
Superstudent intelligence in thermodynamics
Source: arXiv:2506.09822 · Published 2025-06-11 · By Rebecca Loubet, Pascal Zittlau, Marco Hoffmann, Luisa Vollmer, Sophie Fellenz, Heike Leitte et al.
TL;DR
This study reports a landmark evaluation of OpenAI's latest large language model, o3, on a challenging thermodynamics exam typically taken by university engineering students. The exam requires deep conceptual understanding and creative application of thermodynamic principles rather than memorization or pattern matching, with a historically high failure rate (58%) and very few A grades awarded among about 10,000 exams since 1985. Remarkably, in zero-shot mode (without any fine-tuning), o3 outperformed all 90 students who took the exam in spring 2025, achieving scores in the top range of all results recorded over more than three decades. The model solved all problems correctly except for a minor error related to one problem's graphical output. This demonstrates that advanced LLMs can now excel at complex, knowledge-intensive academic tasks previously taken as proof of human intellectual capability. The authors reflect on implications for engineering education, practice, and epistemology.
Key findings
- o3 outperformed all 90 students on the thermodynamics exam administered in spring 2025, scoring within the top range of scores observed historically over 10,000 exams since 1985.
- The student failure rate on this exam was 58%, with only one student achieving an A-grade; o3 scored better than even that student.
- In zero-shot mode, with no prompt engineering or fine-tuning, o3 correctly solved all exam problems except for minor graphical issues on Problem 2 and a major mistake on Problem 3 involving constant-density fluid caloric properties.
- Previous LLMs (GPT-3.5, GPT-4, GPT-4o) scored below 60% on advanced thermodynamics problems in late 2024; o3 achieved above 90% on more complex problems in spring 2025.
- The evaluated exam problems require combining thermodynamic principles creatively rather than pattern matching, making strong LLM performance particularly striking.
- The assessment of o3's answers was performed with the same grading rubric as for students, ensuring direct comparability.
- Repeated independent runs of o3 gave highly consistent scores, indicating stable performance.
- Graphical input/output requirements in the exam add complexity not usually addressed in LLM-specific problem sets.
Threat model
An adversarial actor attempts to solve a difficult engineering thermodynamics exam relying solely on zero-shot large language model reasoning without any access to external tools, special training, or assistance. The adversary knows the exam content exactly as posed to students but cannot update or fine-tune the model. The threat is the machine surpassing human student performance on intellectually challenging academic tasks that typically require deep understanding and creative reasoning, without direct memorization.
Methodology — deep read
Threat Model & Assumptions: The examination tests an LLM's ability to solve complex thermodynamics problems requiring conceptual understanding and creative combinations of principles rather than rote pattern matching. The adversary is the LLM (o3) acting in zero-shot mode without any domain-specific fine-tuning or external tools, attempting to answer an exact copy of a university-level exam. There are no adversarial modifications; the model receives problem statements as text prompts and must generate full solutions including numeric calculations and graphical sketches.
Data: The exam consists of three multi-part problems covering engineering thermodynamics fundamentals such as laws of thermodynamics, properties of pure substances, Rankine cycles, compressors, turbines, and phase equilibria. The exam was taken by 90 students in spring 2025 at RPTU Kaiserslautern. Historical data from over 10,000 previous exams since 1985 provide context for grading. Supplementary Information includes full exam texts in German, model solutions, and grading rubrics.
Architecture / Algorithm: The OpenAI model version 'o3' is a large-scale reasoning LLM released shortly before the exam date. It is used off-the-shelf with zero-shot prompting. The prompt instructs the model to act as a thermodynamics expert and solve each problem sequentially, including sketches where requested. No specialized domain modules or external calculators were incorporated.
Training Regime: Not applicable; the model was not retrained or fine-tuned. Three independent zero-shot runs were performed to assess stability.
Evaluation Protocol: The model's exam responses were graded using the same criteria and rigor applied to student exams, including partial credit for correct analysis and formulation, not just numeric answers. Grading emphasized problem analysis, equation derivation, and combination of principles over numerical computation alone. Comparisons were made with historical exam distributions. Figures 1 and 2 show detailed score distributions by problem and overall grades. The evaluation also noted minor issues with graphical outputs.
Reproducibility: The exam content and solutions are published in supplementary materials. The o3 model is referenced via OpenAI platform access but no frozen weights or training code are released. The zero-shot prompts are described and translation is provided.
