
An Agent-Based Modeling Approach to Free-Text Keyboard Dynamics for Continuous Authentication
Source: arXiv:2505.05015 · Published 2025-05-08 · By Roberto Dillon, Arushi
TL;DR
This paper asks whether free-text keystroke biometrics can be studied without collecting real user data by simulating typing behavior with an agent-based model (ABM). The motivation is practical: continuous authentication for email, document editing, and other real-world text entry is attractive, but public free-text datasets are scarce and often mismatched to the exact hardware and protocol a researcher wants to study. The authors therefore build a synthetic generator that emits keystroke press/release events for five distinct agents, each with different typing speed, error rate, fatigue sensitivity, hand dominance, and keyboard type.
The main result is less about squeezing out a benchmark win and more about exposing a structural issue: keyboard hardware strongly reshapes the feature distributions. In their synthetic data, a Random Forest could separate different users reasonably well when training and testing stayed within the same keyboard type, but it failed to generalize a user profile across laptop vs mechanical keyboards. One-Class SVM, even after PCA reduction, was substantially weaker at distinguishing users and frequently accepted impostor samples as inliers. The paper’s practical takeaway is that keyboard-specific models may be necessary for continuous authentication, and that simulation can be useful for stress-testing assumptions before collecting expensive real data.
Key findings
- The ABM generated five synthetic users, each with two sessions per keyboard type, for 10 total sessions and four files per user: 1,000 typed characters per file on laptop and mechanical keyboards.
- Kolmogorov-Smirnov tests on extracted features were usually significant between different users on the same keyboard (p < 0.05), but same-user same-keyboard comparisons were often not significant (p > 0.05); same-user cross-keyboard comparisons were described as having p-values "very close to 0.00".
- One-Class SVM often failed to separate users: cross-user inlier rates were frequently above 60% and ranged from 50% to 81.25%, indicating many impostor sessions were still accepted as matching the target profile.
- The authors report same-user same-keyboard OC-SVM inlier rates such as 78.15% for User 4 and 73.23% for User 5 on laptop, and 74.04% for User 2 and 81.25% for User 5 on mechanical.
- Random Forest used 500 trees, max depth 10, min_samples_split 5, min_samples_leaf 2, and sqrt feature subsampling; it was evaluated with an accuracy threshold of 0.70 to decide whether two sessions came from different users.
- On laptop sessions, RF often produced high cross-user accuracies such as U1-1 vs U2-1 at 0.88, U1-1 vs U4-1 at 0.90, and U4-1 vs U5-1 at 0.98, while same-user comparisons could fall below threshold, e.g. U1-1 vs U1-2 at 0.66 and U5-1 vs U5-2 at 0.56.
- On mechanical sessions, RF similarly produced many cross-user accuracies above 0.9, while same-user comparisons stayed below the 0.70 threshold in reported examples such as U1-1 vs U1-2 at 0.68 and U2-1 vs U2-2 at 0.67.
- The model could not recognize the same simulated user across different keyboard types: the authors state that sessions from the same agent were "all recognized as different with A > 0.9" when comparing across keyboard types.
- User 3 was the hardest profile to distinguish; the authors note multiple misclassifications involving User 3 and User 5, especially on the laptop simulation.
- The most important RF feature varied by pair: Figure 3 shows average dwell time dominating for same-user laptop comparisons, Figure 4 shows average flight time dominating for a different-user comparison, and Figure 5 shows standard deviation of dwell time helping drive a misclassification between User 3-1 and User 5-2.
Threat model
The assumed adversary is an impostor attempting to masquerade as an enrolled user during free-text typing in a continuous-authentication setting. The system can observe keystroke timing, dwell time, flight time, and error behavior over sliding windows, but it cannot rely on fixed passwords or prompts. The paper does not consider malware, keystroke injection, or adaptive mimicry attacks; it also does not assume the attacker can change the keyboard hardware in a controlled way beyond whatever the environment provides. The key uncertainty is whether a model trained on one session or one keyboard can distinguish the legitimate user from a different user or from the same user on another keyboard.
