
Aura-CAPTCHA: A Reinforcement Learning and GAN-Enhanced Multi-Modal CAPTCHA System
Source: arXiv:2508.14976 · Published 2025-08-20 · By Joydeep Chandra, Prabal Manhas, Ramanjot Kaur, Rashi Sahay
TL;DR
Aura-CAPTCHA is a novel multi-modal CAPTCHA system designed to resist modern automated attacks by combining dynamically generated visual and audio challenges with real-time adaptive difficulty control via reinforcement learning (RL). The system uses a dual-stream GAN architecture to synthesize unique visual patterns and synchronized audio prompts for each challenge instance, thwarting attackers who rely on static training corpora. An RL agent adjusts difficulty based on behavioral interaction features such as response timing and mouse movement entropy, improving usability for humans while increasing attack cost for bots. A hybrid classifier incorporating heuristics and an SVM model further distinguishes humans from bots with low false positives.
Compared to static image or audio CAPTCHAs and commercial baselines like Google reCAPTCHA v2, Aura-CAPTCHA achieves significantly higher human success rates (>92%) and substantially lower bypass rates for classical deep CNN solvers (18.4% vs 70.78%) and YOLO object detectors (31.2% vs 100%). It also reduces single-modal attack surface by requiring simultaneous audio-visual reasoning. However, the system remains vulnerable to emerging agentic vision-language models, which achieve 58.6% bypass rates. The authors openly acknowledge this limitation and propose further research into cognitive-gap tasks and device integrity attestation to bolster robustness. Aura-CAPTCHA prioritizes accessibility compliance and transparent challenge auditing over opaque behavioral risk scoring used by invisible CAPTCHAs like reCAPTCHA v3.
Key findings
- Aura-CAPTCHA achieves a 92.8% human success rate on first attempt with an average response time of 5.6 seconds, outperforming static text (78-85% HSR, 8-15s ART) and audio digit baselines (72-80% HSR, 10-18s ART).
- Bypass rate against deep CNN visual solvers drops from 70.78% on static image grids to 18.4% with Aura-CAPTCHA's GAN-based dynamic challenge generation.
- YOLO object detector success rate decreases from 100% to 31.2% due to abstract geometric patterns and per-session unique visual synthesis.
- Agentic vision-language models (e.g., GPT-4o with browser automation) bypass Aura-CAPTCHA 58.6% of the time, highlighting vulnerability of explicit challenge systems to VLMs.
- Audio-only ASR attacks with OpenAI Whisper have a 42.3% success rate on synthesized audio stream challenges, but multi-modal synchronization lowers overall bypass risk.
- Hybrid SVM and heuristic behavioral classifier achieves a low false positive rate of 3.1%, improving accessibility by reducing false bot flags on legitimate users.
- GAN inference latency is maintained below 200 milliseconds per challenge on single GPU hardware, demonstrating feasibility for real-time web deployment.
- Adaptive difficulty controlled by Q-learning uses user metrics (success, latency, suspicion score) to escalate or relax challenges, improving usability-security trade-off.
Threat model
The adversary consists of automated bots equipped with state-of-the-art computer vision and speech recognition capabilities, such as deep convolutional neural networks, object detectors (YOLO), large agentic vision-language models, and advanced ASR systems like OpenAI Whisper. Attackers can observe and interact with the CAPTCHA challenges repeatedly but cannot access the internal GAN models or RL agents directly. The attacker aims to bypass the CAPTCHA challenges to automate actions like account creation or spam posting, but is constrained by limited ability to mimic nuanced human behavioral interactions perfectly. Device compromise or full control over client hardware is out-of-scope.
Methodology — deep read
Threat Model & Assumptions: The adversary is an automated bot attacker with computational capabilities to train deep CNNs, deploy object detection frameworks (YOLO, Faster R-CNN), use state-of-the-art agentic vision-language models (e.g., GPT-4o with browser automation), and apply off-the-shelf speech recognition systems like OpenAI Whisper. The attacker can observe challenge-response interactions but cannot access internal challenge generation weights or directly manipulate server-side code. The adversary is assumed unable to perfectly mimic nuanced human behavioral signals or access large-scale human interaction datasets for training, although advanced bots may partially approximate human-like mouse and timing patterns. The system does not defend against adversaries with full device control or those breaking the temporal synchronization of audio-visual streams.
