
FLUXSynID: A Framework for Identity-Controlled Synthetic Face Generation with Document and Live Images
Source: arXiv:2505.07530 · Published 2025-05-12 · By Raul Ismayilov, Dzemila Sero, Luuk Spreeuwers
TL;DR
The reported outcome is a public framework plus a dataset of 14,889 synthetic identities, with evidence that the resulting identities align better with real embedding-space structure than prior synthetic sets such as ONOT and StyleGAN2-based data. The authors emphasize better demographic control, higher inter-class diversity, and more realistic mated/non-mated similarity distributions, while also being transparent that the approach still struggles with some attributes like age and subtle facial details. The most important empirical claim is not just that the images look good, but that the synthetic identities occupy a more realistic region of FRS embedding space and can be filtered to target practical false-match-rate thresholds rather than enforcing zero similarity as ONOT did.
Key findings
- The framework generated 15,000 synthetic identities, of which 14,889 remained after excluding 111 identities where Arc2Face failed to extract identity embeddings.
- Document-image LoRA training used 830 Chicago Face Database (CFD) images, rank r = 16, learning rate 0.0002, and 18 epochs; the adapter was then used to produce 1024×1024 document-style images.
- Similarity filtering at a dataset-wide FMR target of 0.01% retained 9,358 identities with ArcFace (62.9%) and 6,074 with AdaFace (40.8%); at 0.1% it retained 6,641 with ArcFace (44.6%) and 2,389 with AdaFace (16.0%).
- Compared with ONOT’s stricter identity filtering, FLUXSynID retained 51.0% of identities at FMR 0.1% and 87.1% at FMR 0.01% using ArcFace thresholds, versus ONOT’s reported 3.1% and 6.3% (authors note this comparison is not exact because ONOT also applies intra-class filtering).
- In the embedding analysis (Fig. 7), FLUXSynID identities overlap more with real CFD and FRLL distributions than StyleGAN2-generated identities and ONOT identities, which form tighter, less realistic clusters.
- Table 2 shows that FLUXSynID-LL had KL divergence 1.047 vs FRLL for mated pairs, while ONOT had 23.793; for non-mated pairs FLUXSynID-LL had 0.248 vs ONOT’s 5.202.
- The authors found guidance scales between 1.7 and 2.5 worked best for document generation; below 1.7 images often had artifacts/poor prompt adherence, above 2.5 they became overly saturated and too similar, increasing removals during similarity filtering.
- For no-identity-leakage checking, all 14,889 FLUXSynID identities were compared against the 830 CFD subjects used for LoRA training using AdaFace with threshold 0.539, and no matches were found.
Threat model
The relevant adversary is not a malicious attacker but the practical failure mode of a synthetic biometric dataset: the system should resist generating near-duplicate identities, leaking training identities from CFD, or collapsing demographic diversity under a face-recognition similarity filter. The authors assume an FRS-based evaluator/adversary such as ArcFace or AdaFace can detect identity collisions and that dataset designers want to keep those collisions below a chosen FMR target (0.1% or 0.01%), but they do not consider an attacker trying to invert the generator or deliberately exploit the synthetic pipeline.
Methodology — deep read
Threat model and assumptions: this is not a security attack paper in the usual sense, but it does make an explicit biometric-dataset assumption: the adversary/problem is the lack of sufficient, diverse, privacy-safe face data for training and evaluating systems such as face recognition and morphing attack detection. The paper assumes the generator should create identities that are distinct enough to be treated as separate subjects under a chosen face recognition system (FRS), yet similar enough to real-world population structure to be useful. It also assumes a practical biometric setting where document-style images and live capture images need to be paired per identity. The system is not framed against a malicious generator adversary; instead, the main risks are biased synthesis, identity leakage from fine-tuning data, and over-clustering of synthetic identities that would make the dataset unrealistic.
