
SafeTriage: Facial Video De-identification for Privacy-Preserving Stroke Triage
Source: arXiv:2506.16578 · Published 2025-06-19 · By Tongan Cai, Haomiao Ni, Wenchao Ma, Yuan Xue, Qian Ma, Rachel Leicht et al.
TL;DR
SafeTriage tackles a very specific privacy bottleneck in clinical AI: how to share and reuse facial video from suspected stroke patients without exposing identity, while still preserving the subtle facial asymmetries and motion patterns that clinicians and models use for triage. The paper’s central idea is to separate identity from motion. It uses a pretrained video motion transfer (VMT) model to copy motion from a real patient video onto a synthetic face, and then adds a conditional generative module to make that synthetic face better matched to the patient’s pose and visible facial structure. That conditional module is framed as a kind of visual prompt tuning: instead of fine-tuning the whole VMT backbone on private data, the method learns to generate a better input prompt using only public face data.
The result is a de-identification pipeline that is evaluated on 113 ER patient videos from Houston Methodist Hospital, with privacy checked via face-embedding similarity and utility checked via a DeepStroke stroke-triage model. The main empirical claim is that SafeTriage meaningfully lowers identity similarity between real and synthetic video frames while keeping stroke-classification performance close to the real-video baseline in the cross-domain settings that matter most. The strongest gains over the no-VPT ablation are in making synthetic-to-real and real-to-synthetic evaluation closer to baseline, although synthetic-to-synthetic performance still drops substantially, suggesting residual artifacts remain when both training and testing are done entirely on generated videos.
Key findings
- The study uses 113 ER patient videos from Houston Methodist Hospital, with 66 stroke and 47 non-stroke cases, all verified by diffusion-weighted MRI.
- Human realism ratings on 113 synthetic videos averaged 2.55/3.0 (std 0.65) from four CV-expert raters, and Fleiss’s kappa was 0.608.
- 38 of 113 synthetic videos were unanimously rated “Very realistic” and advanced to clinician review for diagnostic-pattern preservation.
- Clinician review of those 38 videos produced a mean score of 0.76 on a yes/no consistency check, indicating most synthetic videos preserved diagnostic motion patterns.
- Privacy evaluation with VGG-Face showed real-vs-synthetic frame-pair similarities dropped to below 0.6, versus high similarity for real-vs-real pairs; the paper references a default verification threshold of 0.68.
- For DeepStroke triage, the real-real baseline achieved 62.10% accuracy, 50.44% specificity, 71.10% sensitivity, F1 0.6869, and AUC 0.6885.
- With SafeTriage in the Syn-Real setting, performance was 62.06% accuracy, 49.78% specificity, 71.21% sensitivity, F1 0.6757, AUC 0.6800, and MSE 0.0875 versus 0 baseline.
- The no-VPT ablation was consistently worse than SafeTriage: Syn-Real MSE 0.1386 vs 0.0875, Real-Syn MSE 0.1358 vs 0.1058, and Syn-Syn MSE 0.1479 vs 0.1017.
- Training the triage model on synthetic videos and testing on real videos (Syn-Real) remained close to baseline, while training and testing on synthetic videos (Syn-Syn) dropped to 54.98% accuracy and 32.22% specificity even with SafeTriage.
Threat model
The adversary is a recipient of shared patient facial videos or a downstream researcher/service that may try to identify the patient from visible face cues or face embeddings, or use the synthetic clip to infer identity by matching against known faces. The system assumes the attacker sees the generated synthetic video and can compute similarity scores, but does not have access to private patient videos during training of the visual-prompt generator. It does not model a fully adaptive attacker with access to the internal generation parameters, nor does it provide a formal bound on re-identification risk.
Methodology — deep read
Threat model and assumptions: the paper is a privacy-preserving medical-video generation system, not a classical adversarial security proof. The implicit adversary is anyone who receives shared patient facial videos and may try to re-identify the subject or use raw facial appearance to infer identity. The method assumes the attacker may have access to the synthetic output, possibly multiple frames, and can compare them to face-recognition embeddings; the system is designed so that private patient data is never used to train the generative prompt model. What the attacker cannot do, by design, is access the original patient video during training of the visual prompt generator G, because G is trained only on public face data. The paper does not define a stronger adaptive adversary who knows the exact pipeline and tries inversion or linkage across datasets, and it does not provide a formal privacy guarantee.
Data and preprocessing: the empirical study uses an IRB-approved clinical dataset from Houston Methodist Hospital. Patients suspected of stroke are recorded in the ER while performing two speech tasks; the videos are captured at 1920×1200 and 30 fps, in unconstrained real-world conditions (patients may be lying in bed, sitting, or standing, with varying backgrounds and lighting). Ground truth stroke status comes from diffusion-weighted MRI. The cohort contains 113 patients total: 66 stroke and 47 non-stroke. Mean video length is 1,895 frames, about 63.16 seconds. For generation, the first frame of each patient video is used to derive pose and facial structure cues. The method preprocesses the driving video by removing constant camera roll, square-cropping the face with borders, and resizing to 512×512 before motion transfer. For prompt generation training, the authors use 2,000 face images from FFHQ, resized to 256×256. They also apply an image-quality filter and then enhance selected synthetic prompts with CodeFormer and upsample to 512×512.
