
LLM-Enhanced Self-Evolving Reinforcement Learning for Multi-Step E-Commerce Payment Fraud Risk Detection
Source: arXiv:2509.18719 · Published 2025-09-23 · By Bo Qu, Zhurong Wang, Daisuke Yagi, Zhen Xu, Yang Zhao, Yinan Shan et al.
TL;DR
This paper addresses the challenge of multi-stage e-commerce payment fraud detection by reframing the problem as a constrained Markov Decision Process (MDP) and solving it with policy-gradient reinforcement learning. The core innovation is that instead of hand-engineering reward functions — which requires deep domain expertise and repeated manual tuning — the authors use LLMs (Mixtral-8x7B, LLaMa-3-8B, Gemma7B) as automated reward function designers in an evolutionary loop. The LLM iteratively proposes Python reward functions, the RL agent trains on them, performance feedback is sent back to the LLM, and the cycle repeats until convergence or iteration budget exhaustion. This is claimed to be the first application of LLM-driven reward evolution to e-commerce fraud risk rather than robotics or games.
The payment pipeline covered has three stages: Pre-authorization (platform screens before card issuer), Issuer check (card network validates credentials), and Post-authorization (platform re-evaluates after issuer approval). Traditional supervised learning (SL) treats each stage independently with separate classifiers, losing sequential dependencies and making it impossible to directly optimize business metrics like dollar-weighted precision at fixed recall. The RL formulation aggregates reward signals across stages and enforces a business constraint that dollar-valued true positives caught at Pre-auth must exceed those caught at Post-auth, reflecting the higher value of early interception.
Experiments on real eBay transaction data show that even the human-designed RL reward outperforms the SL baseline on dollar-precision at fixed recall levels, and LLM-evolved rewards improve further, with the best LLM+RL configuration reaching $Precision of 73.74% at 80% recall vs. the SL baseline of 66.57% — a +7.17pp gain. A six-month out-of-time evaluation (Nov 2023 – Apr 2024, 6.17M transactions) shows the LLM-evolved RL agents consistently outperform the baseline across all monthly intervals without retraining, demonstrating temporal robustness.
Key findings
- Human-designed RL reward (REINFORCE with Lagrangian-relaxed precision constraint) improves dollar-precision over the SL baseline by +3.08pp at 80% recall (66.57% → 69.65%), +5.43pp at 85% recall (58.79% → 64.22%), and +4.43pp at 90% recall (51.27% → 55.70%) on Test S (522,105 transactions, Sept 15–30 2023).
- Best LLM+RL configuration (LLaMa-3-8B few-shot) reaches $Precision of 73.74% at 80% recall and 71.70% at 85% recall on Test S, vs. 66.57% and 58.79% for the SL baseline — gains of +7.17pp and +12.91pp respectively.
- Zero-shot LLM reward evolution (no human reward function examples in prompt) achieves competitive results: Gemma7B zero-shot reaches 73.27% at 80% recall, only 0.27pp below the best few-shot result, suggesting the evolutionary feedback loop compensates substantially for the lack of seed examples.
- Long-term evaluation on Test L (6,174,069 transactions, Nov 2023 – Apr 2024, 6 months out-of-time) shows LLM+RL agents consistently outperforming the SL baseline across all monthly intervals in both zero-shot and few-shot scenarios (Figs 5 and 6), without retraining the RL agent.
- The evolved zero-shot reward function (Listing 1, Mixtral-8x7B) introduces structurally distinct logic from the human Lagrangian design: it adds an explicit FN penalty term (fn * 0.5), a low-value transaction penalty (wgt < 50), and asymmetric step weights (1.2 for Pre-auth, 0.9 for Post-auth), rather than just re-parameterizing Equation 3.
- Full LLM+RL training loop (LLM inference + RL training + evaluation) runs in approximately 40 minutes per outer iteration on 2× V100 32GB GPUs with LLMs loaded in 4-bit precision; the RL policy alone (single V100) takes ~20 minutes per 200 training epochs on the full training set.
- Production RL agent achieves inference latency under 50ms on standard CPU infrastructure, making it suitable for real-time two-stage scoring at transaction scale.
