
Is It Really You? Exploring Biometric Verification Scenarios in Photorealistic Talking-Head Avatar Videos
Source: arXiv:2508.00748 · Published 2025-08-01 · By Laura Pedrouzo-Rodriguez, Pedro Delgado-DeRobles, Luis F. Gomez, Ruben Tolosana, Ruben Vera-Rodriguez, Aythami Morales et al.
TL;DR
This paper investigates biometric verification in photorealistic talking-head avatar videos, where attackers may perform impersonation attacks by stealing a victim's avatar to replicate their appearance and voice. Unlike traditional face or voice biometrics, distinguishing impostors solely by appearance or sound is ineffective when avatars perfectly mimic the victim. The core question studied is whether facial motion patterns—captured as behavioral biometrics—can reliably authenticate identity during avatar-mediated communication. To facilitate this, the authors create a novel public dataset of avatar videos generated by the GAGAvatar one-shot model, containing both genuine (self-driven) and impostor (cross-driven) avatars. They propose a lightweight, explainable biometric system using spatio-temporal Graph Convolutional Networks (GCN) with temporal attention pooling on normalized facial landmark sequences. Their experiments show that facial motion cues yield meaningful verification performance, with Area Under the Curve (AUC) scores reaching up to 82.58% on the CREMA-D dataset and around 70% on RAVDESS. Combining datasets further enhances generalization. The study demonstrates the promise of behavioral biometrics based on facial dynamics as a critical defense against avatar impersonation attacks, releasing the benchmark and code to foster further research.
Key findings
- AUC of 82.58% achieved for biometric verification on avatar videos generated from CREMA-D dataset in intra-dataset setting.
- AUC of 69.92% achieved in intra-dataset setting on RAVDESS avatar videos.
- Cross-dataset evaluation shows training on RAVDESS and testing on CREMA-D yields AUC of 78.78%, outperforming RAVDESS intra-dataset (69.92%) due to richer test-time variability.
- Training on combined CREMA-D + RAVDESS avatar data improves verification: CREMA-D AUC from 82.58% to 83.31%, RAVDESS AUC from 69.92% to 74.66%.
- Evaluating the model trained on avatar videos on original real videos yields up to 83% AUC, representing an upper-bound for perfect avatar fidelity.
- The temporal attention mechanism reliably highlights frames with distinctive facial gestures, helping explain verification decisions.
- Landmark-based features alone enable identity discrimination despite identical avatar appearance and voice, confirming facial motion as a behavioral biometric.
- The lightweight 3-layer GCN with temporal attention achieves competitive results with lower computational cost versus previous complex methods.
Threat model
The adversary is an impostor who has obtained the victim's avatar appearance image and can control the avatar's facial movements to impersonate the victim in virtual communication. The attacker can produce highly realistic avatar videos that perfectly replicate the victim's face and voice visually and acoustically. The defender cannot rely on appearance or voice biometrics alone due to this perfect replication. The adversary cannot mimic the victim's unique facial motion patterns precisely, which serves as the behavioral biometric. The task is to verify whether the driver controlling the avatar's facial motion is in fact the legitimate owner despite identical avatar rendering.
Methodology — deep read
The study targets the security threat where an attacker steals a victim's avatar—a photorealistic talking-head video that replicates the victim's face and voice—making classical biometric verification ineffective. The goal is to verify driver identity (person controlling avatar's motion) by analyzing facial motion patterns despite identical avatar appearance.