Data: The human interaction dataset consists of labeled examples collected from a controlled user study involving 500 participants completing Aura-CAPTCHA challenges. Each sample includes user behavioral features such as average response time interval, response time variance, total mouse movement, and number of clicks. Bot interaction simulations use published benchmarks for CNN solvers, YOLO detectors, VLM agents, and Whisper ASR systems. Visual and audio challenge data are synthetically generated dynamically at run-time using GANs; no fixed dataset is used to prevent supervised learning on static corpora.
Architecture / Algorithm: Aura-CAPTCHA integrates three modules:
- Generative Content Module: Utilizes a StyleGAN-inspired generator to create abstract geometric visual stimuli in a 3×3 grid layout, with unique target classes and distractors per challenge. Parallel audio synthesis sub-network generates synchronized spoken word/number phrase prompts with acoustic variability.
- Adaptive Challenge Module: Implements a Q-learning RL agent with states encoding recent user performance metrics (success rate, response time variance, suspicion score) and actions as discrete difficulty adjustments affecting visual distortions, audio speed/noise, and task complexity. Rewards are +1 for correct responses within time limit, -1 for incorrect or timed-out responses, and 0 for ambiguous input.
- User Interaction Analysis Module: Combines heuristic rules on mouse entropy, click ratios, and timing consistency with a lightweight Support Vector Machine trained on interaction feature vectors (avg_time_interval, std_time_interval, total_movement, num_clicks) to classify human vs bot.
Training Regime: The SVM classifier is trained on the collected interaction dataset with labeled human and bot examples. Q-learning executes online during challenge sessions, continually updating Q-values with learning rate α and discount factor γ, based on immediate rewards. GANs are pretrained for content generation. The overall system deployment runs on standard server hardware with GPU acceleration, maintaining challenge generation latency under 200 ms.
Evaluation Protocol: Metrics include bypass rate (percentage of automated attack successes), human success rate on first attempt, average response time, false positive rate of bot detection, and accessibility compliance scores. Baselines compared are static text CAPTCHAs, static image grids, audio digit CAPTCHAs, Google reCAPTCHA v2 and v3, and state-of-the-art attack methods (deep CNN solvers, YOLO, vision-language agents, ASR Whisper). Controlled human studies (N=500) and attack simulations are performed under equivalent conditions. Comparative results are drawn from published literature and verified through experiments, with no mention of cross-validation or statistical significance tests.
Reproducibility: Code and pretrained GAN weights are not explicitly stated as publicly released. Interaction datasets are proprietary from internal user studies and not publicly available. Attack baselines rely on existing published models. The paper provides mathematical formalization of the RL update and SVM decision function for completeness. No frozen model snapshots are shared.
Concrete Example: A human user initiates a challenge session, triggering the GAN to generate a unique 3×3 visual grid of abstract patterns simultaneously synchronized with a spoken phrase prompt. The RL agent selects an initial medium difficulty level based on prior history. The user responds within a 5 second time window, clicking the matching grid element. Behavioral analysis extracts timing intervals and mouse movement features, classifying the user as human. The RL agent receives a +1 reward and may relax difficulty for subsequent challenges. Conversely, low timing variance and linear mouse trajectories in another session trigger difficulty escalation by increasing visual distortion and speeding up audio prompts, thus making automated solving costlier.
Technical innovations
- First application of a dual-stream GAN architecture generating temporally synchronized audio-visual CAPTCHA challenges to combat static dataset attacks.
- Integration of a Q-learning reinforcement learning agent to adapt CAPTCHA difficulty in real time based on user interaction behavioral features.
- Hybrid human-bot classification combining interpretable heuristics with an SVM trained on interaction features to reduce false positives and improve accessibility.
- Multi-modal challenge design forcing simultaneous audio and visual reasoning, increasing attack complexity beyond prior single-modal approaches.