- Outer loop hyperparameters: Niter ≈ 60 iterations, Nsamples ≈ 10 reward candidates per iteration, Nepisodes ≈ 150 RL training episodes per candidate, evaluated at θrecall ∈ {80%, 85%, 90%}.
Threat model
The paper frames fraud detection as an optimization problem against a static adversary: fraudulent transactions are assumed to follow historical patterns present in the training data, and there is no explicit model of an adaptive fraudster who could probe or evade the deployed RL policy. The 'adversary' is effectively the environment — fraudulent GMV that the agent must block. The system assumes that the SL model scores used as state inputs are reliable and not manipulable by fraudsters. Card issuers, the platform, and buyers are treated as fixed environmental entities. The paper does not consider adversarial ML attacks (e.g., feature-space evasion), model extraction, or policy exploitation by informed fraudsters. This is a significant gap for a production fraud system, as sophisticated fraud rings can and do adapt to observed blocking patterns over time.
Methodology — deep read
1. Threat Model and Problem Framing. The adversary here is not an external attacker trying to evade the detector — rather, the 'threat' is fraudulent payment transactions flowing through a three-stage pipeline (Pre-auth → Issuer check → Post-auth). The paper does not address adversarial ML attacks (e.g., feature manipulation by fraudsters to fool the RL policy). The assumed challenge is that legacy SL models at each stage are stationary and non-coordinated, and that human engineers lack the bandwidth to manually explore and tune reward functions that directly optimize business metrics across stages. The RL agent is trained offline on historical labeled transaction data; there is no discussion of adaptive adversaries who could learn to circumvent the deployed policy.
2. MDP Formulation. The transaction pipeline is modeled as a finite-horizon MDP with T=2 decision steps. State Si at each step consists of the output scores from existing gradient-boosted SL models plus stage indicator features (Pre-auth vs. Post-auth). The action space is binary: block (1) or pass (0). The reward function R(Si, Ai) is the object being optimized by the LLM. The global objective is to maximize dollar-valued ($) true positives minus dollar-valued false positives subject to the constraint that $TP at stage 0 > $TP at stage 1, encoding the business logic that early fraud interception is worth more. This is enforced via Lagrangian relaxation into a per-stage reward: R_precision(s,a) = (1−αi)·$TPi − αi·$FPi, where αi is a per-stage precision threshold with α1 < α2.
3. Data. All data is real-world eBay transaction data and is not publicly released. The training set covers 2023-09-01 to 2023-09-14 (2,136,590 transactions, 28,226 fraud labels). Test S covers 2023-09-15 to 2023-09-30 (522,105 transactions, 825 fraud labels). Test L covers 2023-11-01 to 2024-04-30 (6,174,069 transactions, 7,834 fraud labels). The gap between training end (Sept 14) and Test L start (Nov 1) represents a deliberate temporal holdout of ~6 weeks before the 6-month evaluation window. Labels are described as 'key fraud signals' but the exact labeling mechanism (chargebacks, manual review outcomes, etc.) is not specified. The fraud label prevalence in Test S (825/522,105 ≈ 0.16%) is notably lower than in the training set (28,226/2,136,590 ≈ 1.32%), which the authors acknowledge may introduce variance in short-window evaluation.
4. RL Architecture and Training. The policy network is a 3-layer MLP with dimensions [8, 32, 8], GELU activations, and dropout layers. Input dimensionality is 4 (representative SL scores from both stages plus stage indicators). Output is the probability of taking the block action (binary). The algorithm is REINFORCE (Williams 1992) with the Adam optimizer. Training uses the full training dataset per episode (offline RL on historical data). Part 1 (human reward) trained for 200 epochs on a single V100 (32GB), taking ~20 minutes per epoch — the paper likely means 20 minutes total for 200 epochs, though this is ambiguous in the text. Multiple random trials were run to stabilize results (specific seed strategy and number of trials not reported).
