
Pain in 3D: Generating Controllable Synthetic Faces for Automated Pain Assessment
Source: arXiv:2509.16727 · Published 2025-09-20 · By Xin Lei Lin, Soroush Mehraban, Abhishek Moturu, Babak Taati
TL;DR
This paper tackles a very practical bottleneck in automated pain assessment: there are too few diverse, high-pain facial examples to train models that generalize beyond a small set of subjects and demographics. The authors argue that the usual clinical datasets are both ethically constrained and heavily imbalanced, so they build a synthetic alternative, 3DPain, intended to cover identity variation, pain intensity, and clinically meaningful facial action units (AUs) more systematically than prior work.
The core idea is a three-stage generation pipeline: sample a 3D FLAME face, render a neutral face with a depth-conditioned diffusion model, apply a texture synthesis stage, then rig the face using AU-driven deformations to create pain expressions at specified PSPI levels and viewpoints. On top of that dataset, they propose ViTPain, a Vision Transformer that compares a pain image against a neutral reference image of the same identity using cross-attention, and optionally supervises AU prediction through learned query tokens. In their experiments on UNBC-McMaster, synthetic pretraining on 3DPain improves downstream pain estimation, and the full ViTPain model gives the strongest numbers among their compared single-frame baselines.
Key findings
- 3DPain contains 82,500 frames from 2,500 synthetic identities, with the paper stating 25,000 pain expression heatmaps and balanced age/gender/ethnicity coverage.
- The real-world evaluation set is UNBC-McMaster with 48,398 frames from 25 subjects and PSPI labels in the 0–16 range.
- Pretraining Vanilla ViT on 3DPain raises F1 at PSPI≥1 from 0.32±0.08 to 0.46±0.06 and AUROC from 0.54±0.14 to 0.73±0.07; PCC rises from 0.28 to 0.44.
- For the authors’ own ViTPain model, 3DPain pretraining improves F1 at PSPI≥1 from 0.47±0.13 to 0.58±0.06, AUROC from 0.75±0.12 to 0.86±0.03, and PCC from 0.36 to 0.53.
- In Table 3, adding the binary head increases ViTPain F1 at PSPI≥1 from 0.50±0.07 to 0.55±0.09 and PCC from 0.52 to 0.53, while also improving AUROC at ≥1 from 0.80±0.03 to 0.84±0.03.
- The neutral-reference and multi-shot inference settings improve ranking consistency: Table 3 reports PCC rising from 0.53 to 0.54 and AUROC at ≥3 from 0.87±0.04 to 0.89±0.03.
- Against their cited image-based baseline PwCT under 5-fold CV at PSPI≥2, the paper reports AUROC 0.80 and F1 0.48 for their implementation, versus AUROC 0.86±0.04 and F1 0.51±0.04 for ViTPain (k=3); the authors note the PwCT reproduction excludes private training data, so this comparison is not apples-to-apples.
Threat model
The main “adversary” is not a malicious actor but the combination of ethical constraints, demographic skew, and label imbalance that makes pain assessment models brittle. The system assumes the model sees a pain image and, for ViTPain, a neutral image of the same identity at inference; it does not assume access to an attacker model or to adversarial perturbations. What the approach cannot do is solve the lack of temporal context, guarantee clinical correctness of synthetic labels without human validation, or remove the need for a clean neutral reference in deployment.
Methodology — deep read
The threat model is not a cybersecurity adversary but a data/modeling constraint: the authors assume the practical adversary is data scarcity, demographic imbalance, and label imbalance in pain datasets, not an attacker trying to subvert the system. Their target use case is non-communicative patients, especially dementia or severe impairment cases, where one cannot ethically induce severe pain to collect balanced labels. They also assume that a downstream model should generalize subject-independently, so identity leakage is a major confounder. For the synthetic pipeline, the implicit requirement is that generated pain expressions should be clinically plausible, match PSPI semantics, and preserve identity across neutral/pain pairs.
Data provenance is split into synthetic and real. The synthetic dataset, 3DPain, is generated by the authors through a three-stage pipeline rather than collected from a public source. They state 82,500 frames, 2,500 synthetic identities, and 25,000 pain expression heatmaps; Table 1 breaks identities down by age (1,563 young, 937 elderly), gender (1,723 men, 777 women), and ethnicity (Latino 646, Middle East 585, South Asian 469, White 460, East Asian 258, Black 82). The real evaluation dataset is UNBC-McMaster Shoulder Pain Expression Archive: 48,398 frames from 25 subjects with PSPI labels from 0 to 16. They use a 70/20/10 identity-disjoint split for the synthetic data, and then 5-fold cross-validation on UNBC-McMaster. Preprocessing for the recognition model is simple: all images are resized to 224×224. For training on the imbalanced real dataset, they use weighted sampling with weight 2.0 for PSPI≥1 and 1.0 for PSPI<1.
