
BlowPrint: Blow-Based Multi-Factor Biometrics for Smartphone User Authentication
Source: arXiv:2507.04126 · Published 2025-07-05 · By Howard Halim, Eyasu Getahun Chekole, Daniël Reijsbergen, Jianying Zhou
TL;DR
BlowPrint tackles a pretty specific but practical problem in smartphone authentication: can a behavioral signal that is contactless, quick to perform, and hard to spoof be paired with a standard physiological biometric to improve mobile login security? The paper’s core idea is that the way a person blows on a phone microphone produces a distinctive acoustic trace, and that this trace can be used as a behavioral biometric. They pair this with face recognition, then fuse the two scores at the decision stage. The motivation is not just accuracy, but also usability and non-invasiveness: the user faces the camera and blows toward the mic in one shot, without extra sensors.
The reported results are strong on their own terms: on a 50-participant dataset, blow acoustics alone reached 99.35% accuracy with 0.42% FAR, face alone reached 99.96% accuracy with 0.04% FAR, and the fused system reached 99.82% accuracy with 0.18% FAR. The paper’s main claim is not that blow acoustics beats face recognition, but that it provides a new behavioral factor that can be combined with face to raise robustness while preserving smartphone-only deployment. The evaluation is promising, but it is still a controlled proof-of-concept with a small cohort and limited attack modeling.
Key findings
- The empirical study uses 50 participants (40 male, 10 female), each contributing 10 sessions, for a total of 500 session recordings split across sitting and standing conditions (5 sessions each).
- Blow-acoustic authentication alone reports 99.35% accuracy with 0.42% FAR in the main text; the abstract also states 99.59% accuracy, so the paper is internally inconsistent on this figure.
- Face recognition alone, using a pretrained FaceNet-512 embedding and cosine similarity, reports 99.96% accuracy with 0.04% FAR.
- Score-level fusion of blow acoustics and face recognition reports 99.82% accuracy with 0.18% FAR.
- The blow signal is recorded at 48 kHz, compressed to 0.02 s windows (960 samples per window), converted to RMS values, and smoothed with a simple moving average filter (window size 8).
- The paper evaluates multiple time-series similarity measures for blow acoustics: Euclidean Distance, DTW, shapeDTW, DTW+S, SBD, and TWED.
- Thresholds are user-specific and dynamically chosen from target recall values q = 10, 9, or 8 with k = 1 to 4 nearest neighbors, which means operating point selection directly affects FAR/FRR tradeoffs.
- The attack model substitutes other users’ blow patterns as proxies for an attacker who knows the device but not the victim’s blowing style; no real-world spoofing or replay study is reported.
Threat model
The adversary is assumed to have access to the smartphone running BlowPrint and to attempt biometric spoofing, replay, or duplication attacks without compromising the sensors or reading/manipulating stored biometric templates. The attacker may use synthetic face images, recorded blow sounds, or copied public facial photos, but is not assumed to know the victim’s live blowing pattern or to tamper with the microphone/camera pipeline. The paper does not model device compromise, sensor injection, or database exfiltration.
Methodology — deep read
Threat model first: the adversary is assumed to have access to the device running BlowPrint, but not to the stored biometric templates or sensors themselves. The attacker may try spoofing with synthetic face images, recorded blow sounds, or replicated blow patterns, and may also use publicly available facial imagery. The paper explicitly says the sensors are uncompromised and that biometric data is securely stored. What the attacker cannot do, under this model, is read or tamper with enrolled biometric data, or know the victim’s current blow pattern in advance. This is a fairly optimistic biometric threat model: it covers replay/spoofing conceptually, but not device compromise, sensor injection, template leakage, or side-channel style attacks.
Data collection is straightforward but limited in scale. The authors built an Android prototype app, BlowPrint, and recruited 50 participants (40 male, 10 female), aged roughly 22 to 65. Each participant completed 10 sessions of 5 seconds each: 5 while sitting and 5 while standing. During each session, the phone’s built-in microphone captured blow-acoustic signals while the front camera captured face images. The raw acoustic data were stored in CSV format; the paper says facial images were excluded from the released dataset for privacy reasons, and the dataset for the experiment is available online [11]. The paper does not describe a train/validation/test split in the classical machine-learning sense; instead, it evaluates authentication by comparing sessions against per-user enrollment templates and by testing all 490 sessions from other users as impostor attempts.
