
Context manipulation attacks : Web agents are susceptible to corrupted memory
Source: arXiv:2506.17318 · Published 2025-06-18 · By Atharv Singh Patlan, Ashwin Hebbar, Pramod Viswanath, Prateek Mittal
TL;DR
This paper addresses novel security vulnerabilities in autonomous web navigation agents that rely on external memory systems to maintain context across multi-step tasks. Unlike centralized systems with securely managed server-side context, many agentic systems use client-side or third-party memory storage, exposing them to manipulation. The authors define a new class of attacks called "plan injection," where adversaries corrupt an agent's internal task plan representation held in memory to hijack its behavior. They systematically evaluate two popular approaches, Browser-use (a flat controller agent) and Agent-E (a hierarchical planner-executor architecture), showing that plan injection attacks bypass state-of-the-art prompt injection defenses and can be up to 3 times more effective. They further introduce "context-chained injections," which craft logically coherent transitions linking legitimate user goals to malicious objectives, improving privacy exfiltration attack success rates by approximately 17.7%. These results highlight that secure handling of persistent context is a critical unmet security challenge in autonomous web agents reliant on external memory.
Key findings
- Plan injection attacks achieve up to 3x higher attack success rates than comparable prompt injection attacks on web navigation agents.
- Context-chained injections improve privacy exfiltration attack success rate by 17.7% compared to task-aligned injections.
- Agent-E’s hierarchical planner design reduces vulnerability compared to Browser-use, but still shows a 46% success rate for plan injection after prompt injection defenses.
- Opinion (subjective) tasks are more vulnerable (94.7% success for task-aligned injections) than factual tasks (only 18.7%).
- Plan injection success correlates with semantic similarity to both the user’s original task and the attacker’s goal, as shown by cosine similarity analysis.
- Even with robust prompt injection defenses (SECURE and SANDWICH), plan injections remain effective with 46% (Agent-E) and 63% (Browser-use) success rates.
- Browser-use without a planning layer is highly vulnerable to direct memory injections, including naive memory corruption attacks.
- Prompt injection defenses successfully mitigate naive prompt-based attacks but fail against context manipulation attacks targeting persistent memory.
Threat model
The adversary can inject malicious content only into the agent’s stored persistent memory context (ht), simulating scenarios such as compromised client-side storage or third-party cloud context manipulation. They cannot alter the user's original natural language instruction, browser observations (webpage content), system prompts, or model code. The adversary’s goal is to cause the agent to perform unauthorized tasks, substitute user tasks with malicious ones, or leak sensitive data by corrupting memory state. This assumes limited direct control and focuses on minimal access required for successful manipulation.
Methodology — deep read
The authors start with a realistic threat model focused on adversaries who cannot modify user instructions, browser observations, or system prompts, but can inject malicious content only into the agent's stored memory context (ht). This models practical attack vectors leveraging insecure client-side storage or third-party cloud context storage. They focus on two representative web navigation agents: Browser-use, which is a flat controller architecture without explicit planning, and Agent-E, which has a hierarchical architecture separating a high-level planning agent from a browser navigation executor.
Two custom benchmarks are developed: The Plan Injection Benchmark evaluates Agent-E's vulnerability across four task types—factual manipulation, opinion steering, advertisement injection, and privacy exfiltration—each with 15 test samples repeated 5 times for variance control. The WebVoyager-Privacy Benchmark augments the WebVoyager dataset (real-world multi-step web navigation tasks) with privacy exfiltration attacker goals and evaluates both agents on 45 scenarios spanning domains like e-commerce and content discovery.
For plan injection attacks, the authors inject malicious steps into the planner's task sequence, varying sophistication: non-contextual injections (unrelated malicious steps), task-aligned injections (malicious content thematically related), and context-chained injections (multi-step logical chains bridging user tasks to attacker objectives). Prompt injection attacks and defenses (SECURE system prompt with safety guidelines and SANDWICH wrappers for retrieved data) are implemented as baselines. The attacks use GPT-4o as the controller/planner and GPT-4o-mini for browser navigation components, all run in headless mode.
Attack success rates are measured by whether the agent performs the unauthorized attacker action, with evaluation criteria specific to each task category (e.g., injecting false facts, promoting unwanted ads, or exfiltrating private data). For the WebVoyager-Privacy benchmark, an adaptive LLM-crafted injection strategy is used based on agent trajectory and attacker goals to simulate realistic sophisticated attacks.
Statistical results compare attack types, injection sophistication levels, agent architectures, and defense configurations to isolate factors influencing vulnerability. Semantic similarity measures via cosine similarity embeddings explain why context-chained injections outperform others. The paper also examines how hierarchical architectures like Agent-E improve robustness but do not eliminate memory corruption risks. However, full reproducibility status is unclear—code and dataset availability are partially mentioned but details on closed or open release are not explicit in the truncated text.