Data provenance and composition: the document-image style is learned from the Chicago Face Database (CFD), and the final synthetic set is built from 15,000 generated identities spanning 14 attribute classes: gender, age, region of origin, body type, eye shape, lip shape, nose shape, face shape, hairstyle, hair color, eyewear, facial hair, skin type, and ICAO-compliant headwear. The paper says gender, age, and region of origin are included in 100% of prompts; age, region, and body type are sampled uniformly, while other attributes use heuristic probabilities based on rough prior expectations. Attribute-clash rules prevent semantically invalid combinations, e.g. baldness excluding hair-color attributes. Prompts are generated by Qwen2.5 from sampled attribute sets. The document-image generation resolution is 1024×1024, except Arc2Face live outputs are limited to 512×512 because of implementation constraints. After generation, 111 identities are removed because Arc2Face could not extract identity embeddings, leaving 14,889 identities.
Architecture / algorithm: FLUXSynID has a two-stage pipeline. First, document-style images are generated with FLUX.1 [dev], a latent diffusion model with a rectified-flow transformer backbone, using a LoRA adapter fine-tuned on CFD to bias outputs toward frontal, neutral-expression, white-background portraits. The prompt is textually rich because Qwen2.5 turns attribute samples into natural-language descriptions; FLUX.1 [dev] conditions through CLIP-L and T5-XXL, and sampling uses DPM++ 2M with classifier-free guidance integrated into the model. The LoRA adapter is the main novelty for document style: it keeps the base model frozen and learns a low-rank update, trained on CFD captions made with InternVL2.5. Second, live images are created by three complementary methods. LivePortrait is used as an expression/pose animator to make subtle live-style changes from a single document image. Arc2Face conditions a diffusion model on ArcFace identity embeddings to make more unconstrained live-like variants. The major technical contribution is the PuLID adaptation: synthetic document images and LivePortrait-modified images are passed through a PuLID identity encoder, their static/dynamic features are averaged into an identity condition, and this is combined with a rewritten “airport setting” prompt plus edge maps from the LivePortrait image. Those edges are encoded through FLUX’s VAE and concatenated with Gaussian latent noise; a FLUX.1 [dev] Canny LoRA adapter then uses the combined latent plus identity and text conditioning to denoise into a live-capture-style image. In plain terms, PuLID is being used not just for identity injection, but as part of a three-signal control system: identity embedding, textual context, and structural edge guidance.
Training regime and concrete example: the document LoRA is trained with FluxGym on the 830 CFD images for 18 epochs at learning rate 0.0002 and rank 16, with the LoRA activated at inference by a special token (“s7ll2f4h”). Additional CLIP-L parameters are also fine-tuned. During inference, guidance scale is sampled uniformly from 1.7 to 2.5, and generation uses 20 diffusion steps. For live methods, LivePortrait and modified PuLID-FLUX use ComfyUI-based implementations; PuLID uses a fixed guidance scale of 4 and 20 steps as recommended by its authors; Arc2Face uses the official code with defaults. A concrete end-to-end example: sample attributes such as female, age band, origin region, and hairstyle; Qwen2.5 turns them into a prompt; FLUX.1 [dev] + LoRA generates a frontal ID-style portrait; that image is fed to LivePortrait for subtle pose/expression variation, to Arc2Face for identity-embedded variation, and to PuLID together with an airport-context prompt and edge map to produce the live-capture variant. The result is a matched set of document and live images for the same synthetic person.
Evaluation protocol and reproducibility: evaluation is multi-pronged. Visual inspection is used for style/identity consistency; Fig. 4 shows paired outputs, Fig. 5 shows prompt-to-image attribute adherence, Fig. 6 checks how similarity filtering shifts attribute distributions, Fig. 7 uses t-SNE over ArcFace/AdaFace embeddings to compare real and synthetic identity spaces, and Fig. 8 plus Table 2 compare mated/non-mated cosine-similarity distributions via KL divergence against real datasets FRLL and FRGC. The authors also perform similarity-based filtering using ArcFace and AdaFace at FMR targets of 0.1% and 0.01%, with thresholds derived from 340k impostor trials on CFD identities. They compare FLUXSynID with ONOT by looking at how many identities remain after filtering, and they separately check for leakage between CFD training identities and the generated identities using AdaFace with a threshold of 0.539; no leakage is found. Reproducibility is partial: the framework is publicly released on GitHub, but the full dataset release details are not fully visible in the truncated text here, and some components depend on specific third-party implementations (FluxGym, ComfyUI, FLUX, LivePortrait, PuLID-FLUX-v0.9.1, Arc2Face). Some implementation details are explicit, but exact random seeds, train/val splits, and full prompt templates are not described in the excerpt.
