
FacialMotionID: Identifying Users of Mixed Reality Headsets using Abstract Facial Motion Representations
Source: arXiv:2507.11138 · Published 2025-07-15 · By Adriano Castro, Simon Hanisch, Matin Fallahi, Thorsten Strufe
TL;DR
This paper studies whether the abstract facial-motion streams produced by mixed-reality headsets are privacy-sensitive behavioral biometrics, even when no raw video is exposed. The authors motivate the concern with a realistic MR sharing pipeline: inward-facing cameras are converted on-device into blendshape-style facial, eye, and head motion signals that avatar systems consume, and those signals may be observable by an application or service provider. The central question is whether these symbolic motion representations still retain enough person-specific signal to identify users or infer sensitive states.
To test that, they ran a three-session user study with 116 participants across three headset types and a mix of verbal and non-verbal tasks. They then evaluated user identification, cross-session re-identification, cross-device re-identification, and emotion inference from the collected motion data. The headline result is strong privacy leakage: users can be re-identified with up to 98% balanced accuracy, identification remains possible across device types, and emotional state can be inferred with up to 86% accuracy. In other words, the abstraction layer used for avatar animation is not a meaningful privacy boundary.
Key findings
- The study recruited 116 participants and collected motion data over up to 3 sessions; session participation dropped from 116 in session 1 to 83 in session 2 and 49 in session 3.
- Re-identification from abstract facial-motion data reached up to 98% balanced accuracy (reported in the abstract and main evaluation).
- The authors report that identification works across device types, i.e., users remain identifiable even when the headset changes.
- Emotion inference from the same motion data reached up to 86% accuracy.
- The study used three headset types: two Meta Quest Pro devices, one Pico 4 Enterprise, and one HTC Vive Pro Eye with Facial Tracker add-on.
- The dataset contains both verbal tasks (words and nursery rhymes) and non-verbal emotion tasks (happiness, anger, fear), enabling task-stratified analysis.
- The paper reports losing 19 recordings due to a Meta Quest Pro face/eye tracking malfunction, which affected data completeness and eye-tracking quality.
- The HTC Vive recordings from the first recording day had fewer blendshapes than later recordings because of a facial-motion recording issue on that day.
Threat model
The adversary is an observer or service provider who can access the abstract facial-motion stream exported by an MR headset and used for avatar animation, plus associated timing information for tasks or sessions. The adversary can train biometric classifiers on motion data and attempt to identify a user, re-identify them across sessions or devices, or infer their emotional state. The paper does not assume access to raw camera frames, direct sensor control, or the ability to alter the headset’s measurements; it studies leakage from the shared motion representation itself.
Methodology — deep read
Threat model and assumptions: the paper frames the adversary as an observer of facial-motion data shared by an MR application or service, such as a virtual store or social platform. The adversary is assumed to have access to the abstract motion representations used for avatar animation, not necessarily raw camera video. The attacker may attempt two classes of inference: identity disclosure (identification or re-identification, including across sessions and devices) and attribute disclosure (emotion recognition). The paper does not model active sensor spoofing, device compromise, or raw-camera reconstruction; instead, it studies what can be inferred from the exported motion stream itself.
Data collection and provenance: the authors ran a controlled user study at KIT between Jan 22 and Feb 14, 2025 in a dedicated lab. They recruited 116 participants (45 female, 71 male; mean age 23.6, std 4), with 67 native German speakers and a mix of self-reported personality traits. Participants were paid hourly plus bonuses for later sessions. Each participant could attend up to three sessions, spaced roughly a week apart, with actual inter-session gaps between 4 and 16 days. Participation decreased across sessions: 116 in session 1, 83 in session 2, and 49 in session 3. The study used four MR devices overall, but the experimental design exposed each participant to three device types: Meta Quest Pro, Pico 4 Enterprise, and HTC Vive Pro Eye with a facial tracker. Two headsets were used per session, with headset order counterbalanced by assigning participants to groups A and B.