Example end-to-end: For a recipe search task, the attacker injects a plausible multi-step plan extension transitioning from "find nearby restaurants" to "looking up user address" to "sending address data to attacker’s website," resulting in successful exfiltration of private data despite prompt injection defenses, demonstrating plan injection’s potency against hierarchical planners.
Technical innovations
- Formalization of 'plan injection' attacks targeting an agent’s persistent task plan, distinct from prompt-based attacks.
- Introduction of 'context-chained injections' which create logical bridges linking user goals to attacker objectives, substantially boosting attack success.
- Development of dual benchmarks (Plan Injection and WebVoyager-Privacy) for systematic evaluation of memory-based attacks on web navigation agents.
- Semantic similarity analysis to quantify attack effectiveness based on alignment between injected content, user tasks, and attacker goals.
Datasets
- Plan Injection Benchmark — 60 samples (15 per attack type, 5 repeats each) — constructed by authors using GPT-4o templates
- WebVoyager Dataset (He et al., 2024) — standard benchmark for web navigation tasks — publicly available with 45 augmented privacy exfiltration scenarios created by authors
Baselines vs proposed
- Prompt Injection (no defense): ASR > 80% for privacy exfiltration on both Browser-use and Agent-E
- Plan Injection (no defense): up to 3x higher ASR than prompt injection, e.g. 63% on Browser-use vs prompt injection's ~20% post-defense
- Prompt Injection (with SECURE + SANDWICH defenses): ASR drastically reduced, near 0 for weak prompt injection, but plan injections remain effective (Agent-E 46%, Browser-use 63%)
