
Perception-Driven Bias Detection in Machine Learning via Crowdsourced Visual Judgment
Source: arXiv:2506.11047 · Published 2025-05-21 · By Chirudeep Tupakula, Rittika Shamsuddin
TL;DR
This paper addresses the challenge of detecting bias in machine learning datasets without relying on sensitive demographic labels or rigid fairness metrics, which can be inaccessible or ethically problematic in practice. The authors propose a novel perception-driven framework that leverages crowdsourced human visual judgments on simplified visualizations of numeric data grouped by demographic features. By collecting rapid binary similarity/difference judgments from non-expert users viewing stripped-down 2D scatter plots (e.g., salary distributions), their system aggregates perception signals that can flag potential bias cases. These crowdsourced flags are validated statistically using two-sample t-tests and further evaluated via cross-group machine learning model performance. Results from a pilot study involving university participants demonstrate that perceptual signals align with statistically significant disparities and observable model biases, especially in high-risk demographic clusters. The approach offers a label-efficient, interpretable, and scalable complementary bias detection mechanism that is human-aligned and applicable in label-scarce or early-stage ML settings.
The key contribution is a two-phase auditing pipeline: initial human perception collection to identify potential bias in visualized data slices, followed by statistical calibration and machine learning model training to automate future bias screening without sensitive attribute access. Question phrasing and visual design factors influencing perception are also studied, revealing cognitive framing effects on fairness judgments. While preliminary and limited in scale, the work demonstrates the viability of harnessing crowd visual intuition as a fairness sensor and lays groundwork for integrating human perceptual signals into ML fairness pipelines.
Key findings
- Crowdsourced binary judgments from non-expert users on simplified scatter plot visualizations reliably correlate with known bias cases in the High Age–High Experience cluster where male and female salary means differ significantly (p=0.03557).
- User perception responses are consistent and reproducible across participants and repeated exposures, supporting reliability of visual disparity detection.
- Question phrasing modulates bias detection rates: prompts emphasizing difference ("Do you notice a difference?") yield higher bias flags than similarity-framed prompts.
- Cross-group evaluation of subgroup-specific salary prediction models shows increased mean squared error when models trained on one demographic (male/female) are tested on the other, especially in the High Age–High Experience cluster, indicating algorithmic bias linked to data disparities.
- Of four demographic salary clusters studied, only one (High Age–High Experience) shows statistically significant disparity confirmed by t-tests, aligned with perception and model cross-group generalization gaps.
- The framework’s two-phase approach linking crowdsourced perception to statistical validation reduces false positives and enhances interpretability compared to perception-only signals.
- Aggregated human perceptions can bootstrap training datasets for ML models that imitate human bias detection, enabling automated fairness screening without sensitive labels.
- An open web-based platform deployed for pilot testing supported rapid data collection with metadata tracking (e.g., device, response time) enabling future nuanced analyses.
Threat model
Not a security-specific paper; the adversary is essentially the bias present in data or ML model decisions that can negatively impact protected groups. The framework assumes an auditor lacks access to sensitive attributes or explicit fairness metrics. The approach does not consider active adversaries trying to fool perception or algorithmic bias detectors.
Methodology — deep read
Threat Model & Assumptions: The adversary is not explicitly defined as the paper focuses on fairness auditing rather than adversarial attack. The key assumption is lack of access to sensitive group labels or incomplete demographics, making traditional fairness metrics infeasible. The system assumes non-expert crowd workers can perceive group-level disparities visually but may be influenced by framing and cognitive biases.
Data: Originates from real-world salary datasets (e.g., Kaggle), partitioned into demographic clusters by age and experience (e.g., High Age–High Experience, Low Age–Low Experience). Synthetic visualizations generated by plotting grouped data points as 2D scatter plots with color coding representing groups, stripped of contextual axis labels or numeric scales to avoid anchoring biases. The dataset size for user judgments is not precisely quantified, but pilot involved university participants interacting with randomized visualizations. Responses collected include binary yes/no judgments on group similarity, timestamps, question phrasing, device type.
Architecture / Algorithm: No deep learning model architecture is introduced initially; rather, the method starts with human crowd perception for bias flagging. Subsequently, supervised classification models including decision trees and Support Vector Machines (SVMs) are trained on encoded features derived from visualizations and group summary statistics (means, variances, cluster metrics) to predict perceived bias labels. Input features combine visual data slices and structural layout metrics.
