
Transformers for Secure Hardware Systems: Applications, Challenges, and Outlook
Source: arXiv:2505.22605 · Published 2025-05-28 · By Banafsheh Saber Latibari, Najmeh Nazari, Avesta Sasan, Houman Homayoun, Pratik Satam, Soheil Salehi et al.
TL;DR
This is a survey paper, not an empirical system paper. Its core problem is whether Transformer-family models can meaningfully improve detection, classification, and mitigation across hardware-security tasks that are hard for rule-based or conventional ML methods: side-channel leakage, hardware Trojan detection, firmware vulnerabilities, device fingerprinting, malware detection, fault injection, and related hardware-software boundary issues. The authors argue that Transformers are attractive because self-attention can model long-range dependencies and heterogeneous signals better than hand-engineered features or purely local models.
What is new here is the organization and synthesis: the paper maps recent Transformer usage into a security taxonomy (design-time, runtime, post-deployment assurance) and then surveys specific systems such as HTrans, TrojanFormer, NtNDet, TransNet, EstraNet, SHERLOCK, ViT4Mal, SecurityBERT, DDoSViT, FirmVulSeeker, and LLM-IFT. The headline result is not a single benchmark number but a broad claim that Transformer-based methods are consistently competitive or state-of-the-art in their respective subproblems, while the paper also foregrounds the practical barriers: quadratic attention cost, lack of interpretability, adversarial fragility, and dataset scarcity.
Key findings
- HTrans reports 96.7% F1 for hardware Trojan detection and 91.7% accuracy for localization on the Trust-Hub benchmark, with RTL-level detection completed in under 1 second.
- The non-destructive, golden-chip-free PSC-based HTD framework using GPT/BERT/Transformer variants reports 87.74% accuracy for classifying trojans into Enabled, Disabled, and Triggered categories.
- TrojanFormer reports an average F1 of 97.66% on medium- and small-scale datasets; on large-scale circuits it reports a 4% performance improvement and an 18% reduction in computational overhead versus graph-learning baselines.
- TrojanWhisper reports 100% precision/recall for GPT-4o and Gemini 1.5 Pro on RTL Trojan detection, but performance degrades under code perturbation, especially for payload localization.
- NtNDet reports improvements of 5.27% precision, 3.06% TPR, 0.01% TNR, and 3.17% F1 over prior methods on Trust-Hub, TRIT-TC, and TRIT-TS benchmarks.
- TA-MobileViT reports 100% recognition accuracy for single Trojan types, 72.2% accuracy for AES-600 detection, and 97.04% mean accuracy for multi-Trojan detection.
- SecurityBERT reports 98.2% accuracy across 14 attack types on Edge-IIoTset for IoT cyber-threat detection.
- Smart Monitor reports 92% detection accuracy and 78% classification accuracy for EM/clock-glitch fault attacks with zero false positives.
Threat model
The adversary varies by application: a malicious circuit designer or supply-chain attacker inserting hardware Trojans, an external observer extracting secrets via side-channel traces, a malware author trying to evade runtime detection, or a spoofer attempting device impersonation. The survey assumes the attacker may manipulate hardware designs, firmware, signals, or code structure, but does not assume they can alter the evaluation pipeline, access hidden labels, or defeat the source datasets’ collection process. It also highlights that many methods must remain effective under perturbations such as desynchronization, code obfuscation, masking, random delays, or low-SNR conditions.
Methodology — deep read
This is a survey, so its methodology is literature selection, categorization, and comparative synthesis rather than a single experimental pipeline. The implicit threat model varies by sub-area: for Trojan detection the adversary is a malicious design or supply-chain actor who inserts stealthy logic into RTL/netlists; for side-channel work the adversary may be a device owner or remote observer trying to infer secrets from power/timing/EM traces; for malware and firmware work the adversary is malicious code or exploit traffic trying to evade runtime detection; for device fingerprinting the adversary is a spoofer/cloner attempting impersonation. The survey repeatedly assumes the attacker can manipulate inputs, design artifacts, or traces, but cannot break the underlying data access, training, or evaluation setup of the cited papers. The paper itself does not propose a unified threat model across all tasks.
On data, the paper compiles datasets used by prior work, but it does not create a new corpus. The clearest named datasets are Trust-Hub, TRIT-TC, TRIT-TS, Trusthub, ASCAD, Edge-IIoTset, CICIoT2023, and CICIoMT2024; it also references CWEs, NVD/CVE for vulnerability classification, and several RTL/module families such as SRAM, AES, and UART in the context of TrojanWhisper. Because this is a survey, it generally does not state train/test splits, preprocessing details, or label construction for each cited system in a standardized way; instead, those details are deferred to the underlying primary papers. One concrete example summarized in the survey is NtNDet: it converts gate-level netlists into a natural-language-like representation (“Netlist-to-Natural-Language”) so that pre-trained NLP/Transformer models can ingest structural circuit information and learn dependencies relevant to Trojan detection. Another example is TransNet/EstraNet, which operate directly on power traces and modify attention to be shift-invariant for desynchronized side-channel traces.
