
Byte by Byte: Unmasking Browser Fingerprinting at the Function Level Using V8 Bytecode Transformers
Source: arXiv:2509.09950 · Published 2025-09-12 · By Pouneh Nikkhah Bahrami, Dylan Cutler, Igor Bilogrevic
TL;DR
ByteDefender tackles a practical browser-privacy problem: fingerprinting is often embedded inside otherwise legitimate JavaScript, so blunt defenses like URL blocklists or whole-script blocking either miss evasion or break pages. The paper’s core move is to shift detection from scripts to individual functions and from source/AST analysis to V8 bytecode, so the detector sees a more stable representation that is harder to obfuscate and can be checked before execution. The authors argue this is the right granularity to stop fingerprinting while preserving non-malicious code in the same file.
The novelty is a full pipeline: they instrument V8 to emit function-level bytecode with script/function metadata, collect execution traces for high-entropy API calls, heuristically label fingerprinting functions, and train a Transformer on opcode sequences. They then derive lightweight signatures from the model for on-device matching during compilation. Reported results are strong: the offline classifier reaches 98.9% accuracy, and the browser-integrated prevention path adds about 4% average page-load latency. On a crawl of the top 100k websites, they report 99.7% script-level accuracy and better robustness than AST-based methods, especially under obfuscation and URL manipulation.
Key findings
- Offline function-level Transformer on bytecode achieves 98.9% accuracy, 84.0% precision, and 85.1% recall for fingerprinting-function classification.
- Large-scale crawl over the top 100k websites yields 99.7% script-level accuracy for ByteDefender’s detection pipeline.
- Browser-integrated matching during JavaScript compilation adds 4% average page-load latency.
- The system is explicitly function-level, which the authors position as less breakage-prone than script-level blocking when a file mixes fingerprinting and legitimate logic.
- Bytecode-only analysis is claimed to be robust to common source-level obfuscation and URL manipulation, unlike AST-based approaches.
- The paper reports substantial improvements over state-of-the-art AST-based fingerprinting detectors, particularly on obfuscated JavaScript, but the exact per-benchmark deltas are not provided in the excerpt.
Threat model
The adversary is a web script or third-party service that performs browser fingerprinting for cross-site tracking, potentially embedded inside otherwise legitimate JavaScript and possibly protected by source-level obfuscation, URL randomization, or other evasion tactics. The adversary can run code in the browser and vary the script’s source form, but cannot prevent V8 from producing bytecode during compilation or hide from the browser-side instrumentation assumed by the system. The defender cannot rely on prior URL blocklists or manual per-site rule updates and wants to stop fingerprinting before execution without broadly breaking the page.
Methodology — deep read
Threat model and assumptions: the adversary is a third-party script author or service embedding browser fingerprinting code in JavaScript, potentially mixed with benign functionality and protected by common evasion tactics such as obfuscation, URL randomization, or cloaking. The detector is assumed to run inside the browser’s compilation pipeline, before the function executes, and to have access to V8 bytecode plus metadata such as script URL, script ID, and function name. The paper’s security goal is not to block all tracking; it is to specifically detect fingerprinting behavior at function granularity while avoiding broad script blocking that causes breakage. The system does not assume prior knowledge of specific tracking URLs or a fixed API allowlist at inference time; instead it learns patterns from labeled bytecode.
Data collection and labeling: the paper builds a dataset by crawling websites with Selenium in a Chromium browser whose V8 engine is instrumented to dump function-level bytecode and metadata. In parallel, a custom Chrome extension uses the DevTools Protocol tracing domain to capture execution traces, but only for Chromium-designated “High Entropy APIs,” since those APIs are likely to expose device-identifying information and provide a practical hook for heuristic labeling. The crawler visits each homepage for a fixed 15 seconds to let dynamic scripts run. The authors then define heuristic labels for four fingerprinting families: Canvas, Canvas Font, AudioContext, and WebRTC. Example: Canvas fingerprinting requires a fillText call, a toDataURL export, at least 10 text characters, and no save/restore/addEventListener on the rendering context; Canvas Font requires at least 20 measureText calls and more than 20 distinct font values; AudioContext requires creation/manipulation calls such as createOscillator or startRendering plus a later getChannelData; WebRTC requires createDataChannel or createOffer plus setLocalDescription. These heuristics are applied to trace data to label functions as fingerprinting or non-fingerprinting, and the labels are joined back to the bytecode using the tuple (script URL, script ID, function name). Anonymous functions are dropped because they cannot be reliably joined, and missing traces are treated as non-fingerprinting because only functions that invoked high-entropy APIs were traced in the first place.
Architecture and algorithm: ByteDefender’s input is a sequence of V8 bytecode opcodes for a single function, with operands, constants, memory addresses, and offsets intentionally stripped away. The authors argue this makes the representation more invariant to obfuscation that targets variable names, string literals, or control-flow surface form. They explore static embeddings (Word2Vec and FastText) as baselines, but the main model is a Transformer classifier trained on bytecode token sequences. The Transformer uses token and position embeddings, multi-headed self-attention, global average pooling, and dense layers to output fingerprinting vs non-fingerprinting. The key novelty is that the model is trained on function-level bytecode rather than source ASTs or execution graphs, so it learns opcode patterns that correspond to fingerprinting behavior without depending on runtime observation. They also derive lightweight signatures from the trained model for runtime matching against bytecode during compilation, enabling the browser to block or alter execution of a suspect function before it runs.
Training regime and one concrete example: the excerpt does not provide full training hyperparameters such as epochs, batch size, optimizer, learning rate, or seed strategy, so those details are unclear from the source shown. What is clear is that embeddings are learned from bytecode sequences and the Transformer is trained offline on the labeled dataset, with evaluation against both function-level labels and downstream script-level aggregation. A concrete example in the paper is a function like gatherFingerprint() that reads navigator.userAgent, navigator.language, navigator.platform, and screen dimensions; the raw V8 output is reduced to a bytecode sequence such as CreateObjectLiteral, LdaGlobal, GetNamedProperty, DefineNamedOwnProperty, ToString, Add, and Return. Under the authors’ pipeline, if this function’s execution trace matches a fingerprinting heuristic, the corresponding bytecode sequence becomes a positive training example. At inference time, the browser checks new functions’ bytecode against the learned signatures during compilation and can stop the function before execution.
Evaluation protocol and reproducibility: evaluation includes offline classification metrics, robustness tests against obfuscation and URL/origin manipulation, comparison with AST-based methods, and an end-to-end browser overhead measurement. The paper reports results at both function and script levels, but the excerpt does not enumerate exact baselines, split protocol, cross-validation details, or statistical tests. The authors do state a top-100k-websites crawl and a 4% average page-load latency overhead for the browser-integrated path. They also claim the codebase, implementation, and ByteDefender release are public, which helps reproducibility, though the excerpt does not say whether the labeled dataset or model weights are fully released. Because labels are heuristic rather than manually adjudicated ground truth, performance should be interpreted as accuracy against the chosen heuristic definitions rather than against a universally agreed fingerprinting taxonomy.
Technical innovations
- Function-level browser-fingerprinting detection using V8 bytecode instead of source ASTs or dynamic execution graphs.
- Heuristic trace-to-bytecode labeling pipeline that joins CDP high-entropy API traces to instrumented V8 function bytecode via script URL, script ID, and function name.
- Transformer-based opcode classifier that learns obfuscation-resistant representations from bytecode sequences.
- Compilation-time on-device matching of lightweight model-derived signatures to block fingerprinting functions before execution.
Datasets
- Top 100k websites crawl — 100,000 websites — public websites crawled by the authors
- Function-level bytecode + execution traces — size not stated in excerpt — collected by instrumented Chromium/V8 and a custom Chrome extension
- Heuristic labels for Canvas, Canvas Font, AudioContext, WebRTC — size not stated in excerpt — derived from execution traces
Baselines vs proposed
- Transformer bytecode classifier (offline): accuracy = 98.9% vs proposed: 98.9%
- Transformer bytecode classifier (offline): precision = 84.0% vs proposed: 84.0%
- Transformer bytecode classifier (offline): recall = 85.1% vs proposed: 85.1%
- Browser-integrated matching: page-load latency overhead = n/a vs proposed: 4% average
- Top-100k-websites script-level detection: accuracy = n/a vs proposed: 99.7%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2509.09950.