Training Regime: Models trained on perception-labeled datasets generated from aggregated crowd answers. Training details such as epochs, batch size, optimizer are unspecified. Pilot-scale experiments use standard classifiers (scikit-learn implementations) with exploratory hyperparameter tuning implied. Training occurs after statistical validation to ensure label quality.
Evaluation Protocol: Evaluation involves multiple steps: (a) Statistical validation of perception-flagged cases using two-sample t-tests on underlying group salary distributions with significance at p<0.05; (b) Cross-group model performance by training regression models separately on male and female subgroups then testing on opposite groups, measuring Mean Squared Error (MSE) to detect generalization gaps indicative of bias; (c) Analysis of user response consistency, framing effects, and demographic influence on perceptions. No mention of cross-validation or out-of-sample generalization testing for bias prediction models. Limited sample size pilot restricts statistical power.
Reproducibility: The paper describes a custom Flask/PostgreSQL web platform deployed for pilot data collection but does not mention releasing code or datasets publicly at this stage. Visual stimuli generation and crowd interface design details are provided but implementation specifics and seeds for model training are not documented.
Concrete Example: A user is presented with a pair of scatter plots representing salary data for male vs female groups in the High Age–High Experience cluster, shown as color-coded dot clusters without axis labels. They respond 'no' to the question "Do these two groups look visually similar?". Multiple users give similar responses, yielding an aggregated perception flag of bias. This cluster is statistically validated with t-test (p=0.03557) confirming significant salary difference. Regression models trained on male data perform worse when tested on female data (higher MSE), indicating model bias consistent with human perception. This validated perception feedback is then used to label the visualization slice for training an ML classifier to recognize bias from new visual slices autonomously.
Technical innovations
- Leveraging crowdsourced binary visual perception judgments on simplified numeric data scatter plots for bias detection, rather than relying on sensitive attributes or formal fairness metrics.
- Design of minimalistic, context-stripped visualizations to elicit unbiased human perception of group disparities, abstracting away domain-specific cues.
- Two-phase framework combining human perception aggregation with statistical hypothesis testing and cross-group ML model performance to validate and calibrate bias signals.
- Training supervised classifiers on human-labeled perception data to automate bias detection in new dataset slices without access to sensitive group labels.
Datasets
- Salary datasets with demographic attributes (age, experience, gender) derived from public Kaggle data — size unspecified — used in pilot study for visualization generation and analysis
Baselines vs proposed
- User-perception flagged bias vs statistical test significance: High Age–High Experience cluster perception aligns with t-test p=0.03557 (statistically significant), while other clusters flagged less often by users are non-significant (p > 0.1).
- Cross-group prediction errors (MSE) for subgroups: models trained on male data have higher MSE when tested on female data, e.g., High Age–High Experience M→F MSE=15222.83 vs M→M MSE=12583.10, indicating reduced generalization and bias.
- Question phrasing effect on bias flagging rate: No absolute probabilities reported, but phrasing bias-detecting questions ("noticeable difference") increases user-flagged bias frequency compared to similarity-based phrasing.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2506.11047.
