
Risks & Benefits of LLMs & GenAI for Platform Integrity, Healthcare Diagnostics, Financial Trust and Compliance, Cybersecurity, Privacy & AI Safety: A Comprehensive Survey, Roadmap & Implementation Blueprint
Source: arXiv:2506.12088 · Published 2025-06-10 · By Kiarash Ahi
TL;DR
This paper is a broad survey and implementation blueprint about the dual-use impact of LLMs and GenAI on platform integrity, cybersecurity, privacy, financial compliance, and healthcare diagnostics. The core problem it addresses is not “can LLMs be useful?” but “how do we keep digital platforms trustworthy when the same tools that accelerate development, moderation, and compliance also accelerate abuse, fraud, and policy evasion?” The paper argues that app stores, e-commerce platforms, GenAI marketplaces, and financial services are all experiencing a sharp rise in AI-assisted scale, while regulators and trust-and-safety teams are struggling to keep up.
What is new here is the attempt to unify several previously siloed domains into one operational roadmap: review automation, static code analysis, storefront validation, policy auditing, fraud detection, cross-jurisdiction compliance, and even a clinical-diagnostics extension. The paper’s main result is not a single experimental breakthrough, but a synthesized blueprint: an imagined “LLM Design & Assurance (LLM-DA) stack” plus cross-functional governance processes. It supports its argument with many cited industry and media reports and with illustrative trend tables/figures, such as app submissions rising from 1.8 million in 2020 to a projected 3.6 million in 2025, AI-generated Google reviews rising from 1.42% in 2022 to 12.21% in 2023, and LLM-assisted malware projected to rise from 2% in 2021 to 50% by 2025.
The strongest contribution is strategic rather than empirical: it gives bot-defense, integrity, and compliance teams a taxonomy of threats and a proposed operating model for using LLMs defensively. The weakest point is that the paper does not provide a reproducible benchmark or a concrete end-to-end system evaluation for the proposed stack; most quantitative claims are drawn from external sources or are projections, and the clinical-diagnostics section remains conceptual.
Key findings
- Mobile app submissions are reported to rise from 1.8 million in 2020 to 3.0 million in 2024, with a projected 3.6 million in 2025 (Table 1, Fig. 1a).
- The paper reports LLM-assisted malware increasing from 2% of malware in 2021 to a projected 50% by 2025; Table 2 converts this to 1.666M cases in 2021 versus 110.6M projected in 2025.
- AI-generated Google reviews are reported at 1.42% in 2022 and 12.21% in 2023, with a projected 27%–30% in 2025 (Table 3, Fig. 2).
- AI-enabled scam reports increased 456% from May 2023 to April 2024, according to the cited TRM Labs source (Table 4).
- AI-generated email threats are described as a 31-fold increase in 2023, i.e. over 3,000% growth, per the cited Trend Micro source (Table 4).
- AI misinformation sites are reported as increasing over 1,500% from May 2023 to April 2024, per the cited NewsGuard source (Table 4).
- The paper claims platform-deployed LLMs can reduce fraud loss by up to 21% and accelerate onboarding by 40%–60% in financial workflows, citing platforms such as JPMorgan Chase, Stripe, and Plaid.
- Fig. 3 is used to compare abuse trends on a log scale across fake reviews, scams, deepfakes, misinformation sites, and email threats, emphasizing that the rise is not confined to one abuse class.
Threat model
The adversary is a malicious developer, spammer, scammer, fraudster, or malware author who can use off-the-shelf LLMs and GenAI tools to generate code, content, synthetic reviews, storefronts, policies, phishing artifacts, or deepfakes at scale. The adversary is assumed to have access to public model APIs or local open-source models and to adapt rapidly by making polymorphic variants to evade signatures and keyword filters. The defender is a platform or compliance operator with access to automated review and moderation systems, internal logs, policy documents, and possibly runtime analysis signals; the paper assumes the defender can deploy human-in-the-loop review but does not assume the attacker can compromise internal systems or bypass all logging and governance controls.