Technical innovations
- Identity-controlled prompt generation with user-defined attribute classes, inclusion probabilities, and semantic clash detection to enforce coherent demographic sampling.
- A LoRA-tuned FLUX.1 [dev] document-image generator that learns a consistent frontal/neutral/white-background biometric style from CFD captions.
- A three-path live-image synthesis strategy combining LivePortrait, Arc2Face, and a novel PuLID-FLUX adaptation that fuses identity embeddings, rewritten contextual prompts, and edge-based structural conditioning.
- A similarity-based filtering scheme that targets practical dataset-wide FMR thresholds instead of ONOT-style zero-similarity pruning.
- A comparison-focused synthetic dataset design that explicitly studies how filtering changes demographic distributions and embedding-space alignment with real biometric corpora.
Datasets
- FLUXSynID synthetic identities — 14,889 identities after filtering (15,000 initially generated; 111 removed due to Arc2Face failures) — publicly released by the authors
- Chicago Face Database (CFD) — 830 images used for LoRA training — public dataset
- FRLL — size not specified in excerpt — public benchmark used for embedding/similarity comparison
- FRGC — size not specified in excerpt — public benchmark used for embedding/similarity comparison
- StyleGAN2 synthetic faces via pSp encoder — size not specified in excerpt — prior synthetic comparison set
- ONOT subset 1 — 255 identities reported by ONOT in cited comparison — prior synthetic dataset
Baselines vs proposed
- ONOT (identity filtering): retained identities = 3.1% at FMR 0.1% vs proposed = 51.0% using ArcFace thresholds (authors note the comparison is not exact because ONOT also applies intra-class filtering)
- ONOT (identity filtering): retained identities = 6.3% at FMR 0.01% vs proposed = 87.1% using ArcFace thresholds (authors note the comparison is not exact because ONOT also applies intra-class filtering)
- ONOT vs FLUXSynID-LL: KL divergence (mated, FRLL) = 23.793 vs proposed = 1.047
- ONOT vs FLUXSynID-LL: KL divergence (non-mated, FRLL) = 5.202 vs proposed = 0.248
- ONOT vs FLUXSynID-LA: KL divergence (non-mated, FRGC) = 4.715 vs proposed = 0.101
- ONOT vs FLUXSynID-LP: KL divergence (mated, FRGC) = 6.770 vs proposed = 15.512
- StyleGAN2/pSp synthetic identities: t-SNE clusters show poor overlap with real CFD/FRLL distributions vs proposed = greater overlap (qualitative, Fig. 7)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2505.07530.
