
Can We End the Cat-and-Mouse Game? Simulating Self-Evolving Phishing Attacks with LLMs and Genetic Algorithms
Source: arXiv:2507.21538 · Published 2025-07-29 · By Seiji Sato, Tetsushi Ohki, Masakatsu Nishigaki
TL;DR
The paper asks whether phishing generation can be pushed beyond static, prompt-based output by treating attack design as an evolutionary process. The core idea is to couple an LLM that generates phishing messages with a genetic algorithm that mutates and recombines higher-scoring attack strategies, while another LLM plays the victim and assigns a “visit likelihood” score. Instead of optimizing for a one-shot phishing email, the framework evolves natural-language attack strategies over many generations, with the strategy itself acting as the genotype and generated messages as the phenotype.
What is new here is the explicit co-evolution loop: the attacker’s strategy population is selected by victim-model scores, and the victim’s “prior knowledge” can be updated over time from the best-performing phishing messages. The authors use Llama 3.1 8B locally, simulate a social-media mention attack with an Amazon-looking URL, and study three settings: no prior knowledge, realistic awareness guidance, and stronger knowledge of psychological techniques. Their main result is qualitative and trend-based: the evolved strategies become more psychologically sophisticated over 30 epochs, average visit likelihood rises over time, and defense updates do not cleanly eliminate the attacker’s adaptation, producing the cat-and-mouse dynamic the paper argues is hard to break with purely reactive defenses.
Key findings
- With no prior-knowledge prompt, the average visit likelihood increased steadily over 30 epochs; the paper shows this trend in Fig. 3 and reports the top-50% strategy average rising from about 4.6 at epoch 1 to 7.0 at epoch 30 in the example traces.
- The top-50% strategies at epoch 1 emphasize direct cues such as curiosity, urgency, scarcity, and explicit calls-to-action; by epoch 30 they shift toward personalization, value alignment, confidence-building, and social proof, indicating a clear change in the psychological persuasion mix.
- An example epoch-1 interaction yields a victim score of 5 for a “AMAZING deal” / “don’t miss out” message, while an epoch-30 evolved strategy receives a score of 7 from the victim model using a more personalized, value-aligned, and socially validated pitch.
- The evaluation uses 15 attack strategies per generation, 3 phishing messages per strategy, 3 elite copies, 9 crossover offspring, and 3 mutations, across 30 epochs, all run with LLaMA 3.1 8B via Ollama.
- For RQ2, the paper evaluates three victim-knowledge scenarios: no prior knowledge, NCSC phishing-awareness guidance, and comprehensive psychological-technique knowledge; the text states that victim knowledge materially changes the direction of attack evolution.
- The mutation operator draws from a pool of 250 psychology theories extracted from Wikipedia-derived lists (social psychology theories, psychological effects, cognitive biases), so the search space for novelty is not limited to previously documented phishing tactics.
- The paper reports UMAP embeddings of strategy vectors (Fig. 4) and states that strategy embeddings shift across epochs, supporting the claim that the search is exploring different semantic regions rather than merely paraphrasing.
- The co-evolution setting updates victim prior knowledge using the top 10 phishing messages by visit likelihood, which the authors say stabilizes the prompt enough to refine defensive heuristics while still tracking attacker drift.
Threat model
The adversary is an automated phishing strategist that can iteratively generate mention messages with URLs and adapt its wording based on feedback from a simulated victim model. The defender is represented by a victim LLM whose prompt encodes prior knowledge or awareness guidance, and in the co-evolution setting that knowledge is periodically updated from observed attacks. The attacker is assumed not to know the victim’s hidden internal state except through the scored outputs, and the simulation does not include platform-level moderation, real human judgment, or post-click technical exploitation.
Methodology — deep read
Threat model and assumptions: the attacker is a social-engineering adversary who can send targeted mention messages on a social-media-like platform containing a URL intended to induce a click. The victim is not a real human; it is an LLM prompted to behave like a phishing recipient and return a 1–10 likelihood-of-clicking score plus chain-of-thought-style rationale. The paper does not simulate the landing page, credential harvesting, or post-click behavior, so the threat model stops at click intent. The attacker is assumed to know only the simulation setup and the scoring feedback from the victim model; the victim’s prior knowledge can be set to “N/A,” a public awareness guide, or a more complete psychological knowledge prompt. The authors explicitly choose social-media mentions instead of email/SMS because they claim this reduces contextual complexity and avoids needing jailbreaks for institution-impersonation emails.