Methodology — deep read
The paper is a narrative survey plus roadmap paper, so its methodology is synthesis rather than a controlled experiment. The threat model is broad: malicious users, fraudsters, spam operators, malware authors, and deceptive developers who can use public LLMs or GenAI tools to generate code, reviews, listings, policies, phishing content, scam scripts, and synthetic media. The defenders are platform trust-and-safety teams, app-review pipelines, compliance teams, financial-risk teams, and in the clinical section, clinicians with AI support. The implicit assumption is that adversaries have access to the same general-purpose LLM capabilities as defenders, and that traditional keyword filters, signature-based malware detection, and manual review do not scale well enough against polymorphic, high-volume abuse.
Data-wise, there is no original dataset collection, no train/test split, and no labeled benchmark released by the authors. The paper instead aggregates figures and claims from “over 400” academic papers, industry reports, and technical documents, and it repeatedly cites external sources for statistics on app submissions, malware share, fake reviews, scam reports, misinformation sites, and deepfakes. The quantitative material is presented in tables and figures rather than as an experimental dataset. For example, Table 1 lists app submissions by year; Table 2 estimates annual malware detections and the LLM-assisted share; Table 3 lists the likely AI-generated share of Google reviews; Table 4 summarizes abuse trends and sources. The paper also references major platforms’ transparency reports and product pages, but it does not describe any preprocessing, sampling method, or annotation protocol for those external claims.
Architecturally, the main defensive proposal is a conceptual “LLM-DA” stack and a broader integrity workflow. The paper describes several modules: static code analysis using LLMs to inspect source code, bytecode, or AST-like structures for insecure flows and malicious logic; multimodal storefront validation that cross-checks text claims, screenshots, video, and runtime behavior; policy/document review automation that maps app policies to legal obligations like GDPR/CCPA/DSA; website/metadata correlation to detect inconsistencies; and automated rejection reasoning to generate clearer developer feedback. The text also proposes multi-LLM routing, agentic memory and planning, RAG evaluation, and audit/compliance tracking as stack components, but it does not specify model architectures, prompt formats, loss functions, or training objectives. In the clinical extension, the system is described as taking natural-language symptom descriptions, aligning them with image-derived biomarkers, and producing explainable recommendations under physician oversight; again, this is conceptual rather than implemented.
There is no reported training regime in the machine-learning sense. The paper does not state epochs, batch sizes, optimizers, learning rates, seed control, or hardware. Where it discusses fine-tuning, it does so at the level of possibility rather than an experiment: e.g. LLMs “can be fine-tuned” for app safety tasks or compliance parsing. Similarly, the proposed multi-agent compliance parsing is described as a network of specialized agents for jurisdiction-specific rules, but no orchestration algorithm or training curriculum is provided. Because the paper is not an empirical systems paper, there is also no documented ablation study isolating the contribution of one module versus another.
Evaluation is likewise illustrative rather than experimental. The paper references metrics that platform teams should care about—impact, speed, accuracy, fairness, reviewer fatigue, and compliance coverage—but does not report a unified benchmark. The closest thing to evaluation is the use of comparative trend figures (e.g. app-submission growth, malware share growth, review-fraud growth) and platform case studies. The paper cites examples like Google’s SAFE framework, App Defense Alliance, Play Protect, Apple’s review summarization and privacy work, and financial-platform fraud/compliance automation, but the comparisons are not standardized across a common dataset. No statistical tests, confidence intervals, cross-validation, or held-out attacker evaluation are provided.
