
An open-source Modular Online Psychophysics Platform (MOPP)
Source: arXiv:2505.23137 · Published 2025-05-29 · By Yuval Samoilov-Kats, Matan Noach, Noam Beer, Yuval Efrati, Adam Zaidel
TL;DR
MOPP is presented as an open-source, modular web platform for running online psychophysics experiments without requiring researchers to stitch together separate tools for task creation, hosting, authentication, and calibration. The core problem it targets is not a new psychophysical paradigm, but the operational friction of online data collection: researchers need code-heavy setup, remote participants may have inconsistent viewing conditions, and bots or low-quality respondents can contaminate data. MOPP’s design tries to collapse those steps into one browser-based workflow with preloaded tasks, cloning/modification of experiments, and built-in participant checks.
What is new here is the packaging: a Node.js server, MongoDB storage, and a React researcher/participant interface, plus integrated “public mode” and “supervised mode,” email/IP authentication, reCAPTCHA, a virtual chinrest for viewing-distance estimation, and Taylor’s E for acuity measurement. The authors also provide five preloaded example tasks and a pilot online study on AWS with 17 participants. The main result is pragmatic rather than algorithmic: the pilot data reproduced expected psychophysical patterns seen in the lab, suggesting the platform can support standardized online data collection with results comparable to prior offline findings.
Key findings
- MOPP combines experiment building and hosting in one open-source platform, whereas the introduction frames common workflows as requiring at least two separate systems (e.g., PsychoPy+Pavlovia or JsPsych+JATOS).
- The platform includes built-in email-based authentication, IP-based entry blocking, reCAPTCHA verification, a virtual chinrest, and Taylor’s E acuity test; these are integrated into the public-mode workflow before the experiment starts.
- Pilot study size was 17 participants recruited via online student forums; after task-specific exclusions, analyses used N=15 for length, N=17 for numerosity, N=17 for biological motion, N=16 for Mooney face, and N=17 for key tapping.
- Viewing distance measured by the virtual chinrest was 54.1 ± 1.6 cm at the start and 52.9 ± 1.9 cm at the end; the paired difference was not significant (t(16)=0.58, p>0.5, BF10=0.29).
- Mean decimal visual acuity from Taylor’s E was 0.97 ± 0.01; among six participants who reported wearing glasses, mean decimal VA was 0.99 ± 0.01.
- Length judgments followed a linear pattern with strong fit to group means (R2=0.93, p<0.001), with slope β1=0.51 (95% CI [0.42, 0.60]) and intercept β0=3.68 (95% CI [2.70, 4.66]), reproducing regression-to-the-mean effects.
- Numerosity judgments were fit in log-log space with R2=0.97 (p<0.001, fit only for stimuli exceeding 10 dots); slope β1=0.88 (95% CI [0.79, 0.96]) was <1, indicating underestimation at larger numerosities.
- Biological motion detection showed 93.0% ± 6.2% “biological motion” responses for biological stimuli vs 26.7% ± 10.7% for random motion; d’ was 0.66 ± 0.07 and was not significantly different from Weil et al. 2018 large online sample (0.73 ± 0.01, N=189) or small offline sample (0.74 ± 0.03, N=19).
Threat model
The assumed adversary is an untrusted online participant who may be a bot, may try to submit multiple entries, may have variable viewing conditions, and may not follow instructions; MOPP tries to mitigate this with email/IP checks, reCAPTCHA, and calibration. The system does not claim to stop a determined human adversary who can use multiple accounts, rotate IPs, bypass reCAPTCHA, or otherwise game the study, and supervised mode explicitly assumes a trusted in-person researcher who can verify identity manually.
Methodology — deep read
Threat model and operating assumptions are more about data quality than cyber-security. The paper assumes participants may be inattentive, may have variable display/viewing geometry, may attempt multiple entries, and may not be human (hence reCAPTCHA and email/IP controls). It does not present a formal adversary model beyond those practical threats, and it does not claim resistance to determined circumvention, shared accounts, VPN rotation, scripted solver services, or spoofed self-report. Public mode is the intended remote setting; supervised mode is for lab/clinic use where the researcher can verify identity and skip online checks.