Methodology — deep read
The threat model is a continuous-authentication setting in which the system observes free-text typing in the background and must decide whether the current session belongs to the enrolled user or an impostor. The paper’s adversary is not a live active attacker with malware or keystroke injection; instead, the evaluation is framed as session-level verification across simulated users. The central assumption is that typing rhythm is user-specific enough to support biometrics, but also that keyboard hardware changes the observable behavior. The authors explicitly study two hardware classes: laptop (membrane) and mechanical keyboards. They do not model a capable adaptive attacker who knows the feature extractor or attempts mimicry, nor do they evaluate adversarial manipulation of timing features.
Data are synthetic, generated entirely by the ABM rather than collected from humans. The paper defines five agents with parameter ranges for WPM, error rate, fatigue factor, finger agility, and dominant hand; Table 1 lists the ranges used, including one left-handed user and four right-handed users. For each agent, the generator produces two 1,000-character typing sessions on each of the two keyboard types, yielding four files per user and 20 total session files across the five users. The text generator samples English-like characters from empirical character frequencies, and the system outputs timestamped press and release events at millisecond precision. Features are then computed over a sliding 5-second window updated every second. Each window yields five features: average dwell time, dwell-time standard deviation, average flight time, flight-time standard deviation, and error rate (backspaces divided by total characters in the window, expressed as a percentage).
The ABM itself is the main algorithmic contribution. It models typing as an event-driven process with internal state variables for fatigue, speed, and short-term memory of previous characters. A keyboard geometry module maps QWERTY keys to coordinates so Euclidean distance can influence transitions. The most distinctive piece is the flight-time formulation in Eq. (1): flight time is a product of a keyboard-specific base time, a distance term, a per-pair personal factor, a quadratic fatigue multiplier, and Gaussian noise N~N(1,0.05). The personal factor P_i,j in Eq. (2) combines a user baseline multiplier, a hand-dominance term, and a digraph bonus for common English digraphs. Repeated characters get a special-case shorter effective distance (D_i,j = 0.2). Fatigue accumulates monotonically by a user-specific increment gamma (Eq. 3), and the typing speed WPM decreases quadratically with fatigue according to Eq. (4). Error generation is also explicit: each character can trigger a backspace event with probability e, and backspaces have shorter dwell times, modeled as N(40,3) ms. The implementation is in Python using NumPy; the paper does not report any non-default library beyond that for the simulator.
For preprocessing and statistical inspection, the authors apply Kolmogorov-Smirnov tests pairwise across extracted feature distributions. Their tables compare same-agent same-keyboard sessions, different-agent same-keyboard sessions, and same-agent cross-keyboard sessions. The reported pattern is that same-user same-keyboard distributions are often similar enough that p-values exceed 0.05 for most features, while different-user pairs are often significantly different. By contrast, cross-keyboard comparisons for the same agent show dramatic shifts, with p-values described as effectively zero across all features. This supports the paper’s thesis that the hardware itself is a major covariate in continuous authentication.
For classification, the authors compare two methods. First, One-Class SVM is used as an anomaly detector. Before OC-SVM, the five features are normalized and reduced to the first two principal components via PCA. The stated reason is to reduce dimensionality, avoid overfitting, and visualize inliers/outliers in 2D. The model is trained on one full session for a given user-keyboard pairing and tested on the held-out session and on other users’ sessions. The reported outputs are inlier percentages rather than a standard binary accuracy, so the evaluation is closer to "does this session look like the target user?" than a full multi-class identification task. Second, Random Forest is used as a binary session-pair classifier with scikit-learn. The authors specify 500 trees, max depth 10, min_samples_split 5, min_samples_leaf 2, max_features=sqrt, and bootstrap enabled. One full session per keyboard is used for training and the remaining sessions are used as tests. They interpret accuracy above 0.70 as evidence the two sessions come from different users; accuracy below 0.70 means the pair is too similar to separate reliably and is treated as same-user-like.
A concrete end-to-end example is Figure 3: User 1-1 versus User 1-2 on the laptop keyboard. The two sessions are first converted into sliding-window features (average and standard deviation of dwell and flight time, plus error rate). These features are then fed into Random Forest, which classifies the pair as same-user-like because the accuracy is 0.66, below the 0.70 threshold. Figure 3 also shows feature importance, with average dwell time being the most important contributor in that comparison. By contrast, Figure 4 shows a different-user case, User 1-1 versus User 3-2 on laptop, where average flight time becomes the most important feature and the pair is correctly classified as different users. Figure 5 shows a failure case, User 3-1 versus User 5-2, where standard deviation of dwell time is most important but overlapping error-rate and flight-time variability causes a same-user-like misclassification. The paper does not report cross-validation, confidence intervals, or statistical significance tests for the classifier outputs, and it does not release code, frozen weights, or a public dataset in the text provided.