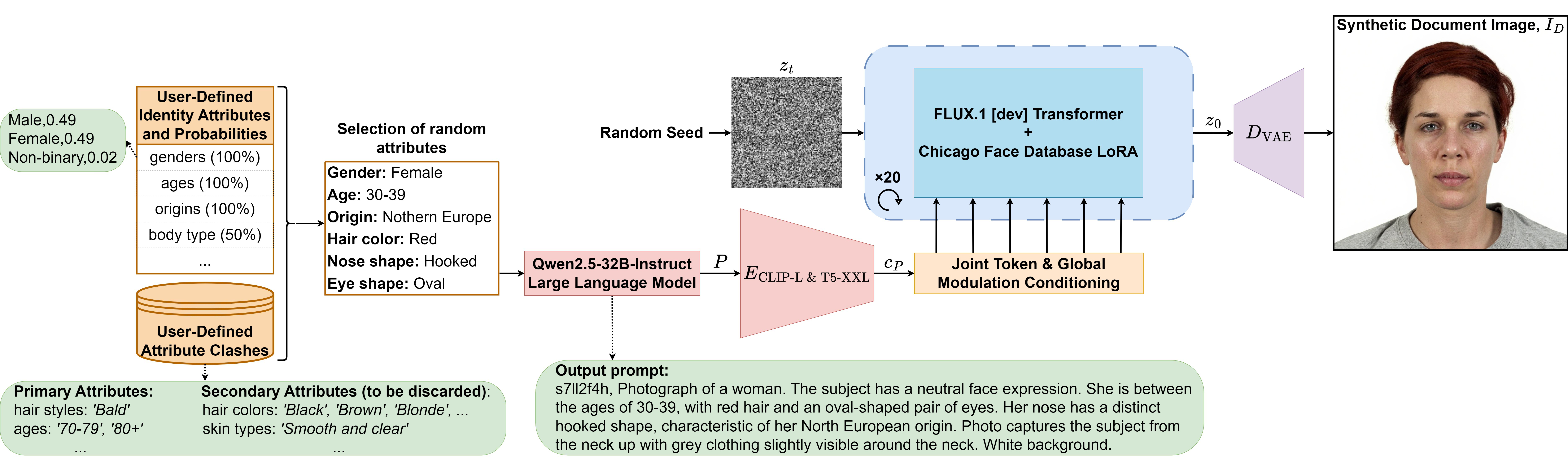
Fig 1: Overview of the FLUXSynID pipeline for synthetic document image generation. Given user-defined identity attributes and

Fig 2: (Top row): Synthetic document images generated with-
Fig 3: Overview of the FLUXSynID live capture image generation pipeline. Starting from a synthetic document image, three methods

Fig 4: Examples of synthetic identities from FLUXSynID, each shown with a document image (ID) and corresponding live capture

Fig 5: Examples of randomly sampled identity attributes and
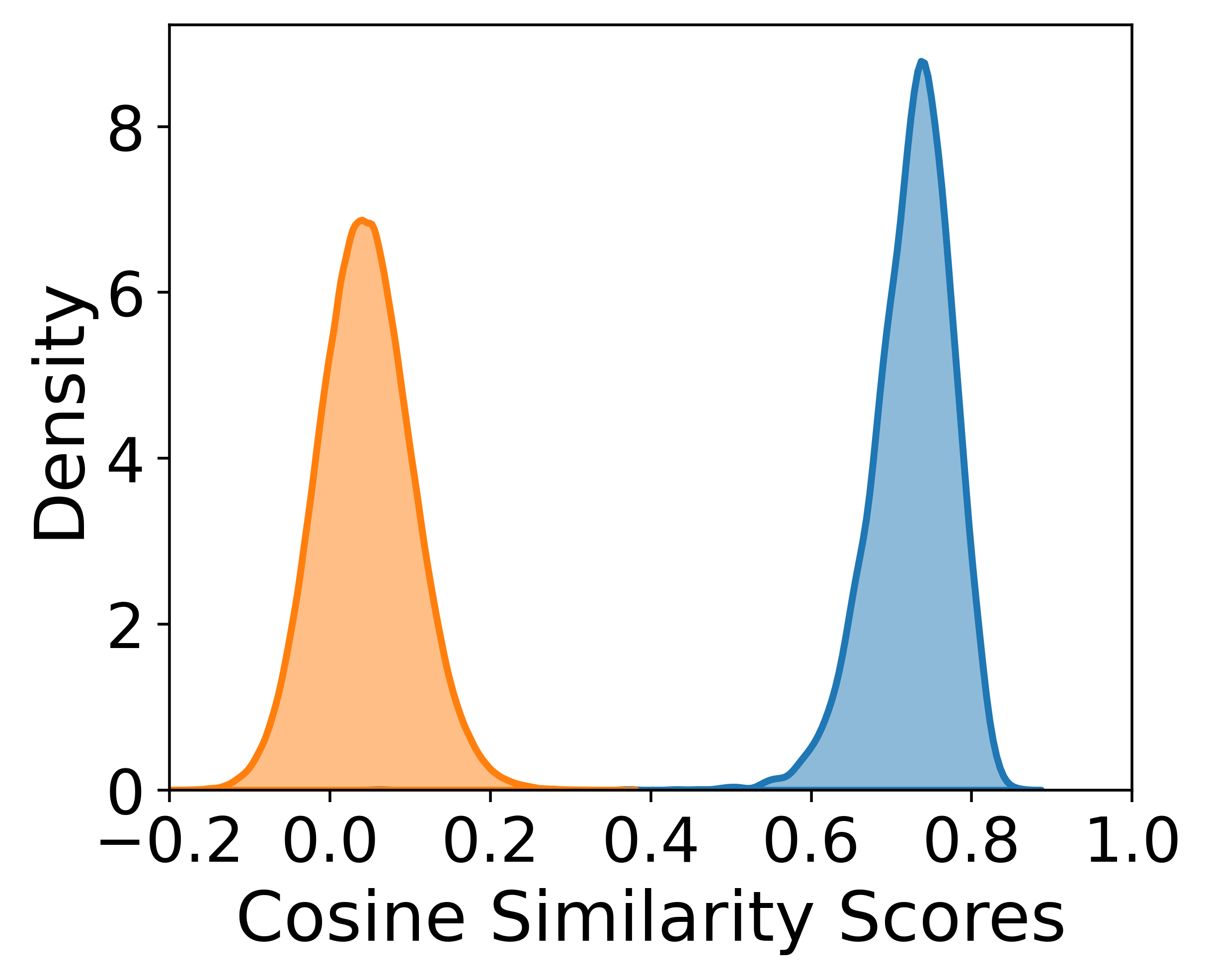
Fig 6: Distribution of identity attributes in the dataset before and after filtering based on identity similarity. Each bar plot shows the
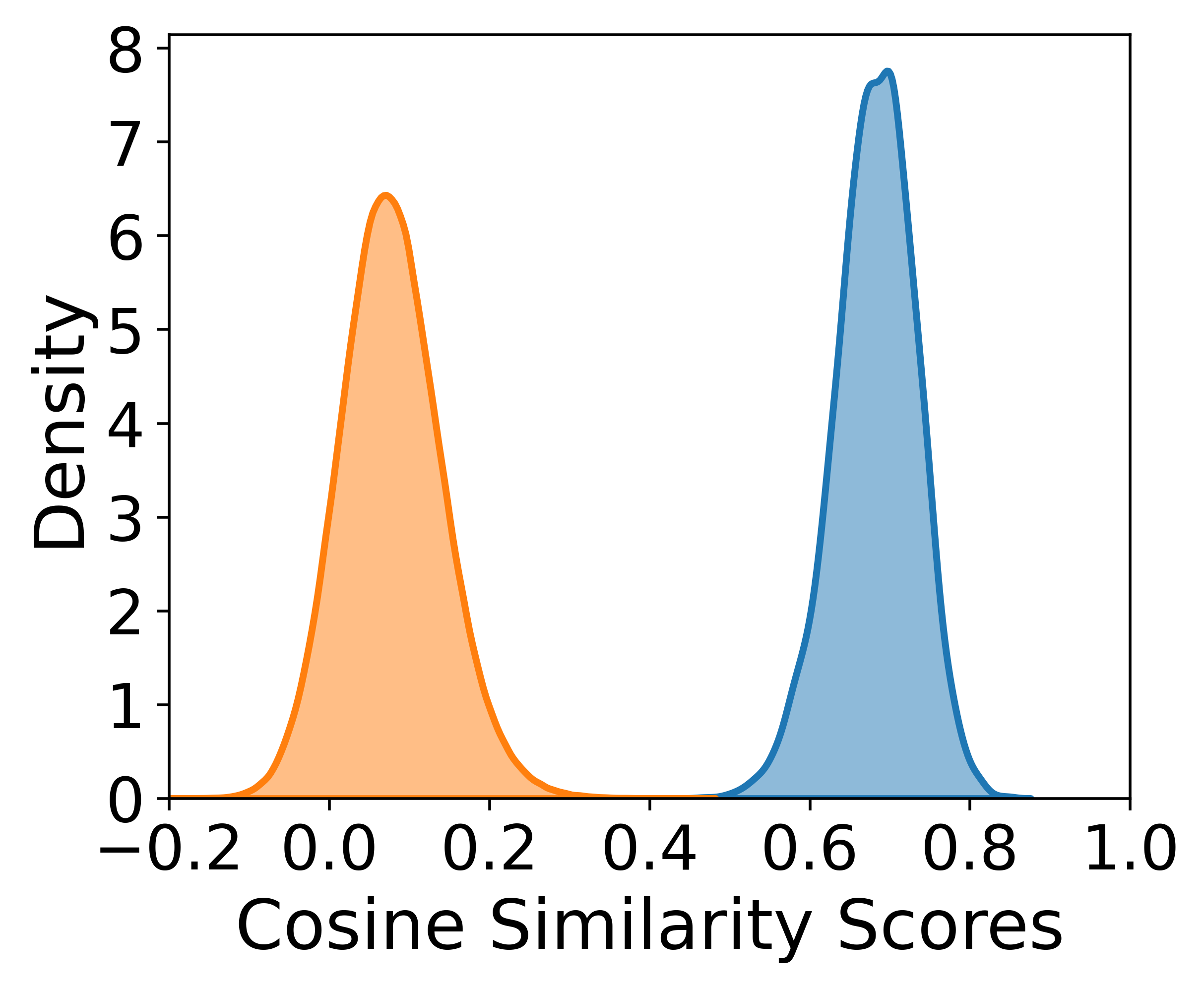
Fig 7: t-SNE [53] visualization of FRS embeddings derived
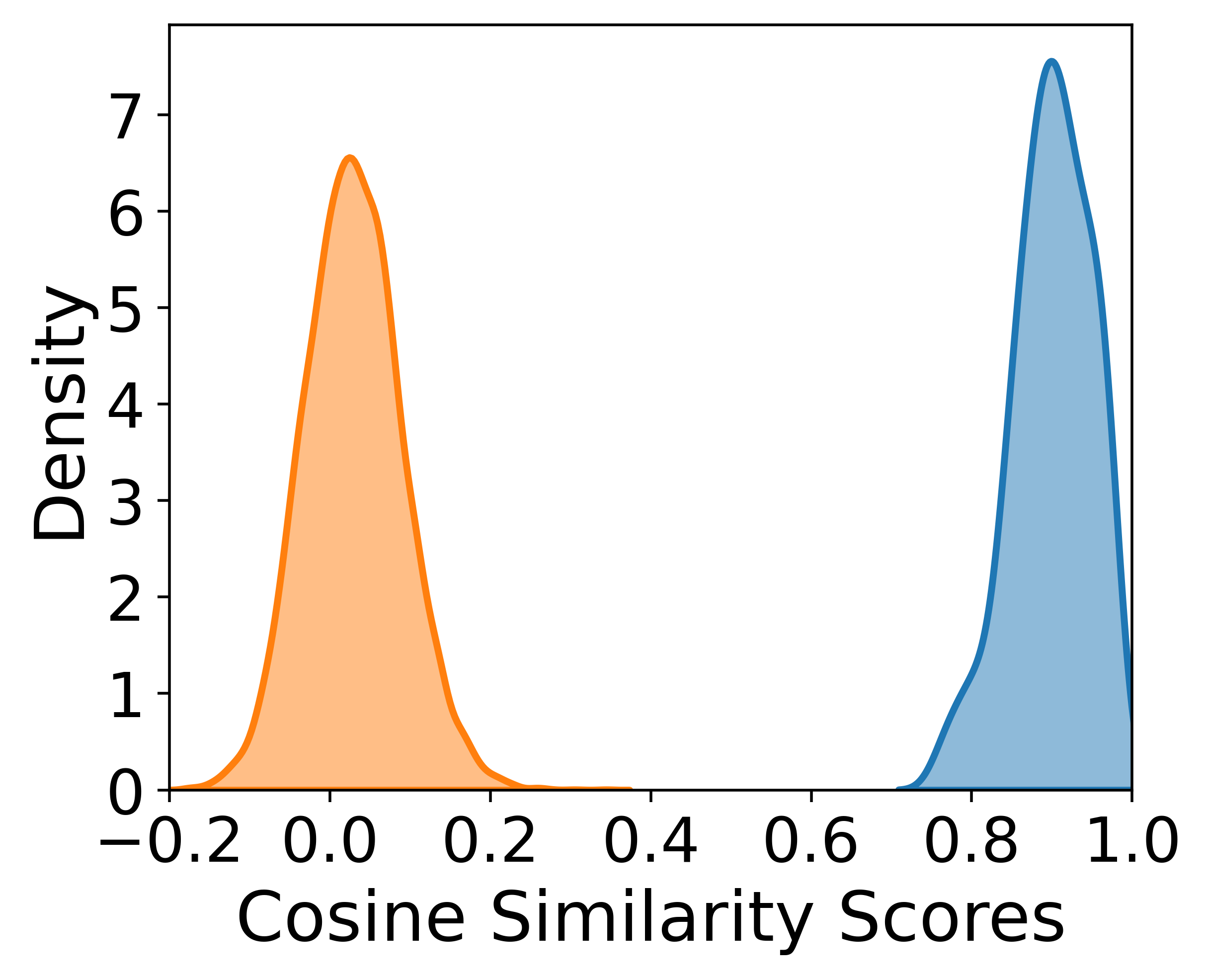
Fig 8: Distribution of cosine similarity scores for mated (blue)
Limitations
