
Moravec's Paradox: Towards an Auditory Turing Test
Source: arXiv:2507.23091 · Published 2025-07-30 · By David Noever, Forrest McKee
TL;DR
This paper investigates a fundamental and longstanding challenge in AI known as Moravec's paradox, specifically within the domain of auditory perception. Whereas humans effortlessly decode complex auditory scenes such as overlapping speech or speech under noise, state-of-the-art AI models perform catastrophically on these tasks. To systematically quantify this disparity, the authors design and deploy an "auditory Turing test" benchmark consisting of 917 curated audio challenges across seven categories, ranging from cocktail-party style overlapping speech to temporal distortions, spatial audio effects, and perceptual illusions. Human listeners achieve an average accuracy of 52%, while all tested AI models, including GPT-4's audio capabilities and OpenAI's Whisper variants, fare poorly with success rates under 7%, revealing a striking 7.5x gap. The results highlight critical deficits in current AI auditory systems' front-end perception, particularly in selective attention, noise robustness, and context-aware interpretation. The paper argues that closing this gap demands architectural innovations integrating auditory scene analysis mechanisms, physics-based reasoning, and top-down contextual modulation, rather than solely scaling training data or enhancing language understanding. The proposed auditory benchmark offers a diagnostic framework to measure progress toward human-level machine listening and underscores why traditional audio CAPTCHA designs remain effective against automated attacks.
Key findings
- Human listeners achieved 52% average accuracy (range 30%-83%, 95% confidence interval 40%-64%) on the 917 auditory Turing test challenges.
- State-of-the-art AI models failed at rates exceeding 93%, with GPT-4's audio model scoring 6.9% accuracy and Whisper base 4.6% accuracy.
- Whisper Tiny, the smallest model tested, scored only 0.8% accuracy (1/131 correct), highlighting capacity limitations for auditory tasks.
- Performance varied by category: spatialized speech tasks reached 25.0% accuracy on GPT-4 audio, overlapping speech 17.9%, but more complex distortions as low as ~3.6%.
- The AI models systematically failed at selective auditory attention tasks like focusing on a target speaker in overlapping speech, mimicking human cocktail party effect.
- Noise robustness was poor; AI accuracy dropped sharply with increasing background noise while humans maintained near-ceiling performance even at 0 dB SNR.
- Providing AI models with hints about task category or multiple transcription attempts led to minimal improvement, indicating architectural limitations rather than lack of information.
- Using specialized audio preprocessing (e.g. source separation) prior to transcription improved AI accuracy on overlapping speech, pinpointing the front-end perception as the bottleneck.
Threat model
The adversary is an AI system attempting to transcribe or interpret complex auditory inputs without human-like auditory scene analysis capabilities. The AI lacks specialized front-end modules for selective attention, source separation, or contextual adaptation. It receives only audio data and cannot leverage multimodal cues or top-down cognitive priors. The adversary cannot break physical audio distortions or reverse spatial transformations but tries to decode speech as humans do.
Methodology — deep read
The authors introduce an auditory Turing test benchmark comprising 917 audio tasks spanning seven distinct categories designed to pose challenges that humans can solve readily but that break current AI models. The threat model is that the AI systems represent state-of-the-art automated speech recognition or multimodal language models with audio input, without explicit knowledge or mechanisms for human-like auditory scene analysis or selective attention. The adversaries (AI models) have no access to multimodal context beyond audio and lack specialized front-end modules for source separation or spatial hearing.
Data comes from synthesized and curated audio clips simulating complex ecological listening conditions such as overlapping speech (cocktail party), speech in stationary and non-stationary noise (coffee shop, babble), temporal warping and phoneme distortions, spatialized and reverberant audio, phone-line distortion, and perceptual auditory illusions inspired by known psychoacoustic phenomena. The set includes approximately 20–25 clips per category, totaling 917 challenges.
Human evaluation was performed with a small group (n=9) of volunteer listeners who transcribed or decoded the audio clips under controlled conditions, establishing baseline human performance metrics. Prior published data on speech-in-noise tasks were also referenced. AI evaluation included testing multiple automatic speech recognition models and multimodal architectures: GPT-4 with audio input blend, OpenAI’s Whisper variants (base, small, tiny), and a large commercial ASR system. Models were assessed on the same 917 challenges, scoring transcription correctness.
