
Browser Fingerprinting Using WebAssembly
Source: arXiv:2506.00719 · Published 2025-05-31 · By Mordechai Guri, Dor Fibert
TL;DR
This paper studies browser fingerprinting through the timing behavior of WebAssembly (Wasm) and JavaScript interoperability. The core problem is that traditional web fingerprinting relies heavily on JavaScript performance measurements, which are noisy and unstable because of JIT compilation, engine optimizations, and platform variance. The authors argue that Wasm provides a better timing substrate because it executes closer to native speed and exposes implementation differences in browser engines, especially around function calls, setters/getters, argument adaptation, and memory access.
The main novelty is not a brand-new classifier, but a carefully chosen set of 20 Wasm-focused timing tests that amplify subtle differences across browsers, operating systems, CPUs, and virtualization stacks. The paper reports that the most discriminative signals are two WebAssembly-JavaScript setter tests, which behave very differently on Chromium-based browsers versus Firefox/Safari. In their evaluation across 158 browser instances and 25 physical devices, they show that the Wasm fingerprint can distinguish Chromium-based browsers even when the User-Agent is spoofed, with a false-positive rate below 1%, and can separate environments spanning Intel, AMD, ARM, Windows, macOS, Android, iOS, and common VMs.
Key findings
- The evaluation covers 158 browser instances built from 25 physical devices plus VM environments, with 20 WebAssembly timing tests per instance (Fig. 3, Table III).
- The paper’s strongest browser-family signal is from wasm-scripted-setter-1 and wasm-scripted-setter-2: on Chrome/Edge these ratios to wasm-scripted-getter-0 have mean 5.59 and 6.21, versus 1.67 and 1.98 on Firefox (Table IV).
- On bare-metal Windows Chrome, wasm-scripted-setter-1 and wasm-scripted-setter-2 average 152.21 ms and 161.14 ms, while the paper says other tests are around 19.54 ms on average (Fig. 4).
- On bare-metal Unix-like systems, Chrome’s wasm-scripted-setter tests are reported as 300–750% slower than the other timing tests, while Firefox and Safari are more consistent (Fig. 5).
- On VMs, Chrome and Edge show up to 570% increased times for wasm-scripted-setter tests versus other tests, while Firefox remains consistent across hypervisors (Fig. 6).
- On Android, wasm-scripted-setter tests are reported as 700–760% slower than the rest of the suite, indicating unusually strong separability on mobile Chromium builds (Fig. 7).
- The authors state the method distinguishes Chromium-based browsers from non-Chromium browsers even when identifiers such as the User-Agent are completely spoofed, with false-positive rate below 1% (abstract).
- iOS devices are the least separable environment in the qualitative discussion: timing results are described as more consistent across browsers, with mean times around 21 ms (Fig. 8).
Threat model
An active website operator or embedded script runner loads JavaScript and WebAssembly into a victim browser, measures execution timings of boundary-crossing operations, and uses the resulting fingerprint to identify the browser family, device type, or returning client. The adversary is assumed to observe local timing behavior and may face spoofed high-level identifiers such as the User-Agent. The paper does not assume the adversary can break the browser sandbox or access privileged local state.
Methodology — deep read
The threat model is an active web attacker: a server-controlled webpage delivers JavaScript and WebAssembly to a visiting browser, executes a battery of timing tests locally, and returns a timing vector to the server for classification. The attacker is assumed to know or control the fingerprinting code, can observe the browser’s execution timings, and may face spoofed identifiers such as a forged User-Agent. The paper’s explicit claim is that the fingerprint still separates Chromium-based browsers from non-Chromium browsers even under User-Agent spoofing. The paper does not frame a stronger adversary such as a user who blocks JavaScript/Wasm entirely, tampers with high-resolution timers, or runs anti-fingerprinting defenses; those cases are not empirically studied here.
The dataset is not a public benchmark in the usual sense; it is the authors’ own measurement corpus collected from real devices and VMs. They report 25 physical devices: 14 Windows PCs, 1 MacBook Pro, 6 Android devices, and 4 iOS devices, plus virtualized environments using VMWare, Hyper-V, VirtualBox, and KVM. The browser set includes Google Chrome, Microsoft Chromium Edge, Mozilla Firefox, and Apple Safari, with availability varying by OS (for example, Safari on macOS/iOS, and Chrome/Edge/Firefox on Windows, Linux, Android, and macOS). Figure 3 summarizes 158 browser instances, each running 20 timing tests listed in Table II. The paper does not give a train/validation/test split in the excerpt provided; instead, the evaluation appears to be exploratory/measurement-based rather than a standard supervised ML benchmark with held-out splits. Preprocessing is minimal and mostly consists of aggregating raw execution times into feature vectors; for some analysis they compute ratios such as scripted-setter / scripted-getter and compare distributions (Table IV).