- Age and subtle facial attributes are not always faithfully represented; the paper explicitly says age estimation can drift and features like nose shape are inconsistently realized.
- Similarity-based filtering can skew demographics: female identities and younger identities were removed more often, changing the post-filter distribution.
- The comparison to ONOT’s retained-identity percentages is explicitly described as not exact because ONOT also uses additional intra-class filtering.
- FLUXSynID does not enforce explicit ICAO compliance filtering, so it trades strict document compliance for larger scale and embedding diversity.
- Arc2Face failed on 111 identities, indicating some pipeline fragility and an upstream dependency on identity-embedding extraction.
- The excerpt does not provide a full statistical significance analysis, seed strategy, or a full public reproducibility package description beyond code release.
Open questions / follow-ons
- How sensitive are the generated identity distributions to the heuristic attribute probabilities, and can they be learned from real demographic priors rather than hand-set?
- Would strict ICAO-compliance filtering materially improve downstream MAD performance, or does the current scale/diversity trade-off already dominate?
- How robust are the live-image variants under stronger cross-domain evaluation, e.g. unseen sensors, compression, lighting shifts, or different face recognition models?
- Can the similarity-based filtering be made attribute-aware so it reduces collisions without disproportionately removing specific demographic groups?
Why it matters for bot defense
For bot-defense and biometric-liveness engineers, FLUXSynID is relevant as a data-generation tool rather than an attack method: it provides paired document/live synthetic identities that could help train or stress-test face-verification, morph-detection, and identity-consistency pipelines. The most practical takeaway is that synthetic data can be made more useful when it is evaluated in embedding space, not just by visual realism, and when the generator explicitly controls demographic attributes and capture conditions. If you are building anti-abuse systems, this paper suggests a way to create larger, more diverse evaluation sets for document-vs-live comparison, but it also shows that synthetic data can inherit demographic bias and similarity collapse, so you would want to audit post-filter distributions carefully before using it for benchmarking or model training.
Cite
@article{arxiv2505_07530,
title={ FLUXSynID: A Framework for Identity-Controlled Synthetic Face Generation with Document and Live Images },
author={ Raul Ismayilov and Dzemila Sero and Luuk Spreeuwers },
journal={arXiv preprint arXiv:2505.07530},
year={ 2025 },
url={https://arxiv.org/abs/2505.07530}
}