
A Comprehensive Performance Comparison of Traditional and Ensemble Machine Learning Models for Online Fraud Detection
Source: arXiv:2509.17176 · Published 2025-09-21 · By Ganesh Khekare, Shivam Sunda, Yash Bothra
TL;DR
This paper addresses the critical problem of online credit card fraud detection, which is challenging due to highly imbalanced data and complex fraud patterns amid rising digital transactions. The authors systematically compare traditional machine learning models—Random Forest, Support Vector Machine (SVM), Logistic Regression, and XGBoost—with ensemble learning methods, specifically Stacking and Voting classifiers, on a public credit card transaction dataset with 492 fraud cases among ~285,000 transactions. The study applies domain-specific preprocessing including data balancing by random undersampling and feature normalization using PCA-transformed anonymized features.
The key novelty lies in the comprehensive side-by-side evaluation of these methods focusing on metrics relevant to fraud detection trade-offs such as precision, recall, F1-score, and accuracy on the same heavily skewed dataset. Ensemble methods achieve very high precision (~0.99) reducing false positives, whereas traditional models like SVM and Random Forest provide better recall (~0.92-0.93), capturing more fraud cases at the cost of some false alarms. The study highlights that no single approach universally dominates and that model choice depends on the operational tolerance for false positives versus false negatives. Overall, ensembles slightly outperform on balanced metrics, demonstrating their value when deployed for real-world fraud defense.
Key findings
- Dataset contains 492 fraud transactions out of 284,807 total (imbalance approx 0.17%).
- Voting Classifier and Stacking ensemble methods achieved near-perfect fraud class precision (~0.99 and 0.98 respectively).
- SVM, Random Forest, and Logistic Regression yielded higher recall for fraud detection (~0.92 to 0.93) compared to ensembles.
- All models achieved accuracy between 0.91 and 0.94, with Voting Classifier, Random Forest, and SVM at top (0.94).
- F1-score was over 0.93 for Voting, Stacking, and Random Forest, indicating a good balance between precision and recall.
- SVM was excluded from precision-recall and ROC curve analyses due to unreliable probability calibration via Platt scaling.
- Random undersampling was used to balance the data by selecting an equal number of legitimate transactions (492) to match fraud cases.
- Use of PCA to anonymize and numerically represent 28 features (V1 to V28) in dataset, preserving privacy.
Threat model
The adversary is a fraudster generating illicit credit card transactions intending to evade detection systems. The adversary may craft transactions with features similar to legitimate ones to avoid classification as fraudulent. The detection system has access only to anonymized transaction features without direct domain knowledge of fraud tactics. The adversary is assumed not to have white-box knowledge of the model internals but tries to evade through input manipulation. Active adversarial attacks or adaptive evasion methods are not considered.
Methodology — deep read
Threat Model & Assumptions: The study assumes an adversary generating fraudulent credit card transactions that need to be detected in real-time from a large number of legitimate transactions. The adversary's strategies and transaction features are unknown; the classifier operates on anonymized PCA-transformed numerical features. There is no explicit adversarial evasion evaluation.
Data: The dataset is sourced from Kaggle, containing 284,807 transactions with 492 labeled frauds (class 1) and the rest legitimate (class 0). Features V1-V28 are anonymized PCA components. Time (elapsed seconds) and Amount (transaction value in USD) are additional features. The data is severely imbalanced (~0.17% fraud proportion).
Preprocessing: Data cleaning involved handling nulls and outliers, which were not detailed explicitly but implied. Feature scaling was applied to ensure uniform ranges. Due to severe imbalance, random undersampling was performed by selecting 492 legitimate transactions to match fraud count, resulting in a balanced dataset of 984 samples for training and testing. This approach means the model is trained on a balanced but much smaller subset.
Models: Six models were implemented:
- Random Forest: ensemble of decision trees.
- Support Vector Machine (SVM): hyperplane separation, with probability calibration noted problematic.
- Logistic Regression: linear model with sigmoid activation.
- XGBoost: gradient boosting trees with second-order optimization.
- Stacking Classifier: combines base learners' predictions using a meta-model.
- Voting Classifier: aggregates predictions by majority vote.