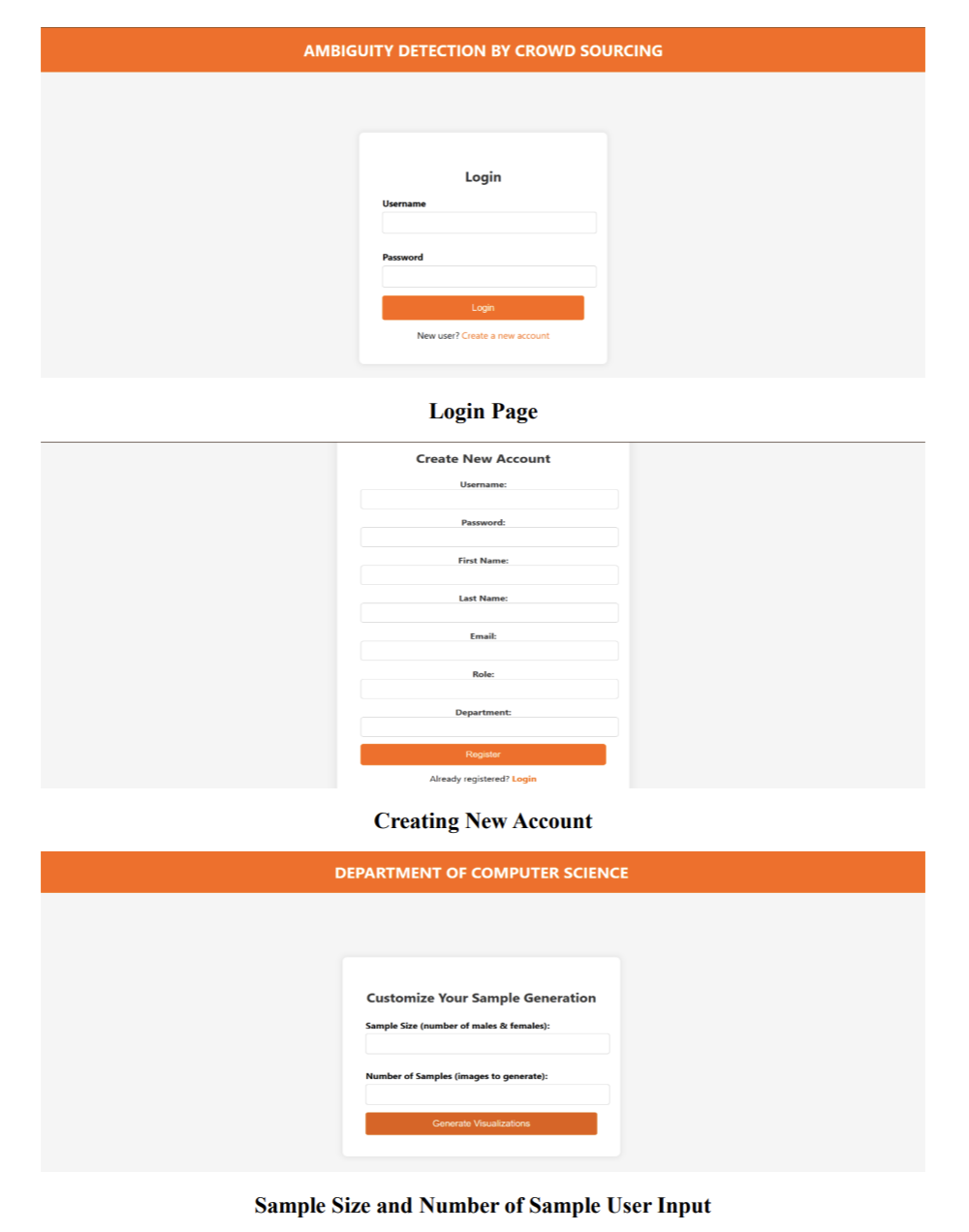
Fig 1: Web-based user interface for login, registration, and customization of sample generation. The platform
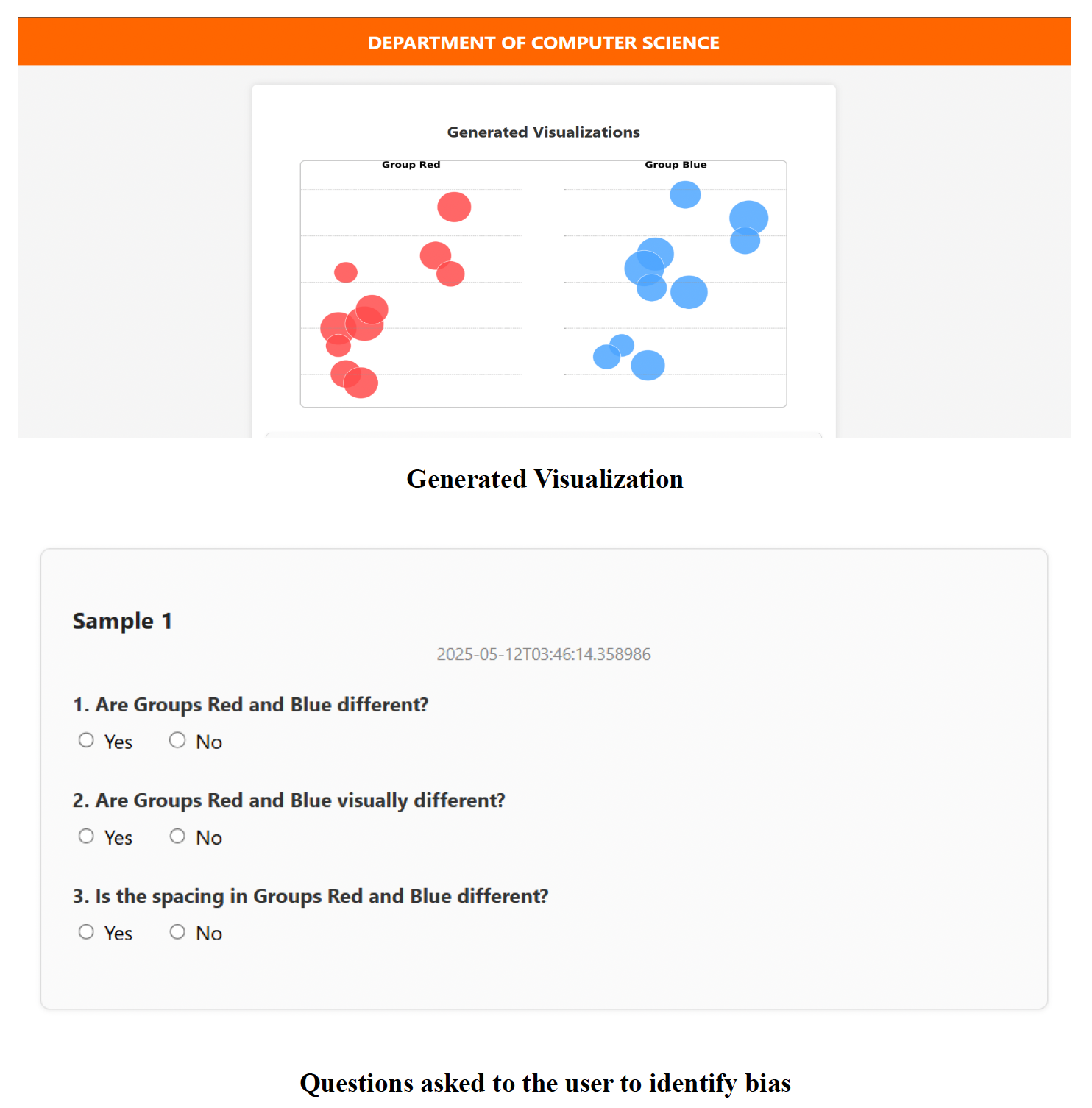
Fig 2: Interface showing a generated visualization alongside three versions of the perception question. The
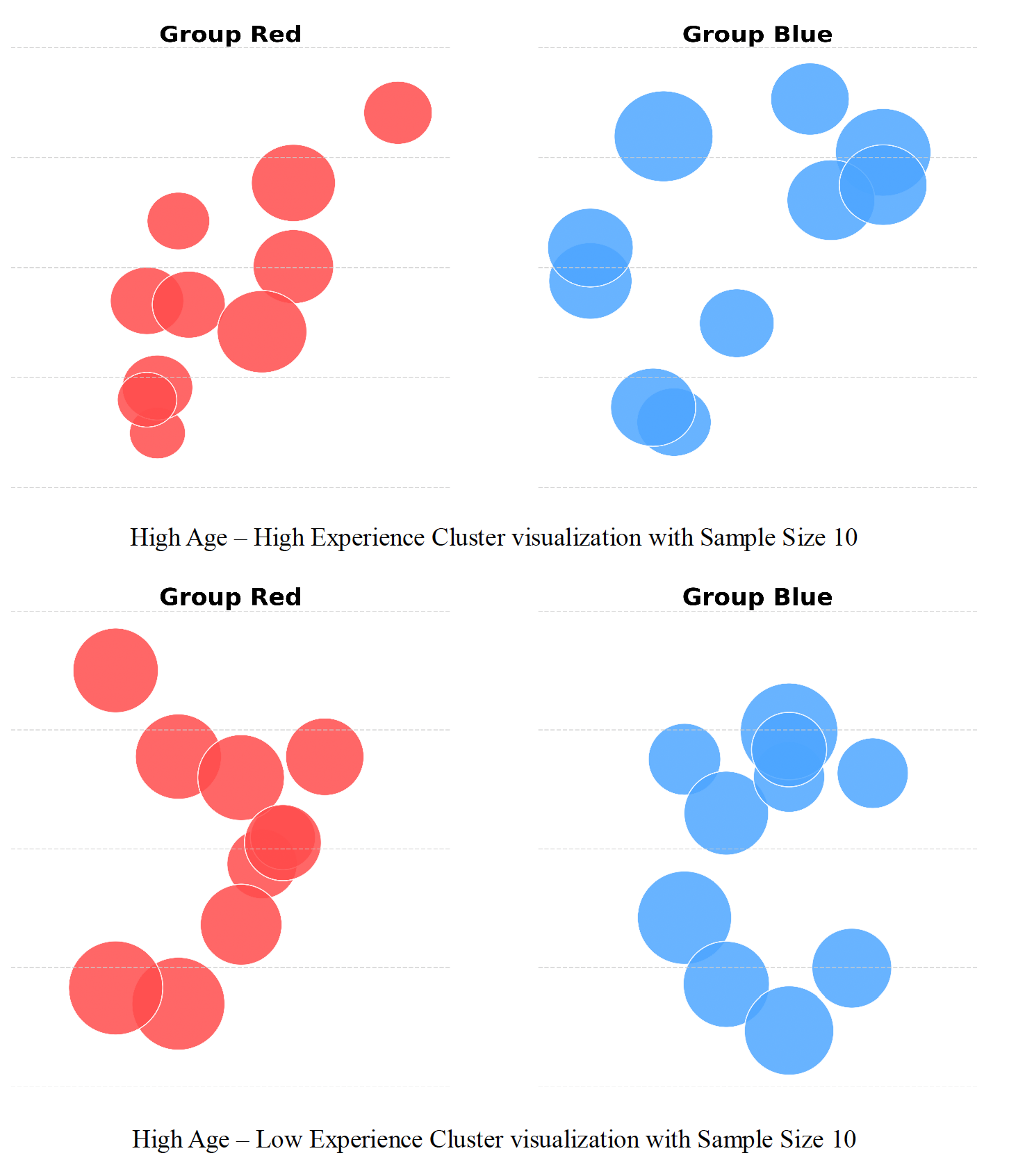
Fig 3: Sample cluster visualizations presented to users. Groups are color-coded and plotted without axis labels
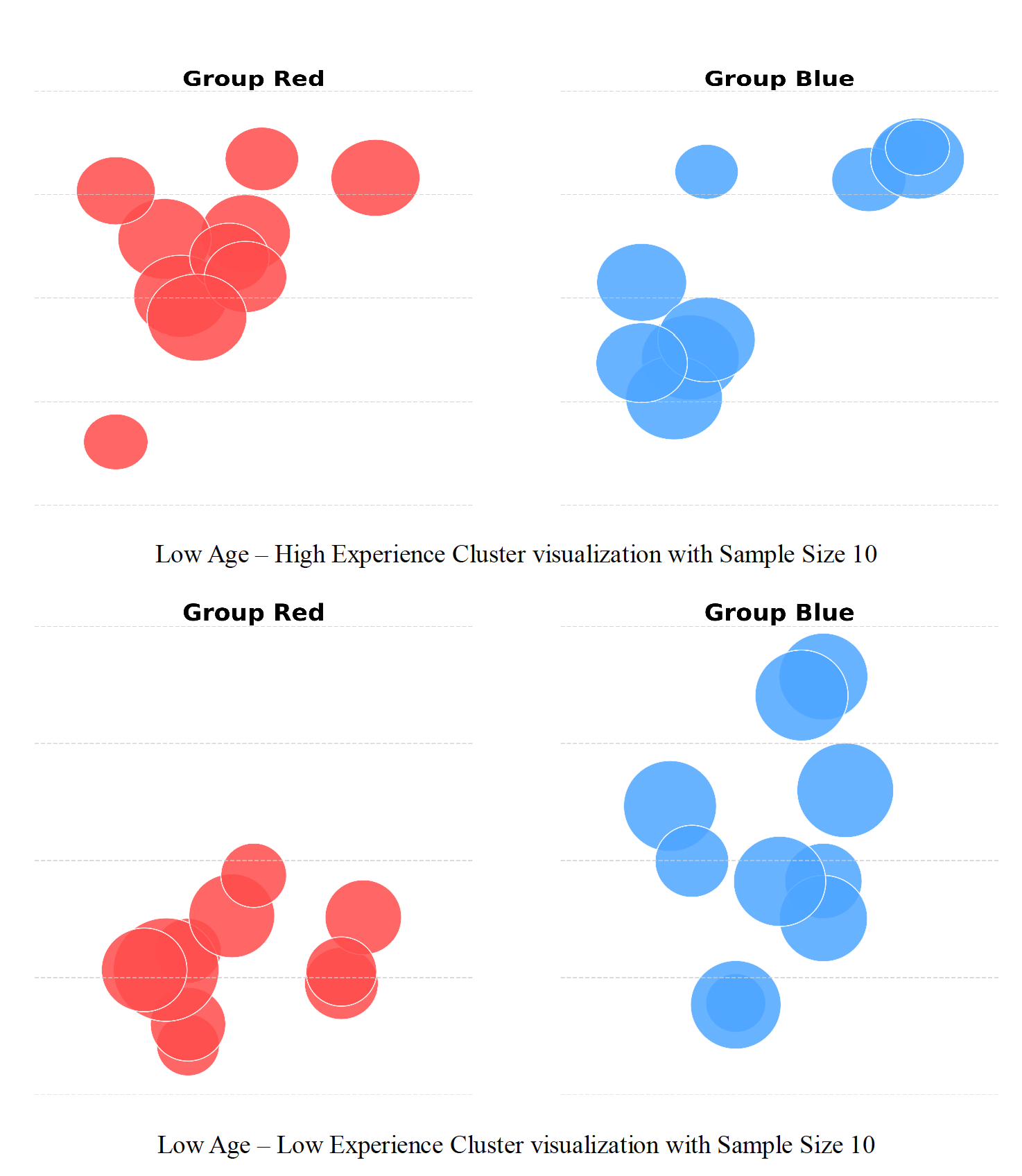
Fig 4: Overview of the proposed two-phase framework for bias detection. Phase 1 captures user-perceived disparities
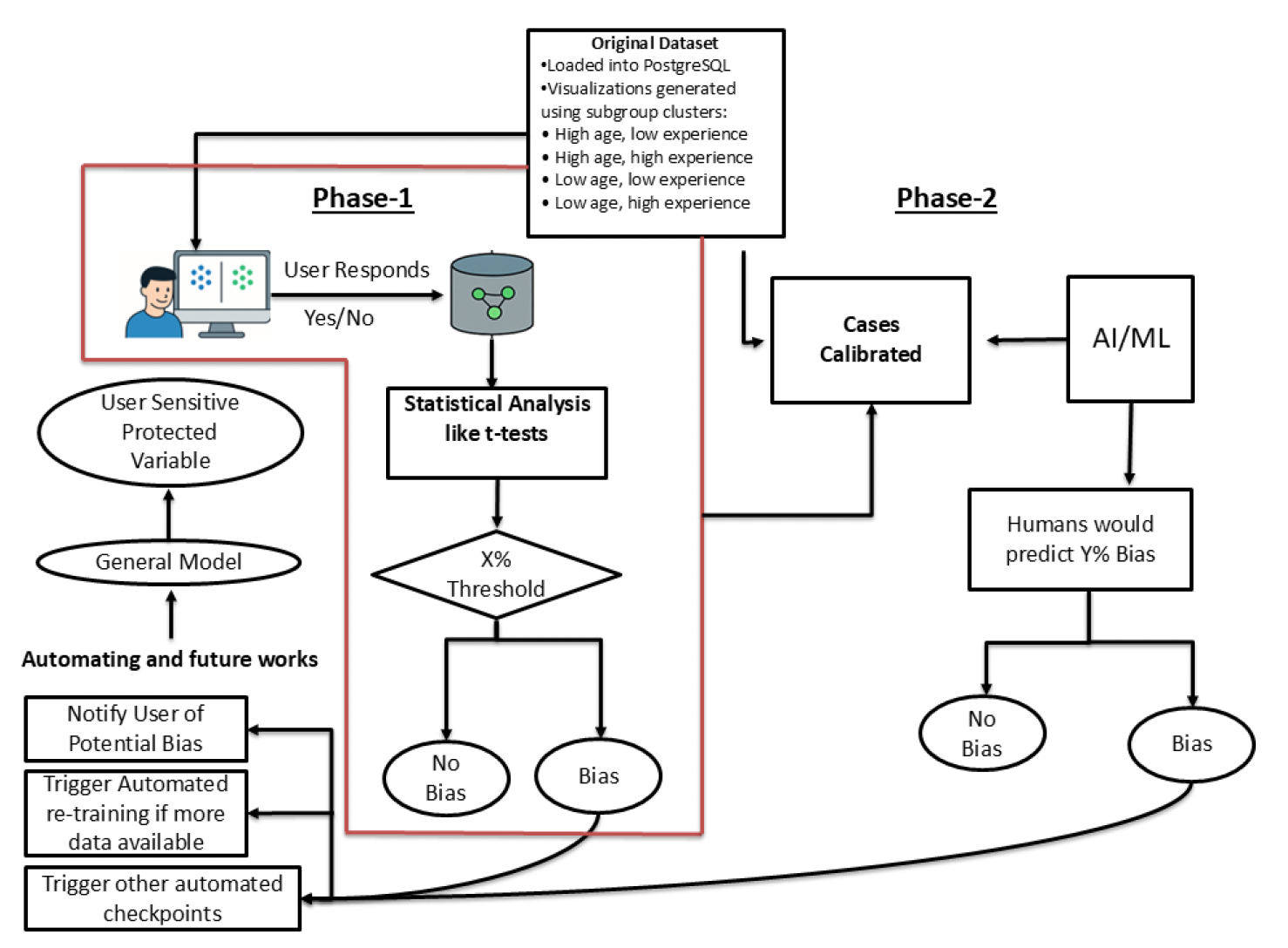
Fig 5 (page 7).
Limitations