Datasets
- Aura-CAPTCHA interaction dataset — 500 participants — proprietary controlled user study
- Published benchmark datasets for static text CAPTCHA solvers and image semantic CAPTCHA attacks — from cited literature
Baselines vs proposed
- Static text CAPTCHA [8]: HSR = 78-85%, ART = 8-15s, Bypass Rate ≥90% (generic solver [5]) vs Aura-CAPTCHA: HSR = 92.8%, ART = 5.6s, Bypass Rate = 18.4%
- Static image grid CAPTCHA [29]: HSR = 81-86%, ART = 7-12s, Bypass Rate = 70.78% (deep CNN [29]) vs Aura-CAPTCHA: Bypass Rate = 18.4%
- Audio digit CAPTCHA [4]: HSR = 72-80%, ART = 10-18s, Bypass Rate = 85-99% (ASR/Whisper [3]) vs Aura-CAPTCHA: Bypass Rate (audio-only) = 42.3%
- YOLO object detector attacks [20]: Bypass Rate = 100% on reCAPTCHA v2 static grids vs Aura-CAPTCHA Bypass Rate = 31.2%
- Agentic VLM agents (e.g., GPT-4o) [32]: Bypass Rate = up to 58.6% vs Aura-CAPTCHA multi-modal synchronized challenge
- Hybrid SVM classifier: False Positive Rate = 3.1% vs heuristic-only baselines with higher FPR
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2508.14976.
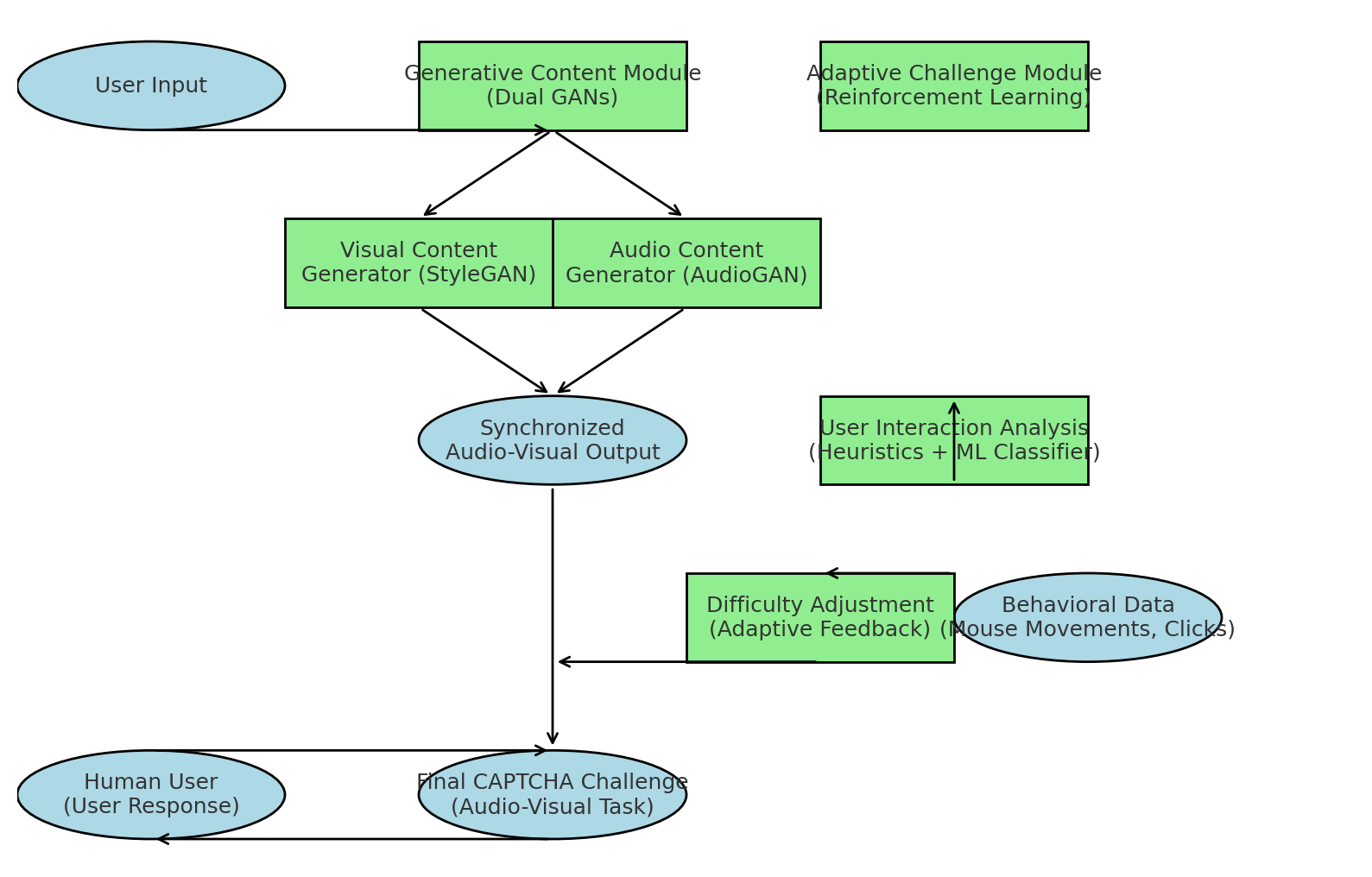
Fig 1: Methodology of Aura-CAPTCHA: a three-phase pipeline of challenge genera-
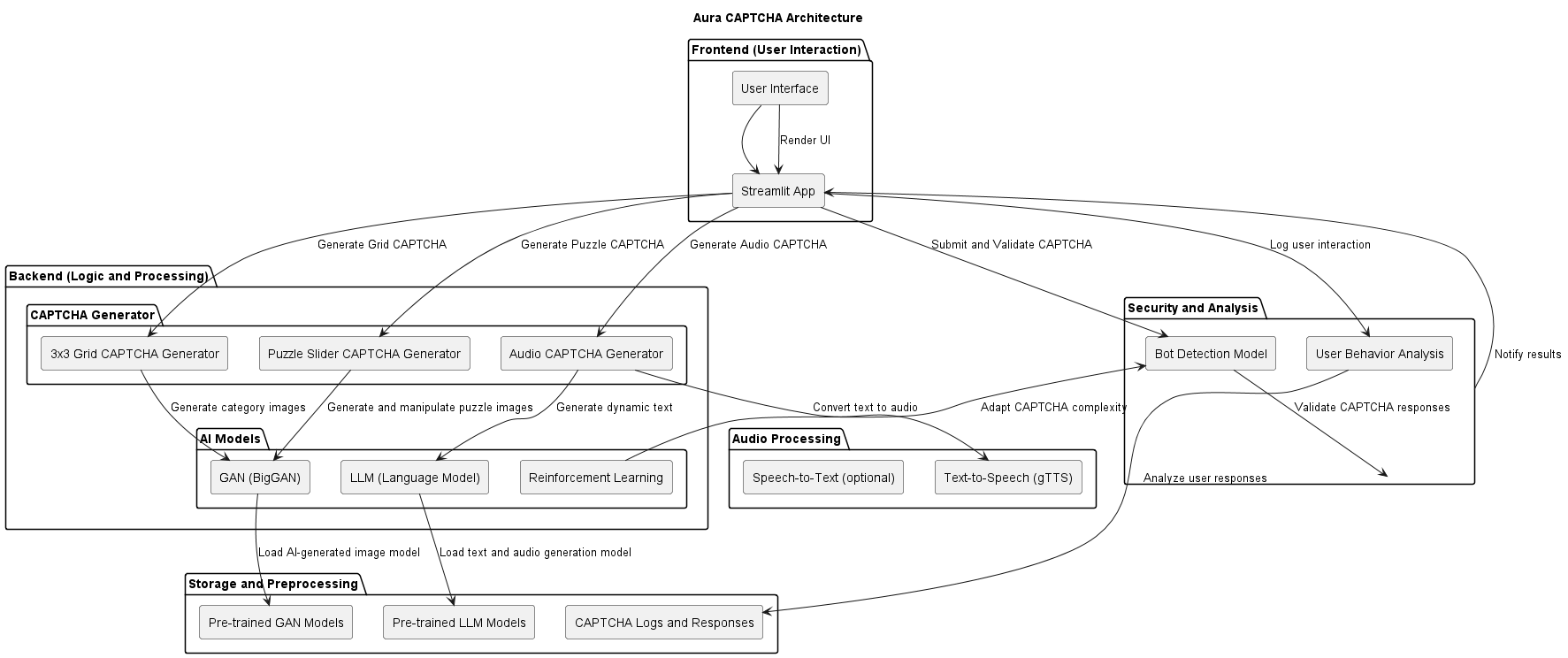
Fig 2: Functional architecture of Aura-CAPTCHA with technology stacks per module.