For a concrete end-to-end example, the paper’s envisioned “multimodal storefront validation” would work as follows: an app developer submits an app with a textual description claiming “no data is collected,” screenshots showing an onboarding flow, and a privacy policy document; the LLM-based reviewer would parse the policy, compare it against screenshots and metadata, and then compare the declared behavior against runtime signals from dynamic analysis. If the policy says no location collection but the app requests location permissions and transmits GPS coordinates in logs, the system would flag a discrepancy, generate a rejection rationale, and route the case to a human reviewer. That entire workflow is described at a high level, but the paper does not provide an implementation trace, latency numbers, or measured false-positive/false-negative rates. Reproducibility is therefore limited: there is no code release, no frozen weights, no shared benchmark, and the dataset of cited sources is not packaged in a way that another team could directly reproduce the claims.
Technical innovations
- It proposes a unified cross-domain integrity blueprint that ties together app-store moderation, GenAI marketplace defense, e-commerce fraud control, compliance automation, and clinical AI governance instead of treating them as separate problems.
- It introduces the conceptual LLM-DA stack, described as an independent infrastructure layer for safety verification, compliance-as-code, multi-LLM routing, RAG evaluation, and audit tracking.
- It frames LLMs as both attack accelerators and defense accelerators, with specific defensive modules for semantic code analysis, multimodal storefront validation, and policy/document reasoning.
- It extends platform-integrity thinking into clinical diagnostics by proposing a multimodal symptom-to-biomarker mapping workflow with physician-in-the-loop oversight.
- It operationalizes integrity as a cross-functional process spanning product, engineering, trust & safety, legal, and policy teams rather than as a pure model problem.
Datasets
- No original dataset released — survey synthesis only — sources include over 400 academic papers, industry reports, and technical documents
- Table 1 mobile app submissions series — 2020-2025 projected — source not public in paper (aggregated from platform reporting)