Task design and preprocessing: each session contained a fixed battery of nine tasks repeated several times in random order. There were six verbal tasks (three words: sixpence, dinosaurs, muffin; and three nursery rhymes: Sing a Song of Sixpence, Dinosaurs, The Muffin Man) and three non-verbal tasks (happiness, anger, fear). The study intentionally emphasized verbal tasks because prior work suggested they carry stronger identity cues in facial motion. Each task began from a neutral face and the participant pressed a button to start/stop recording. Session 1 used four repetitions per task; sessions 2 and 3 used five repetitions per task. The raw export per session included unsegmented facial, eye, and head motion streams, task timestamps, microphone recordings, and metadata. Because headset data formats differed, the authors unified device-dependent facial/eye representations into a common schema (e.g., left/right blendshapes were averaged when a device emitted separate channels). They then segmented the motion streams into task-level clips using recorded start/end timestamps. For verbal tasks they further aligned audio to transcripts using WhisperX to transcribe the full recording, then Montreal Forced Aligner to obtain word/phoneme boundaries; these boundaries were converted back to motion timestamps. A concrete example would be: a participant utters the nursery rhyme “Sing a Song of Sixpence,” WhisperX produces the transcript, MFA aligns each word and phoneme to the audio, and the corresponding facial-motion samples in that time range become one labeled verbal segment for identification experiments.
Architecture / algorithm: the paper is primarily a privacy study, so the key “algorithmic” component is the experimental pipeline rather than a new neural architecture. The authors evaluate three biometric recognition models for identification (the exact model names are not fully visible in the truncated text, so the paper’s main contribution here is the benchmarking setup rather than a novel classifier). The facial-motion input is abstract, device-normalized time series over blendshape-like facial channels plus eye and head motion. The study compares performance on whole-task segments and on finer-grained word/phoneme segments for verbal tasks, which is important because it probes whether a user’s identity survives temporal subdivision and ASR-based alignment. For emotion inference, they treat the three expression tasks as classification targets.
Training regime and evaluation protocol: the source excerpt does not fully specify model hyperparameters, optimizer, number of epochs, batch size, or seed strategy, so those details cannot be recovered here without the full paper. What is clear is the evaluation structure: they test general identification, re-identification across sessions, and cross-device identification, and they also analyze which tasks are best for recognition. They report balanced accuracy for identification and accuracy for emotion recognition; for eye-gaze and MR motion literature in the related work they mention EER/F-score baselines, but the FacialMotionID results cited in the abstract are the 98% balanced accuracy and 86% emotion accuracy figures. The study also includes practical robustness issues as part of the evaluation context: one device-day had incomplete HTC Vive blendshape data, Meta Quest Pro eye calibration was often unreliable, and 19 recordings were lost due to a tracking malfunction. Those issues matter because they create nontrivial missingness and quality variation across devices and sessions.
Reproducibility: the excerpt does not mention code release, frozen model weights, or public dataset release, so reproducibility appears limited from the provided text. The apparatus is described in unusual detail, including Unity v2021.3.32f1, Meta Movement SDK v71.0.1 / Meta XR Core v71.0.0, Pico Unity Integration SDK v2.5.0, and VIVE OpenXR Plugin v2.0.0 with SRanipalRuntime v1.3.1.1, which helps replication. However, the exact downstream identification models, training settings, and whether the dataset will be made available are not visible in the truncated source, so those points remain unclear.
Technical innovations
- First study to analyze privacy leakage from abstract facial-motion representations used for MR avatar animation rather than raw face video.
- A three-session, three-device study design that explicitly tests both temporal stability and cross-headset identifiability of facial-motion biometrics.
- A unified preprocessing pipeline that normalizes vendor-specific facial and eye tracking outputs into a shared blendshape/gaze schema for downstream biometric experiments.
- Joint evaluation of identity disclosure and emotion inference on the same MR motion stream, showing that the privacy risk is not limited to re-identification.
Datasets
- FacialMotionID study dataset — 116 participants, up to 3 sessions, 3 headset types, 9 tasks per session with 4/5 repetitions; 19 recordings lost due to device malfunction — collected by the authors (non-public not stated in excerpt)
Baselines vs proposed
- Three biometric recognition models: identification up to 98% balanced accuracy vs reported emotion inference up to 86% accuracy on the same dataset (exact per-model values not visible in excerpt).
- Cross-session identification: possible across sessions with participants returning 4-16 days later; exact per-baseline numbers not visible in excerpt.
- Cross-device identification: possible across headset types; exact baseline comparisons not visible in excerpt.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2507.11138.