Data and inputs: there is no external labeled phishing dataset in the evaluation loop. The initial population of attack strategies is generated by the LLM from its pretrained knowledge, and each strategy is a natural-language prompt that instructs the attacker LLM how to craft phishing mentions. The phishing URL is fixed to an imaginary Amazon product page, https://amazon.com/dp/123456, chosen because Amazon is familiar and plausibly tied to login behavior. For the awareness scenario, the paper uses the UK NCSC guidance “Phishing: Spot and report scam emails, texts, websites and calls,” specifically the “How to spot scam messages or calls” section; the paper says it encodes five indicators—Authority, Urgency, Emotion, Scarcity, Current Events—into the victim prompt. For the stronger-knowledge scenario, the victim prompt is augmented with broader psychological techniques used in phishing, but the full prompt details are deferred to appendices that are not included in the excerpt.
Architecture / algorithm: the system is a two-LLM loop wrapped in a genetic algorithm. First, an “attack strategy” prompt is fed to the attacker LLM, which generates multiple phishing messages per strategy to reduce output variance. Second, each message is scored by the victim LLM, which is instructed to think step-by-step and then output a click-likelihood score from 1 to 10. Third, the average score over the messages produced by a strategy becomes its fitness. The authors do not use the score directly; instead they transform average visit likelihood v into fitness 1.4^v to amplify selection differences at the top end. That fitness feeds roulette-wheel selection. The GA uses elitist copy of the top strategies, then crossover and mutation to refill the population. Crossover is done by prompting the LLM with two parent strategies and asking it to extract key elements and synthesize a new strategy. Mutation is driven by a randomly selected psychological theory from a list of 250 theories; the LLM first generates a short description of the theory, then adapts an existing strategy to incorporate it. The novel part is that the genotype is not tokens or parameters, but a human-readable persuasion strategy, which makes the evolutionary path analyzable in psychological terms.
Training regime and runtime setup: the evaluation runs for 30 epochs with 15 strategies per generation, 3 phishing messages per strategy, 3 copied elites, 9 crossover strategies, and 3 mutated strategies. The paper uses LLaMA 3.1 8B, hosted locally through Ollama, and Python with Mirascope for LLM calls. No optimizer, learning rate, or gradient-based training is involved because the LLM weights are frozen; evolution occurs only through prompting and GA selection. The paper does not report multiple random seeds, confidence intervals, or repeated runs, so it is unclear how stable the reported trends are across stochastic LLM sampling. One concrete example end-to-end: at epoch 1, a strategy like “spark curiosity by highlighting exclusive benefits” produces a message such as “I just discovered an AMAZING deal on Amazon!... don’t miss out!”; the victim model reasons that the sender is not fully trusted but the deal is tempting, and assigns a 5. That score contributes to the strategy’s fitness. After many generations, the strategy shifts toward personalization and value alignment—e.g., referencing the target’s tech reviews, claiming social proof, and framing the click as beneficial to values—and the victim model gives a 7. That change is what the authors interpret as evolutionary sophistication.
Evaluation protocol, baselines, and reproducibility: the paper primarily reports within-method comparisons over time rather than against strong external baselines. The implicit baseline is the generation at epoch 1, described by the authors as comparable to conventional LLM-only phishing message generation. For RQ1 they compare early vs late generations using average visit likelihood and UMAP embeddings (Fig. 3 and Fig. 4). For RQ2 they vary victim prior knowledge across three scenarios and track average visit likelihood over epochs; the truncated excerpt mentions figures for each scenario and cosine-distance plots for victim-knowledge embeddings, but no numeric table is included. For RQ3 they describe a co-evolution loop where the victim’s prior knowledge is periodically updated using the top 10 phishing messages by score, but the excerpt does not provide a quantified success metric beyond the plotted trends. Reproducibility is partial: the authors name the model, local runtime, population sizes, and the 250-theory mutation source, but the exact prompts are in appendices and are not fully visible here; no code release, frozen weights, or dataset release is mentioned in the provided text.
Technical innovations
- Treating phishing strategy as an evolvable natural-language genotype, rather than generating only individual messages from a static prompt.