Training Regime: Specific hyperparameters, epochs, batch sizes, or hardware details are not provided. Models were implemented using Python libraries. The same preprocessed dataset split was used consistently for all models.
Evaluation: Metrics computed were accuracy, precision, recall, F1-score, and AUC-ROC (though SVM excluded from precision-recall and ROC due to calibration issues). Comparisons were visualized in figures for class-wise precision, recall, and F1-score. The balanced test set evaluation allows metric analysis without class imbalance bias but may distort real-world class ratios.
Reproducibility: The dataset is public from Kaggle. No mention is made of releasing code, pretrained model objects, or seeds for randomness control.
Example end-to-end: The raw dataset with ~285K transactions was first reduced by randomly sampling non-fraud entries to equal the 492 fraud examples, creating a balanced dataset. These samples feature PCA components V1-V28, plus time and amount features. The balanced dataset was normalized and split into train/test sets. Individual models like Random Forest were trained and predicted on this data. Metrics were calculated to compare precision and recall, showing Random Forest had recall ~0.93 and Voting Classifier achieved precision ~0.99. This balance illustrated precision-recall tradeoffs in choosing detection models.
Technical innovations
- Comprehensive empirical comparison of traditional and ensemble ML methods on highly imbalanced credit card fraud dataset under consistent preprocessing and evaluation.
- Use of random undersampling to create balanced dataset for fair metric comparisons of models addressing severe class imbalance.
- Demonstration that ensemble methods like Voting and Stacking optimize precision (reduce false positives) while traditional models maximize recall (reduce false negatives).
- Explicit exclusion of SVM from probability-based evaluation due to calibration issues highlights practical limitations of certain models for imbalanced fraud detection.