The architecture is a fingerprinting pipeline rather than a deep model. The client receives HTML plus JavaScript and Wasm, then runs a sequence of timing tests that exercise different interaction paths between JavaScript and WebAssembly. The tests are intentionally diverse: Wasm calling into JS builtins (e.g., Math.cos), JS calling Wasm functions with monomorphic and polymorphic signatures, Function.prototype.call/apply variants with expected vs unexpected arity, scripted getters/setters backed by Wasm exports, and a small arithmetic conditional test. The novelty is in exploiting browser-engine differences in how these calls are optimized or adapted. The paper repeatedly emphasizes that the most sensitive tests are the scripted-setter cases, because they trigger pronounced timing gaps between browser families. Algorithm 1 is just timing collection: for each test, record start time, execute the test, record end time, and store the delta in a vector fp. The vector is then compared against a database of known fingerprints using Euclidean distance, cosine similarity, or Mahalanobis distance; the authors also mention PCA as a dimensionality-reduction option before matching.
One concrete end-to-end example is Algorithm 2, the wasm-scripted-setter tests. The browser loads a Wasm module exporting setter functions, then JavaScript creates an object with Object.defineProperty and assigns the exported Wasm function as the property setter. The code repeatedly writes to GETSET.x inside a loop, which triggers the Wasm-backed setter many times. The authors argue that the way different engines bridge JS property access and Wasm exports creates measurable timing differences. Their empirical observation is that on Chrome and Edge this operation is much slower relative to a simple Wasm getter than on Firefox. Table IV quantifies this: for scripted-setter-1 divided by scripted-getter-0, the mean ratio is 5.59 for Chrome+Edge but 1.67 for Firefox; for scripted-setter-2 divided by scripted-getter-0, the mean ratio is 6.21 for Chrome+Edge but 1.98 for Firefox. That ratio-based separation is the clearest numerical evidence in the provided text.
Evaluation is primarily descriptive and comparative across environments, with figures showing timing distributions for Windows bare metal, Unix-like bare metal, VMs, Android, and iOS. The paper compares browser families qualitatively and via summary statistics rather than reporting classifier AUC/accuracy for a clearly defined train/test protocol in the excerpt. The authors do, however, explicitly note a false-positive rate below 1% for distinguishing Chromium-based browsers under spoofed identifiers. The use of 158 browser instances suggests a broad cross-product of device/OS/browser combinations, but the exact per-class sample counts, timing repetitions per test, and any randomization/seed strategy are not fully specified in the excerpt. Reproducibility is limited by the lack of a public dataset or code statement in the provided text; no frozen weights are relevant because the method is rule-based/distance-based rather than a learned model.
Technical innovations
- A WebAssembly-centric browser fingerprint that focuses on JS↔Wasm boundary behavior instead of generic JavaScript microbenchmarks.
- A 20-test timing suite covering wasm-to-js calls, monomorphic/generic call paths, Function.prototype.call/apply variants, scripted getters/setters, and a small arithmetic branch test.
- A practical discriminator between Chromium-based and non-Chromium browsers using the unusually slow wasm-scripted-setter tests.
- A distance-based identification scheme over timing vectors, with optional Mahalanobis distance and PCA for robustness against correlated timing noise.
Datasets
- Author-collected browser timing corpus — 158 browser instances across 25 physical devices plus VM instances — non-public, collected by the authors
Baselines vs proposed
- Firefox vs Chrome+Edge on scripted-setter-1 / scripted-getter-0: mean = 1.67 vs proposed = 5.59 (Table IV)
- Firefox vs Chrome+Edge on scripted-setter-2 / scripted-getter-0: mean = 1.98 vs proposed = 6.21 (Table IV)
- Bare-metal Windows average non-setter tests: mean = 19.54 ms vs proposed scripted-setter tests = 152.21 ms and 161.14 ms (Fig. 4)
- Android timing suite: non-setter tests vs proposed scripted-setter tests = 700–760% slower (Fig. 7)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2506.00719.