Architecturally, the AI models are large transformer-based ASR and multimodal encoders paired with language models. No novel architectural modifications were introduced—rather, their default or lightly fine-tuned versions were benchmarked. The authors additionally tested augmentations such as providing the model with the category label (e.g. "two speakers"), multiple decoding attempts (N-best lists), and a pre-processing pipeline incorporating source separation to isolate speakers in overlapping speech.
The training regimes and hyperparameters largely follow the original model training setups, with no re-training conducted by the authors. Evaluation metrics primarily involved per-challenge transcription accuracy (% correct) and error rates across categories. Human-machine performance gaps were statistically analyzed, though detailed statistical tests beyond confidence intervals are not specified.
Reproducibility is partially supported by using publicly accessible ASR models (OpenAI's Whisper), and detailed category descriptions. The full curated audio benchmark and human data are not publicly released according to the text, limiting exact reproduction but offering a procedural template for blind testing.
A concrete example: in the overlapping speech category, a synthesized two-speaker clip plays with simultaneous distinct phrases from male and female voices. Humans are tasked with transcribing only the designated target speaker's phrase, leveraging selective attention and spatial cues. AI models without source separation input often transcribe a confused mash of both speakers or omit words entirely, resulting in less than 20% correct accuracy. Applying a source separation preprocessing step before feeding audio to ASR raises AI accuracy on this category substantially, demonstrating the critical role of front-end auditory decomposition.
Technical innovations
- Design of a comprehensive auditory Turing test benchmark spanning seven human-perceptual auditory challenges with 917 curated tasks.
- Systematic evaluation of multiple state-of-the-art multimodal and ASR models (including GPT-4 audio and Whisper variants) on complex audio CAPTCHA-like challenges.
- Empirical demonstration that front-end auditory perception—selective attention, noise robustness, and spatial hearing—is the primary bottleneck limiting AI auditory understanding, not the language model backend.
- Proposal that future models require integrated selective attention and physics-based auditory scene analysis modules to approach human-level machine listening capabilities.
Datasets
- Auditory Turing Test Benchmark — 917 audio challenges — curated synthetic and real-world inspired audio, not publicly released
Baselines vs proposed
