
A Tale of Two Identities: An Ethical Audit of Human and AI-Crafted Personas
Source: arXiv:2505.07850 · Published 2025-05-07 · By Pranav Narayanan Venkit, Jiayi Li, Yingfan Zhou, Sarah Rajtmajer, Shomir Wilson
TL;DR
This paper conducts a comprehensive ethical audit comparing synthetic personas generated by three large language models (GPT4o, Gemini 1.5 Pro, Deepseek 2.5) to human-authored self-descriptions, with a focus on racial identity representation. They collected 756 authentic self-descriptions from 126 U.S.-demographically diverse participants alongside 1,512 synthetic personas generated under various prompt conditions. The study uses mixed methods including lexical analyses, sociolinguistic markedness, sentiment analysis, and a parameterized creativity framework to reveal systematic differences in how LLMs and humans represent identity.
Key findings include that LLM personas excessively foreground racial and cultural markers, producing hypervisible yet reductive depictions of minoritized identities. These personas tend to be syntactically elaborate but narratively shallow, relying on stereotypical and exotic tropes. Sentiment analyses reveal a "benevolent bias" where LLM-generated texts are more positively valenced yet mask underlying stereotyping. Overall, the paper formalizes "algorithmic othering" as the phenomenon where marginalized groups are overemphasized as categories, erasing nuance and authentic lived experience. The authors propose design recommendations for narrative-aware evaluation and community-centered validation to mitigate representational harms.
Key findings
- LLM-generated personas disproportionately foreground racial markers, evidenced by TF-IDF terms like 'african', 'heritage', 'resilience' appearing at high weights across all models and prompt settings (Table 2).
- Human-authored self-descriptions emphasize relational and experiential terms such as 'people', 'work', 'life' across racial groups, contrasting with racially coded language in LLM outputs.
- Log-odds ratio analysis of markedness shows statistically significant differences (|δw| > 1.96) in racially salient lexical markers for minoritized groups in LLM personas versus White as default (Table 3).
- Sentiment analysis using VADER and RoBERTa shows LLM-generated personas have consistently higher positive sentiment scores than human-authored ones across all racial groups, especially among Hispanic/Latino and African American/Black groups (Table 4), indicating benevolent bias.
- LLM personas, despite syntactic fluency, rely on formulaic structures and stereotypical themes leading to narratively reductive identity expressions.
- Algorithmic othering manifests through overemphasis on difference via cultural-historical markers and trauma scripting rather than authentic identity narratives.
- Prompting with fuller sociodemographic profiles does not eliminate overreliance on racial identity features in LLM-generated personas.
- Human-authored responses contain richer intersectional nuance and situational detail absent in synthetic personas.
Threat model
The adversary is the large language model acting as a generative agent producing synthetic personas. The models are assumed to have no malicious intent or adversarial directives but can encode and reproduce entrenched sociocultural biases present in training data. The threat involves representational harms manifesting as stereotypical, reductive, or biased identity portrayals, particularly of marginalized racial groups. The adversary cannot access or manipulate the human data and operates solely under prompt-driven text generation.
Methodology — deep read
The study examines how large language models (LLMs) represent identity in synthetic personas compared to humans, focusing on racial representation within the US demographic context.
Threat Model & Assumptions: The adversary is conceptualized as the LLM generating biased synthetic personas given sociodemographic prompts. The evaluation assumes authentic human self-descriptions represent ground truth identity performance. The LLMs have access to demographic inputs but no adversarial instructions; the study explores inadvertent biases.
Data: Human data was collected via an IRB-approved survey of 141 participants recruited on Prolific, stratified to represent diverse US races and genders. Participants answered six open-ended self-description prompts (~500 words each). After filtering for AI-generated text via GPTZero at 0.85 threshold, 126 participants with 756 responses remain. Sociodemographic metadata was collected. LLM-generated data consists of 1,512 synthetic personas (three LLMs × four prompt conditions × six questions each). In total, 9,072 synthetic persona texts were generated.
Architecture/Algorithm: Three public LLMs were prompted: GPT4o, Gemini 1.5 Pro, and DeepSeek 2.5. Prompt design included four conditions varying demographic context: race only, race + age, race + gender + age, and full profile (including occupation, nationality, relationship status). All prompts framed in second person to simulate persona first-person narratives, with temperature set at 1.0 for balancing creativity.
Training Regime: Not reported (models are pre-trained APIs). Data generation occurred in April 2025 through API calls.
Evaluation Protocol: Mixed methods combining qualitative close readings and quantitative analyses:
- TF-IDF lexical analysis stratified by race and source (human vs LLM) identified distinctive/marked terms.
