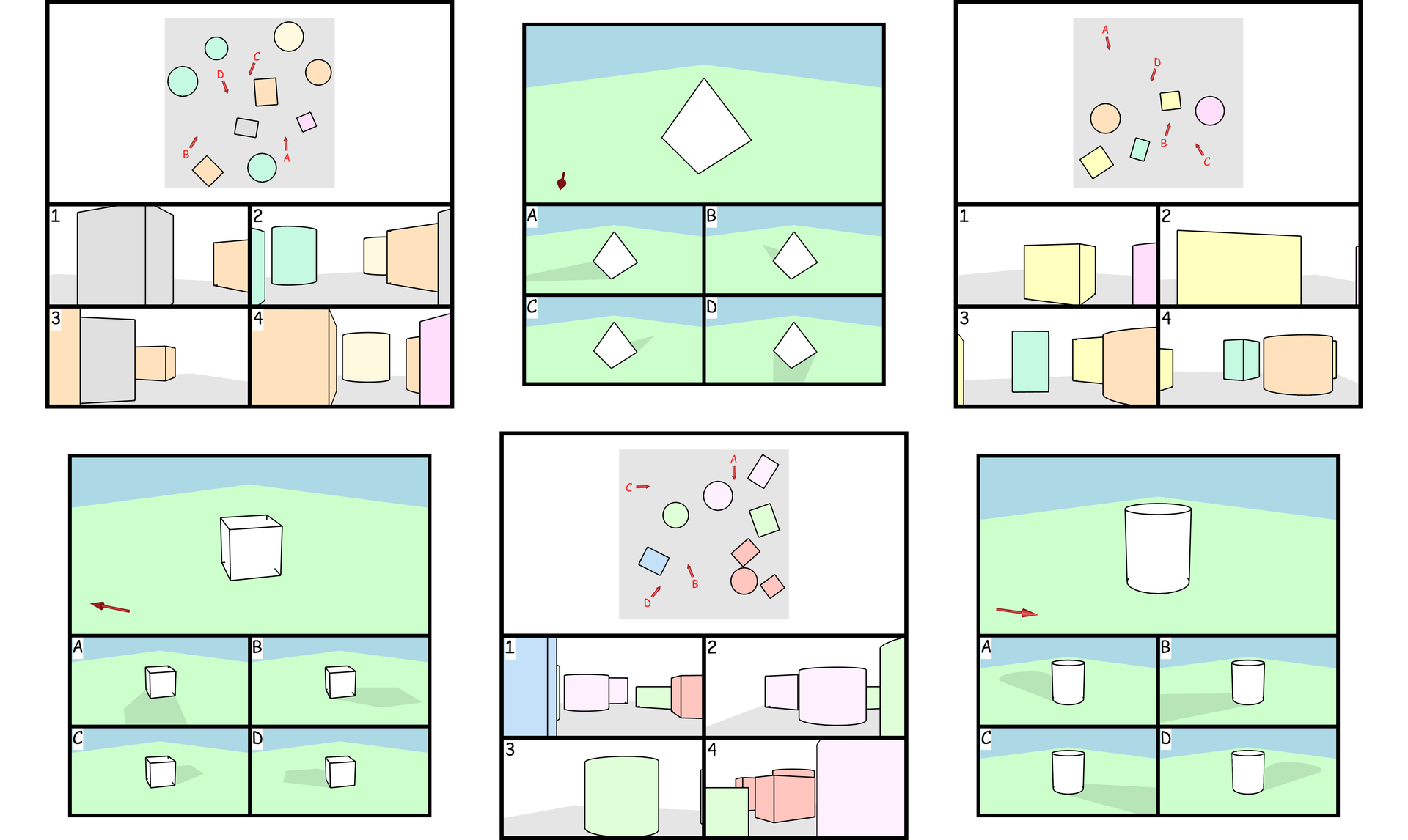
Fig 5: Examples of tasks probing Spatial orientation and perspective-taking. Participants must mentally
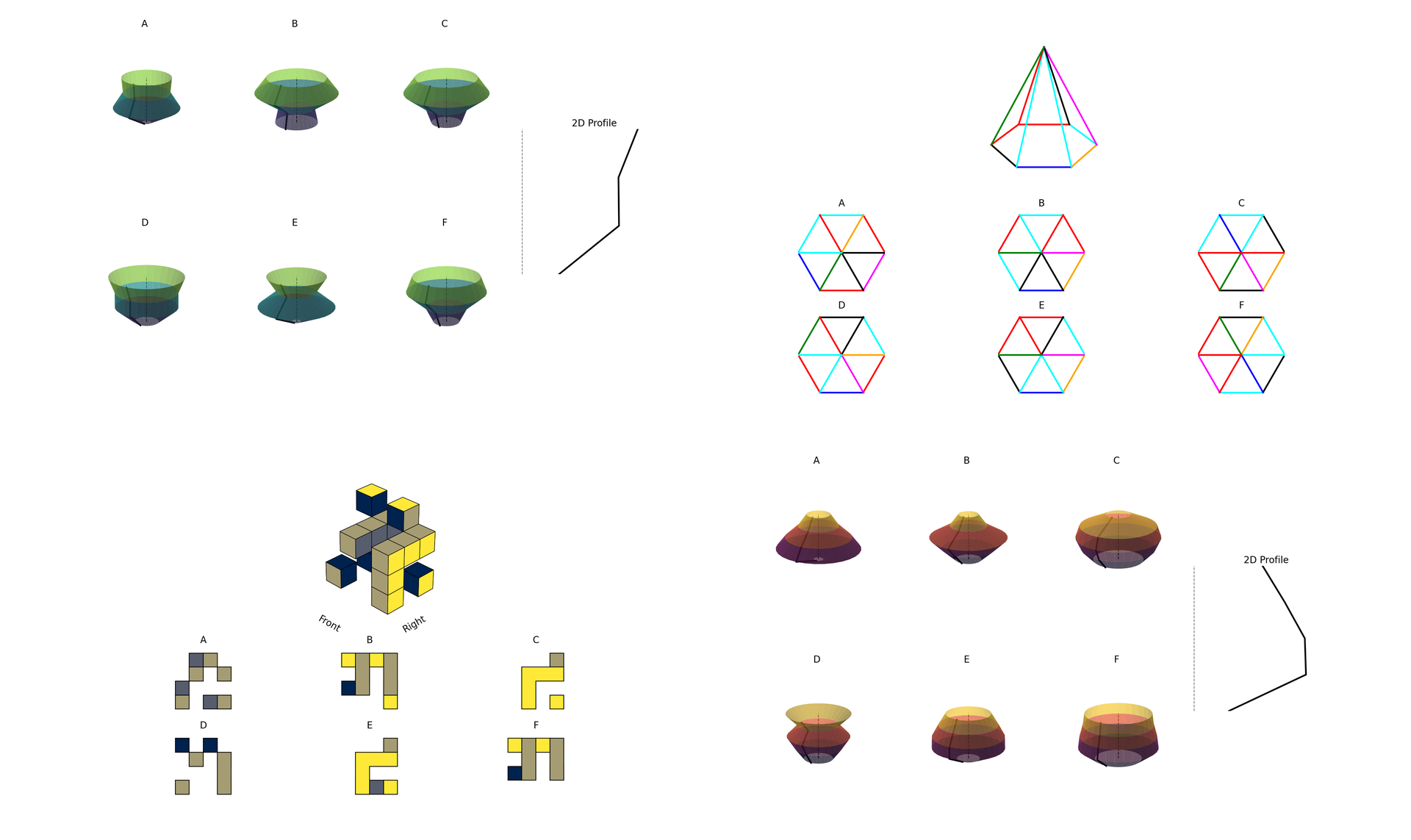
Fig 6: Examples of tasks engaging the Mental objects rotation ability. The settings include polyhedral
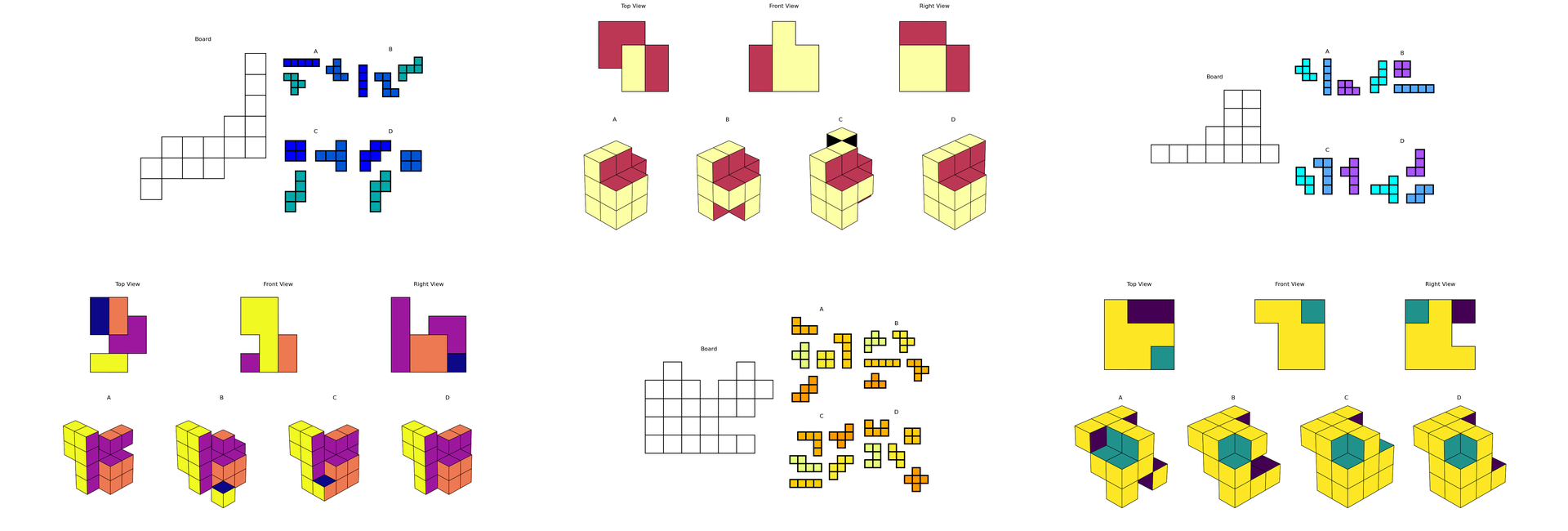
Fig 7: Examples of tasks engaging the spatial visualization ability involving multiple transformations.
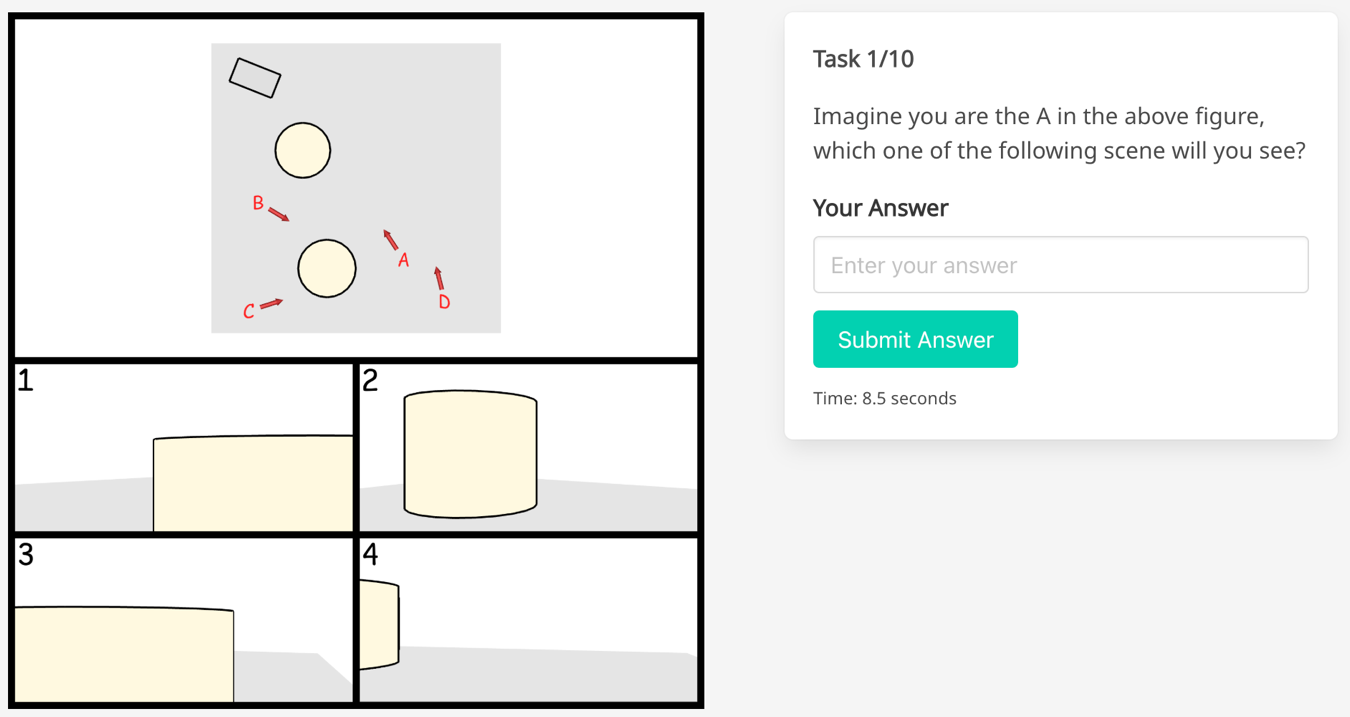
Fig 8: Illustration of the agent sight task of our online spatial CAPTCHA service: (a) we provide difficulty
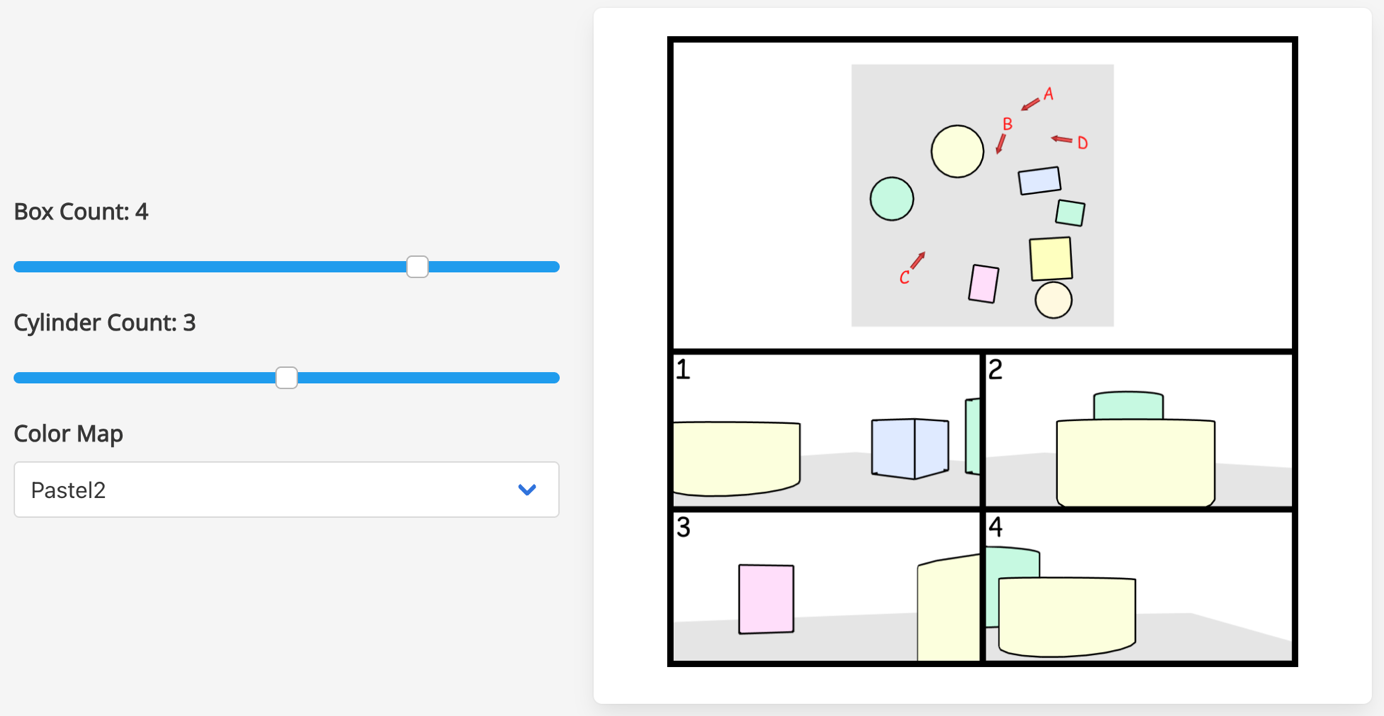
Fig 8 (page 24).
Limitations
- Evaluations used zero-shot MLLM settings without chain-of-thought prompting or fine-tuning, so stronger prompting strategies might improve performance.