- GPT-4 audio model: accuracy = 6.9% vs human listeners: 52%
- Whisper Base: accuracy = 4.6% vs human listeners: 52%
- Whisper Small: accuracy = 1.5% vs human listeners: 52%
- Whisper Tiny: accuracy = 0.8% vs human listeners: 52%
- Large commercial ASR system: accuracy ≈ 0%
- Post source separation preprocessing + ASR (on overlapping speech): accuracy improved significantly (exact numbers not specified)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2507.23091.
Fig 1: Audio speech recognition with adversarial
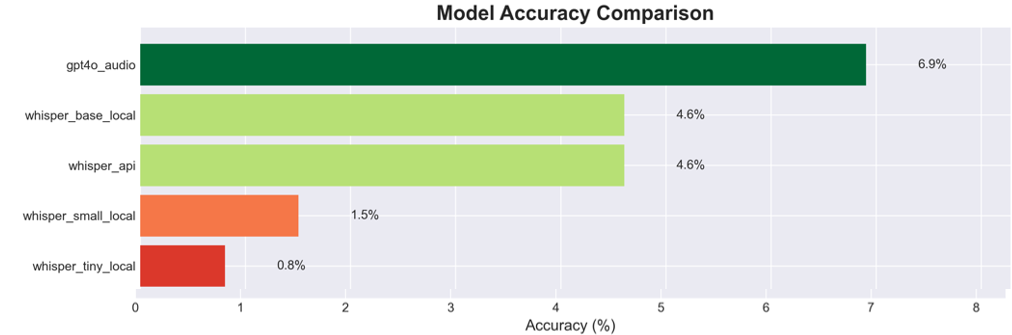
Fig 2: Model Accuracy for 131 Decoding Challenges
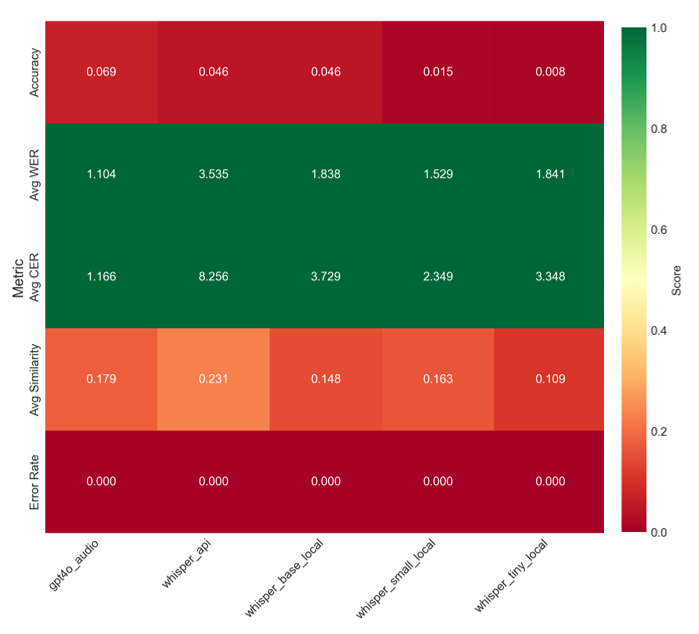
Fig 3: Metrics for Error as Heatmap for Each Model
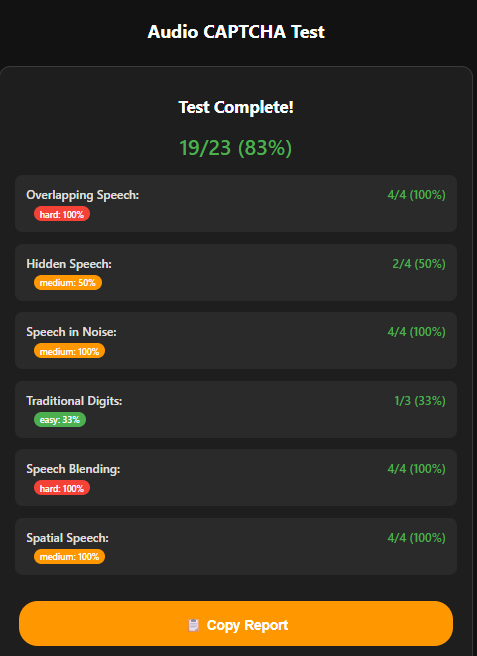
Fig 4: Human reports on easy-hard captcha
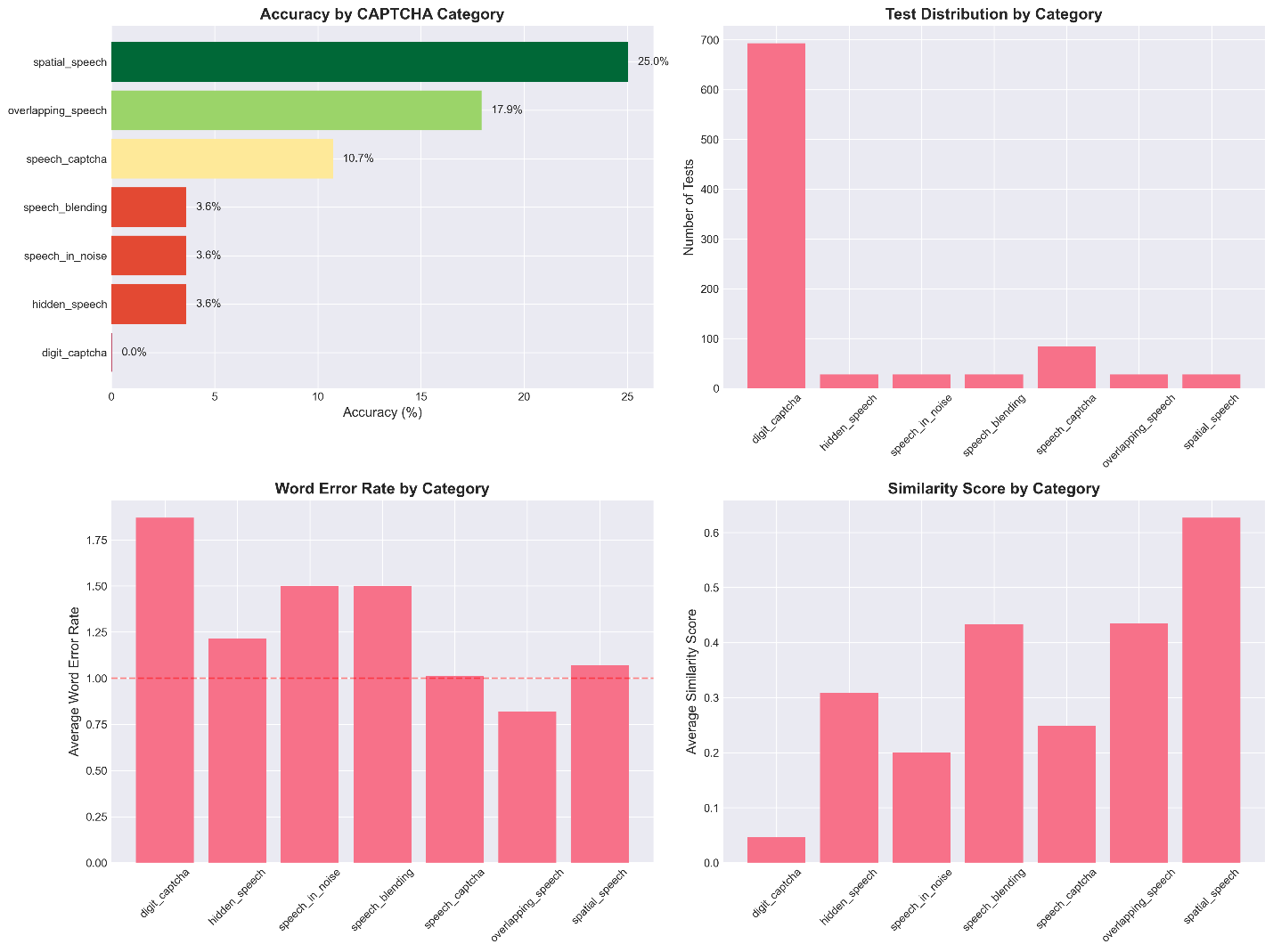
Fig 5: CAPTCHA Accuracy by Category Across All Models
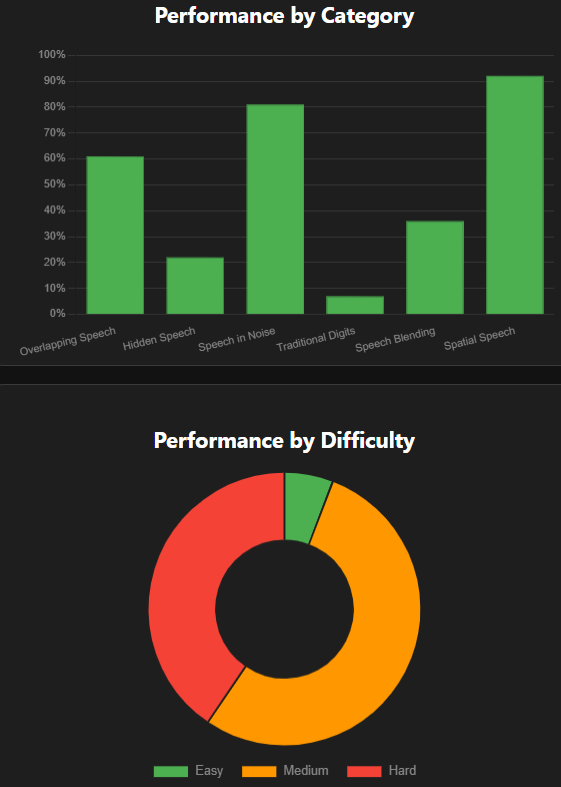
Fig 6: Summary of Human Test Results by Challenge Categories and Difficulty
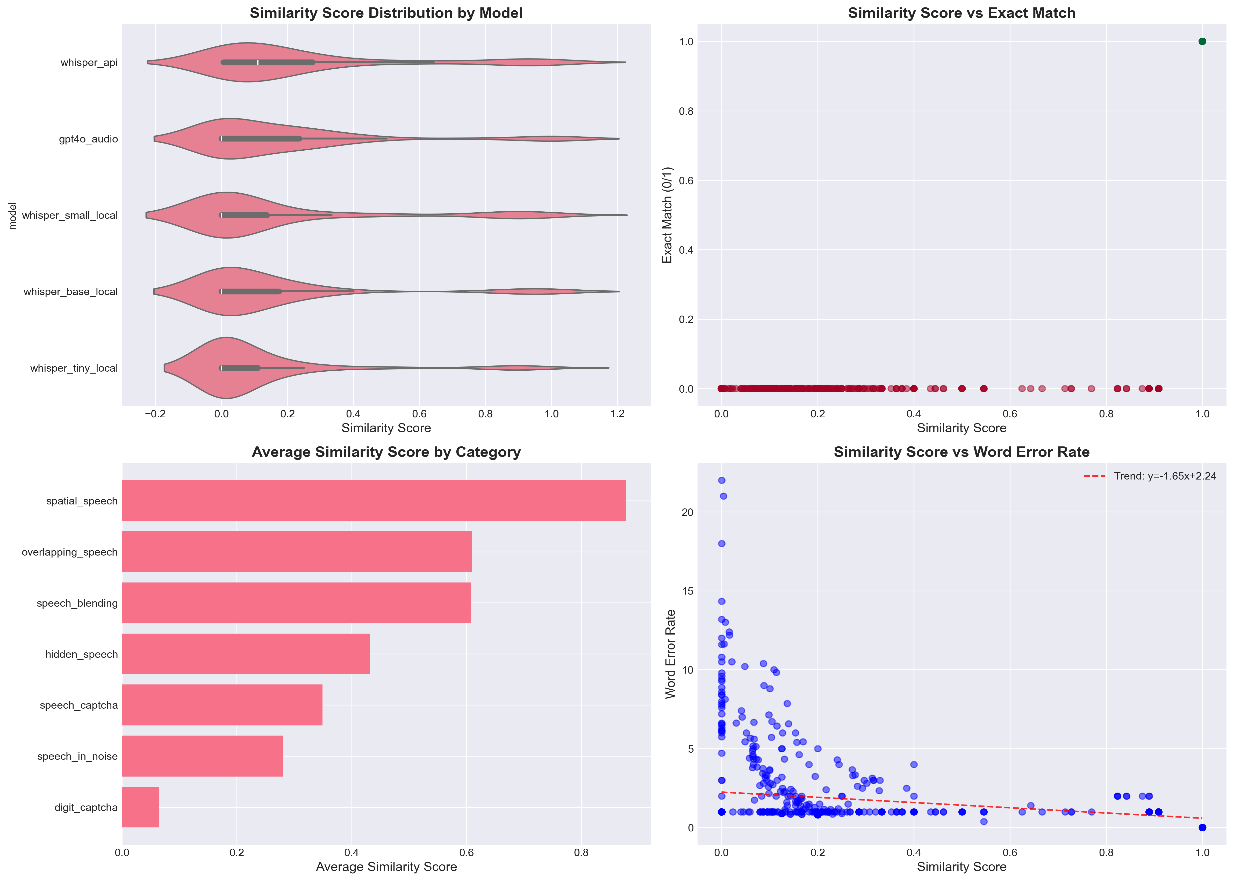
Fig 7: Similarity Score Analysis
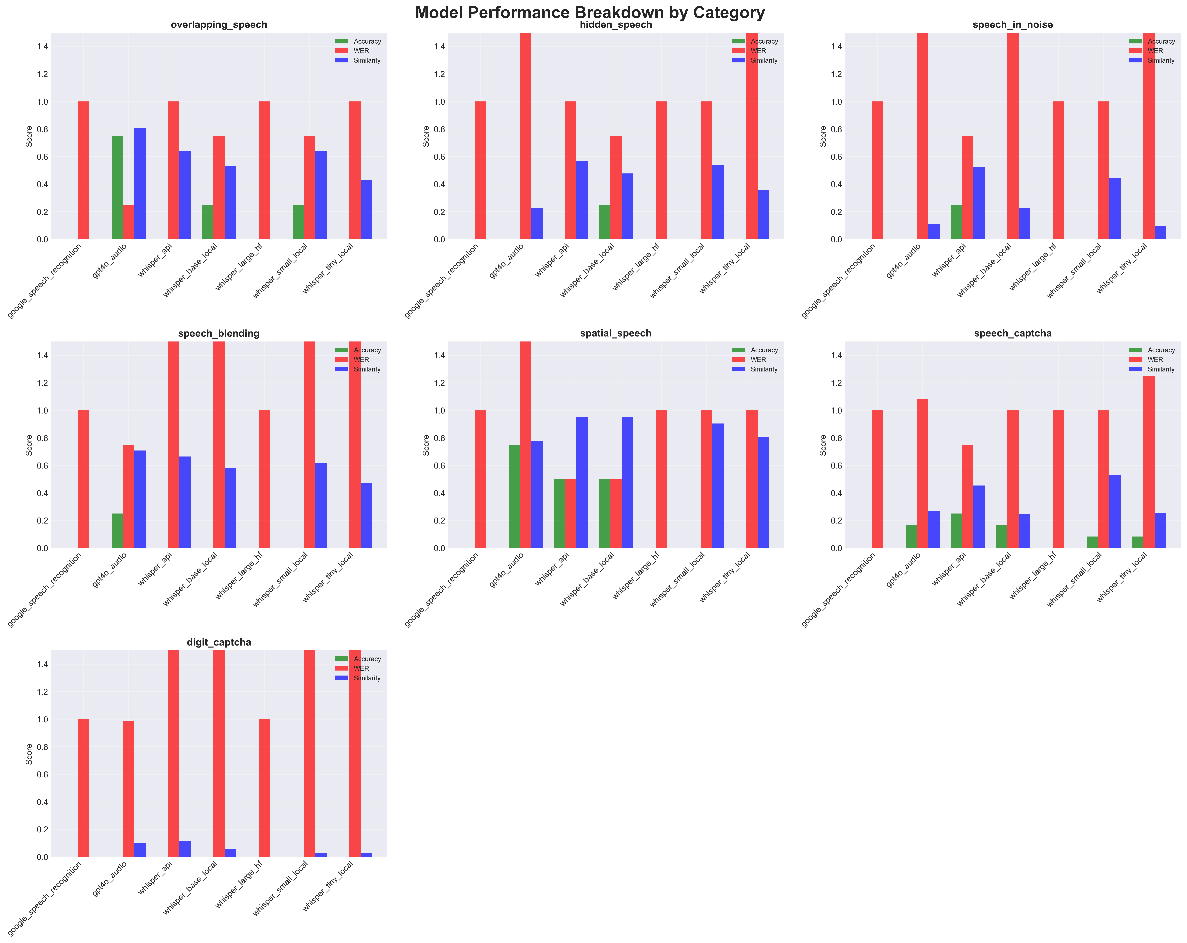
Fig 8: Model Performance Breakdown by Category
Limitations
- Human evaluation was conducted with a small number of volunteers (n=9), which may limit generalizability of human baseline statistics.
- The auditory benchmark dataset is not publicly released, limiting external reproducibility and independent validation.