Datasets
- Credit Card Fraud Detection Dataset — 284,807 transactions with 492 frauds — Public Kaggle dataset
Baselines vs proposed
- Random Forest: accuracy = 0.94, recall = 0.93, F1-score > 0.93 vs Voting Classifier: accuracy = 0.94, precision = 0.99, F1-score > 0.93
- SVM: accuracy = 0.94, recall ~0.92 (excluded from precision-recall analysis) vs Stacking Classifier: precision = 0.98, accuracy = 0.93
- Logistic Regression: accuracy = 0.93, recall ~0.92 vs XGBoost: accuracy = 0.91, lower overall performance
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2509.17176.
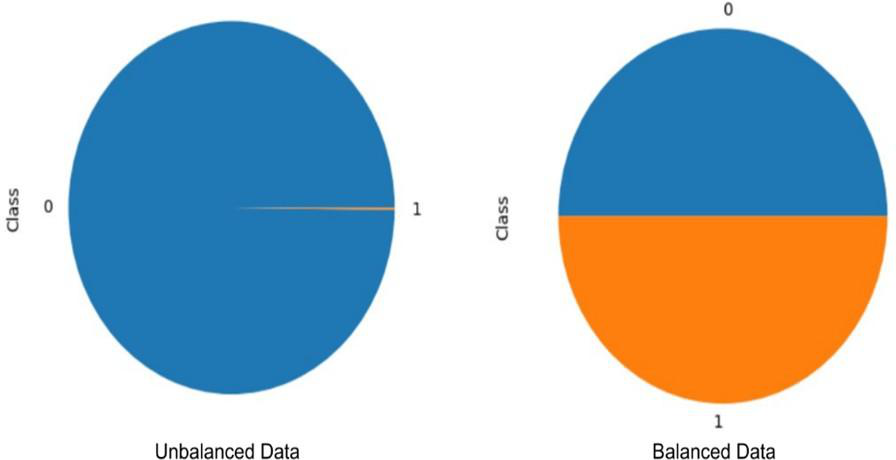
Fig 1: Before and after balancing the data
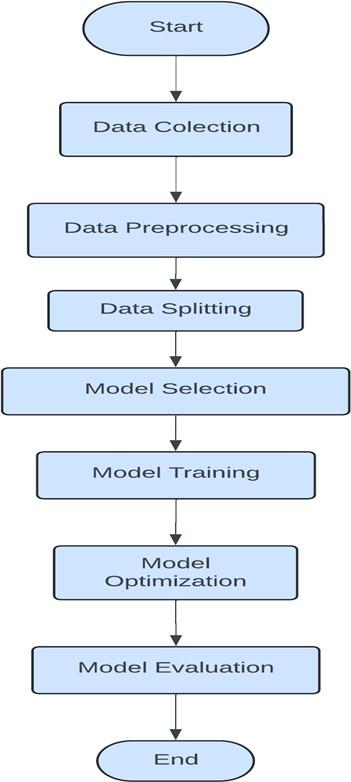
Fig 2: Flowchart for a machine learning algorithm
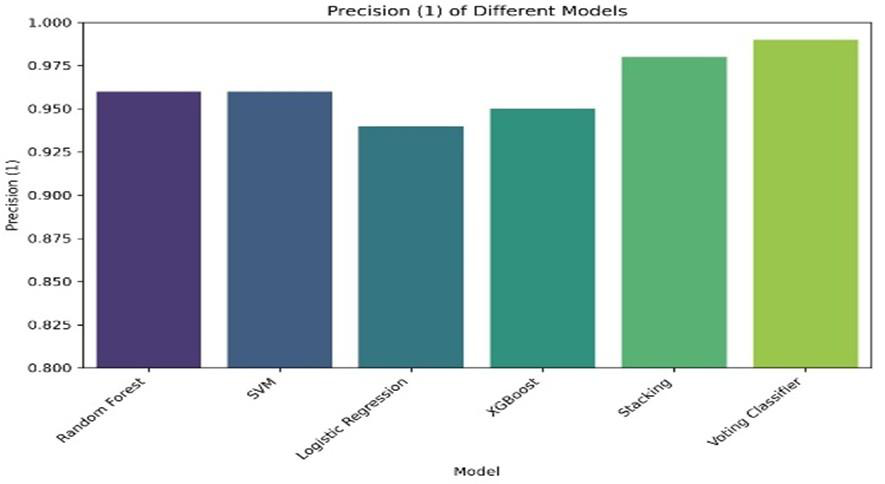
Fig 3: Comparison of machine learning techniques based on accuracy
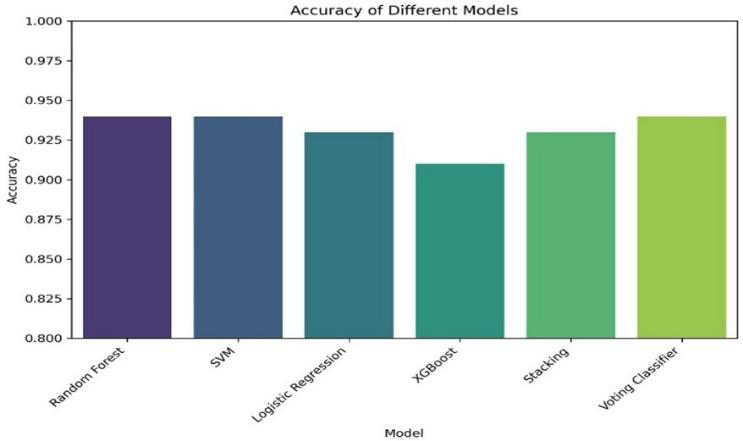
Fig 4: Comparison of machine learning models based on precision
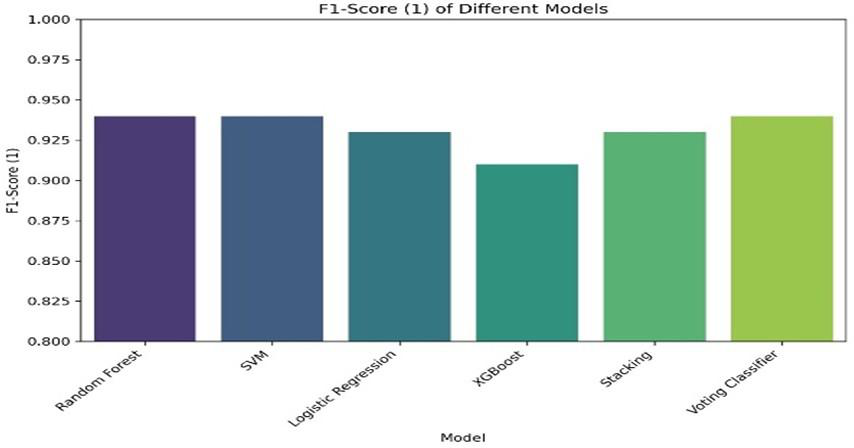
Fig 5: Comparison of machine learning models based on recall
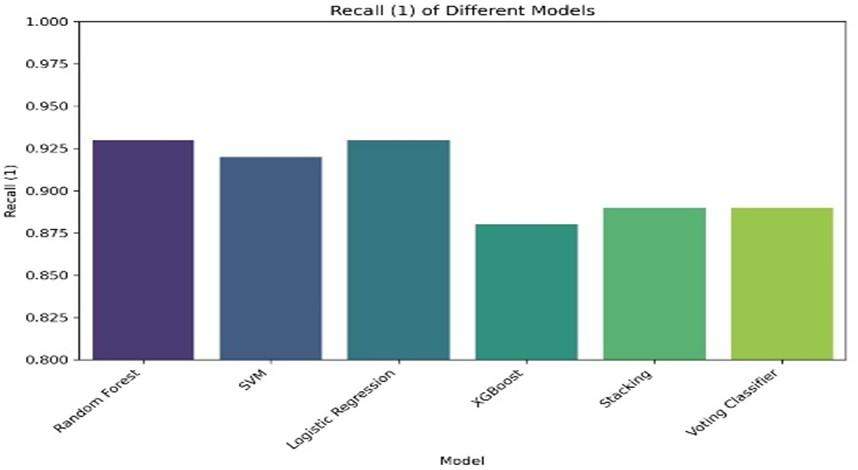
Fig 6: Comparison of machine learning models based on F1-score
Limitations
- Random undersampling reduces dataset size significantly, potentially losing data representativeness and affecting model generalization for real distribution.
- No adversarial robustness evaluation against fraudsters adapting techniques to evade detection.
- SVM probabilities poorly calibrated, leading to exclusion from precision-recall and ROC analyses, limiting full comparison.
- No hyperparameter tuning details or cross-validation reported, reducing reproducibility and risk of overfitting.
- PCA feature anonymity precludes interpretability of which original features most influence fraud detection.
- No online or real-time performance testing; results are purely offline evaluation on static data splits.
Open questions / follow-ons