The data story has two parts: platform components and pilot behavioral data. The platform itself is described as open-source code available on GitLab, with AWS deployment instructions in a user guide. The empirical evaluation uses a small online pilot study hosted in public mode on AWS and recruited from online student forums. Seventeen participants were enrolled (mean age 30.9 ± 2.6 years, 8 females). All provided informed consent; the study had IRB approval (ISU202110005). The five preloaded tasks were: length estimation, numerosity estimation, biological motion discrimination, Mooney face discrimination, and a key-tapping motor task. Stimulus sets were created once and reused across participants for the pilot tasks; that is important because the results reflect fixed stimulus lists rather than a fresh random sample per participant. For length, 24 integer stimulus values were drawn from a Uniform(1,18) distribution. For numerosity, 24 integers were drawn from a Gaussian distribution with mean 22 and SD 5. For biological motion, each participant saw 24 trials, half biological motion and half random motion. For Mooney faces, each participant saw 24 trials split among upright faces, inverted faces, and random images. For key tapping, participants alternated s and k for 30 seconds. The paper says participants completed the tasks on PCs only, using Chrome, with ad blockers disabled; mobile devices were rejected.
Architecturally, MOPP is a three-tier web app. The server-side component runs in Node.js and controls experiment flow, sends stimulus details to the browser, and receives responses. The database layer uses MongoDB for storage. The client-side interface is React.js and exposes two roles: researcher and participant. The researcher portal lets users create, clone, edit, and launch experiments; reorder tasks; edit pre-experiment questions; and load preloaded or custom tasks. Tasks can be added from a drop-down list, and task-specific parameters can be exposed in the UI so researchers can change them without editing code. The paper’s main novelty is this modularization: the platform supports copying/modifying tasks between environments and encourages reuse, while keeping experiment-level settings editable until launch. A concrete example is the preloaded numerosity task: the researcher selects it from the task list, can edit the number distribution parameters on the task page, and then launches the experiment. At runtime, participants first authenticate, solve reCAPTCHA, answer pre-experiment questions, complete visual calibration, and then enter the actual task sequence.
The training regime is not applicable in the machine-learning sense because MOPP is not trained as a model. The closest analog is the task-development workflow. Researchers can either code tasks directly in JavaScript or use jsPsych plugins and then load them into MOPP. The paper does not report development team size, versioning, seed strategy, or software benchmark metrics. It does specify that MOPP was tested primarily on Chrome, supports PCs but not mobile devices, and was hosted on AWS for the pilot; it also notes that MOPP could in principle run on Azure, Google Cloud, or a local server, but only AWS is documented here. Practice trials are supported, and tasks can define passing conditions for practice responses; that is part of the experimental design, not model training.
Evaluation is a pilot functional validation plus face-validity check against known psychophysical patterns. The authors use descriptive plots and simple statistical tests: linear regression for length judgments, log-log regression for numerosity, paired t-tests for the viewing-distance comparison, one-tailed paired t-tests for biological-motion discrimination, and unpaired Welch’s t-tests comparing their d’ values with prior work by Weil et al. (2018). They also report Bayes factors for several comparisons (e.g., BF10=0.29 for the viewing-distance start/end difference, BF10=0.40 and 0.50 in the biological-motion comparisons). For length, the regression on mean values gave R2=0.93 with slope <1 and positive intercept, matching regression-to-the-mean. For numerosity, the log-log fit yielded R2=0.97 and slope 0.88, matching sublinear growth and underestimation at higher numerosities. For biological motion, participants reported biological motion more often for biological than random stimuli (93.0% vs 26.7%), and d’ matched prior online/offline norms. For Mooney faces, the authors report that upright faces were detected better than inverted faces, consistent with the original stimuli paper, though the excerpt truncates the exact percentages for that comparison. For key tapping, the excerpt does not provide a quantitative benchmark result, so that task appears to be included mainly as a demonstration of platform breadth rather than a validated outcome.