5. LLM-Enhanced Reward Evolution Loop (Algorithm 1). The outer loop runs for Niter ≈ 60 iterations. At each iteration: (a) The LLM is prompted with domain context (business metric definitions, RL code skeleton, best known reward function, sub-optimal reward functions, or self-generated failure reflections) and asked to produce Nsamples ≈ 10 candidate Python reward functions. (b) Each candidate is validated syntactically and structurally — if invalid, the LLM regenerates it without human intervention. (c) Each valid candidate trains an RL agent for Nepisodes ≈ 150 episodes. (d) The trained agent is evaluated on Test S using $Precision at three $Recall thresholds (80%, 85%, 90%). (e) The best-performing reward updates the 'current best' in the LLM context; sub-optimal rewards are included as negative examples; if no improvement is found, the LLM is asked to write a self-reflection summarizing why previous candidates failed, and this reflection is injected into the next iteration's prompt. LLM temperature is dynamically adjusted based on feedback loop outcomes (specific temperature schedule not disclosed). Three open-source LLMs were tested: Mixtral-8x7B, LLaMa-3-8B, and Gemma7B, all loaded in 4-bit quantization on 2× V100 GPUs.
6. Evaluation Protocol. The primary metric is dollar-weighted precision ($Precision) at fixed dollar-weighted recall ($Recall) levels of 80%, 85%, and 90%. For the RL agent, thresholds on the block probability output across both stages are jointly swept to achieve the target $Recall, then $Precision is read off. The baseline is the Pre-auth SL score (gradient boosted machine) thresholded at the equivalent $Recall. No cross-stage SL baseline is constructed — the authors argue this would require manual policy design that doesn't exist in their current system. There are no statistical significance tests reported. Ablations compare: (i) human-designed reward vs. SL baseline, (ii) LLM-evolved vs. human-designed vs. SL baseline, (iii) zero-shot vs. few-shot prompting, (iv) three different LLMs. Long-term robustness is assessed on Test L, plotted monthly in Figs 5 and 6.
7. Concrete Example End-to-End. A transaction arrives at Pre-auth. The legacy GBM SL model produces a risk score S_cr0. The RL policy network receives [S_cr0, stage_indicator=0, S_cr1_placeholder, ...] as state and outputs p(block). If the agent blocks, the reward from the LLM-evolved function (e.g., Listing 1) computes: reward = action * target * wgt * 1.2 (if Pre-auth, step=0) minus FN penalty minus FP penalty minus low-value-transaction penalty, normalized by wgt. If the transaction passes Pre-auth, it proceeds to Issuer check (external, not modeled), then arrives at Post-auth where the agent again observes updated state with Post-auth SL score and makes a second binary decision, this time with step=1 weight multiplier of 0.9. The cumulative reward across both steps is used to update the REINFORCE policy gradient.
Technical innovations
- First application of LLM-driven evolutionary reward function design to e-commerce payment fraud detection, adapting the evolutionary loop paradigm from robotics (Ma et al., 2023) to a financial MDP with dollar-weighted business constraints.
- Constrained multi-step MDP formulation for payment fraud that encodes the business constraint $TP_stage1 > $TP_stage2 via Lagrangian relaxation into per-stage reward terms, replacing independent SL classifiers at each pipeline stage.
- Self-reflective LLM feedback mechanism where, in the absence of any improved reward candidate, the LLM generates a natural-language failure summary that is injected back into its own prompt for the next iteration, enabling zero-shot reward optimization without human-crafted seed examples.
- Domain-specific prompt engineering that grounds LLM reward generation in explicit financial metric semantics ($TP, $FP, $TN, $FN as dollar-weighted tensors) rather than generic RL reward descriptions, producing interpretable reward terms (e.g., step-weighting, FN penalty) that align with operational fraud economics.
- Two-step automated reward function validation (structural prompt constraints + preliminary code checks) that enables fully autonomous regeneration of invalid LLM outputs without a human in the loop.