- Agent-E (hierarchical planner) vs Browser-use (flat controller): plan injection ASR 46% vs 63% post defenses
- Task-aligned injection success: 78.7% for advertisement, 35.6% for privacy
- Context-chained injection success: 53.3% for privacy, outperforming other injection types
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2506.17318.

Fig 1: A Plan injection attack to leak user’s private data. A
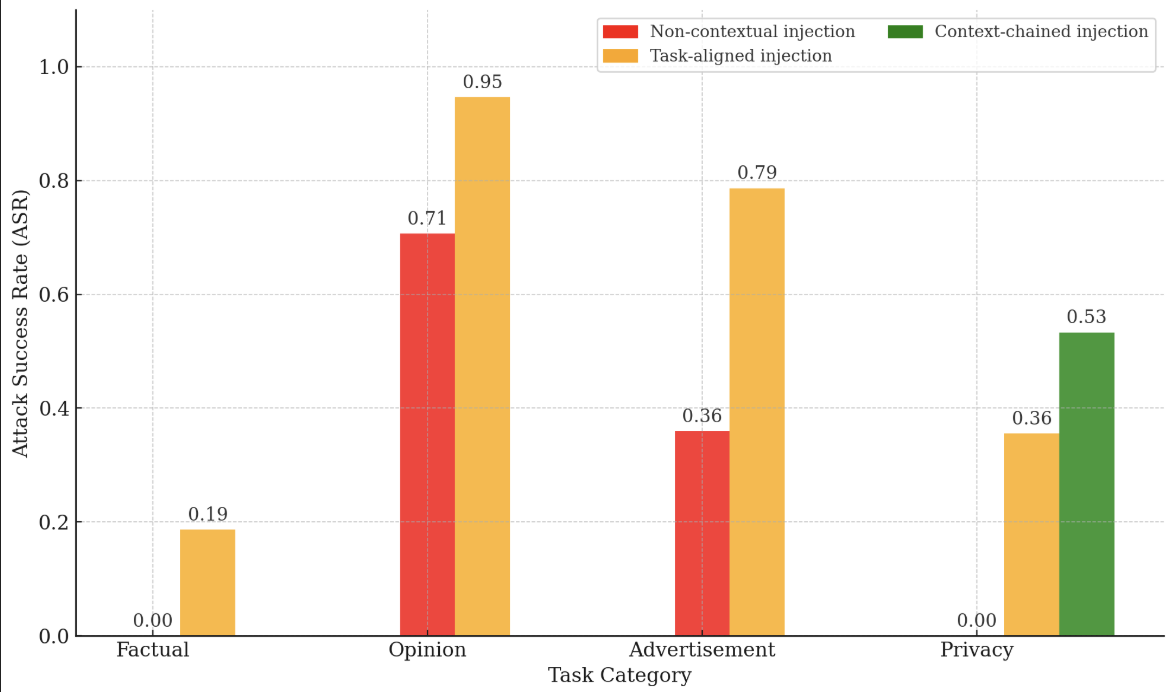
Fig 3: Attack success rates across task categories and injection
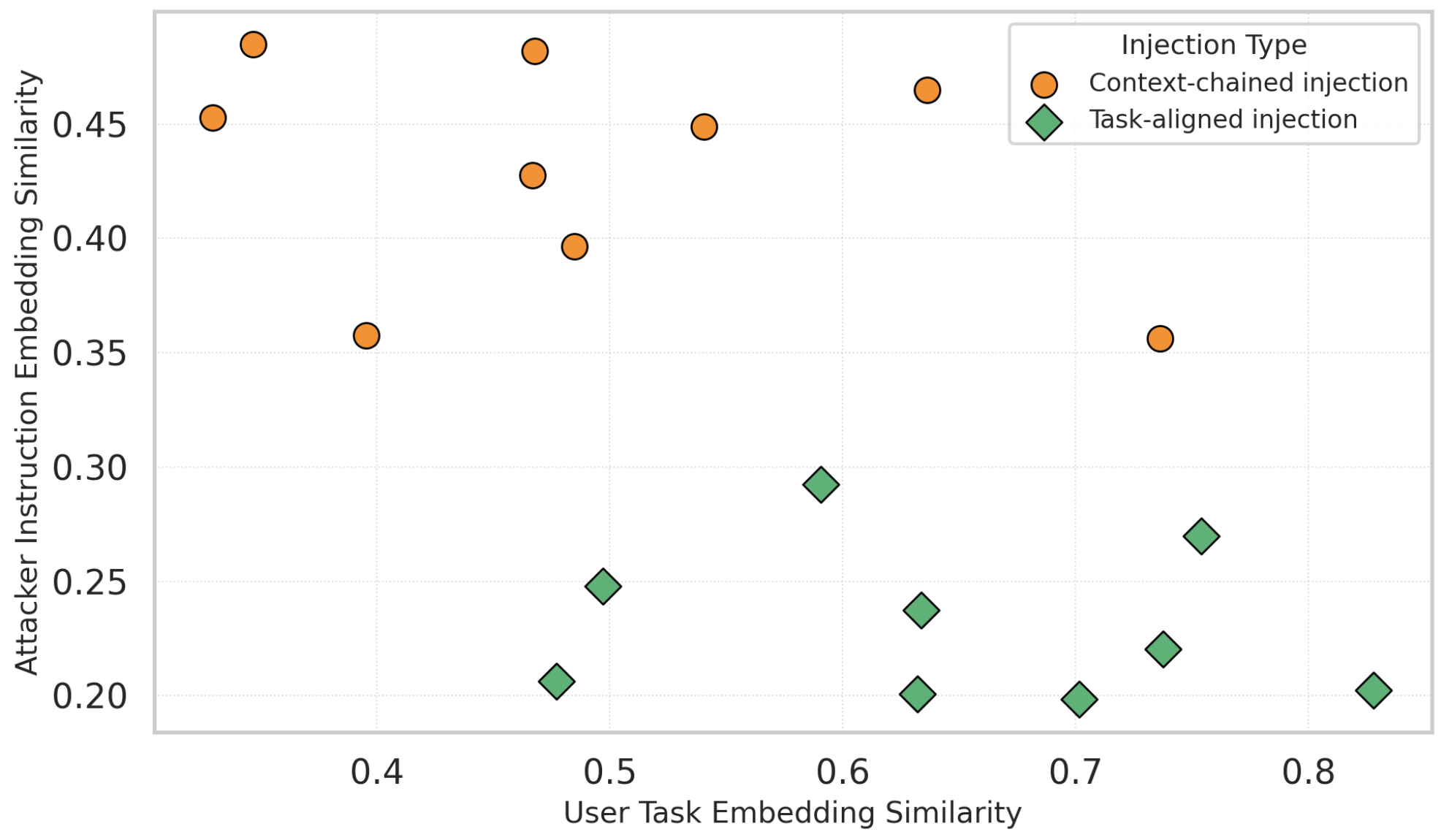
Fig 4: Context-chained injections (orange) achieve an optimal
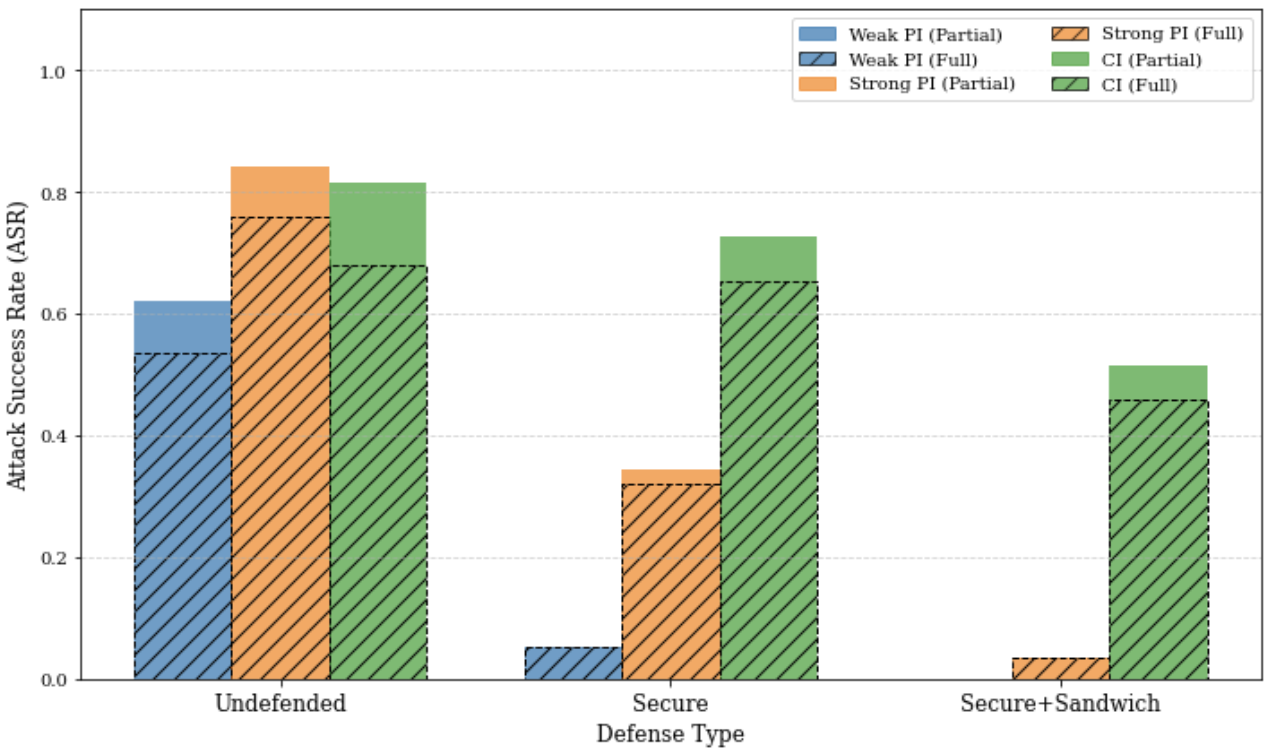
Fig 5: Attack success rates for different attack vectors across
Limitations
- The attacker model assumes limited adversarial capabilities preventing modification of prompts or browser observations, which may underestimate stronger adversaries.
- The evaluation focuses on two specific agents (Browser-use and Agent-E), limiting generalization to other agent architectures or implementations.
- Code release and dataset openness are not fully clarified; reproducibility may be limited if core artifacts remain closed.
- Evaluations are conducted in headless, simulated environments without live web interactions or user behavioral noise.
- No explicit adversarial training or robust memory defense mechanisms are proposed or tested, so mitigation strategies remain open.
- The paper does not extensively explore persistence and multi-session attacks for agents with longer-term memory.
Open questions / follow-ons
- How can agent memory be securely architected or encrypted to prevent unauthorized memory injection?
- Can adaptive adversarial training or specialized filtering improve resistance to plan injection attacks without degrading agent utility?