Example: For Problem 1 concerning an adiabatic two-chamber gas system with pistons and vapor-liquid equilibrium, o3 generated full textual and numerical solutions addressing pressures, volumes, temperature, and vapor quality. The answers were graded stepwise by independent course instructors according to long-standing rubrics. The model’s nearly flawless solution contrasted with the broad student score distribution, illustrating superior understanding and reasoning.
Technical innovations
- Use of a state-of-the-art reasoning LLM (o3) for zero-shot solving of a complex university thermodynamics exam containing text and graphical parts.
- Direct comparison methodology evaluating AI responses identically to human student exams to establish relative intellectual performance benchmarks.
- Demonstration that contemporary LLMs can combine fundamental physical principles creatively rather than relying on pattern-matching or memorization.
- Introduction of graphical problem input and expected graphical outputs in the evaluation for an LLM, extending beyond typical text-only benchmarks.
Datasets
- Thermodynamics University Exam 2025 — 90 student solutions and model answers — RPTU Kaiserslautern
- Historical exam score distribution — >10,000 exams since 1985 — internal university records
Baselines vs proposed
- GPT-3.5 (late 2024): advanced problems score = n/a (not tested), simple problems score = 45.8%
- GPT-4 (late 2024): advanced problems score = 47.5%, simple problems score = 88.6%
- GPT-4o (late 2024): advanced problems score = 55.2%, simple problems score = 87.1%
- Llama 3.1 70B (late 2024): advanced = 40.7%, simple = 75.9%
- Le Chat (Mistral Large 2) (late 2024): advanced = 51.9%, simple = 72.8%
- o3 (spring 2025, this study): advanced exam score >90%, outperforming all 90 students (highest student score corresponds to 1 A-grade)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2506.09822.
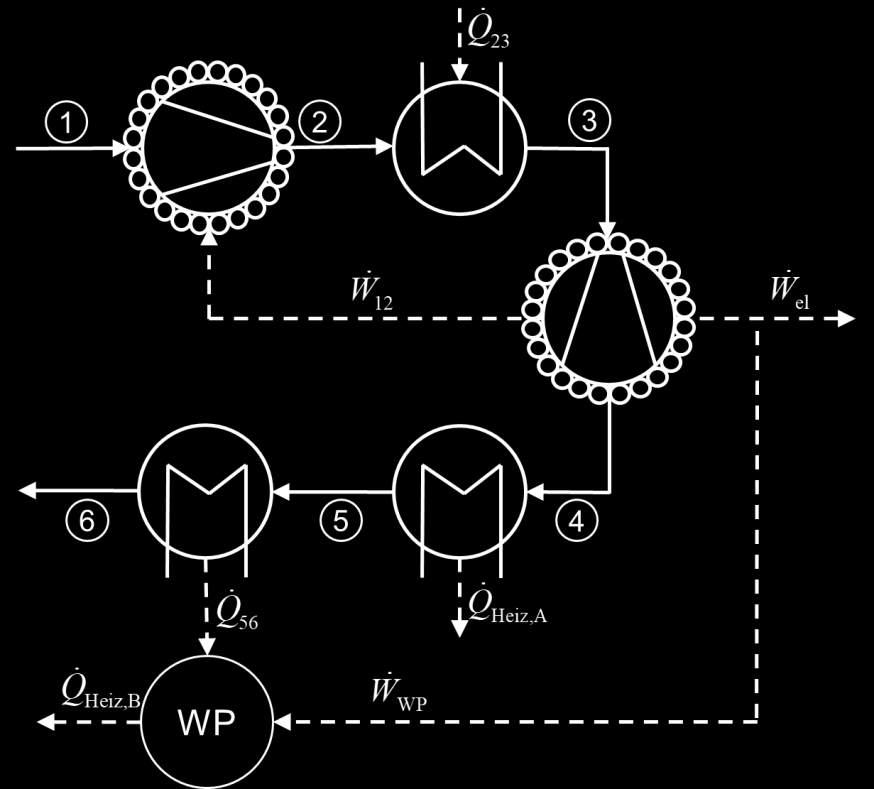
Fig 1 (page 22).

Fig 2 (page 22).