- Using an LLM both as attacker and as a victim-scoring model, with the victim’s rationale feeding selection pressure in a GA loop.
- Injecting psychological-theory mutations from a 250-item theory pool to explore persuasion techniques beyond conventional phishing templates.
- Adding co-evolution by periodically updating the victim’s prior knowledge from the top-scoring phishing messages, creating an attacker–defender feedback loop.
Datasets
- NCSC guidance “Phishing: Spot and report scam emails, texts, websites and calls” — 1 public guidance document — source: UK National Cyber Security Centre
- Wikipedia-derived psychology theory lists — 250 theories total — source: “List of social psychology theories”, “List of psychological effects”, and “List of cognitive biases”
- Synthetic phishing-message corpus generated during simulation — 15 strategies/generation × 3 messages/strategy × 30 epochs = 1,350 messages per run — fully synthetic, no public source
Baselines vs proposed
- LLM-only initial generation (epoch 1): average visit likelihood ≈ 4.6 in the representative example vs evolved epoch-30 strategy: 7.0
- No prior-knowledge scenario: Fig. 3 shows average visit likelihood increases steadily across 30 epochs vs epoch-1 baseline; exact final mean not numerically tabulated in the excerpt
- N/A — no external baseline model or detector comparison is reported in the provided text
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2507.21538.
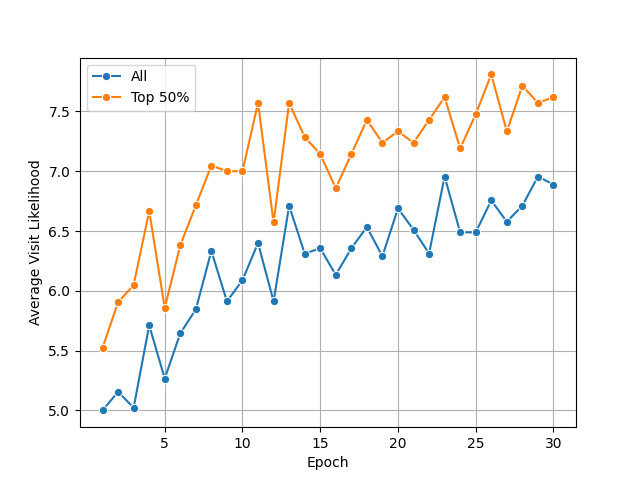
Fig 2: Genetic algorithm procedure
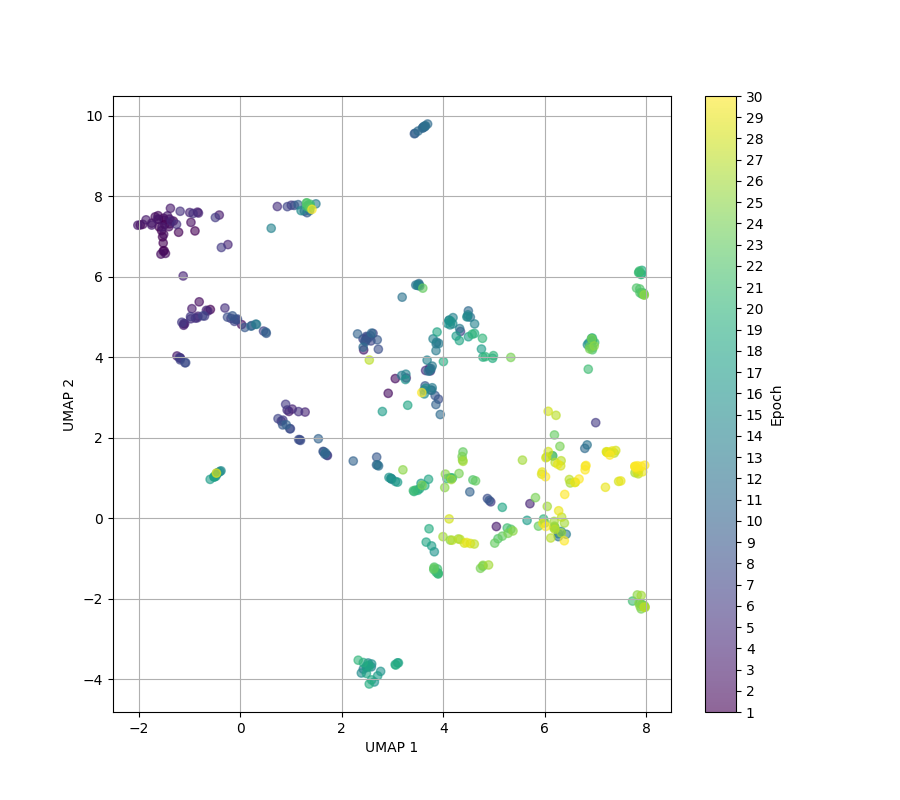
Fig 4: Embeddings of attack strategies (without victim’s
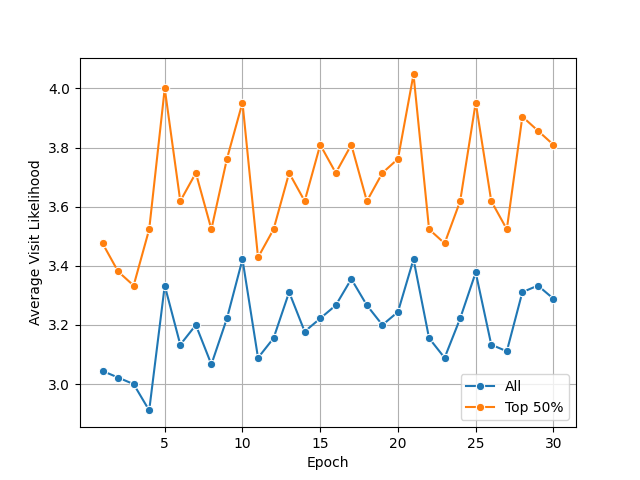
Fig 5: Evolution of average visit likelihood (Scenario 2:
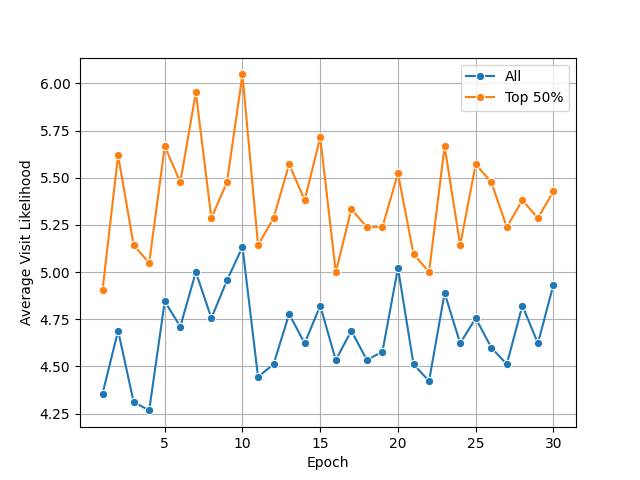
Fig 6: Evolution of average visit likelihood (Scenario 3:
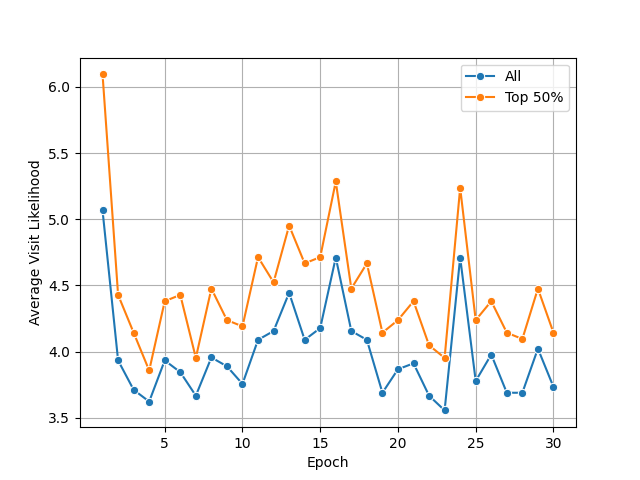
Fig 7: Evolution of average visit likelihood (Prior knowl-
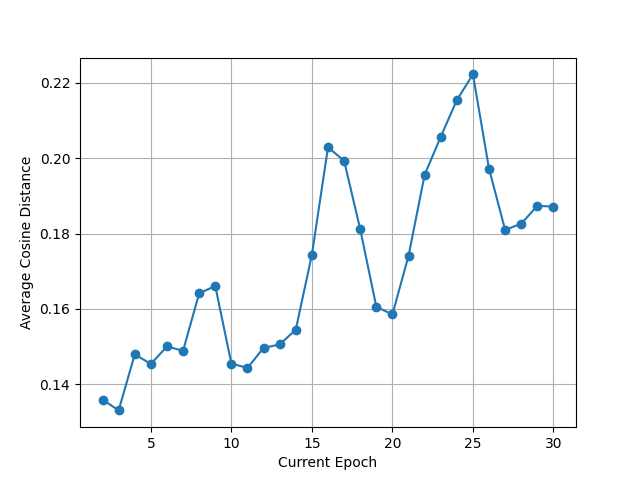
Fig 8: Average cosine distance of strategy embeddings
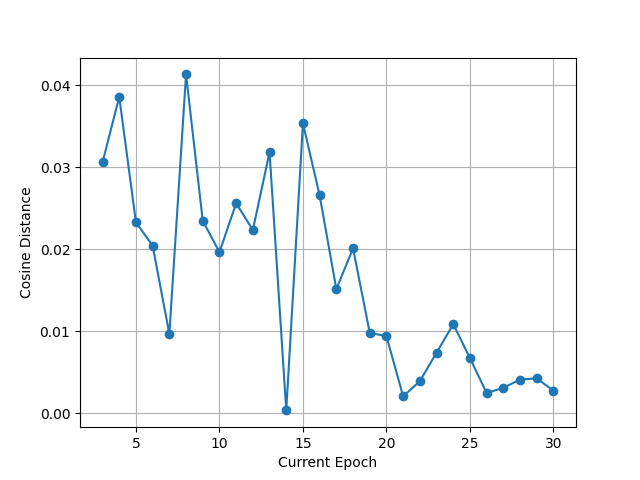
Fig 9: Cosine distance of prior knowledge embeddings
Limitations
- The victim, defender adaptation, and click-likelihood labels are all LLM-generated, so the evaluation is a simulation of human behavior rather than evidence from humans.
- The paper stops at “visit likelihood” and does not model whether a victim would submit credentials, install malware, or complete any downstream attack objective.
- There is no reported multi-seed analysis, confidence interval, or significance test in the excerpt, so the stability of the evolutionary trends is unclear.
- The chosen social-media mention setting is simpler than email/SMS spear phishing and may understate contextual complexity and real-world filters.
- The phishing URL is a fixed imaginary Amazon path, so the work does not evaluate domain reputation, URL shortening, brand impersonation, or page-content effects.
- The excerpt does not show direct comparisons against non-LLM evolutionary search, human-written strategies, or real phishing corpora, making it hard to isolate what the GA adds beyond better prompting.
Open questions / follow-ons
- How stable are the evolutionary trajectories across random seeds, different base LLMs, or different temperature settings for message generation?
- Would the same psychological-theory mutation pool transfer to email, SMS, or multilingual phishing, or is it specific to social-media mention framing?