Architecture / algorithm: SafeTriage has two main modules. First is a conditional synthetic face generator G, implemented with ControlNet on top of Stable Diffusion. Its inputs are two facial conditions extracted from the first frame of the patient video: landmark heatmaps and edge maps. Landmark heatmaps encode head pose; edge maps are extracted within bounding boxes around facial organs using Canny edges to capture facial asymmetries and wrinkles around the eyes, nose, mouth, and cheeks. The novelty is that the model is not asked to recreate the patient identity; instead, it synthesizes a pseudo-identity face that matches the patient’s geometry and visible asymmetry cues without using patient data for training. Second is the motion-transfer model M, implemented with LivePortrait, which is frozen. M takes the synthetic subject image s and the patient driving video d and outputs a retargeted video y whose identity comes from s and whose motion comes from d. Conceptually, the method uses the synthetic face as a visual prompt, analogous to prompt tuning in language models: the input is adapted rather than the backbone. The paper explicitly contrasts this with full fine-tuning, partial fine-tuning, and adapter-style additive fine-tuning, which they avoid because of computation and potential privacy-leakage concerns.
Training regime and concrete example: G is trained for 100 epochs with batch size 2 on two NVIDIA RTX 6000 GPUs, using only FFHQ and not any private patient data. The paper does not report optimizer, learning rate, or seed details for G. For the stroke classifier, they use the stand-alone video branch of DeepStroke, whose backbone is a ResNet-34 pretrained on FairFace; parameters are frozen except for the last residual block and output fully connected layer. They use five-fold cross-validation with a common manual seed so the fold splits are consistent. One end-to-end example described in the text is: take a suspected-stroke patient video of speech, extract landmarks and edge features from the first frame, generate a pseudo-identity face via ControlNet, then feed that face plus the patient motion video into LivePortrait to create a synthetic video. That synthetic clip is then evaluated by humans for realism, by VGG-Face for identity leakage, and by DeepStroke for whether the stroke decision matches the baseline trained/tested on real video.
Evaluation protocol and reproducibility: the evaluation is three-pronged. Human evaluation uses four raters with computer-vision expertise, scoring realism on a 3-point scale and then, for the subset unanimously rated “Very realistic,” asking a clinician whether diagnostic patterns are consistent with the original. Inter-rater agreement is reported with Fleiss’s kappa. Privacy is measured by cosine similarity of VGG-Face embeddings computed on random frame pairs, comparing real-real pairs from the same patient video to real-synthetic pairs. Diagnostic utility is tested with accuracy, specificity, sensitivity, F1, AUC, and MSE between prediction logits/probabilities and the real-video baseline. They report three synthetic regimes: Syn-Real, Real-Syn, and Syn-Syn, plus a no-VPT ablation using StyleGAN3-FFHQ synthetic faces instead of the conditional prompt generator. Reproducibility is partial: the authors say some code and examples are on GitHub, and they specify the public data source FFHQ plus the LivePortrait commit used, but the full patient dataset is not public in the text provided, and important implementation details such as optimizer settings, confidence intervals, and statistical significance tests are not reported.
Technical innovations
- Conditional visual-prompt tuning for facial video retargeting: a ControlNet-based face generator adapts the VMT input space using landmarks and edge maps instead of fine-tuning the motion-transfer backbone on patient data.
- Pathology-aware prompt conditions: edge maps are extracted around eyes, nose, mouth, and cheeks specifically to preserve facial asymmetries relevant to stroke triage, not just generic pose.
- Frozen-backbone motion transfer with LivePortrait: the method uses a pretrained VMT model to carry patient motion onto a synthetic identity, keeping patient identity out of the generation training loop.
- A privacy-utility evaluation pipeline that couples face-recognition similarity with downstream stroke-triage performance rather than relying only on visual realism.
Datasets
- Houston Methodist Hospital ER stroke-suspect facial video cohort — 113 patients (66 stroke, 47 non-stroke) — private/IRB-approved clinical dataset
- FFHQ — 2,000 face images used for ControlNet training — public dataset
- FairFace — public dataset used to pretrain the DeepStroke ResNet-34 backbone
- FaceNet — benchmark referenced for VGG-Face recognition accuracy, not used as the primary dataset in the paper
Baselines vs proposed
- DeepStroke real-real baseline: accuracy = 62.10% vs proposed (Syn-Real, SafeTriage) = 62.06%
- DeepStroke real-real baseline: specificity = 50.44% vs proposed (Syn-Real, SafeTriage) = 49.78%
- DeepStroke real-real baseline: sensitivity = 71.10% vs proposed (Syn-Real, SafeTriage) = 71.21%
- DeepStroke real-real baseline: F1 = 0.6869 vs proposed (Syn-Real, SafeTriage) = 0.6757
- DeepStroke real-real baseline: AUC = 0.6885 vs proposed (Syn-Real, SafeTriage) = 0.6800
- No-VPT ablation vs SafeTriage (Syn-Real): MSE = 0.1386 vs proposed = 0.0875
- No-VPT ablation vs SafeTriage (Real-Syn): MSE = 0.1358 vs proposed = 0.1058
- No-VPT ablation vs SafeTriage (Syn-Syn): MSE = 0.1479 vs proposed = 0.1017
- Human triage statistic (ER department, not the model): accuracy = 64.03% vs DeepStroke baseline = 62.10%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2506.16578.
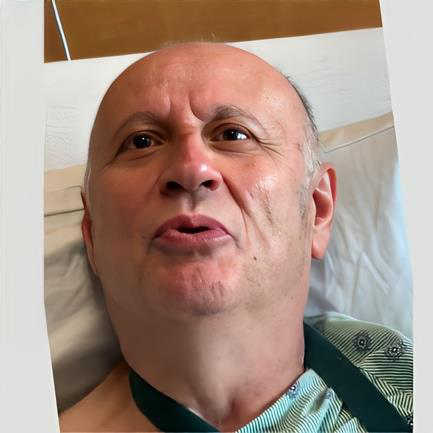
Fig 1: Illustration of the advantages of the SafeTriage framework. A direct application