Datasets
- eBay Real-World Transaction Data (Train) — 2,136,590 transactions, 28,226 fraud labels, 2023-09-01 to 2023-09-14 — proprietary eBay internal dataset, not publicly released
- eBay Real-World Transaction Data (Test S) — 522,105 transactions, 825 fraud labels, 2023-09-15 to 2023-09-30 — proprietary eBay internal dataset, not publicly released
- eBay Real-World Transaction Data (Test L) — 6,174,069 transactions, 7,834 fraud labels, 2023-11-01 to 2024-04-30 — proprietary eBay internal dataset, not publicly released
Baselines vs proposed
- SL Baseline (Pre-auth GBM score) @80% recall: $Precision = 66.57% vs. Human-designed RL: 69.65% vs. Best LLM+RL (LLaMa-3-8B few-shot): 73.74%
- SL Baseline @85% recall: $Precision = 58.79% vs. Human-designed RL: 64.22% vs. Best LLM+RL (LLaMa-3-8B few-shot): 71.70%
- SL Baseline @90% recall: $Precision = 51.27% vs. Human-designed RL: 55.70% vs. Best LLM+RL (Mixtral-8x7B few-shot): 58.00%
- SL Baseline @80% recall (zero-shot): $Precision = 66.57% vs. Gemma7B zero-shot: 73.27%; Mixtral-8x7B zero-shot: 72.71%; LLaMa-3-8B zero-shot: 72.86%
- SL Baseline long-term (Test L, Figs 5 and 6): consistently lower $Precision than all LLM+RL agents across all 6 monthly evaluation intervals in both zero-shot and few-shot settings (exact monthly values not tabulated in the accessible text)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2509.18719.
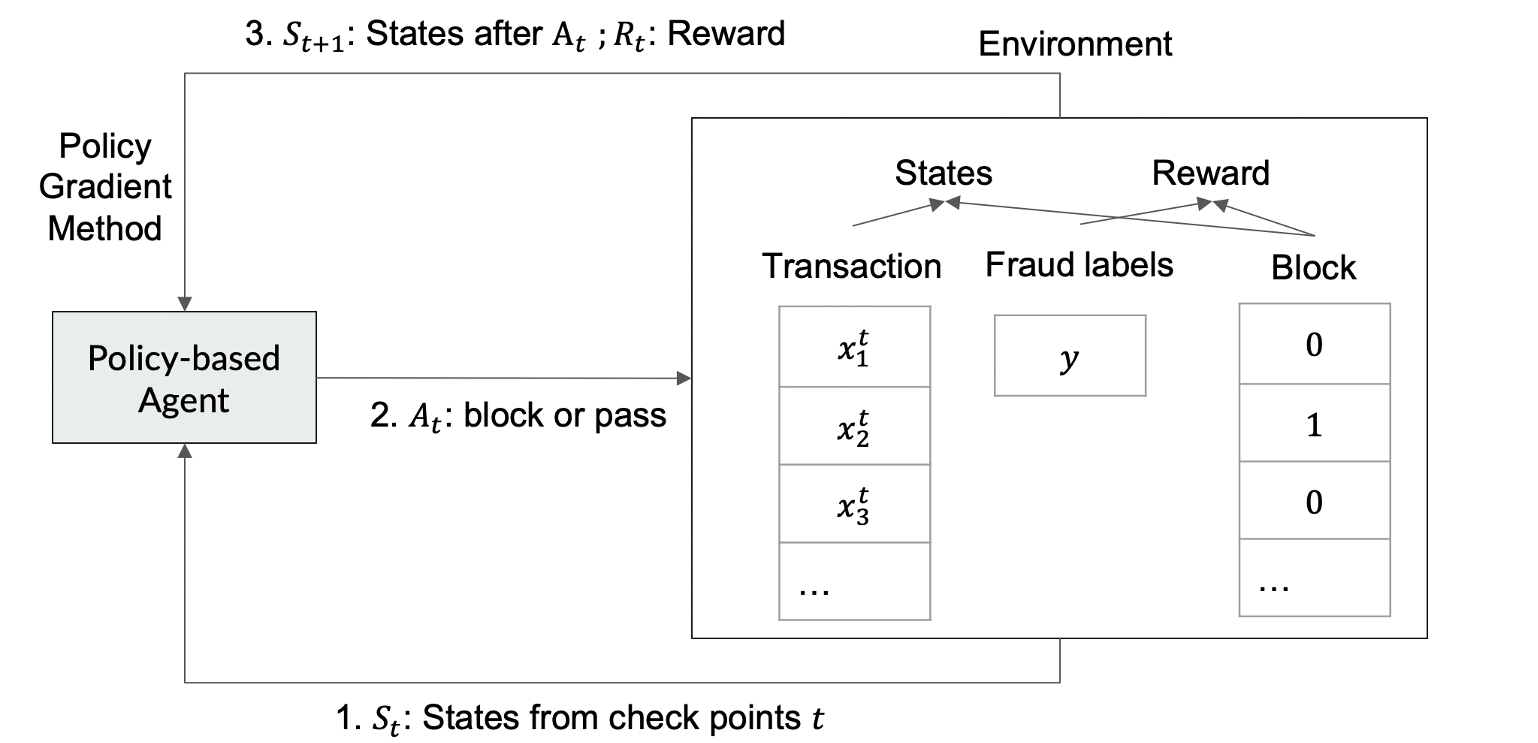
Fig 1: The LLM enhanced self-improving RL framework overview. It takes in the task description/instructions,

Fig 2: Imagine the buyer transaction risk decision

Fig 3: TRISK MDP framework with staged decision
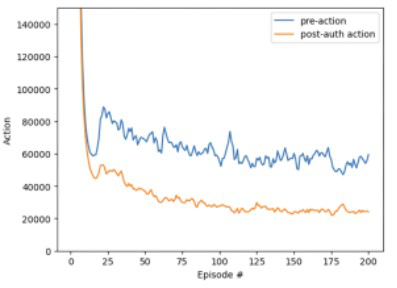
Fig 4 (page 2).