- Can the attack-side GA be countered by a similarly evolved defense-side prompt or classifier, and if so does the asymmetry persist?
- Does optimizing for click likelihood on an LLM victim correlate with any measurable human susceptibility in controlled user studies?
Why it matters for bot defense
For bot-defense practitioners, the paper is useful less as a direct attack recipe and more as a stress-test generator for social-engineering defenses. It suggests that static phishing detectors and awareness copy can be probed against an evolving prompt population rather than a fixed template set, which is relevant if you want to evaluate whether a detector overfits to obvious urgency/scarcity cues. The strongest operational takeaway is that attacker prompts can drift toward personalization, confidence-building, and value alignment, so a defense strategy that only looks for blunt “urgent click this” language will miss later-generation variants. For CAPTCHA or bot-defense teams, this does not directly change challenge design, but it does reinforce that account-abuse defenses need to account for adaptive human-targeted lures, not just automated abuse at the endpoint. The main caution is that the whole framework is synthetic: it is best used to generate hypotheses and red-team prompts, not as a substitute for human-subject validation.
Cite
@article{arxiv2507_21538,
title={ Can We End the Cat-and-Mouse Game? Simulating Self-Evolving Phishing Attacks with LLMs and Genetic Algorithms },
author={ Seiji Sato and Tetsushi Ohki and Masakatsu Nishigaki },
journal={arXiv preprint arXiv:2507.21538},
year={ 2025 },
url={https://arxiv.org/abs/2507.21538}
}