Two public datasets simulating virtual meetings—CREMA-D (7,442 videos, 91 subjects) and RAVDESS (1,440 videos, 24 subjects)—serve as the basis. For each identity, a single target image is selected to represent appearance. Genuine avatar videos are generated by combining the target image with that identity's real videos as driving videos (self reenactment). Impostor avatar videos are made by driving the same avatar appearance with videos from other identities (cross reenactment). This yields a dataset of avatar videos where appearance matches the target identity, but motion signals genuine or impostor drivers.
Facial landmarks are extracted per frame with MediaPipe (468 3D points), reduced to 109 key landmarks and normalized for translation (nose tip subtraction) and scale (intercanthal distance). Each video's frame sequence is converted into a temporal sequence of graphs: nodes are landmarks, edges defined by Delaunay triangulation.
The biometric model is a spatio-temporal architecture: a 3-layer Graph Convolutional Network (GCN) processes each frame's landmark graph to produce spatial embeddings (64 units in first two layers, 256 in last). Outputs from all frames in a clip (50 frames per clip) form a sequence passed through a temporal attention pooling mechanism that learns to weight frames by their importance for identity discrimination. The final embedding summarizes the clip.
Training uses triplet loss: anchor and positive share the same driver identity but different appearances; negative has a different driver identity. Training data is split so identities in train, validation, and test are disjoint, preventing identity leakage. The model is trained for 200 epochs with Adam optimizer, batch size 1024, on an NVIDIA RTX 4090 GPU.
Evaluation considers all genuine (same driver) and impostor (different driver) pairs in the test set, reporting verification performance using Area Under the ROC Curve (AUC). Cross-dataset (train on one dataset and test on another), intra-dataset, and combined datasets settings are evaluated. The approach isolates behavioral cues because impostor avatars share identical appearance and voice, forcing the system to rely on subtle facial motion dynamics. Temporal attention explainability is demonstrated by showing peaks correspond to characteristic facial expressions.
The authors provide code and a public benchmark dataset, facilitating reproducibility. However, the avatar generation quality is imperfect, potentially limiting model upper bound, and landmark extraction errors may affect results. No adversarial attacks or real-world live settings are tested.
Technical innovations
- Introduction of a public benchmark dataset of avatar videos simulating genuine and impostor drive scenarios using GAGAvatar one-shot model for avatar generation.
- A lightweight, explainable spatio-temporal GCN architecture that explicitly models facial mesh geometry of landmarks to capture coordinated facial movements.
- Temporal attention pooling mechanism over frame-level graph embeddings to focus on discriminative facial gesture frames automatically.
- Formulation of the avatar biometric verification problem focusing solely on behavioral facial motion patterns despite identical visual appearance and voice.
Datasets
- CREMA-D — 7,442 videos, 91 actors — public, controlled environments with diverse emotions
- RAVDESS — 1,440 videos, 24 actors — public, studio recordings with 8 emotions
- GAGAvatar Avatar Video Dataset — Generated using CREMA-D and RAVDESS videos and images with GAGAvatar model, size matching source datasets
Baselines vs proposed
- Trained on CREMA-D, tested on CREMA-D: AUC = 82.58% vs trained on RAVDESS, tested on RAVDESS: AUC = 69.92%
- Trained on RAVDESS, tested on CREMA-D: AUC = 78.78% vs trained on RAVDESS, tested on RAVDESS: 69.92%
- Trained on CREMA-D, tested on RAVDESS: AUC = 75.38% vs trained on CREMA-D, tested on CREMA-D: 82.58%
- Trained on combined CREMA-D + RAVDESS, tested on CREMA-D: AUC = 83.31% vs CREMA-D only training: 82.58%
- Trained on combined CREMA-D + RAVDESS, tested on RAVDESS: AUC = 74.66% vs RAVDESS only training: 69.92%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2508.00748.
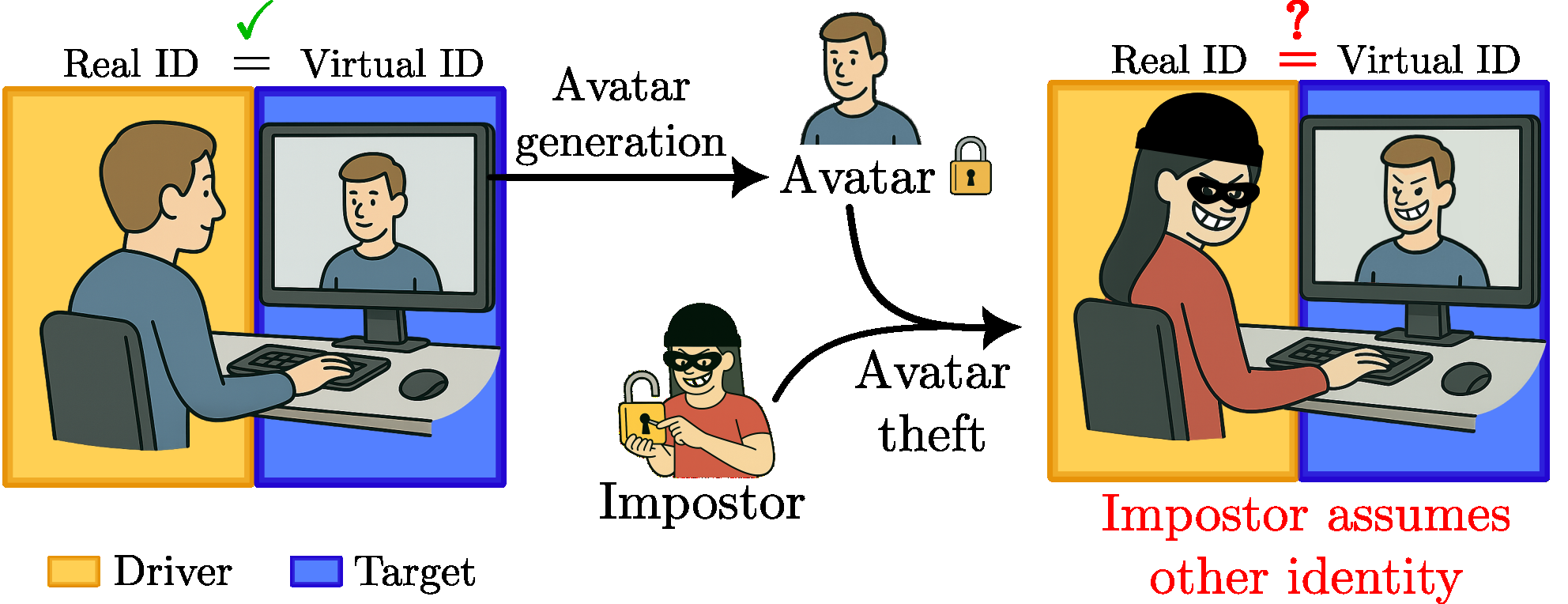
Fig 1: Avatar impostor attack scenario: An impostor steals a