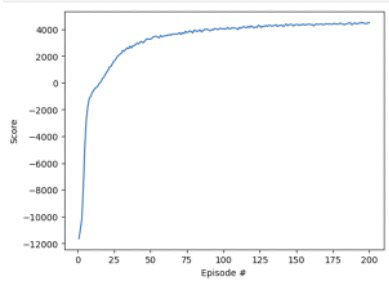
Fig 5 (page 2).
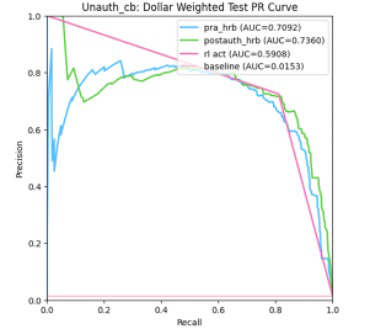
Fig 6 (page 2).
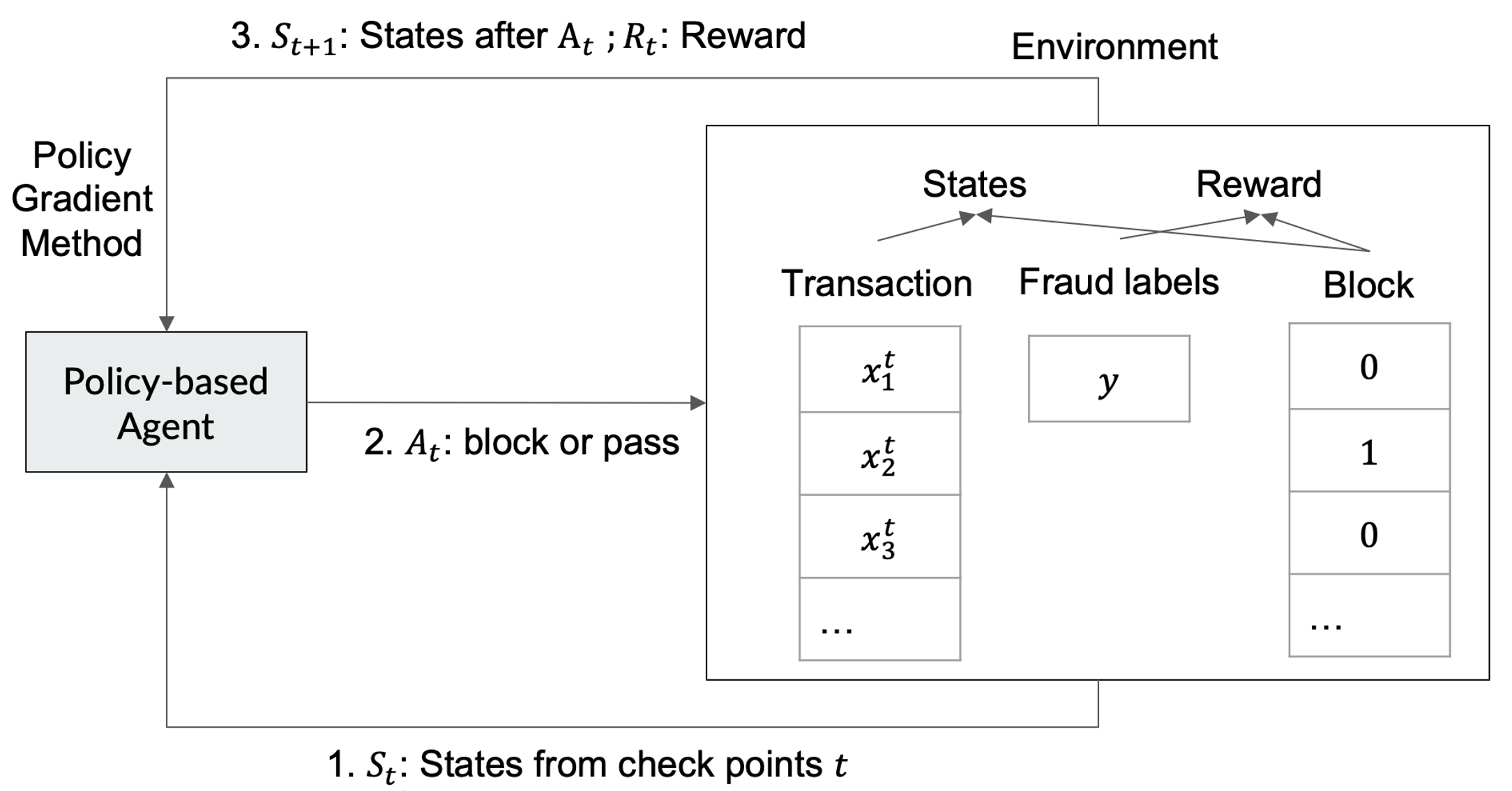
Fig 4: Reward function designs evolved by Mix-
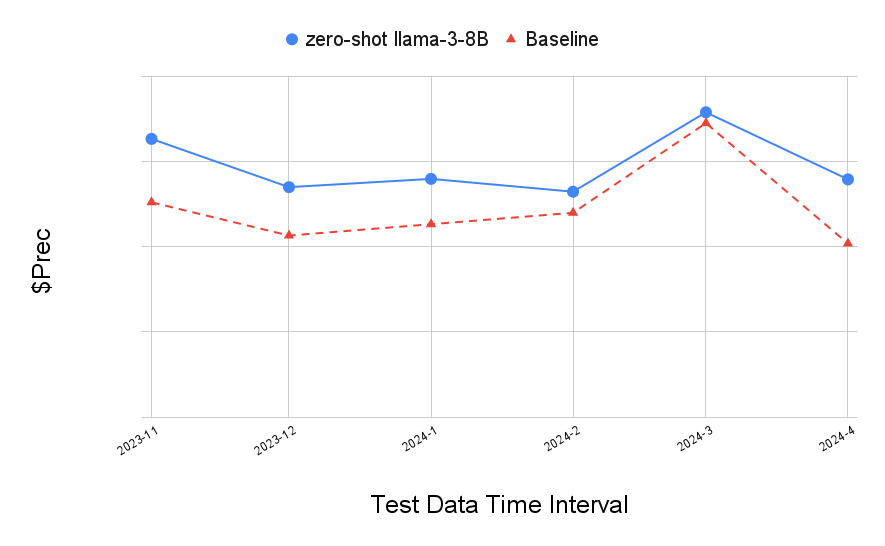
Fig 8 (page 12).
Limitations
- No adversarial robustness evaluation: the paper does not test whether fraudsters who observe blocking patterns could adapt to evade the RL policy; the threat model assumes a static fraud population, which is unrealistic for a deployed production system.
- Proprietary, non-reproducible data and closed weights: all experiments use internal eBay transaction data that cannot be shared; no model weights, reward function evolution logs, or code are released, making independent replication impossible.
- Weak baseline: the only comparison is against the Pre-auth SL score used as a single-stage ranker. No cross-stage SL ensemble, no cost-sensitive SL model, and no prior RL fraud detection baseline (e.g., Shen and Kurshan 2020) are evaluated, making it hard to isolate the contribution of RL vs. LLM reward evolution.