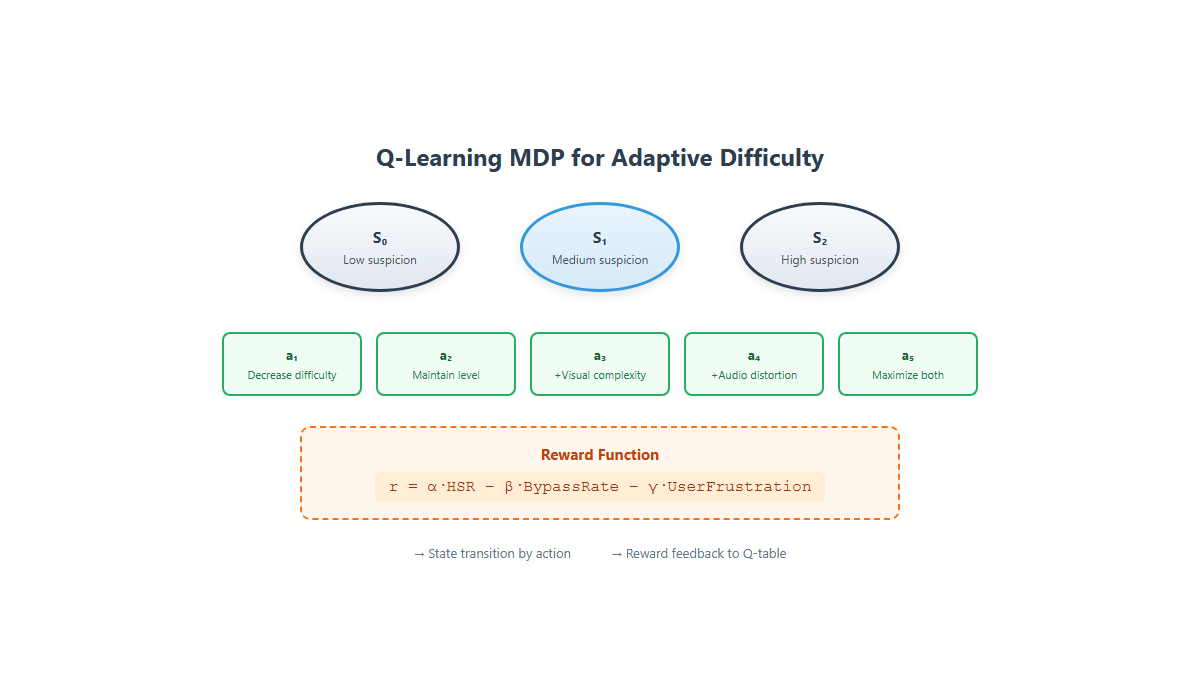
Fig 3: Conceptual Q-learning state-action space for adaptive difficulty adjustment.