Fig 2: Avatar generation and the proposed evaluation protocol. (Left): An avatar video is generated using a target image (leftmost

Fig 3: Proposed biometric verification system: For each frame t in a video, a graph G(t) is built. All the T graphs from the video are

Fig 4: Landmarks extracted for each video frame: (a) shows

Fig 5 (page 4).
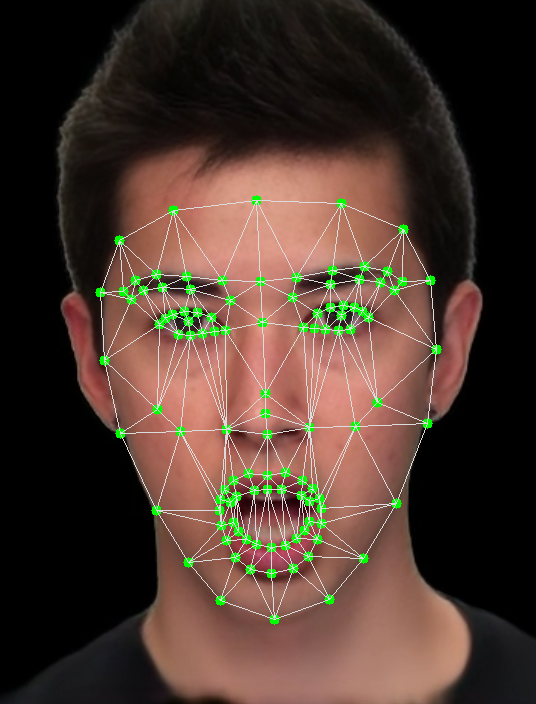
Fig 6 (page 4).

Fig 7 (page 4).
Limitations
- Reliance exclusively on facial landmarks extracted by MediaPipe may suffer from tracking errors under challenging poses or expressions.
- GAGAvatar avatar generation does not perfectly replicate subtle or extreme facial expressions, limiting biometric signal fidelity.
- No evaluation under real-world adversarial attacks or live spoofing scenarios was conducted.
- Model trained and tested only on avatar videos generated by a single avatar synthesis method, limiting generalization across different avatar technologies.
- The system uses only facial motion cues, excluding other modalities like voice or context that could strengthen verification.
- Identity-disjoint splits prevent leakage, but evaluation is limited to two datasets that may not reflect in-the-wild diversity.
Open questions / follow-ons
- How do more advanced avatar generation models that better capture subtle facial micro-expressions affect biometric verification performance?
- Can multimodal behavioral biometrics combining facial motion with voice or interaction patterns improve robustness to avatar impersonation?
- How does the system perform under adversarial attacks aimed specifically at fooling motion pattern recognition?
- What additional deep learning architectures or loss functions could boost performance beyond the current GCN with triplet loss?
Why it matters for bot defense
This paper addresses the emerging security challenge of verifying users' identities when highly realistic talking-head avatars mimic visual appearance and voice, rendering conventional biometrics ineffective. For bot-defense and CAPTCHA practitioners, the key insight is that behavioral biometrics based on subtle, individualized facial motion patterns can provide a discriminative signal to detect avatar impersonation. Adopting lightweight, explainable models that operate on landmark-based facial gestures offers a promising avenue for real-time user verification in avatar-mediated communication platforms. The accompanying public benchmark and code establish a reproducible baseline for developing anti-impersonation defenses that complement or substitute appearance- or voice-based methods. However, practical deployments should consider limitations such as avatar generation fidelity and landmark quality, and may need to integrate multimodal signals for higher assurance. Overall, this work encourages bot-defense practitioners to move beyond static features and incorporate dynamic behavioral traits to counter deepfake-style avatar attacks.
Cite
@article{arxiv2508_00748,
title={ Is It Really You? Exploring Biometric Verification Scenarios in Photorealistic Talking-Head Avatar Videos },
author={ Laura Pedrouzo-Rodriguez and Pedro Delgado-DeRobles and Luis F. Gomez and Ruben Tolosana and Ruben Vera-Rodriguez and Aythami Morales and Julian Fierrez },
journal={arXiv preprint arXiv:2508.00748},
year={ 2025 },
url={https://arxiv.org/abs/2508.00748}
}