The generation pipeline is the central algorithmic contribution. Stage 1 samples a FLAME facial identity [20] and renders a frontal depth map; this depth map conditions Kandinsky 2.2 with ControlNet [31] to synthesize a photorealistic neutral face that is geometrically aligned with the 3D mesh. Stage 2 uses Hunyuan3D 2.1 [37] texture generation to map the neutral face back onto the FLAME mesh as physically based rendering textures, aiming to preserve fine-grained skin detail, wrinkles, and ethnicity-related appearance cues while maintaining view consistency. Stage 3 applies Neural Face Rigging (NFR) [27], which uses DiffusionNet [32] features and Neural Jacobian Fields [1] to map desired AU activations to mesh deformations. This is how they claim to control pain: the rigging directly targets AU4, AU6, AU7, AU9, AU10, and AU43, the components of PSPI. The final stage uses Kandinsky inpainting for background synthesis and hair completion, producing multi-view rendered faces. One concrete end-to-end example is: sample a neutral FLAME identity, render depth, generate a neutral face conditioned on that depth, texture the mesh, apply AU-specific deformations corresponding to a chosen PSPI level, render several viewpoints, then inpaint background/hair to create the final frame.
ViTPain is built as a paired-image transformer. It takes a pain image I_pain and a neutral reference image I_neutral from the same subject. Both are encoded by separate DINOv3 backbones with distinct LoRA adapters; the base backbone is frozen, and LoRA rank is 8. The pain token sequence queries the neutral token sequence through an 8-head cross-attention block, producing reference-aligned context features F_context = LayerNorm(Z_pain + A_ref). The CLS token from this fused representation feeds a PSPI regression head with sigmoid output. Patch tokens are used for an auxiliary binary pain/no-pain head and for AU supervision via six learnable AU query tokens. Those AU queries cross-attend over patch tokens to produce AU-specific latent features, which are mapped through MLPs and ReLU to nonnegative AU intensity predictions. The loss is a weighted sum of MSE for PSPI regression, BCE for the binary head, and MSE for AU regression, with weights λ_PSPI = 1.0, λ_bin = 1.0, and λ_AU = 0.1.
Training and evaluation are fairly standard but with some important protocol choices. They use AdamW with learning rate 1e-5, weight decay 1e-1, cosine annealing down to 1% of the initial learning rate over 100 epochs, and frozen backbones during both pretraining and 5-fold CV. They explicitly say architectural choices and hyperparameters were tuned on the held-out synthetic 3DPain test split, not on UNBC-McMaster validation folds, to avoid leakage. Evaluation on UNBC-McMaster reports mean AUROC and F1 across the five folds, plus aggregated PCC across validation folds. They assess clinically relevant thresholds at PSPI≥2 and ≥3, with ≥1 included for historical comparability. They also test a multi-shot inference variant where multiple neutral references are averaged at test time. No statistical significance tests are reported in the excerpt, and reproducibility is partial: the method description is detailed, but the text provided does not mention code release, frozen checkpoints, or public release status for the synthetic dataset beyond the narrative of the paper.
For one concrete evaluation path: ViTPain with 3DPain pretraining is trained on synthetic identities, then evaluated with 5-fold subject-independent CV on UNBC-McMaster. At PSPI≥1 it reaches F1 0.58±0.06 and AUROC 0.86±0.03; at PSPI≥3 it reaches F1 0.43±0.17 and AUROC 0.88±0.03. In the ablation table, the model without the reference branch already benefits from the AU query head and binary head, but the reference branch and multi-shot inference mostly improve ranking consistency (PCC) and AUROC rather than raw F1 at the high thresholds. The paper’s own interpretation is that the neutral reference helps disentangle identity from expression, making the latent representation smoother and more monotonic with respect to pain intensity.
Technical innovations
- A three-stage synthetic face generation pipeline that combines FLAME geometry, depth-conditioned diffusion, texture synthesis, and AU-driven neural rigging to produce clinically targeted pain expressions.
- Dataset-level pairing of neutral and pain images with exact AU intensities, PSPI labels, and pain-region heatmaps, which is richer supervision than typical pain benchmarks.
- A paired-image ViT with neutral-reference cross-attention that explicitly conditions pain estimation on the same subject’s neutral face to reduce identity confounding.
- An auxiliary AU query-attention branch that turns patch tokens into AU-specific predictions for the six PSPI-relevant facial actions.
Datasets
- 3DPain — 82,500 frames, 2,500 synthetic identities, 25,000 pain expression heatmaps — authors’ synthetic pipeline
- UNBC-McMaster Shoulder Pain Expression Archive — 48,398 frames, 25 subjects — public dataset
Baselines vs proposed
- PwCT [28] (baseline): F1 ≥1 = 0.52 ± 0.10 vs proposed: 0.58 ± 0.06; AUROC ≥1 = 0.77 ± 0.07 vs proposed: 0.86 ± 0.03; PCC = 0.54 vs proposed: 0.53
- Vanilla ViT (baseline): F1 ≥1 = 0.32 ± 0.08 vs proposed: 0.46 ± 0.06 after 3DPain pretraining; AUROC ≥1 = 0.54 ± 0.14 vs proposed: 0.73 ± 0.07; PCC = 0.28 vs proposed: 0.44
- ViTPain (baseline): F1 ≥1 = 0.47 ± 0.13 vs proposed: 0.58 ± 0.06 after 3DPain pretraining; AUROC ≥1 = 0.75 ± 0.12 vs proposed: 0.86 ± 0.03; PCC = 0.36 vs proposed: 0.53
- Rezaei et al. (PwCT, authors’ impl.): AUROC ≥2 = 0.80 vs proposed: 0.86 ± 0.04; F1 ≥2 = 0.48 vs proposed: 0.51 ± 0.04; PCC = 0.54 vs proposed: 0.54
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2509.16727.