Reproducibility is relatively good for a platform paper: the code is public, the pilot data and figure-generation code are on GitHub, and the authors provide a GitLab-based user guide. What is not fully clear from the excerpt is whether the exact pilot stimulus lists, container images, or frozen dependency versions are archived, and whether the platform has a tagged release. The paper also does not spell out browser versioning, network conditions, or any load-testing/stress-testing methodology. Because the evaluation is a small pilot with fixed stimulus sets and modest sample sizes, the evidence supports functional plausibility and psychophysical validity, not broad claims about reliability under adversarial or heterogeneous real-world deployment.
Technical innovations
- A single open-source web platform that unifies experiment construction, deployment, participant authentication, and data export for online psychophysics.
- Built-in calibration modules for viewing distance (virtual chinrest) and visual acuity (Taylor’s E), embedded directly into the participant workflow.
- Public mode versus supervised mode, allowing the same platform to serve remote crowdsourcing studies and controlled lab/clinic sessions.
- Task modularity via reusable preloaded tasks plus the ability to clone, modify, and import JavaScript/jsPsych tasks without changing the base platform.
Datasets
- Pilot psychophysics dataset — 17 participants total across five tasks (task-specific analyzed Ns: 15/17/17/16/17) — recruited via online student forums and hosted on AWS
- Preloaded task stimulus sets — 24 length stimuli, 24 numerosity stimuli, 24 biological-motion trials per participant, 24 Mooney-face trials per participant, 30-second key-tapping trials — generated by the authors for the platform demonstration
Baselines vs proposed
- Viewing distance start vs end: paired t-test t(16)=0.58, p>0.5, BF10=0.29; proposed calibration consistency across the session = 54.1 ± 1.6 cm vs 52.9 ± 1.9 cm
- Length task: regression on mean values R2=0.93, p<0.001; proposed = β1=0.51, β0=3.68, crossing unity at 7.51 units
- Numerosity task: log-log regression R2=0.97, p<0.001; proposed = β1=0.88, β0=0.20 with fit only for stimuli >10 dots
- Biological motion discrimination: biological-stimulus reports = 93.0% ± 6.2% vs random-motion reports = 26.7% ± 10.7%; p<0.001, t(16)=10.1
- Biological motion sensitivity: Weil et al. 2018 large online sample d’=0.73 ± 0.01 (N=189) / offline sample d’=0.74 ± 0.03 (N=19) vs proposed = 0.66 ± 0.07; p=0.33 and p=0.30, respectively
- Mooney face task: upright faces were detected better than inverted faces; exact percentages are truncated in the provided text, so the precise numeric comparison is unclear
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2505.23137.