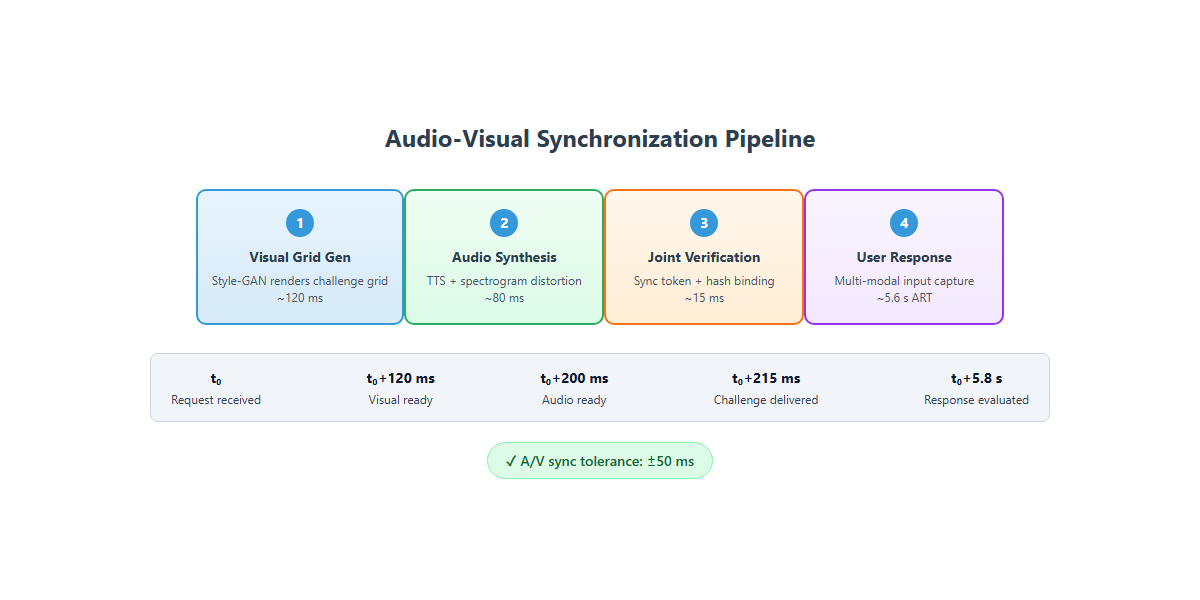
Fig 4: Temporal synchronization pipeline for multi-modal challenge delivery.
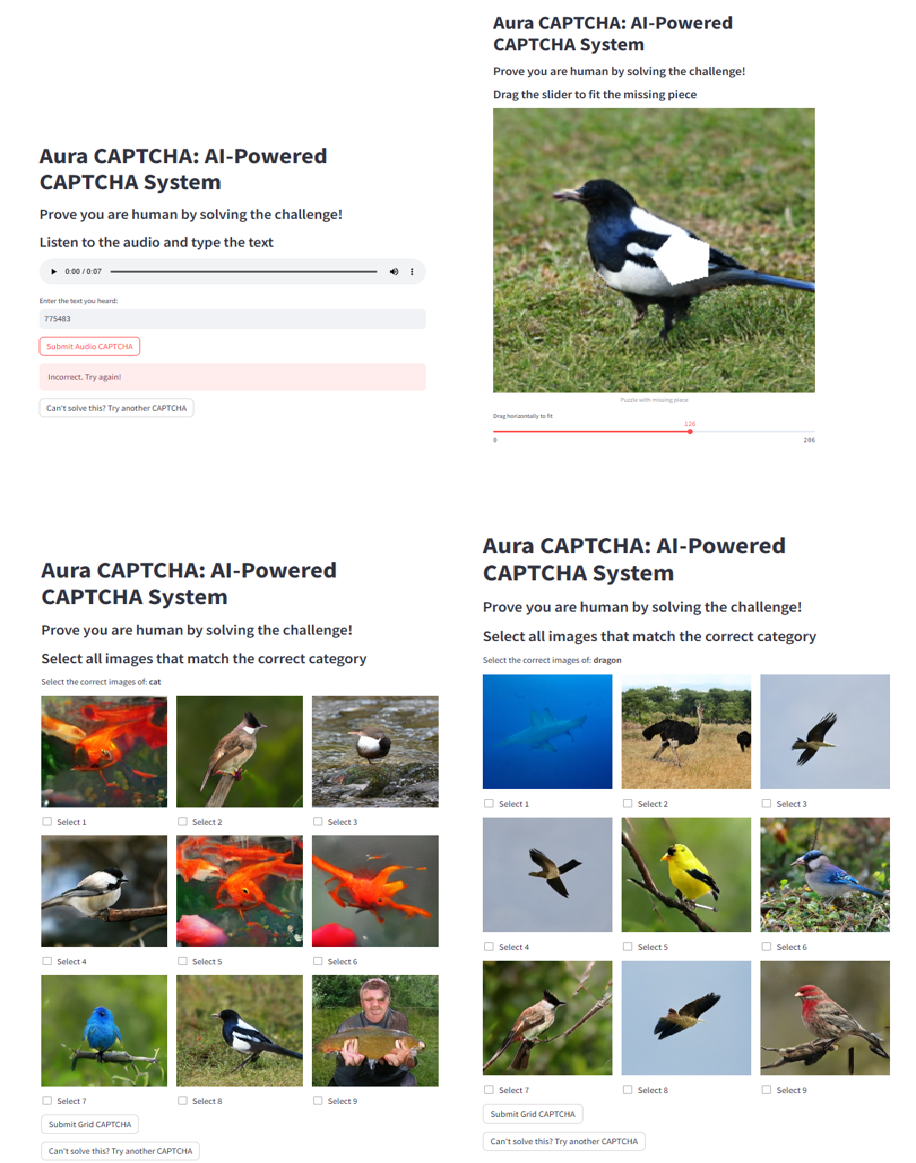
Fig 5: Sample outputs generated by the Aura-CAPTCHA system: visual grid chal-
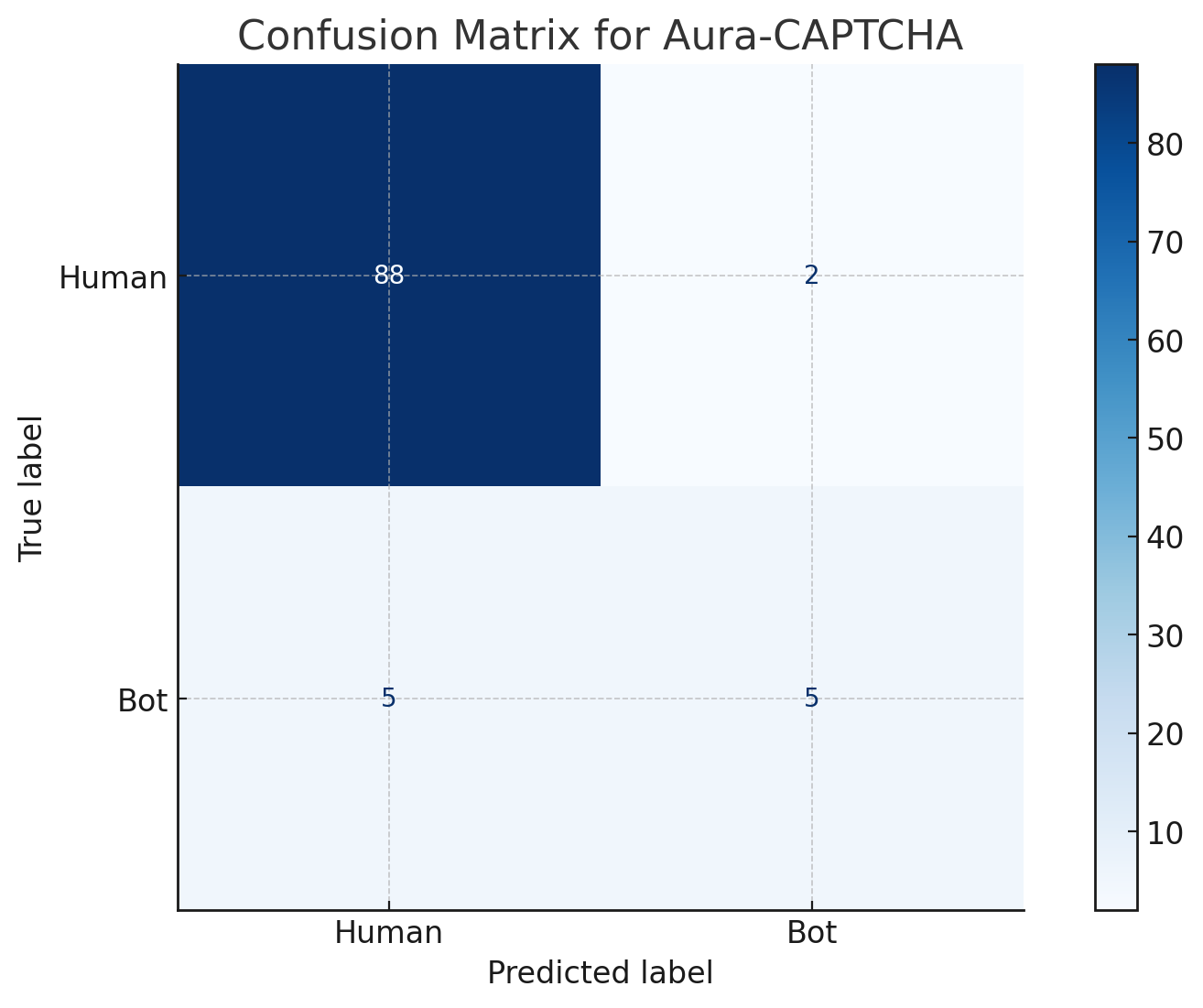
Fig 6: Comparison of CAPTCHA systems across key security and usability metrics.
Limitations
- Fundamental vulnerability to emerging agentic vision-language models, which achieve 58.6% bypass rate despite multi-modal challenges.
- On-demand GAN generation increases system computation and latency compared to static CAPTCHAs; prototype latency <200ms but large-scale deployments require optimization.
- Advanced bots emulating human-like behavioral signals (mouse movement, timing) may still evade heuristic and SVM detection modules.
- Absence of integration with device integrity attestation or cryptographic assurance limits defense against fully automated sophisticated adversaries.
- No explicit robustness validation under distribution shifts, noisy network conditions, or adversarially perturbed inputs appears in the evaluation.