Architecturally, the survey’s value is in describing how each cited approach adapts Transformers to hardware data. In hardware Trojan detection, there are graph-based variants such as HTrans, which uses a GCN in preprocessing to scale across design sizes, and TrojanFormer, which adds a message-passing scheme inside a graph transformer to improve detection while reducing overhead. In side-channel analysis, TransNet introduces relative positional encoding to handle trace shifts, while EstraNet further aims for linear-time/linear-memory behavior through GaussiS P self-attention and a custom layer-centering normalization instead of batch/layer norm. For runtime/malware tasks, several works convert binaries or bytecode to images and then apply ViTs (for example SHERLOCK and ViT4Mal), while other approaches treat process-resource or network events as sequences and apply attention over temporal logs. The survey also highlights hybrid systems that fuse attention with GNNs, CNNs, LSTMs/GRUs, or LLMs depending on whether the inputs are graphs, images, sequential telemetry, or source-code-like text.
Training regime details are mostly absent because the paper is not reporting original training. Where the survey cites results, it usually gives only the headline metric and sometimes a computational note. For example, HTrans is described as completing RTL-level detection in under a second; TrojanFormer is described as reducing computational overhead by 18% on large-scale circuit datasets; EstraNet is described as scaling to traces exceeding several thousand points while remaining robust to masking, random delays, and clock jitter. The survey does not standardize epochs, batch sizes, optimizers, random-seed strategy, or hardware used for training across the reviewed studies, and in many cases those details are simply not recoverable from the survey text alone.
Evaluation in the survey is comparative at the paper-summary level: it cites reported metrics such as accuracy, F1, precision/recall, TPR/TNR, and overhead reductions, usually against unspecified or named baselines from the primary papers. The survey itself does not perform statistical testing, cross-validation analysis, or a new held-out attacker study. It does, however, emphasize meaningful evaluation axes for this domain: robustness to perturbations (TrojanWhisper under variable-name obfuscation and design restructuring), robustness to desynchronization and masking (TransNet, EstraNet), scalability to large circuits or long traces (TrojanFormer, EstraNet), and deployment constraints such as on-device resource limits (ViT4Mal, TransMalDE, SecurityBERT). One concrete example of the reported evaluation logic is TrojanWhisper: it tests multiple off-the-shelf LLMs (GPT-4o, Gemini 1.5 Pro, Llama 3.1) on RTL designs without fine-tuning, then perturbs code to probe whether performance depends on superficial syntax rather than semantic understanding.
Reproducibility is mixed and mostly inherited from the underlying literature. The survey does not claim to release code, frozen weights, or a unified benchmark. It does note where works rely on public benchmarks such as Trust-Hub or Edge-IIoTset, but it also stresses that many hardware-security datasets are proprietary or difficult to access, which limits direct replication. Because the paper is a review, its reproducibility contribution is primarily bibliographic: it points readers to the named methods and datasets, but it does not itself provide a new experimental artifact package.
Technical innovations
- The paper’s main technical contribution is a taxonomy of Transformer use in hardware security, separating design-time security, runtime security, and post-deployment assurance rather than treating all detection tasks as one bucket.
- It identifies and contrasts several adaptation patterns for hardware data, including graph-to-Transformer pipelines, sequence-to-Transformer pipelines for traces and logs, and image-based ViT pipelines for binaries and defect images.
- It synthesizes efficiency modifications such as relative positional encoding for desynchronized traces, linear/efficient attention, and hybrid GNN-Transformer modules as the key enablers for deployment on hardware-constrained settings.
- It highlights the emerging use of LLMs not just for classification but for security reasoning and mitigation generation, as in TrojanWhisper, SCAR, FirmVulSeeker, SLFHunter, and HW-V2W-Map.