- Log-odds ratio with informative Dirichlet priors calculated statistically significant markedness of words across racial groups relative to White baseline.
- Sentiment analysis was performed with two models: VADER (lexicon-rule based) and RoBERTa (transformer-based) to evaluate polarity differences.
- A parameterized creativity framework measured semantic diversity, novelty, surprisal, and complexity of narratives (details partially truncated).
- Comparison of lexical, narrative, and sentiment features between LLM and human-generated texts across racial subgroups.
- Reproducibility: The exact code release or dataset availability is not mentioned explicitly. The paper states survey instruments and prompt templates are included in Appendix. The human data is privacy sensitive and anonymized. LLMs used are publicly accessible via APIs.
Example illustration: For a prompt "Please describe yourself" with a 50-54 year-old African American woman engineer persona, LLM responses heavily foreground race-related terms like 'resilience', 'Black history', 'gospel music' (Table 1), whereas the human-authored narrative is more holistic focusing on family, volunteering, and health. This exemplifies the pattern of 'algorithmic othering' by LLMs.
In sum, the methodology rigorously compares matched human vs. synthetic persona texts through systematic lexical, sociolinguistic, sentiment, and creativity lenses to identify representational biases at scale.
Technical innovations
- Formalization of 'algorithmic othering' as a novel sociotechnical harm where LLM personas render minoritized identities hypervisible via racial markers but narratively reductive.
- Application of sociolinguistic markedness theory combined with log-odds ratio statistical analysis to quantify representational bias in synthetic versus human persona texts.
- Development of a parameterized creativity framework (semantic diversity, novelty, surprisal, complexity) to characterize narrative expressiveness differences between LLM and human-authored identities.
- Identification and quantification of benevolent bias via sentiment analysis showing positive yet stereotypical portrayals that mask deeper structural harm.
Datasets
- Authentic self-descriptions — 756 narrative texts from 126 diverse U.S. participants — collected via Prolific survey (non-public)
- LLM persona dataset — 1,512 synthetic personas (~9,072 texts) from GPT4o, Gemini 1.5 Pro, DeepSeek 2.5 — generated in study
Baselines vs proposed
- Human-authored personas: TF-IDF lexical distinctiveness features focus on relational/experiential terms, positive sentiment scores average ~0.3 (RoBERTa scale).
- LLM-generated personas: TF-IDF shows racially coded terms with +0.15 to +0.30 higher weights; sentiment scores systematically higher by +0.1 to +0.2 across racial groups.
- Markedness log-odds ratios significant at |δw| > 1.96 in LLM personas for race-related words versus White baseline; human-authored texts show fewer marked lexical signals.