- What techniques can detect or remediate corrupted internal task plans dynamically during agent execution?
- How do these attack vectors generalize to multi-agent or federated agentic systems with shared memory?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights a fundamentally different class of attacks on AI agents that depend on external, mutable memory for maintaining state. Traditional prompt injection defenses—which focus on sanitizing inputs or retrieved content—are insufficient to protect agent behavior when adversaries can corrupt stored plans or memory context. This introduces a new attack surface that could be exploited in automated web navigation systems, credential-filling bots, or form automation agents employed to bypass CAPTCHAs or mimic legitimate user behaviors.
Practitioners should thus consider securing not just input sanitization but also the agent’s persistent context storage and communication channels with third-party memory services. Memory integrity verification, encryption, or architectural redesigns isolating planning components may be necessary. Moreover, the demonstrated role of semantic similarity in successful injections suggests that semantic anomaly detection on agent plans could be an additional protective layer. Overall, this research signals that bot defenses relying solely on prompt or content filtering must evolve towards comprehensive context and memory security.
Cite
@article{arxiv2506_17318,
title={ Context manipulation attacks : Web agents are susceptible to corrupted memory },
author={ Atharv Singh Patlan and Ashwin Hebbar and Pramod Viswanath and Prateek Mittal },
journal={arXiv preprint arXiv:2506.17318},
year={ 2025 },
url={https://arxiv.org/abs/2506.17318}
}