The blow-acoustic pipeline is the novel behavioral side. Audio is recorded at 48 kHz using Android’s AudioRecord, with amplitude values sampled every 0.02 seconds, producing 960 samples per window. Each window is reduced to a single scalar via RMS, yielding a 5-second signal, and then smoothed with a simple moving average (SMA) filter with window size 8 to reduce short-term fluctuations. Authentication is then done by comparing enrolled and query sequences using a family of time-series similarity measures: Euclidean Distance, DTW, shapeDTW (with a compound descriptor of raw values plus first derivatives), DTW+S, SBD, and TWED. The paper also shows illustrative raw and refined traces in Fig. 3 and Fig. 4, where a DBA-aggregated “Signature” is used only for visualization, not authentication.
The facial pipeline is conventional: faces are detected and cropped using Google ML Kit’s Android Face Detection Library, then passed through a pretrained FaceNet-512 model to produce 512-dimensional embeddings. Similarity is computed via cosine similarity between enrolled and query face embeddings. The multimodal design uses score-level fusion: the blow and face similarity scores are min-max normalized, then combined with equal-weight weighted summation. The fused score is then fed into a k-nearest neighbors classifier. A user-specific threshold τ is set dynamically based on k and a target recall value q, so the operating point is personalized rather than globally fixed. The paper doesn’t give enough detail on the exact kNN distance space or training procedure to fully reconstruct the classifier beyond this description.
Evaluation is centered on FAR, FRR, accuracy, and EER, but the authors explicitly argue that FAR matters more than EER in this setting because a false reject only costs the user a retry, whereas a false accept grants unauthorized access. Their impostor evaluation treats other participants’ blow traces as attacker attempts against each user’s enrolled template. They compare the candidate similarity algorithms under several k and q settings, then report which operating points provide the best tradeoff. The main reported outcomes are: blow acoustics 99.35% accuracy and 0.42% FAR, face 99.96% accuracy and 0.04% FAR, and fusion 99.82% accuracy and 0.18% FAR. However, the paper’s narrative appears internally inconsistent in at least one place: the introduction says blow acoustics achieves 99.59% accuracy, while the evaluation summary says 99.35%.
Reproducibility is partial. The app implementation is described in enough detail to recreate the Android-side capture pipeline, and the authors mention an online dataset [11] for the acoustic data. But the facial images are not released, the exact kNN configuration and some threshold-selection details are under-specified, and the paper does not appear to release code or frozen model artifacts in the excerpt provided. One concrete end-to-end example from the paper’s workflow is: a user aligns their face in the oval guide, blows for 5 seconds, the phone records audio and image data simultaneously, the audio is RMS-compressed and SMA-smoothed, the face is cropped and embedded with FaceNet-512, the two similarity scores are min-max normalized and fused, and the fused score is compared against a user-specific threshold to accept or reject the login.
Technical innovations
- Introduces phone-blowing acoustics as a new behavioral biometric modality for smartphone authentication.
- Combines blow acoustics with face recognition using score-level fusion instead of relying on either modality alone.
- Uses a smartphone-only capture pipeline with simultaneous microphone and front-camera acquisition in a one-shot authentication flow.
- Evaluates blow similarity using multiple time-series measures, including DTW variants, shapeDTW, SBD, and TWED, rather than assuming a single distance metric.
Datasets
- BlowPrint participant dataset — 50 participants, 500 sessions total (10 per participant) — collected by the authors; acoustic data released online, facial images withheld for privacy [11]
Baselines vs proposed
- Euclidean Distance: blow-auth accuracy not explicitly numerically reported in the excerpt vs proposed best blow-auth accuracy = 99.35%
- DTW: blow-auth accuracy not explicitly numerically reported in the excerpt vs proposed best blow-auth accuracy = 99.35%
- shapeDTW: blow-auth accuracy not explicitly numerically reported in the excerpt vs proposed best blow-auth accuracy = 99.35%
- DTW+S: blow-auth accuracy not explicitly numerically reported in the excerpt vs proposed best blow-auth accuracy = 99.35%
- SBD: blow-auth accuracy not explicitly numerically reported in the excerpt vs proposed best blow-auth accuracy = 99.35%
- TWED: blow-auth accuracy not explicitly numerically reported in the excerpt vs proposed best blow-auth accuracy = 99.35%
- FaceNet-512 face-only: accuracy = 99.96% vs proposed fused = 99.82%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2507.04126.