Technical innovations
- A keyboard-aware ABM that makes flight time depend on QWERTY geometry, hand dominance, digraph frequency, keyboard type, and fatigue rather than sampling all digraphs from a uniform distribution.
- A synthetic free-text keystroke generator that emits press/release events with millisecond timestamps and explicit backspace-correction behavior, enabling continuous-authentication experiments without collecting human logs.
- A sliding-window feature extraction pipeline for free-text typing that tracks mean and standard deviation of dwell and flight time plus error rate over 5-second windows updated every second.
- A comparative evaluation showing that a simple Random Forest is more discriminative than OC-SVM on this synthetic data, while also surfacing the hardware generalization problem that a pure user profile cannot ignore.
- An explicit simulation of cross-keyboard variability as a first-class factor, rather than treating keyboard type as nuisance noise.
Datasets
- Synthetic ABM keystroke sessions — 20 session files total (5 users × 2 keyboard types × 2 sessions), 1,000 characters per file — generated by the authors in Python
- Sliding-window feature tables — derived from the 20 synthetic sessions using 5-second windows updated every second — generated by the authors
Baselines vs proposed
- One-Class SVM: cross-user inlier detection often > 0.60, range 0.50–0.8125 vs proposed RF: same-user/different-user separation improved, but no direct scalar accuracy comparison reported
- One-Class SVM: User 4 laptop same-keyboard inlier rate = 78.15% vs User 4 laptop held-out same-user session; User 5 laptop same-keyboard inlier rate = 73.23% vs same-user held-out session
- One-Class SVM: User 2 mechanical same-keyboard inlier rate = 74.04% vs User 5 mechanical same-keyboard inlier rate = 81.25%
- Random Forest: User1-1 vs User1-2 on laptop A = 0.66 vs threshold 0.70 (same-user-like)
- Random Forest: User1-1 vs User2-1 on laptop A = 0.88 vs threshold 0.70 (different-user)
- Random Forest: User4-1 vs User5-1 on laptop A = 0.98 vs threshold 0.70 (different-user)
- Random Forest: User1-1 vs User1-2 on mechanical A = 0.68 vs threshold 0.70 (same-user-like)
- Random Forest: User2-1 vs User2-2 on mechanical A = 0.67 vs threshold 0.70 (same-user-like)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2505.05015.