- Evaluation focuses on existing pretrained ASR and multimodal models; no new trained architectures or learned modules were proposed or compared.
- No adversarial robustness testing under targeted attacks beyond environmental noise and distortions was performed on AI models.
- The effect of multimodal context (e.g. visual cues) on auditory perception was not explored, leaving open how vision-language integration might help.
- Statistical analyses beyond confidence intervals and descriptive statistics were not detailed, reducing quantitative rigor on significance testing.
Open questions / follow-ons
- How can novel architectures for integrated selective auditory attention and source separation be designed and trained jointly with language models?
- Can self-supervised learning on natural auditory scenes enable representations robust to noise, distortion, and overlapping speech similar to human infants?
- What role could multimodal context (visual, linguistic priming) play in disambiguating complex auditory signals in AI?
- How can physics-based auditory scene modeling (e.g., reverberation, echo) be incorporated into trainable neural front-ends to improve robustness?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work provides a rigorous and quantifiable demonstration that current AI systems remain profoundly deficient at solving complex audio CAPTCHA challenges involving noisy, overlapping, or distorted speech. The very human auditory skills exploited by traditional audio CAPTCHAs—the cocktail party effect, noise resilience, perceptual illusions—are absent in prevailing ASR and multimodal language models. This explains why audio CAPTCHAs relying on these perceptual filters continue to differentiate humans from machines effectively. Meanwhile, the benchmark establishes concrete tasks and failure modes that future attack or defense systems should consider. Defenders can use such test suites to calibrate difficulty and maintain accessibility while ensuring AI bots cannot reliably solve auditory puzzles. The paper’s diagnostic framework also guides future protective designs toward challenges systematically exploiting front-end perceptual deficits rather than relying solely on “noise injection,” which harms usability. Overall, this study cautions reliance on clean speech recognition accuracy alone for bot detection and stresses developing auditory CAPTCHA methods targeting fundamental gaps in AI auditory scene analysis.
Cite
@article{arxiv2507_23091,
title={ Moravec's Paradox: Towards an Auditory Turing Test },
author={ David Noever and Forrest McKee },
journal={arXiv preprint arXiv:2507.23091},
year={ 2025 },
url={https://arxiv.org/abs/2507.23091}
}