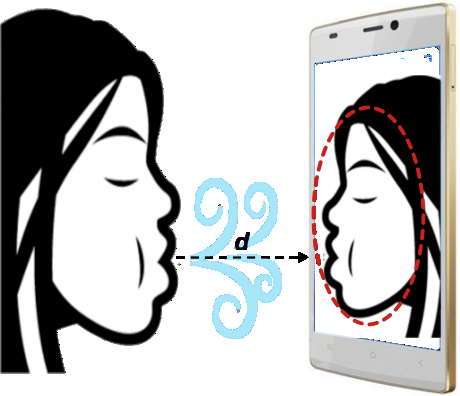
Fig 1: Illustration of BlowPrint
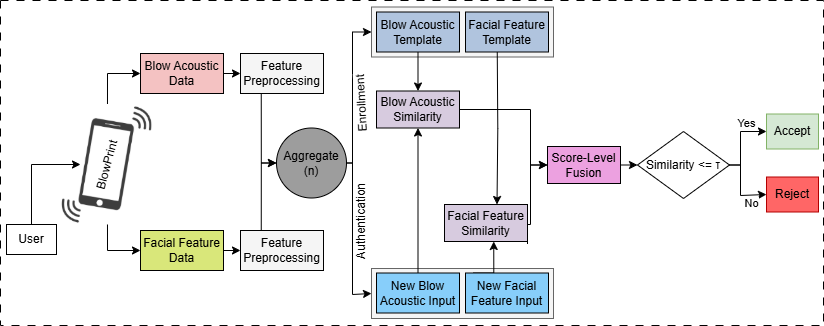
Fig 2: A high-level workflow of BlowPrint
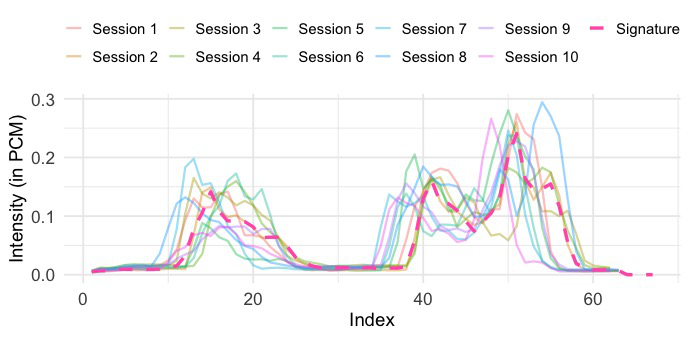
Fig 3: Sample raw blow-acoustic data of (a) Participant 1 (b) Participant 2 (c)
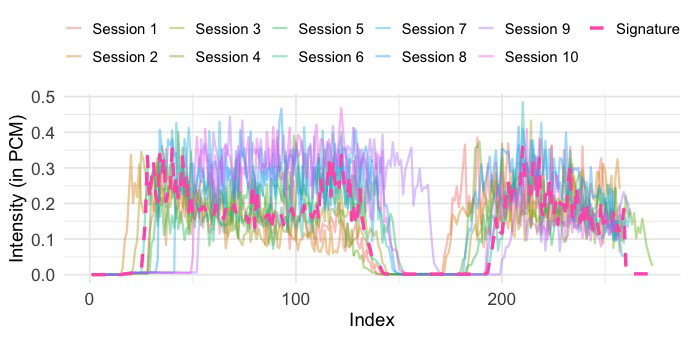
Fig 4: Sample refined blow-acoustic data of (a) Participant 1 (b) Participant 2 (c)
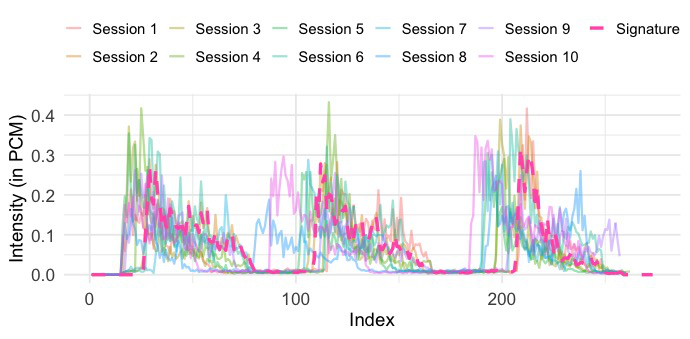
Fig 5 (page 13).
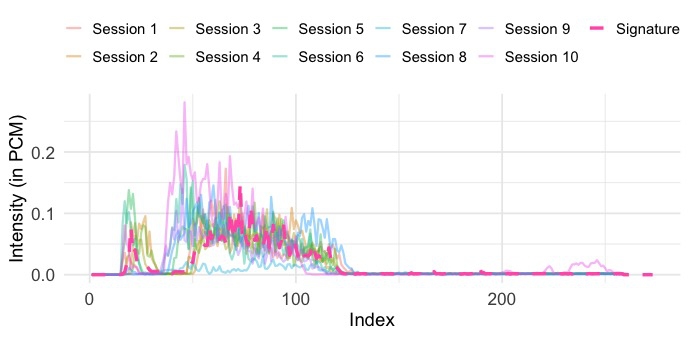
Fig 6 (page 13).