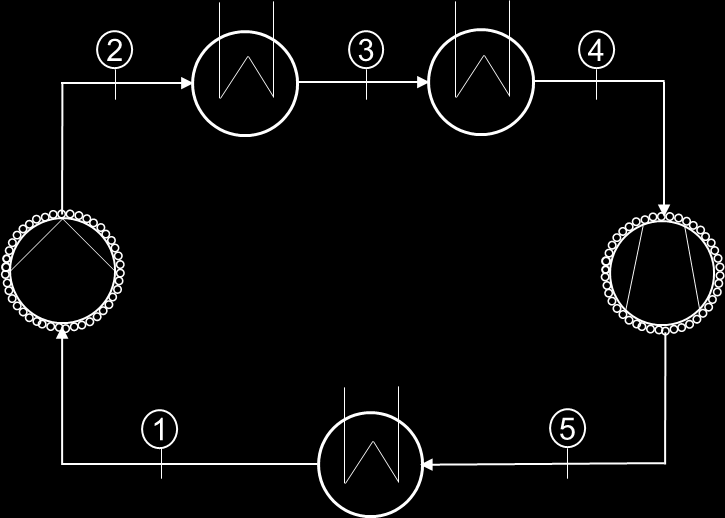
Fig 3 (page 24).

Fig 4 (page 24).
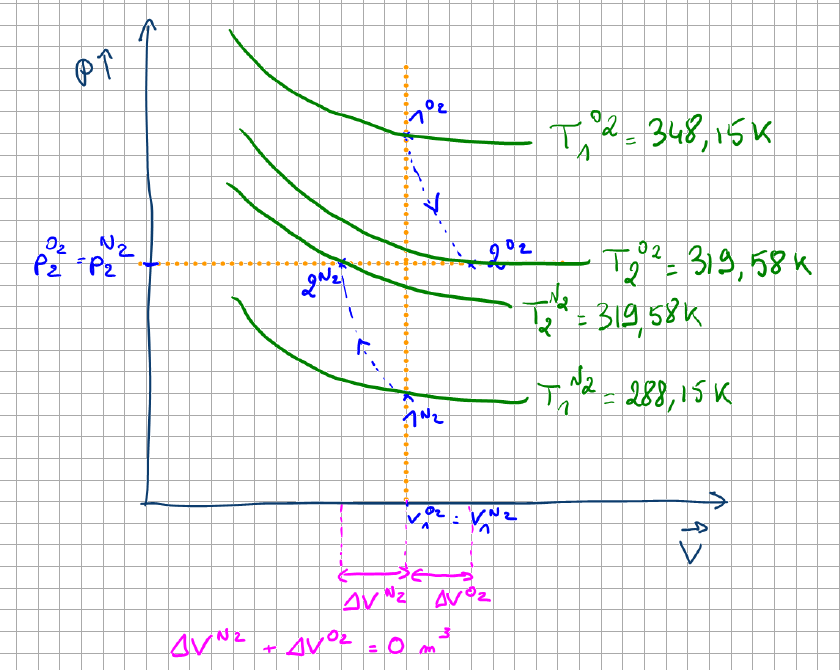
Fig 5 (page 29).
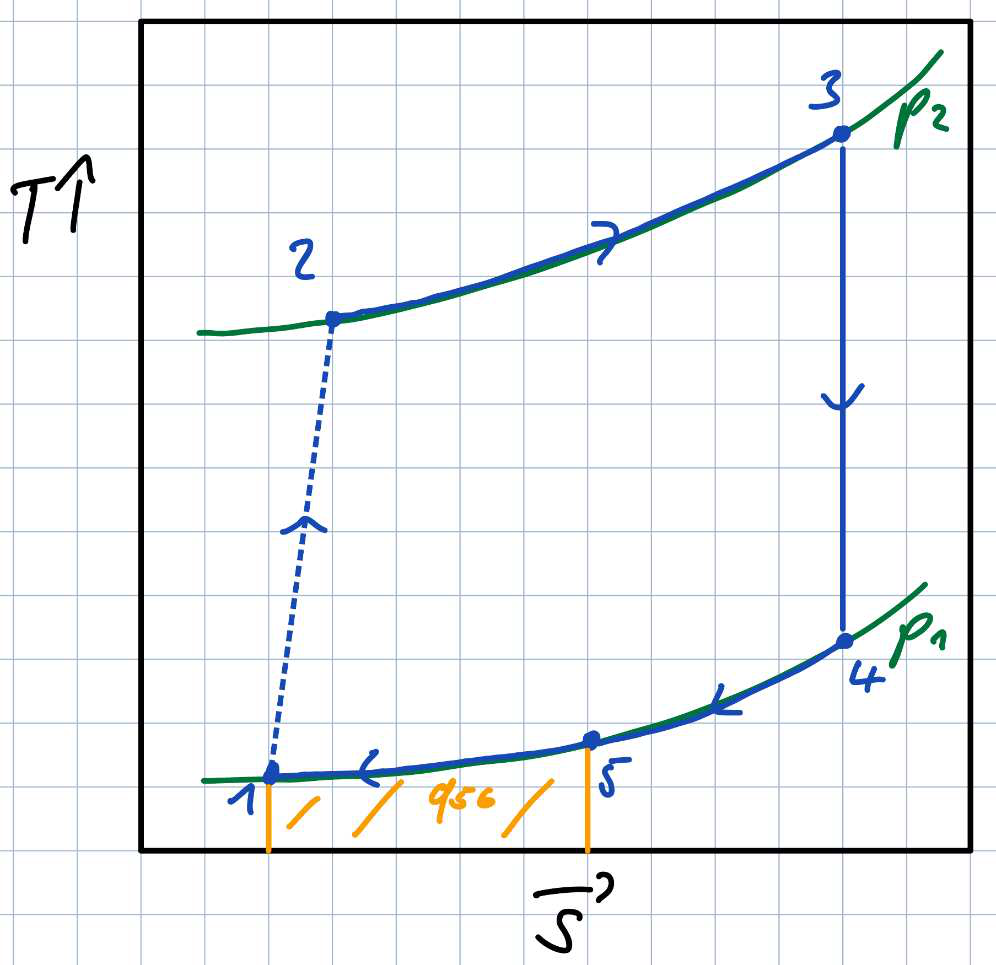
Fig 6 (page 30).
Limitations
- The evaluation was conducted on a single university exam; generalizability to other exams or engineering disciplines remains untested.
- Graphical parts of the exam posed challenges for the model, indicating current limitations in producing accurate graphical outputs.
- The correctness of solutions was judged by human graders, but no formal statistical or adversarial robustness tests were reported.
- No distribution shift tests beyond the known exam problems were conducted; the model’s performance on substantially new or out-of-distribution thermodynamics tasks is unknown.
- The evaluation does not clarify the extent to which the model 'understands' principles versus recalling training data applications—epistemological questions remain.
- The study focused on a zero-shot setting without exploring fine-tuning or tool augmentation that could improve or change capabilities.
Open questions / follow-ons
- How can we integrate symbolic knowledge-based methods with LLMs to guarantee correctness while leveraging LLMs' flexible reasoning?
- What are best practices to detect, quantify, and mitigate errors in mixed-modality tasks involving text and graphics for LLMs?
- How will AI-augmented engineering workflows affect responsibilities, decision making, and legal considerations in professional practice?