- Human evaluation used a small 70-item Tiny subset under time constraints; broader real-world user testing remains to be done.
- The benchmark tests only static spatial reasoning with rendered images, lacking interactive or temporal-spatial tasks yet.
- MLLMs evaluated are all current generation circa mid-2025; future models may narrow the gap, requiring continual updates.
- No adversarial attack or adaptive solver experiments were presented to test robustness against intelligent adaptive attackers.
- Rendering pipelines rely on specific engines; visual style differences may affect generalization and durability of CAPTCHA scheme.
Open questions / follow-ons
- Can chain-of-thought prompting, few-shot learning, or multimodal fine-tuning of MLLMs significantly improve their spatial reasoning performance on Spatial CAPTCHA tasks?
- How effective are interactive or dynamic temporal-spatial CAPTCHA formats that require active manipulation of 3D objects in further widening the human-model gap?
- What adversarial strategies can attackers deploy to partially mimic or approximate human spatial reasoning, and how to harden CAPTCHAs against them?
- Can large-scale human annotations gathered via Spatial CAPTCHA be used to train or pretrain MLLMs to reduce their spatial reasoning weaknesses?
Why it matters for bot defense
This work is highly relevant to bot-defense practitioners seeking to future-proof CAPTCHA systems against increasingly capable multi-modal AI attackers. Spatial CAPTCHA leverages a cognitive dimension—fundamental 3D spatial reasoning—that remains a notable blind spot for current state-of-the-art MLLMs. By employing procedurally generated, verifiably correct challenge tasks that go beyond low-level perception to require embodied geometric cognition and perspective taking, it delivers a scalable and auditable CAPTCHA framework. The Spatial-CAPTCHA-Bench dataset enables offline evaluation of CAPTCHA difficulty and AI robustness systematically.
Bot-defense engineers could adopt or extend this approach to generate next-generation CAPTCHAs that resist automated solvers more rigorously than conventional text or 2D-object recognition tasks, thus raising the bar beyond adversarially trained visual pattern classifiers. Moreover, the diagnostic insights into MLLM failure modes around spatial invariant reasoning can inform the continual adaptation and validation of CAPTCHA challenges as AI capabilities evolve. However, operational deployment should consider integrating usability studies and adversarial robustness assessments to balance friction with security.
Cite
@article{arxiv2510_03863,
title={ Spatial CAPTCHA: Generatively Benchmarking Spatial Reasoning for Human-Machine Differentiation },
author={ Arina Kharlamova and Bowei He and Chen Ma and Xue Liu },
journal={arXiv preprint arXiv:2510.03863},
year={ 2025 },
url={https://arxiv.org/abs/2510.03863}
}