Datasets
- Trust-Hub — size not specified in survey — public benchmark
- TRIT-TC — size not specified in survey — public benchmark
- TRIT-TS — size not specified in survey — public benchmark
- ASCAD — size not specified in survey — ANSSI Side-Channel Attack Database
- Edge-IIoTset — size not specified in survey — public IoT security dataset
- CICIoT2023 — size not specified in survey — public dataset
- CICIoMT2024 — size not specified in survey — public dataset
- NVD/CWE/CVE — size not specified in survey — public vulnerability repositories
Baselines vs proposed
- Prior graph-learning baselines: TrojanFormer average F1 = not specified vs proposed = 97.66%
- Existing HT detection methods: NtNDet precision = not specified vs proposed = +5.27% precision
- Existing HT detection methods: NtNDet TPR = not specified vs proposed = +3.06% TPR
- Existing HT detection methods: NtNDet TNR = not specified vs proposed = +0.01% TNR
- Existing HT detection methods: NtNDet F1 = not specified vs proposed = +3.17% F1
- Baseline deep learning methods: TA-MobileViT single Trojan recognition = not specified vs proposed = 100%
- Baseline deep learning methods: TA-MobileViT multi-Trojan mean accuracy = not specified vs proposed = 97.04%
- Traditional ML/DL methods: SecurityBERT accuracy = not specified vs proposed = 98.2%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2505.22605.
Fig 1: Scenarios where Transformers detect, classify, and mitigate vulnerabilities.
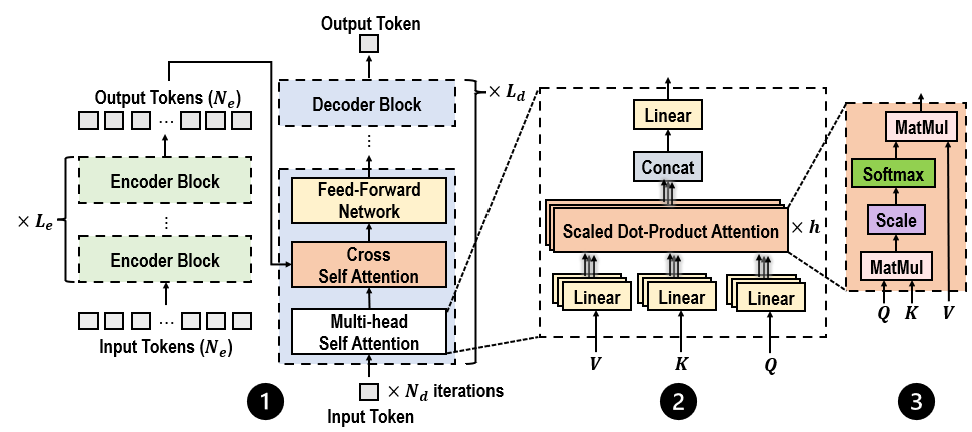
Fig 2: Architecture of the Vanilla Transformer, featuring (1) an Encoder-Decoder structure, (2) Multi-Head Self-Attention
Limitations
- This is a survey, so there is no unified experimental protocol, no new ablation study, and no direct apples-to-apples benchmark across all cited tasks.
- Many quoted numbers are inherited from primary papers and are not directly comparable because datasets, threat models, and metrics differ widely.
- The survey acknowledges that Transformer models are computationally expensive, which limits deployment on embedded devices and FPGAs.
- It notes a lack of explainability, but does not provide a concrete interpretability method or evaluation framework of its own.
- Dataset scarcity and proprietary data access remain unresolved; the survey does not propose a released benchmark to address this.
- Adversarial robustness is discussed at a high level, but the survey does not perform or summarize a standardized adversarial evaluation across methods.
Open questions / follow-ons
- Can a single benchmark unify graph, trace, binary-image, and log-based hardware-security tasks so that Transformer variants can be compared fairly?
- How much of the reported performance survives stronger adaptive adversaries, especially for LLM-based Trojan or firmware analysis under semantic-preserving obfuscation?
- What is the best way to combine interpretability with deployment efficiency for hardware-constrained systems, beyond post-hoc attention visualization?
- Can self-supervised pretraining on unlabeled hardware traces, netlists, or telemetry materially improve out-of-distribution robustness?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the main takeaway is not that Transformers magically solve hardware security, but that attention-based sequence and graph modeling is increasingly viable when the signal is messy, long-range, and multi-modal. The methods surveyed here are relevant if you are building telemetry-based fraud detection, device reputation, or remote attestation systems where low-level execution traces, network flows, or RF fingerprints can complement traditional challenge-response logic.
At the same time, the survey is a cautionary note: these models are expensive, often brittle under perturbation, and heavily dependent on data quality and threat-model fidelity. A bot-defense team should treat Transformer-based signals as one layer in a defense stack, and should explicitly test for obfuscation, distribution shift, and adaptive adversaries before relying on them operationally.
Cite
@article{arxiv2505_22605,
title={ Transformers for Secure Hardware Systems: Applications, Challenges, and Outlook },
author={ Banafsheh Saber Latibari and Najmeh Nazari and Avesta Sasan and Houman Homayoun and Pratik Satam and Soheil Salehi and Hossein Sayadi },
journal={arXiv preprint arXiv:2505.22605},
year={ 2025 },
url={https://arxiv.org/abs/2505.22605}
}