- Prompt variations (Race only to Full profile) did not reduce racial overemphasis in LLM outputs; consistent patterns of algorithmic othering observed.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2505.07850.
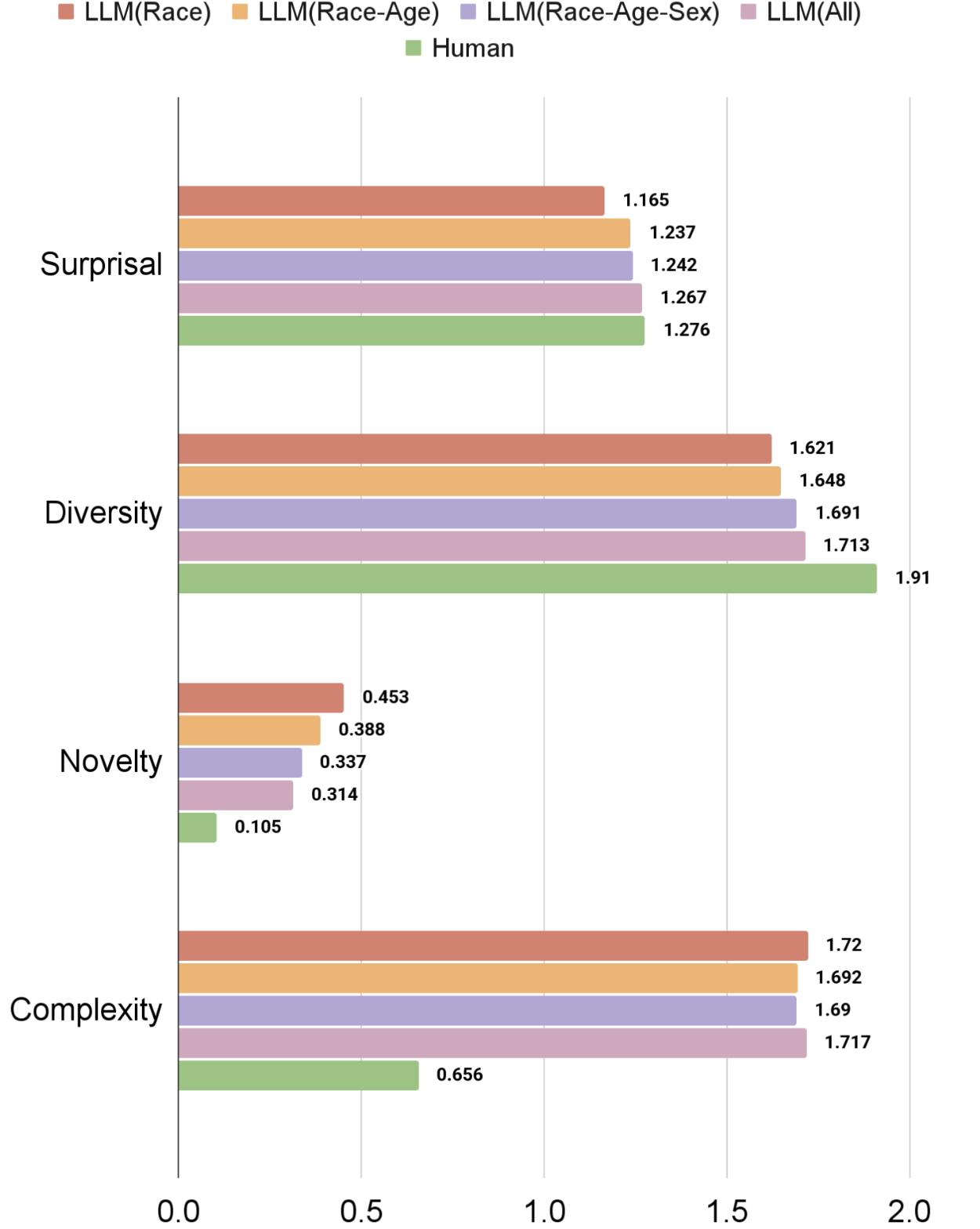
Fig 1: Average creativity scores across all LLM-
Limitations
- Human data was collected within the US demographic and cultural context, limiting generalizability to other regions or languages.
- The study did not conduct adversarial prompt testing or explore model fine-tuning effects on persona generation bias.
- LLM-generated personas were assessed under single-shot prompting without prompt engineering optimizations, which may not reflect best practices to mitigate bias.
- No downstream impact or human subject evaluation of personas’ effects on user perception or decision-making was performed.
- Full creativity framework parametric results and model training details were truncated, limiting analysis of stylistic expressiveness in generated texts.
- Code and data releases are not explicitly noted, impacting reproducibility for external audit.
Open questions / follow-ons
- How can effective prompt engineering or model fine-tuning reduce algorithmic othering in persona generation without sacrificing narrative authenticity?
- What are the impacts of synthetic persona biases on end-user trust and decision-making in sensitive domains like healthcare or social services?
- How can community-centered participatory approaches be systematically incorporated into persona validation workflows?
- Can automated metrics combining sociolinguistic markedness and creativity parameters reliably detect biased synthetic identities in black-box models?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights risks in using LLM-generated synthetic personas as stand-ins for real human identities, especially within security or user verification contexts. The phenomenon of algorithmic othering means synthetic personas may exhibit surface fluency yet carry biased, stereotyped markers that could be exploited or lead to unfair treatment. Understanding lexical and narrative signals of synthetic identity bias can inform development of more robust detection or filtering methods to distinguish authentic user-generated data from AI-generated counterfeits.
Moreover, the study’s mixed-methods evaluation framework—combining sociolinguistic analysis, sentiment quantification, and creativity metrics—can inspire richer feature sets for bot detection systems that go beyond simple token statistics. Practitioners should be wary of over-relying on synthetic personas generated by generic LLM prompts without community vetting. Finally, the findings advocate for incorporating human-aligned narrative validation and demographic-aware evaluation into identity-based defenses to mitigate sociotechnical harms in automated user modeling.
Cite
@article{arxiv2505_07850,
title={ A Tale of Two Identities: An Ethical Audit of Human and AI-Crafted Personas },
author={ Pranav Narayanan Venkit and Jiayi Li and Yingfan Zhou and Sarah Rajtmajer and Shomir Wilson },
journal={arXiv preprint arXiv:2505.07850},
year={ 2025 },
url={https://arxiv.org/abs/2505.07850}
}