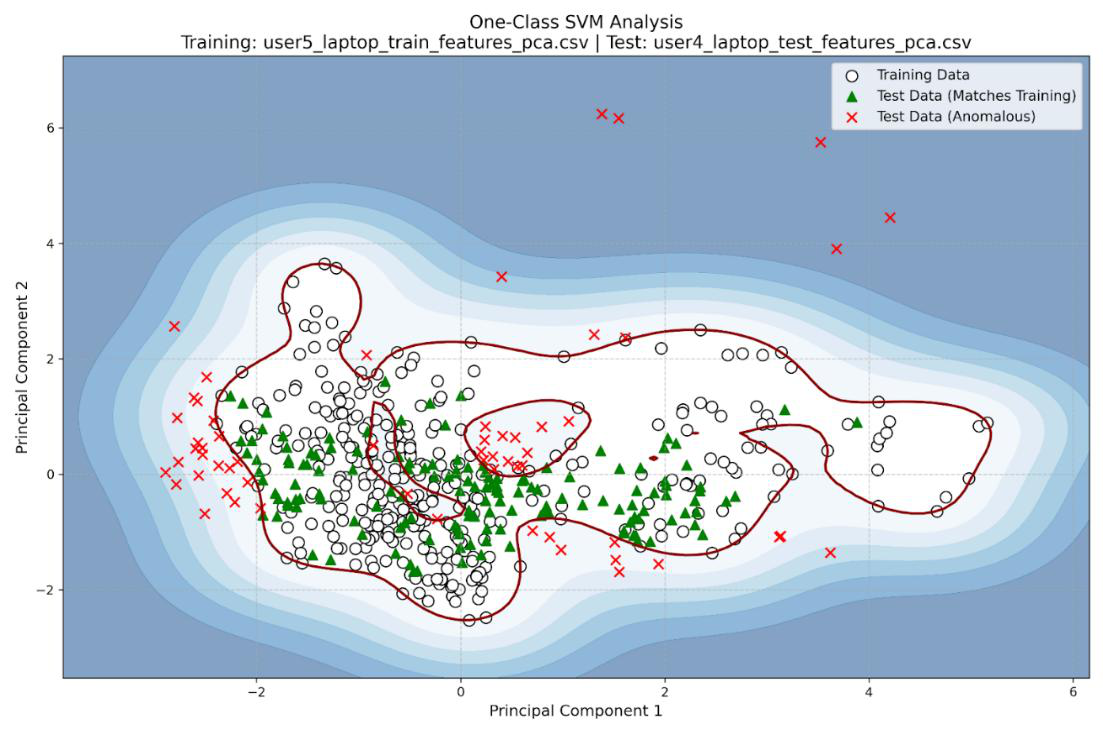
Fig 1: Data points for “User 5 L 1” vs “User 4 L 2”. More than 70% of the testing data falls in the
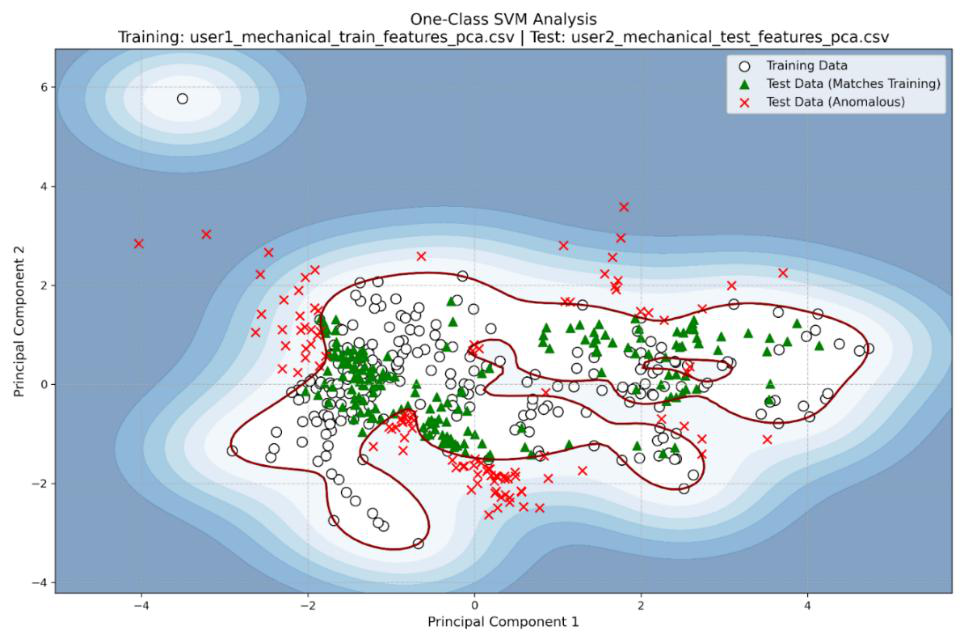
Fig 2: Data points for “User 1 M 1” vs “User 2 M 2”. More than 60% of the testing data is still
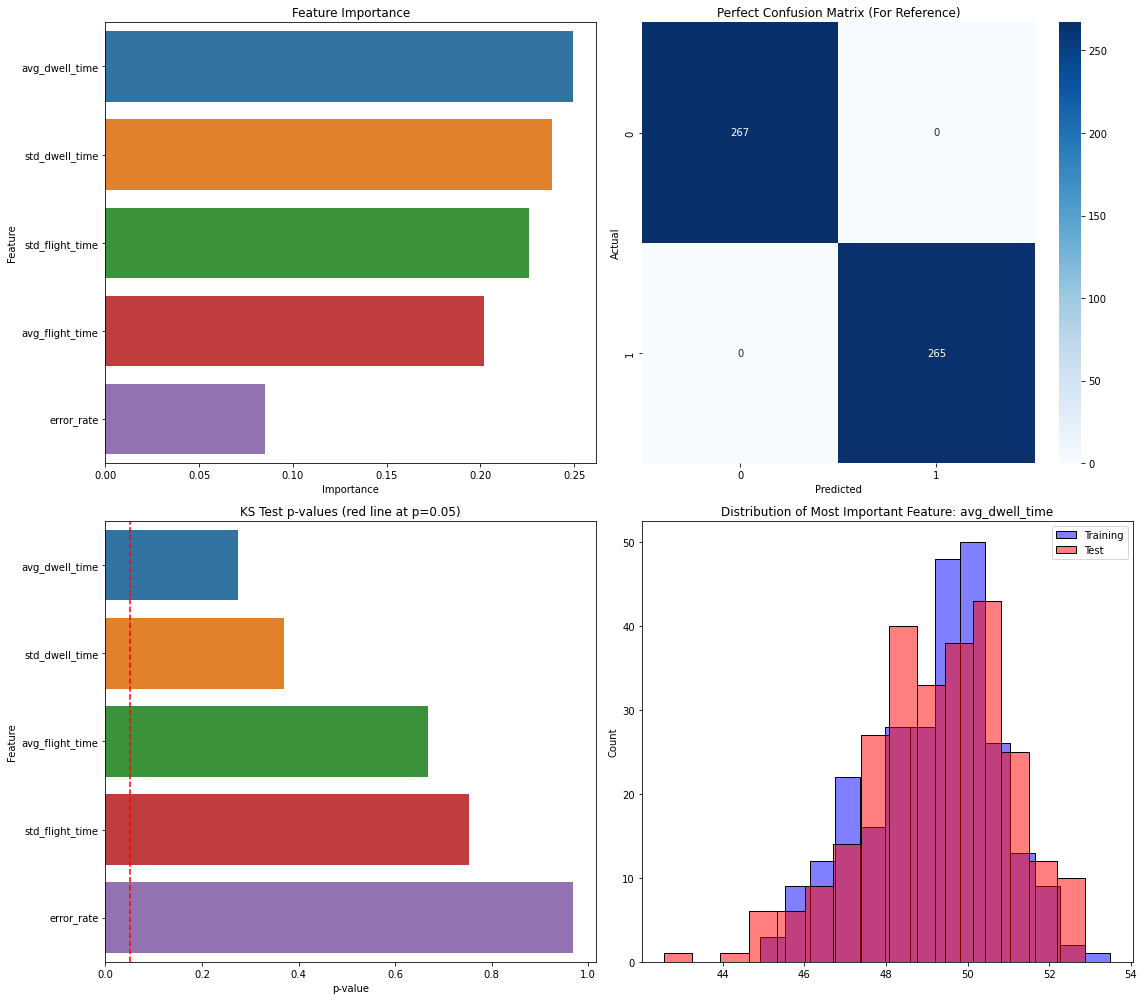
Fig 3: Analysis for User 1-1 vs User 1-2 sessions on a laptop keyboard, which are correctly recognized
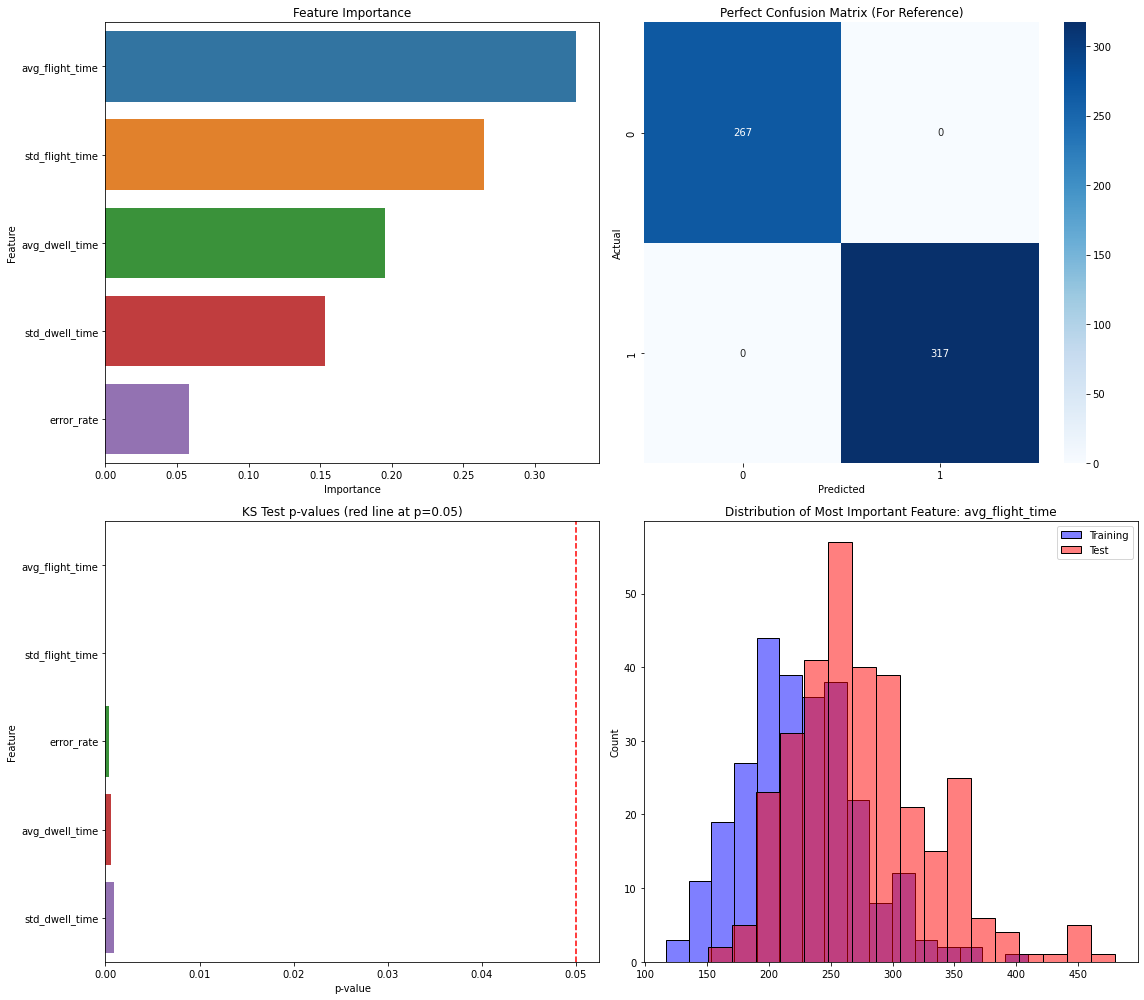
Fig 4: Analysis for User 1-1 vs User 3-2 sessions on a laptop keyboard, which are correctly recognized
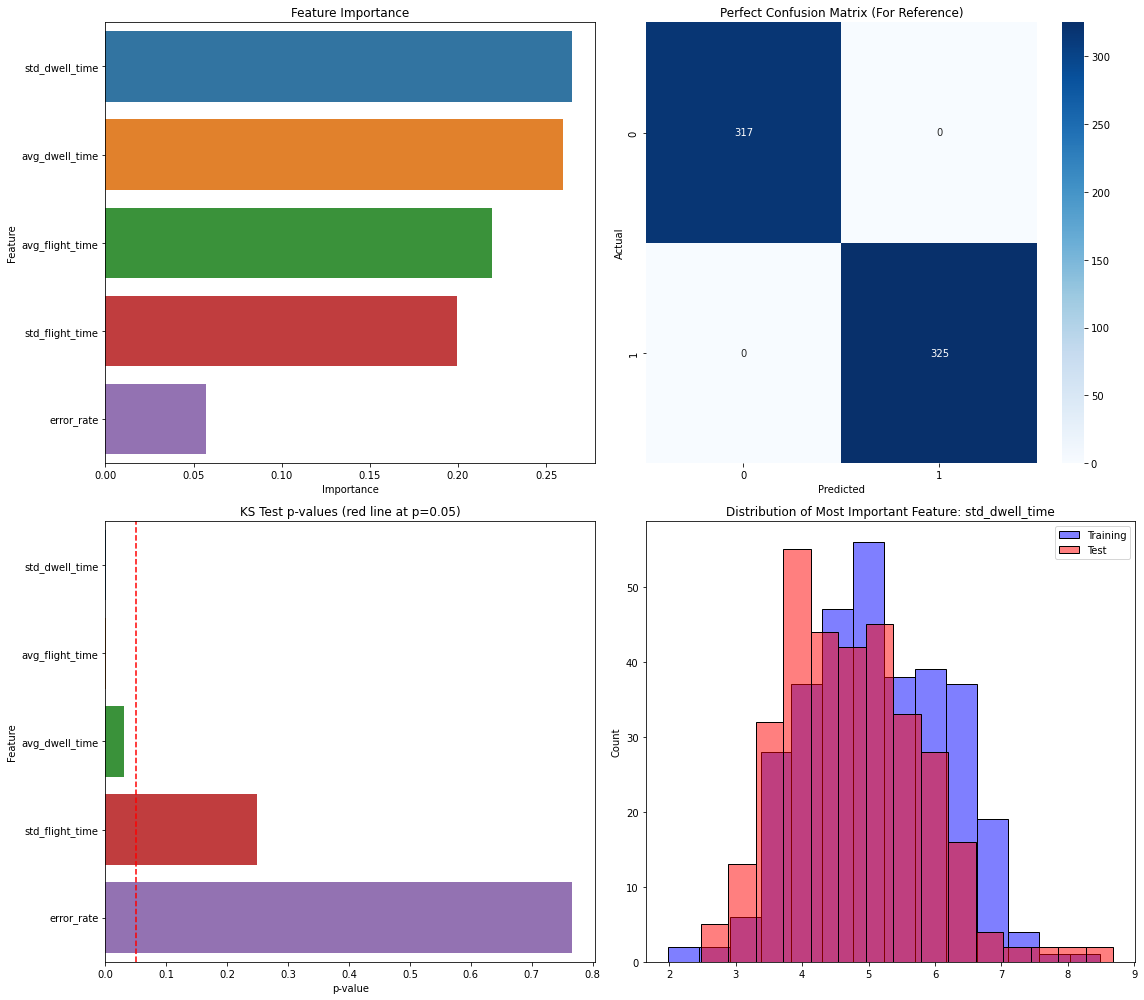
Fig 5: Analysis for User 3-1 vs User 5-2 sessions on a laptop keyboard, which are wrongly identified
Limitations
- The entire dataset is synthetic, so the results depend on the realism of the ABM rather than observed human behavior; there is no external validation against real keystroke logs in the paper text provided.
- Only five agents were simulated, which is too small to estimate population-scale variance or to stress-test whether the learned separability survives broader user diversity.