Fig 1: for an example). Integrating facial and eye motions
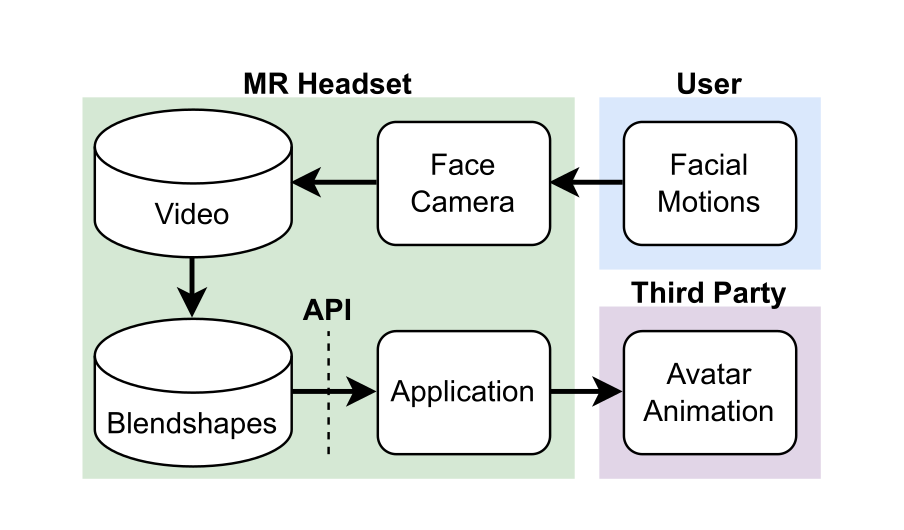
Fig 2: The data sharing pipeline of facial motion data captured by MR

Fig 3: A blendshape named “MouthRight” being activated on an MR

Fig 4: The participant performs

Fig 5: The participant performs
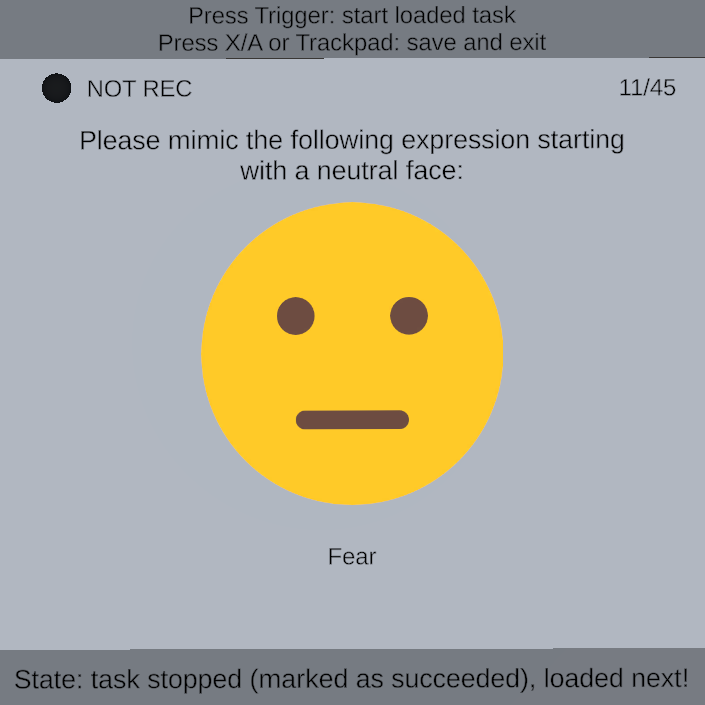
Fig 6: An example of a verbal task in which the participant is uttering
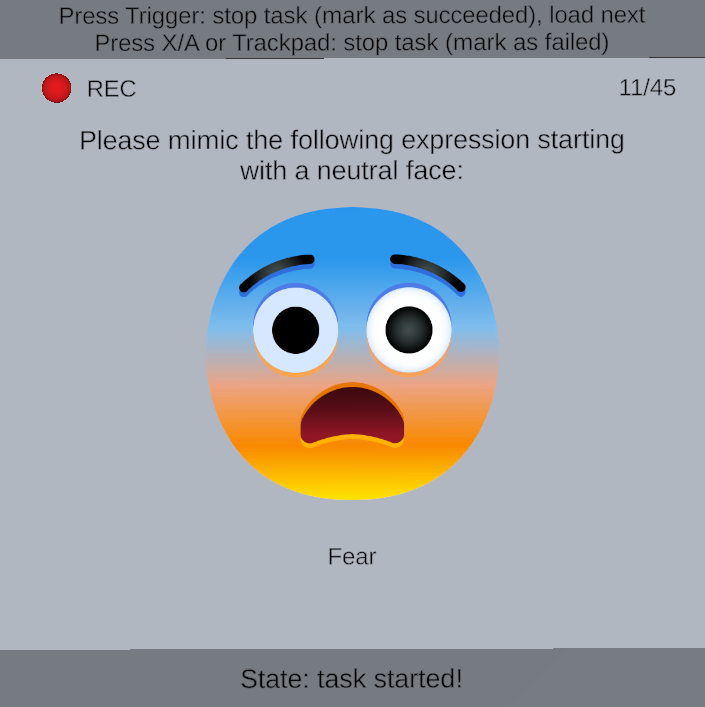
Fig 7: A participant performing the tasks with the HTC Vive Pro Eye.