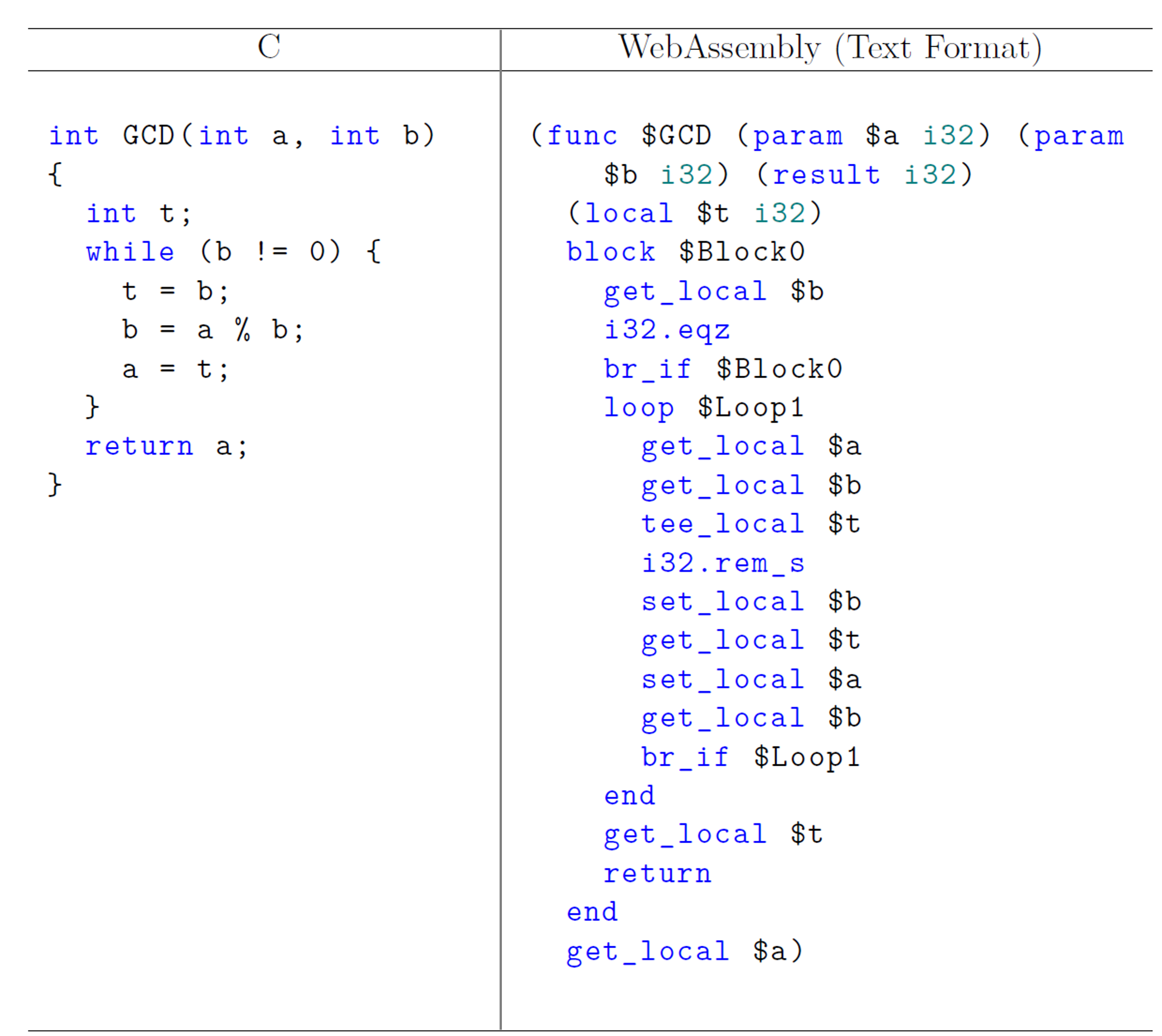
Fig 1: Euclid’s GCD algorithm implemented in C and its
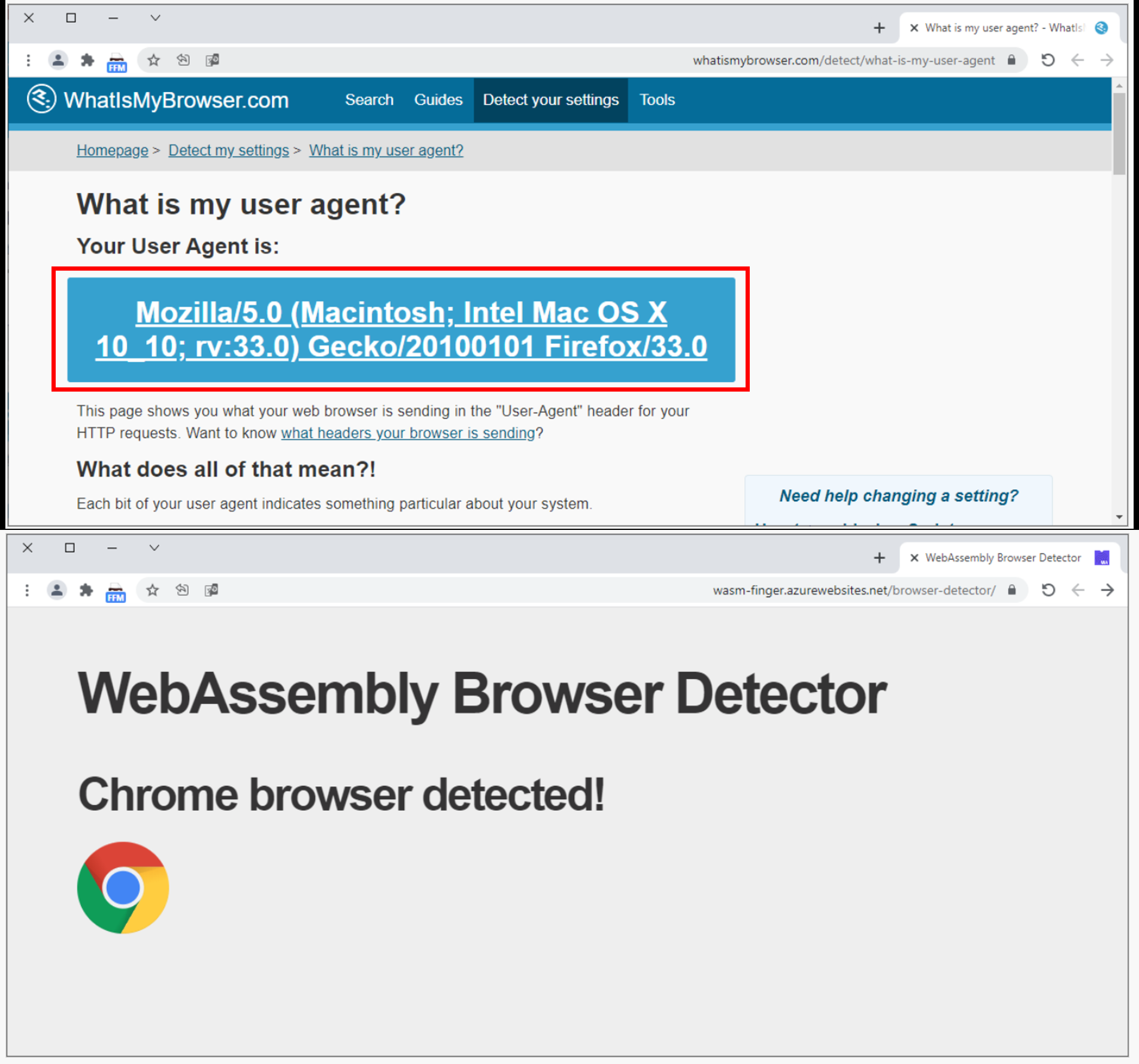
Fig 9: shows the screenshot of a browser with reported
Limitations
- The provided text does not specify a standard supervised evaluation protocol, so reported separability may not translate directly into out-of-sample classification accuracy under a stricter benchmark.
- The dataset appears to be author-collected and non-public, which limits independent replication and makes it hard to assess coverage bias.
- The method depends on timing measurements that may be degraded by timer clamping, background load, power-saving modes, or browser privacy defenses; these conditions are not evaluated here.
- The strongest distinctions are reported for Chromium vs non-Chromium browsers; finer-grained browser-version or device-model identification is less clearly quantified in the excerpt.
- iOS appears less separable than Android/desktop in the reported timing plots, suggesting uneven robustness across platforms.
- The paper mentions mitigation ideas, but the excerpt does not detail or benchmark them, so their effectiveness is unknown.
Open questions / follow-ons
- How stable are the Wasm timing fingerprints across browser updates, OS patches, CPU throttling, and thermal/power states?