- The ABM encodes keyboard-specific differences by design, so the strong cross-keyboard failure may partly reflect the generator’s assumptions rather than an empirical property of all users.
- The OC-SVM evaluation is constrained by PCA to two components, which may discard discriminative information and make the comparison less favorable to the anomaly detector.
- The paper does not report cross-validation, confidence intervals, calibration, or statistical tests on classifier performance, so the robustness of the reported accuracies is unclear.
- The RF decision rule is based on a hard 0.70 threshold chosen by the authors; the effect of threshold tuning on FAR/FRR tradeoffs is not explored.
Open questions / follow-ons
- How much of the observed cross-keyboard drift remains after controlling for text content, task type, and session length in real human data?
- Would adding richer features such as digraph/trigraph counts, burstiness, correction patterns, or n-gram context improve same-user across-device recognition?
- Would a domain-adaptation or calibration layer let a single user profile generalize across laptop and mechanical keyboards without a separate model per device?
- How well does the ABM match real users when validated against a held-out human dataset, especially for fatigue progression and error-correction timing?
Why it matters for bot defense
For bot-defense and continuous-authentication practitioners, the paper is a reminder that typing biometrics are not just "user style" signals; they are entangled with hardware, text content, and session context. If you deploy free-text keyboard dynamics, you should expect device-specific calibration to matter, and you should test whether a model trained on one keyboard or one office setup fails badly on another. The paper also suggests a useful engineering pattern: use ABM-generated data to probe feature sensitivity and identify brittle assumptions before collecting sensitive real-user telemetry. The cautionary side is that simulation can easily overstate separability if the generator bakes in too much structure, so synthetic results should be treated as a design aid, not evidence of field performance.
Cite
@article{arxiv2505_05015,
title={ An Agent-Based Modeling Approach to Free-Text Keyboard Dynamics for Continuous Authentication },
author={ Roberto Dillon and Arushi },
journal={arXiv preprint arXiv:2505.05015},
year={ 2025 },
url={https://arxiv.org/abs/2505.05015}
}