- Table 2 annual malware detections — 2021-2025 projected — AV-TEST (as cited)
- Table 3 share of Google reviews likely AI-generated — 2021-2025 projected — Originality.ai / cited secondary source
- Table 4 scam, email threat, deepfake, and misinformation trends — 2023-2025 projected — TRM Labs, Trend Micro, Deep Instinct, Sumsub, NewsGuard (as cited)
Baselines vs proposed
- No controlled baseline comparison reported — only cited trend estimates and industry case studies
- Google reviews likely AI-generated: 1.42% (2022) vs proposed trend 27%–30% (2025 projection)
- LLM-assisted malware share: 2% (2021) vs proposed trend 50% (2025 projection)
- AI-enabled scam reports: 2023-May to 2024-April baseline vs +456% increase reported
- AI-generated email threats: 2022 vs 2023 baseline vs 31-fold increase reported
- AI misinformation sites: May 2023 to April 2024 baseline vs >1500% increase reported
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2506.12088.
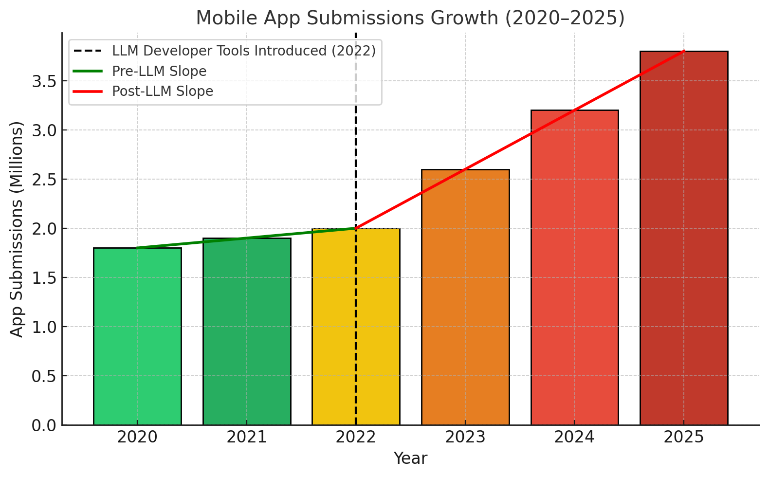
Fig 1: (a) Growth of Mobile App Submissions from 2020 to 2025,
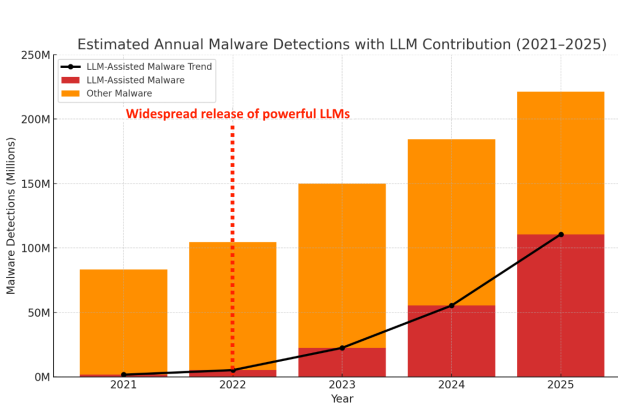
Fig 2: Percentage of Google reviews likely generated by AI from 2021 to
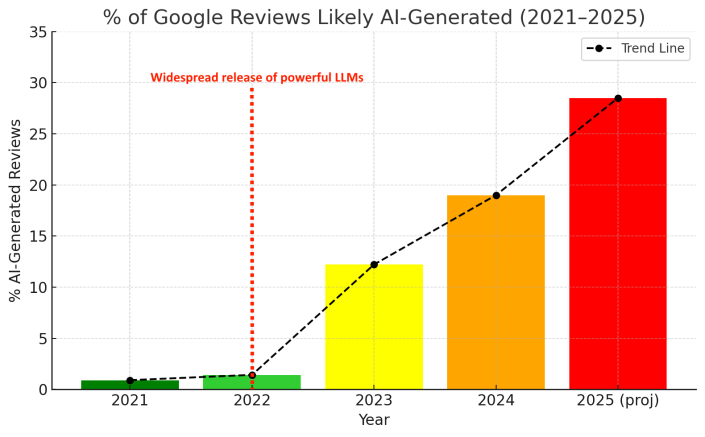
Fig 3: Log-scaled comparison of GenAI-driven abuse trends (2019–
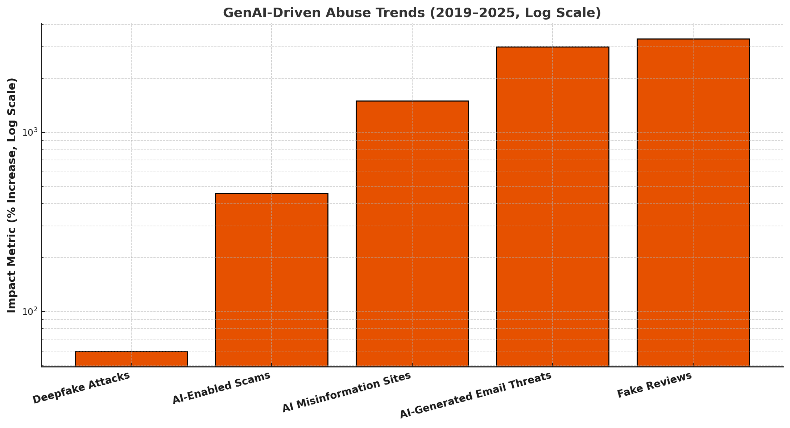
Fig 4: Dual-use nature of LLMs in app ecosystems: enabling both
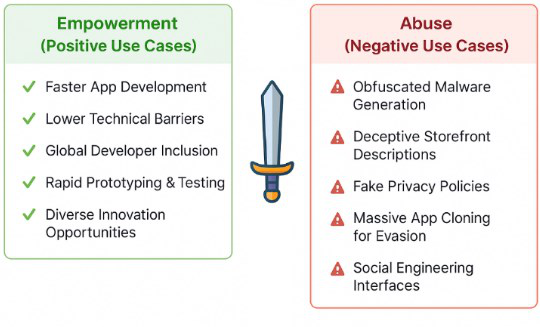
Fig 5: summarizes the principal types of LLM-enabled abuse

Fig 6: visualizes examples of storefront misrepresentation

Fig 7: illustrates how unsafe SDK integrations can expose apps
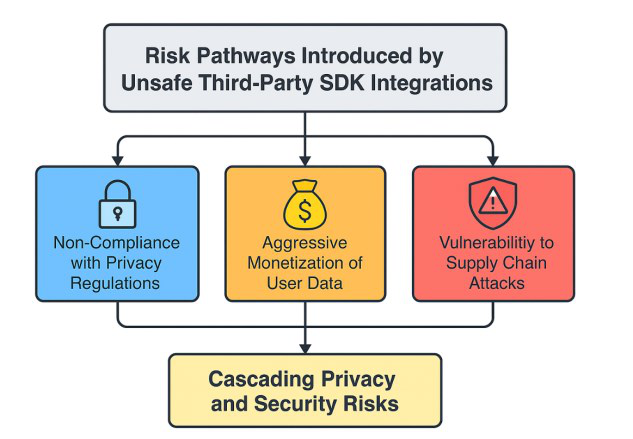
Fig 8: How LLMs enable polymorphic app variant generation for
Limitations
- No original experimental benchmark, so the proposed LLM-DA stack is not validated against a controlled baseline.
- Most quantitative claims are secondary citations or projections, so they are useful for trend framing but not for causal inference.
- The paper does not report data collection, labeling, or annotation reliability for any new dataset.
- Threats and defenses are described broadly, but the system-level details needed for deployment are largely unspecified.
- The clinical diagnostics extension is conceptual; there is no study of patient outcomes, calibration, or physician workload.