- Can anti-fingerprinting defenses selectively perturb the specific JS↔Wasm boundary behaviors used here without breaking legitimate Wasm apps?
- How well does this method generalize to less common browsers or privacy-focused browsers with timer and JIT hardening?
- Could a learned classifier over the 20 timing features outperform the simple distance-based matching, and what would it buy in robustness?
Why it matters for bot defense
For bot defense, this paper is a reminder that browsers leak more than static headers: the JS↔Wasm execution path itself can act as a high-entropy signal. A CAPTCHA or risk-engine practitioner could use this kind of timing fingerprint as one feature in a broader reputation model to detect browser spoofing, automation stacks, or environment changes between sessions. The flip side is that the same technique is privacy-invasive and likely to trigger countermeasures from anti-fingerprinting browsers, so it is most relevant as a passive risk signal rather than as a user-facing authentication factor. It also suggests that defenses focusing only on User-Agent, canvas, or WebGL are incomplete if WebAssembly is allowed to run with high-resolution timers.
Cite
@article{arxiv2506_00719,
title={ Browser Fingerprinting Using WebAssembly },
author={ Mordechai Guri and Dor Fibert },
journal={arXiv preprint arXiv:2506.00719},
year={ 2025 },
url={https://arxiv.org/abs/2506.00719}
}