- Pilot deployment had limited and demographically narrow participant pool (mainly university students), risking sampling bias in perception signals.
- Visualizations generated from real-world data but lacked controlled synthetic experiments to isolate effects of specific visual features (e.g., spacing, clustering) on perception.
- Question phrasing and visual layout variations were not fully counterbalanced or randomized, leaving potential confounds in cognitive framing effects.
- Human visual perception is inherently subjective and variable; aggregation and calibration mitigate but do not eliminate noise or bias in responses.
- No comprehensive evaluation of fairness prediction models under distribution shifts, adversarial settings, or with large-scale generalization testing provided.
- Code, datasets, and trained models are not publicly released, which limits reproducibility and independent validation.
Open questions / follow-ons
- How can visual features influencing perception of bias (e.g., spacing, clustering) be systematically parameterized and tested in controlled synthetic setups?
- How does demographic diversity (culture, education, biases) among crowd workers affect the reliability and generalizability of perception-based fairness signals?
- Can trained ML models fully replicate human perception on complex, high-dimensional real-world data beyond simplified visualizations?
- What is the robustness of perception-driven bias detection under adversarial manipulations or noisy, incomplete data conditions?
Why it matters for bot defense
This work presents a novel way to integrate human perceptual judgments into bias detection for ML systems, analogous to how CAPTCHAs mobilize human effort for labeling tasks. For bot-defense and CAPTCHA engineers, it showcases the potential of lightweight, rapid human-in-the-loop tasks harnessing intuitive pattern recognition to flag fairness concerns without needing sensitive labels or expert knowledge. This approach offers a scalable human-aligned feedback channel that could complement automated monitoring pipelines, especially early in model development or in label-scarce environments. However, factors like prompt phrasing, visualization design, and user diversity must be carefully considered to maintain reliability and reduce noise. Integrating such perception-driven cues could enrich CAPTCHA-style bot defenses with socio-ethical auditing capabilities, potentially guiding model retraining or automated fairness checks. The work also demonstrates how aggregated human judgments can seed ML models to automate bias screening, suggesting a path for combining crowdsourcing with automated fairness monitoring.
Cite
@article{arxiv2506_11047,
title={ Perception-Driven Bias Detection in Machine Learning via Crowdsourced Visual Judgment },
author={ Chirudeep Tupakula and Rittika Shamsuddin },
journal={arXiv preprint arXiv:2506.11047},
year={ 2025 },
url={https://arxiv.org/abs/2506.11047}
}