Fig 1: 3DPain synthetic dataset. Our dataset provides multiview images and cor-

Fig 2 (page 2).

Fig 3 (page 2).

Fig 4 (page 2).

Fig 5 (page 2).

Fig 6 (page 2).

Fig 7 (page 2).
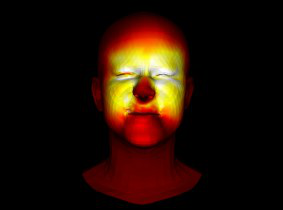
Fig 8 (page 2).
Limitations
- The synthetic pipeline is only as clinically valid as its AU-to-expression assumptions; the paper does not report human expert validation of whether generated faces truly match PSPI semantics beyond the labels they assign.
- The source excerpt does not report quantitative fidelity metrics for the generated images themselves, so photorealism and identity preservation are asserted more than measured.
- UNBC-McMaster is still the only real-world evaluation set shown, and it has only 25 subjects, so external validity across hospitals, devices, and pain etiologies remains untested.
- The model uses neutral reference frames from the same subject, which is a strong assumption that may not hold in practical deployments where a clean neutral baseline is unavailable.
- They acknowledge domain shift in skin texture realism and lack of temporal modeling; all evaluations here are frame-based, despite pain often unfolding over time.
- The comparison to some baselines is imperfect because prior methods used different validation protocols or private training data, so reported deltas are informative but not perfectly controlled.
Open questions / follow-ons
- How well do the synthetic AU/PSPI labels correspond to clinician judgments on generated images, especially for subtle AUs like AU6 and AU9?
- Can the synthetic pretraining gains transfer to other pain datasets, camera setups, ethnic distributions, or spontaneous-pain contexts beyond UNBC-McMaster?
- Would a temporal model built on top of 3DPain and ViTPain outperform the frame-based approach on video benchmarks without sacrificing the neutral-reference design?
- Can the generation pipeline be extended to other non-verbal clinical states, such as discomfort, fatigue, or delirium, with similarly controllable annotations?
Why it matters for bot defense
For bot-defense practitioners, the direct technical relevance is limited, but the paper is a useful case study in synthetic-data design under severe ethical and class-imbalance constraints. The same general lesson applies to CAPTCHA and human-verification research: if you cannot safely or cheaply collect balanced real examples of edge cases, you need a generation pipeline whose conditioning variables are semantically tight enough to produce labels that matter, not just images that look plausible.
The more specific takeaway is methodological. The authors do not rely on generic image synthesis; they build a controllable pipeline around the latent factors that define the task, then train a model with an explicit reference image to reduce identity confounding. In bot defense, an analogous setup would be to separate stable user/device identity from transient challenge-response behavior, and to evaluate whether synthetic pretraining actually improves generalization to unseen user populations or automation strategies rather than only improving in-distribution accuracy.
Cite
@article{arxiv2509_16727,
title={ Pain in 3D: Generating Controllable Synthetic Faces for Automated Pain Assessment },
author={ Xin Lei Lin and Soroush Mehraban and Abhishek Moturu and Babak Taati },
journal={arXiv preprint arXiv:2509.16727},
year={ 2025 },
url={https://arxiv.org/abs/2509.16727}
}