Fig 1: Simplified V8’s compilation pipeline
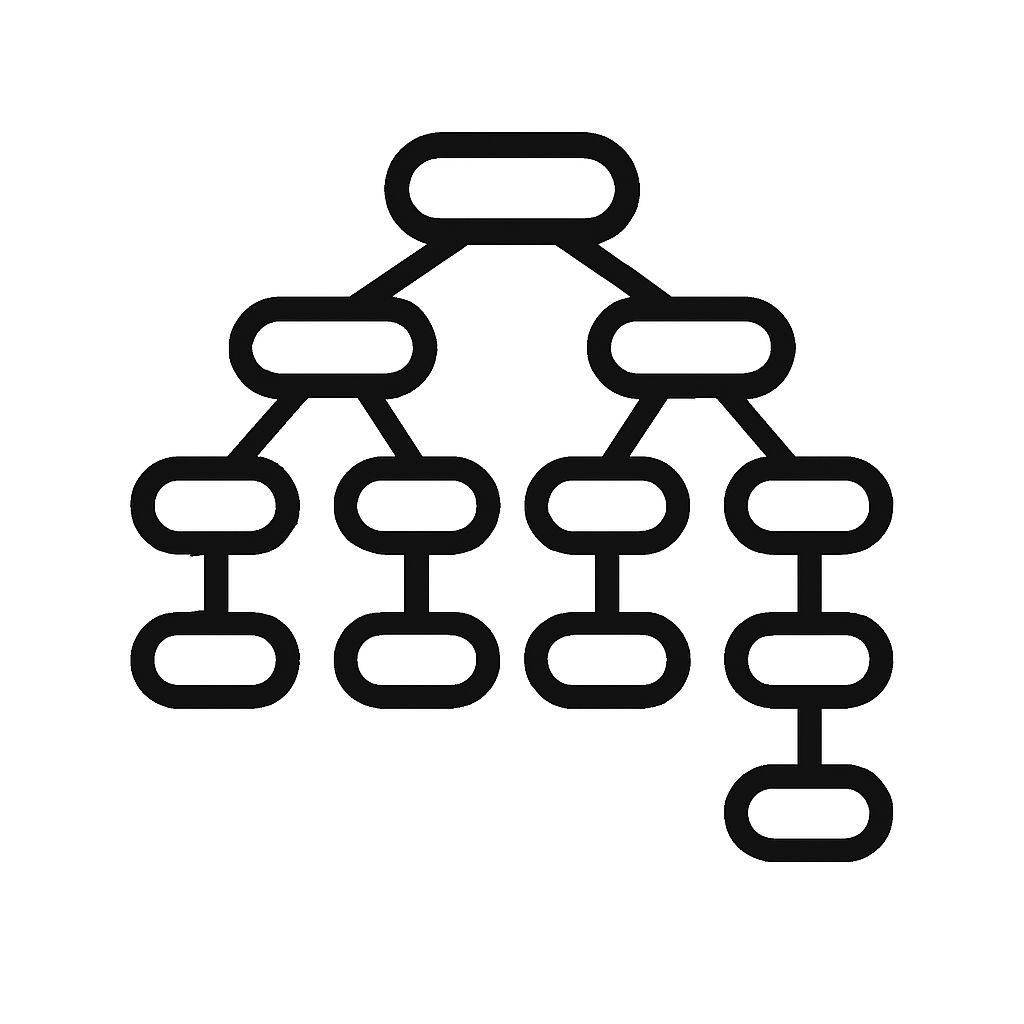
Fig 2: provides a high-level overview of ByteDefender.