- The paper does not provide latency, cost, or throughput analysis for the proposed multi-LLM or multimodal review pipeline.
Open questions / follow-ons
- How accurate and cost-effective is LLM-based semantic code review compared with conventional static analysis and rule-based review at platform scale?
- What is the best way to evaluate multimodal storefront validation against adversarially optimized synthetic listings and screenshots?
- Can multi-agent compliance parsing be kept current across jurisdictions without producing inconsistent or contradictory enforcement decisions?
- How should platforms measure whether LLM-assisted moderation reduces abuse without increasing false positives, reviewer fatigue, or demographic bias?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the paper reinforces that abuse is moving toward higher-volume, higher-quality synthetic content, not just scripted requests. The practical takeaway is to treat LLMs as both an attacker tool and a reviewer-assistance tool: use them to reason over claims, policies, metadata, and multimodal evidence, but do not rely on them alone for hard enforcement. In CAPTCHA and anti-abuse systems, this means pairing model-based semantic analysis with stronger provenance signals, device and behavior telemetry, and human escalation for ambiguous cases.
The paper is especially relevant where CAPTCHA sits inside a broader trust pipeline: account creation, review submission, marketplace listings, app onboarding, and fraud/compliance workflows. A bot-defense team could use the roadmap to think beyond challenge-response and toward cross-checking the consistency of user claims across text, images, runtime behavior, and historical reputation. At the same time, the paper’s lack of benchmarks is a warning sign: if you adopt LLM-based moderation, you will need your own evaluation harness, adversarial test set, and error analysis before trusting it in enforcement.
Cite
@article{arxiv2506_12088,
title={ Risks & Benefits of LLMs & GenAI for Platform Integrity, Healthcare Diagnostics, Financial Trust and Compliance, Cybersecurity, Privacy & AI Safety: A Comprehensive Survey, Roadmap & Implementation Blueprint },
author={ Kiarash Ahi },
journal={arXiv preprint arXiv:2506.12088},
year={ 2025 },
url={https://arxiv.org/abs/2506.12088}
}