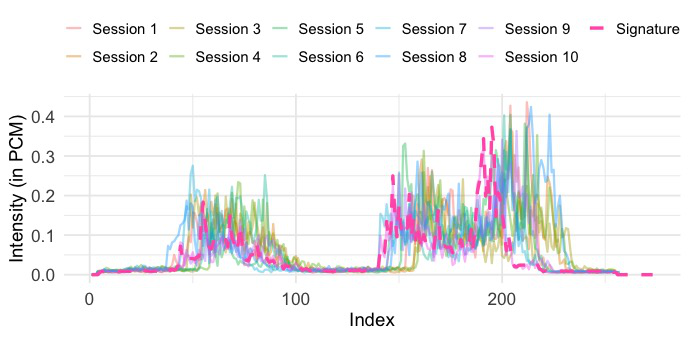
Fig 7 (page 13).
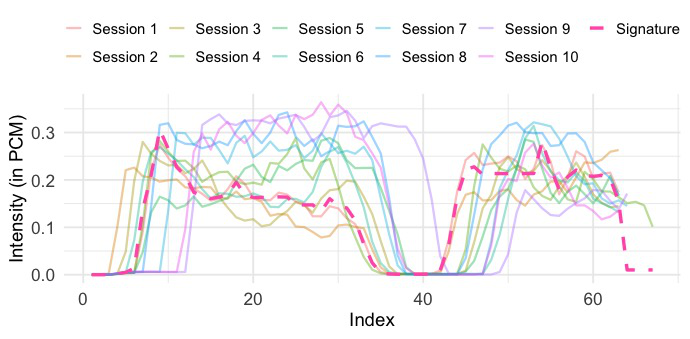
Fig 8 (page 13).
Limitations
- The evaluation is small-scale: only 50 participants, which is not enough to assess long-term robustness or population diversity.
- The attack evaluation is proxy-based; the paper does not report live spoofing, replay, deepfake, or adaptive adversary experiments on the system.
- The paper has at least one internal inconsistency in reported blow accuracy (99.35% in evaluation vs 99.59% in the introduction).
- Facial images are not publicly released, limiting reproducibility for the multimodal fusion pipeline.
- The threat model assumes secure sensors and secure storage, so it does not test compromise of the capture device or template database.
- There is no evidence of longitudinal testing across days/weeks/months, so temporal stability of blow behavior remains unclear.
Open questions / follow-ons
- How stable are blow-acoustic signatures across days, illnesses, hydration state, and different phone models or microphone placements?
- Can the system withstand adaptive spoofing where an attacker learns a victim’s blow profile from repeated observations or recordings?
- How much of the performance comes from face recognition versus the added value of blow acoustics under harder attacker settings?
- Would the modality still work if the user is moving, outdoors, or using noisy environments typical of real smartphone login?
Why it matters for bot defense
For bot-defense engineers, the main lesson is that “touchless” behavioral signals can be harvested from sensors people already use on phones, and those signals may be combined with conventional biometrics to create an authentication step that is harder to automate than a typed password or static face-only check. The idea is not directly a CAPTCHA replacement, but it is relevant to risk-based authentication: a product could ask for a quick blow gesture plus face capture when risk is elevated, turning a low-friction biometric into a step-up challenge.
At the same time, this paper also highlights a cautionary point for CAPTCHA practitioners: strong lab accuracy on a constrained dataset does not mean the modality is robust against adaptive automation, synthetic replay, or environmental shift. If a team wanted to use a similar idea defensively, they would need to validate against real attackers, device heterogeneity, and false-reject impacts in the wild. The fusion design is useful as a pattern: pair a behavioral signal that is hard to fake in real time with a physiological signal that supports liveness, but don’t assume the reported FAR/accuracy will survive outside a controlled study.
Cite
@article{arxiv2507_04126,
title={ BlowPrint: Blow-Based Multi-Factor Biometrics for Smartphone User Authentication },
author={ Howard Halim and Eyasu Getahun Chekole and Daniël Reijsbergen and Jianying Zhou },
journal={arXiv preprint arXiv:2507.04126},
year={ 2025 },
url={https://arxiv.org/abs/2507.04126}
}