Fig 3 (page 5).
Fig 4 (page 5).

Fig 5 (page 5).

Fig 6 (page 5).

Fig 7 (page 5).
Limitations
- Ground truth is heuristic and limited to four fingerprinting families (Canvas, Canvas Font, AudioContext, WebRTC), so other fingerprinting techniques may be missed or mislabeled.
- The excerpt does not specify full training details (epochs, batch size, optimizer, learning rate, random seeds), which limits exact reproducibility assessment from the text shown.
- Dropping anonymous functions and relying on script URL/script ID/function name may omit real-world patterns where naming is unavailable or misleading.
- The model intentionally discards operands and constants, which may improve robustness but can also remove discriminative signal for some edge cases.
- The paper claims robustness to obfuscation and URL manipulation, but the excerpt does not show a full adversarial evaluation against adaptive attackers.
- A 4% average latency overhead is promising, but the excerpt does not break down tail latency, worst-case overhead, or impact on large/complex pages.
Open questions / follow-ons
- How well does bytecode-only detection generalize to fingerprinting techniques outside the four labeled families, such as newer canvas variants, WebGPU-based fingerprinting, or behavior spread across multiple functions?
- Can the heuristic labeling be replaced or supplemented with manual adjudication or weak-supervision methods to reduce label noise and quantify false positives more cleanly?
- What is the best way to turn model outputs into safe, low-breakage interventions: block, stub, delay, or degrade specific API calls inside a function?
- How resilient is the approach against an adaptive attacker who rewrites fingerprinting logic to mimic benign opcode patterns or fragments logic across many small functions?
Why it matters for bot defense
For bot-defense teams, the paper is relevant because it treats some fingerprinting code as a function-level signal rather than a whole-page property. That matters in mixed-purpose scripts common on login, fraud, and CAPTCHA-adjacent flows, where blocking a vendor bundle outright can break challenge delivery, telemetry, or risk scoring. A bytecode-level detector could let a browser or client-side control plane suppress only the fingerprinting function while leaving the rest of the script intact.
Operationally, a bot-defense engineer would read this as a candidate for precision mitigation rather than broad script blocking. It is especially interesting where obfuscation is common and where the defender wants pre-execution intervention inside the browser runtime. The main caution is that the system is tuned to privacy fingerprinting, not necessarily to all anti-bot instrumentation; deploying it in CAPTCHA or fraud contexts would require careful review of false positives, because many legitimate security checks also resemble fingerprinting at the API level.
Cite
@article{arxiv2509_09950,
title={ Byte by Byte: Unmasking Browser Fingerprinting at the Function Level Using V8 Bytecode Transformers },
author={ Pouneh Nikkhah Bahrami and Dylan Cutler and Igor Bilogrevic },
journal={arXiv preprint arXiv:2509.09950},
year={ 2025 },
url={https://arxiv.org/abs/2509.09950}
}