- How would advanced data balancing methods like SMOTE or ADASYN affect model performance compared to random undersampling?
- Can model calibration techniques (e.g., CalibratedClassifierCV) improve probability estimates for SVM or other models to enable full precision-recall analysis?
- How do deep learning approaches (e.g., ANN, CNN) compare when integrated with ensemble methods for fraud detection on this dataset?
- What is the impact of real-time deployment constraints (latency, throughput) on these models' suitability for fraud detection?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this study illustrates important trade-offs between precision and recall in classification systems for detecting rare malicious behavior amid massive legitimate traffic, a scenario analogous to fraud detection in payments. The detailed comparison of ensemble versus traditional ML approaches highlights that aiming for very high precision can reduce false positives (important for user experience in CAPTCHA), while high recall is critical to catch all attacks but incurs more friction. The methodology of balancing imbalanced datasets through undersampling demonstrates a simple yet impactful preprocessing step but also warns about potential losses in data representativeness. Although this paper focuses on financial fraud, lessons on model calibration issues (e.g., SVM) and the value of combining multiple classifiers via stacking or voting are broadly applicable to bot detection and other anomaly classification tasks in adversarial settings. Designing bot defense systems should carefully consider these performance trade-offs and evaluate models across multiple metrics rather than accuracy alone.
Cite
@article{arxiv2509_17176,
title={ A Comprehensive Performance Comparison of Traditional and Ensemble Machine Learning Models for Online Fraud Detection },
author={ Ganesh Khekare and Shivam Sunda and Yash Bothra },
journal={arXiv preprint arXiv:2509.17176},
year={ 2025 },
url={https://arxiv.org/abs/2509.17176}
}