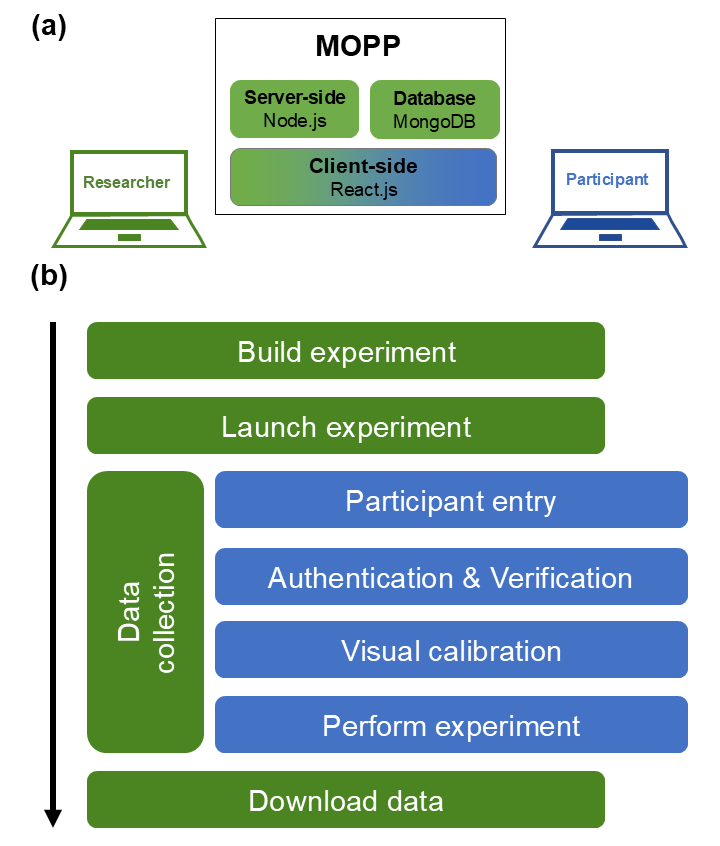
Fig 1: MOPP overview. (a) MOPP consists of three main components: (i) the server-side component
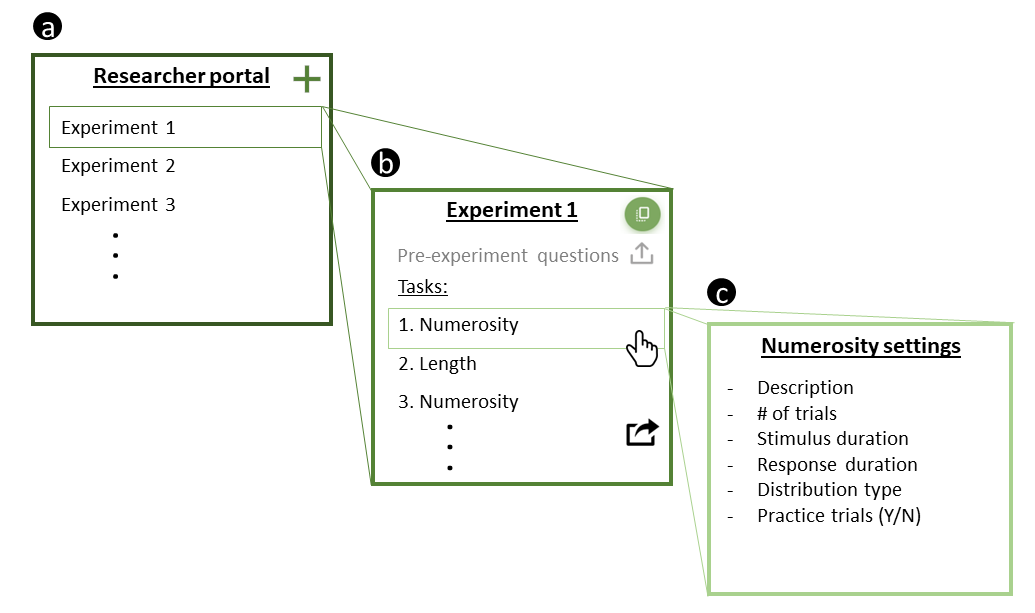
Fig 2: Illustration of the web-based interface for managing, building, and launching experiments.