Fig 2: Overview of the proposed SafeTriage framework, which comprises two main

Fig 3 (page 2).

Fig 3: Illustration of Visual Prompt Tuning. Given a subject image s and a driving
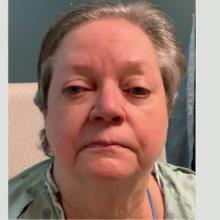
Fig 5 (page 3).

Fig 6 (page 3).
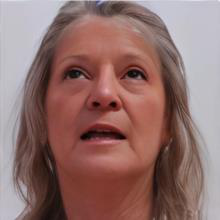
Fig 7 (page 3).

Fig 8 (page 3).
Limitations
- The paper does not provide a formal privacy guarantee; privacy is inferred from VGG-Face similarity dropping below the 0.68 threshold.
- The synthetic-vs-synthetic setting remains weak: SafeTriage still drops to 54.98% accuracy and 32.22% specificity, indicating artifacts accumulate when both training and testing rely on generated videos.
- The clinical human evaluation is narrow: only 38 synthetic videos were clinician-reviewed, and the task was binary consistency judgment rather than full diagnostic workflow assessment.
- Important training details are missing from the excerpt, including optimizer, learning rates, augmentation policy, and confidence intervals or significance tests.
- Generation quality is limited by the pretrained VMT backbone; the authors explicitly note that better motion-transfer models would likely improve results.
- The method currently handles only visual data and does not address audio de-identification, despite the speech-based nature of the underlying ER tasks.
Open questions / follow-ons
- Would a video-level identity metric or a stronger face-reidentification attack show the same privacy gap as the frame-level VGG-Face cosine similarity used here?
- How much of the remaining Syn-Syn drop is due to ControlNet prompt artifacts versus LivePortrait motion-transfer artifacts, and can either be isolated with ablations?
- Can the same prompt-tuning idea be extended to audio-video triage, where speech content may also be privacy-sensitive and diagnostically important?
- Would training G on a broader and more medically relevant public face corpus improve generalization to non-ER settings or different demographic distributions?
Why it matters for bot defense
For a bot-defense engineer, this paper is mainly relevant as a case study in separating identity from behavior while preserving task signal. SafeTriage is not about CAPTCHA directly, but the design pattern is useful: instead of trying to hide or blur all input, preserve the minimum motion/behavioral features needed for downstream classification and replace the identity layer with a synthetic surrogate. That’s analogous to building defense pipelines that keep liveness or interaction dynamics but suppress personally identifying signals.
The evaluation style is also instructive. They do not stop at visual quality; they test identity leakage and downstream utility separately, and they compare a conditional prompt approach against an unconditional synthetic-face ablation. For bot defense, that’s a good reminder that privacy-preserving transformations need two tests: whether they actually break linkability/recognition, and whether they leave the security-relevant signal intact. The paper’s weak spot for practitioners is that its privacy testing is still relatively shallow—frame-level face embedding similarity is not the same as a determined re-identification attack—so one should be cautious about adopting the same kind of argument in a high-stakes setting without stronger attacker models and video-level evaluation.
Cite
@article{arxiv2506_16578,
title={ SafeTriage: Facial Video De-identification for Privacy-Preserving Stroke Triage },
author={ Tongan Cai and Haomiao Ni and Wenchao Ma and Yuan Xue and Qian Ma and Rachel Leicht and Kelvin Wong and John Volpi and Stephen T. C. Wong and James Z. Wang and Sharon X. Huang },
journal={arXiv preprint arXiv:2506.16578},
year={ 2025 },
url={https://arxiv.org/abs/2506.16578}
}