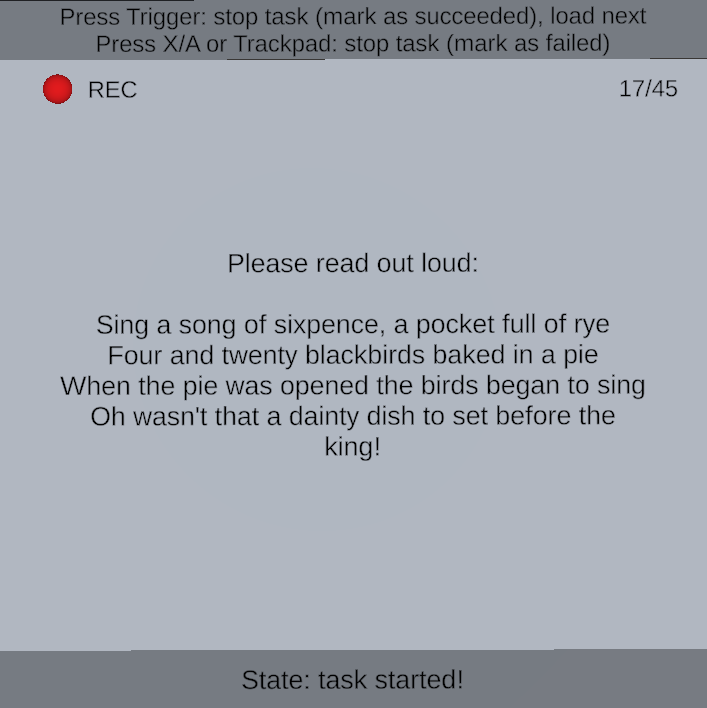
Fig 8 (page 5).
Limitations
- The excerpt does not expose the exact identification model architectures, hyperparameters, training epochs, or seeds, making replication of the classifier results incomplete from the provided text alone.
- The sample is moderately sized and convenience-based (116 participants from a KIT panel), with attrition across sessions; only 49 participants reached session 3.
- The study is lab-based and task-constrained, so it may overestimate identifiability relative to highly naturalistic MR use.
- Meta Quest Pro eye tracking had calibration problems and tracking malfunctions, and 19 recordings were lost, which may bias device comparisons.
- The paper focuses on identification and emotion inference, but does not evaluate stronger adversaries such as spoofing, model inversion, or raw-video reconstruction.
- The abstract and excerpt claim cross-device identifiability, but the exact per-device confusion patterns and statistical significance tests are not visible here.
Open questions / follow-ons
- How much identification remains if the motion stream is aggressively downsampled, quantized, or temporally perturbed before leaving the device?
- Which subset of blendshapes, eye channels, or head-motion channels contributes most to identity leakage, and can a minimal feature set preserve avatar quality while reducing leakage?
- Does the cross-device identifiability hold under stronger domain shift, such as different firmware versions, calibration routines, or user populations outside the lab?
- Can privacy-preserving transformations be learned that suppress identity while retaining emotion expressiveness for avatars?
Why it matters for bot defense
For a bot-defense engineer, the main takeaway is that MR facial-motion telemetry should be treated as a strong behavioral biometric, not as harmless animation metadata. If an application collects these streams, they can likely support user re-identification even when avatars are visually generic, so they are risky as a passive authenticator or as an auxiliary signal in account linking. That matters both offensively and defensively: attackers could use motion traces to track returning users, while defenders could consider them as a high-entropy signal for fraud detection, but only with explicit consent and a clear privacy model.
Practically, this paper argues for minimizing exposure of facial-motion data at the API boundary. If a CAPTCHA, liveness check, or abuse-detection system uses MR headset motion, you should assume the signal is identity-bearing across sessions and devices unless proven otherwise. A safer design would isolate feature extraction on-device, restrict export to task-specific aggregates, and test any proposed anonymization against cross-session and cross-device re-identification, not just against a single-session classifier.
Cite
@article{arxiv2507_11138,
title={ FacialMotionID: Identifying Users of Mixed Reality Headsets using Abstract Facial Motion Representations },
author={ Adriano Castro and Simon Hanisch and Matin Fallahi and Thorsten Strufe },
journal={arXiv preprint arXiv:2507.11138},
year={ 2025 },
url={https://arxiv.org/abs/2507.11138}
}