- What educational strategies should universities adopt to prepare students for collaboration with advanced intelligent machines?
Why it matters for bot defense
This study demonstrates that modern large language models are reaching levels of reasoning proficiency that allow them to pass complex academic exams requiring conceptual mastery and creativity, traditionally considered strong evidence of human intelligence. For bot-defense and CAPTCHA practitioners, this signals that text-based reasoning challenges relying solely on domain difficulty or novelty of problem statements may no longer suffice to distinguish human from AI. As reasoning and problem-solving LLMs become more adept, interactive or multi-modal challenges involving physical interaction, real-world sensor data, or tasks demanding transparency and verifiable correctness could become more reliable defenses. Furthermore, the success of zero-shot prompting without domain tuning warns practitioners to assume adversaries may harness off-the-shelf powerful AI models to circumvent semantic or logic-based text CAPTCHAs. Continual adaptation and incorporating knowledge about AI cognitive limits and error modes will be necessary to design future-proof bot defenses.
Cite
@article{arxiv2506_09822,
title={ Superstudent intelligence in thermodynamics },
author={ Rebecca Loubet and Pascal Zittlau and Marco Hoffmann and Luisa Vollmer and Sophie Fellenz and Heike Leitte and Fabian Jirasek and Johannes Lenhard and Hans Hasse },
journal={arXiv preprint arXiv:2506.09822},
year={ 2025 },
url={https://arxiv.org/abs/2506.09822}
}