- Interaction and challenge datasets are proprietary, hindering external reproducibility and independent benchmarking.
Open questions / follow-ons
- How effective would cognitive-gap tasks that exploit current limitations in VLM visual-spatial reasoning be at reducing agentic model bypass?
- Can integration with device integrity attestation mechanisms like WebAuthn significantly raise attack costs without hurting accessibility?
- What model optimization techniques (distillation, quantization) can retain GAN quality while reducing computational overhead for large-scale deployment?
- How does Aura-CAPTCHA perform under adversarial perturbations, distribution shifts, or when faced with sophisticated bot behavioral mimicry?
Why it matters for bot defense
Aura-CAPTCHA offers a compelling architecture for explicit-challenge CAPTCHA systems requiring high transparency and auditability, such as regulated financial services or accessibility-sensitive public interfaces. Bot-defense engineers should note that its dynamic, generative nature substantially raises attack costs by denying attackers a fixed training distribution, which is a key weakness of traditional static CAPTCHAs. The reinforcement learning-driven adaptive difficulty can also improve human usability by tailoring challenge complexity in real-time, a useful technique to reduce false positives and user frustration.
However, the system is not a silver bullet; the vulnerability to large-scale agentic vision-language models underscores that explicit visual challenges alone cannot keep pace with state-of-the-art AI attackers. Therefore, Aura-CAPTCHA is best employed as part of a layered defense strategy, combining multi-modal challenges with behavioral analytics and possibly device attestation. Practitioners should carefully evaluate deployment trade-offs including computational cost, latency, and accessibility implications, while also preparing for integration with future cognitive-gap or attestation-based enhancements.
Cite
@article{arxiv2508_14976,
title={ Aura-CAPTCHA: A Reinforcement Learning and GAN-Enhanced Multi-Modal CAPTCHA System },
author={ Joydeep Chandra and Prabal Manhas and Ramanjot Kaur and Rashi Sahay },
journal={arXiv preprint arXiv:2508.14976},
year={ 2025 },
url={https://arxiv.org/abs/2508.14976}
}