- Test S label sparsity and variance: Test S has only 825 fraud labels across 522,105 transactions (~0.16%), versus ~1.32% in training. The authors acknowledge this introduces variance but report no confidence intervals or bootstrap estimates on $Precision metrics, so the magnitude of improvement cannot be assessed for statistical significance.
- Offline RL generalization gap not formally addressed: the paper uses historical data and validates on out-of-time test sets but does not discuss covariate shift between train and Test L (Nov 2023 – Apr 2024 vs. Sep 2023 training), seasonal fraud pattern changes, or counterfactual feedback bias inherent in offline RL (the training data reflects past blocking decisions, not the counterfactual outcomes of the new policy).
- LLM reward function interpretability remains partial: the authors acknowledge the 'black-box' nature of evolved rewards but only provide qualitative inspection of two example functions (Listings 1 and 2); there is no formal analysis of why specific LLM-chosen parameter values (e.g., 1.2 step weight, 0.005 low-value penalty) produce the observed precision-recall outcomes.
- Hyperparameter sensitivity of the outer evolutionary loop (Niter, Nsamples, temperature schedule) is not ablated; it is unclear how sensitive final performance is to these choices or whether 60 iterations is necessary vs. sufficient.
Open questions / follow-ons
- How does the LLM+RL framework perform against an adaptive adversary who observes blocking decisions and adjusts transaction features to evade the policy — i.e., can the evolutionary reward loop respond to concept drift induced by strategic fraudsters rather than just distributional shift?
- What is the counterfactual performance gap from offline RL bias: since training data reflects past blocking decisions (surviving transactions are those the old policy passed), the RL agent is trained on a biased sample of the true transaction distribution — can online RL or off-policy correction methods (e.g., importance sampling, doubly robust estimation) close this gap?
- Can the LLM reward evolution framework be extended to more than two decision stages, or to continuous action spaces (e.g., setting a per-transaction block threshold rather than a binary decision), and does the evolutionary loop remain stable with longer horizons?
- How much of the performance gain is attributable to the multi-step MDP structure itself (vs. a well-tuned single-stage model) versus the LLM-evolved reward specifically — a controlled ablation replacing LLM reward with the human Lagrangian reward trained on both stages simultaneously would clarify this.
Why it matters for bot defense
For bot-defense and CAPTCHA engineers, the most directly transferable concept is the LLM-as-reward-designer paradigm applied to a sequential decision pipeline. Many bot-defense systems already involve multi-stage risk scoring (e.g., passive fingerprinting → behavioral biometrics → CAPTCHA challenge → account review), where each stage has different cost-benefit tradeoffs and the stages are currently operated as independent classifiers. The MDP formulation here — with stage-specific precision constraints and a global dollar-weighted objective — maps cleanly onto that architecture. The evolutionary reward loop could, in principle, automate the tuning of challenge-aggressiveness thresholds across stages without requiring manual reward engineering each time business requirements change (e.g., when friction budgets shift during peak traffic or attack campaigns).
The practical caution for bot-defense practitioners is that this paper's RL agent operates in an offline, relatively slow-moving fraud domain where adversarial adaptation is measured in weeks or months. Bot operators, by contrast, can adapt within hours to observed CAPTCHA or challenge patterns, making the static offline RL assumption much more dangerous. The absence of any adversarial evaluation or online learning component means this framework as published should not be adopted without significant additional work on concept drift detection and policy refresh cadence. The inference latency result (<50ms on CPU) is encouraging for real-time deployment, but the 40-minute outer loop iteration time means the system cannot react quickly to a live bot campaign — it would need integration with online or continual RL to be operationally relevant in an active attack scenario.
Cite
@article{arxiv2509_18719,
title={ LLM-Enhanced Self-Evolving Reinforcement Learning for Multi-Step E-Commerce Payment Fraud Risk Detection },
author={ Bo Qu and Zhurong Wang and Daisuke Yagi and Zhen Xu and Yang Zhao and Yinan Shan and Frank Zahradnik },
journal={arXiv preprint arXiv:2509.18719},
year={ 2025 },
url={https://arxiv.org/abs/2509.18719}
}