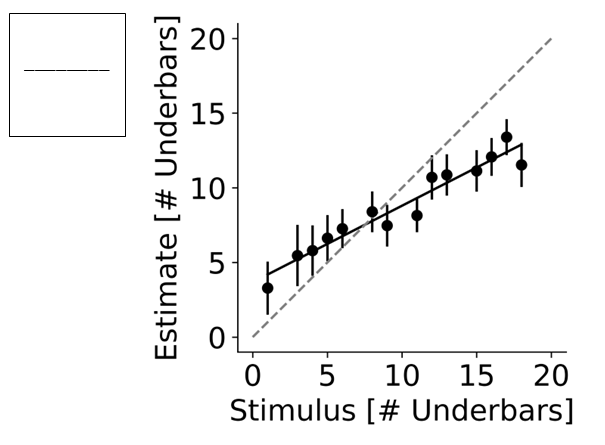
Fig 3: Pilot data for the length task collected via MOPP. A stimulus schematic is presented in the
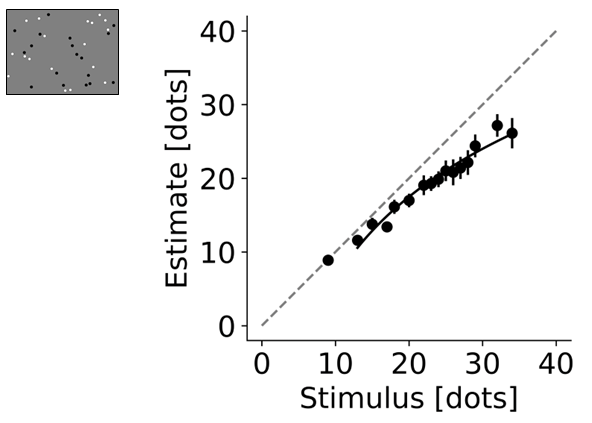
Fig 4: Pilot data for the numerosity task collected via MOPP. A stimulus schematic is presented in
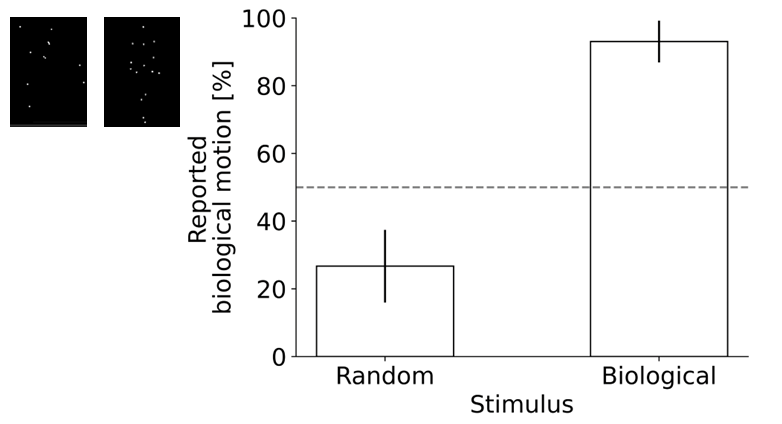
Fig 5: Pilot data for the biological motion task collected via MOPP. Stimulus schematics are
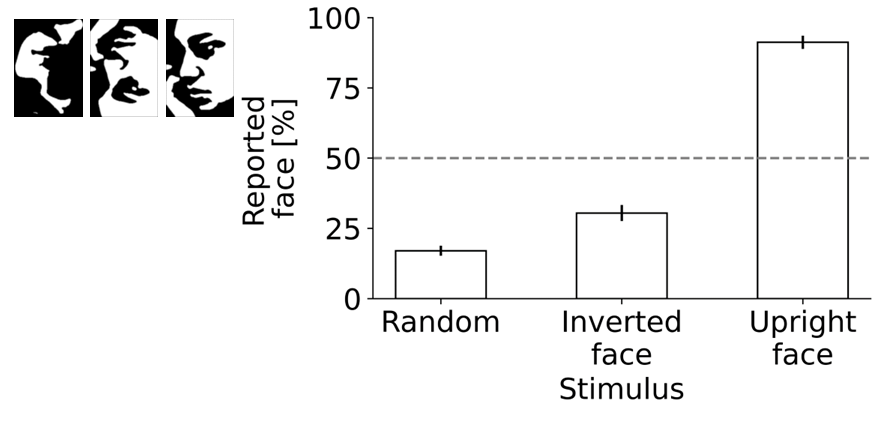
Fig 6: Pilot data for the Mooney face task collected via MOPP. Stimulus schematics are presented
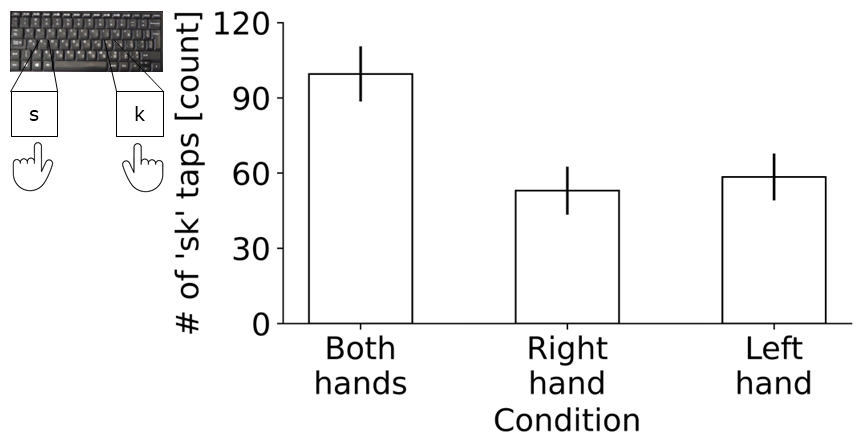
Fig 7: Pilot data for the key-tapping motor task collected via MOPP. An illustration of the task is
Limitations
- Small pilot sample: only 17 participants total, with task-specific exclusions reducing some analyses to 15 or 16 participants.
- The evaluation is mostly sanity-check/face-validity rather than a stress test; there is no large-scale benchmark of throughput, dropout, or failure rates.
- No formal adversarial study of the anti-bot/authentication measures; reCAPTCHA, email login, and IP blocking can likely be bypassed by determined attackers.
- The platform was primarily tested on Chrome and PCs; mobile support is absent, and cross-browser compatibility is not established in the excerpt.
- The paper does not report robustness under network interruptions, browser tab switching, ad-blocker behavior beyond a warning, or heterogeneous hardware/display setups.
- Stimulus sets in the pilot were generated once and reused across participants, so the evidence is about a fixed online deployment rather than fully randomized per-participant stimulus generation.
Open questions / follow-ons
- How well do the email/IP/reCAPTCHA checks hold up against coordinated fraud, shared devices, VPNs, or commercial bot-solving services?
- How stable are the calibration procedures across browsers, monitors, operating systems, and non-laptop/desktop hardware that the platform currently excludes?
- Can the modular task model support more complex adaptive psychophysics paradigms, such as staircase procedures or inter-trial dependent stimulus selection, without custom code?
- What is the operational overhead and failure rate of AWS deployment at larger scale, especially under concurrent participant load and variable network quality?
Why it matters for bot defense
For a bot-defense engineer, MOPP is interesting less as a CAPTCHA paper than as a case study in layered participant vetting inside a research workflow. The platform combines account-level checks, IP deduplication, reCAPTCHA, and task-level plausibility checks (practice trials, data-type validation, calibration) to reduce low-quality participation before data collection starts. In practice, that suggests a defense-in-depth pattern: authentication is only one signal, and the more useful protection may come from combining identity, device/network reuse, and behavioral consistency checks.
If you were building a CAPTCHA-adjacent research pipeline, the important lesson is that anti-bot measures need to be compatible with low-friction experimental UX and with accessibility constraints. MOPP also highlights an operational tradeoff: stronger gating can improve data quality, but it can also exclude legitimate participants without stable email access, non-Chrome browsers, or mobile devices. For bot-defense, that means measuring false rejects and accessibility impact alongside bot catch rate, not treating the CAPTCHA as the whole solution.
Cite
@article{arxiv2505_23137,
title={ An open-source Modular Online Psychophysics Platform (MOPP) },
author={ Yuval Samoilov-Kats and Matan Noach and Noam Beer and Yuval Efrati and Adam Zaidel },
journal={arXiv preprint arXiv:2505.23137},
year={ 2025 },
url={https://arxiv.org/abs/2505.23137}
}