
FeatInsight: An Online ML Feature Management System on 4Paradigm Sage-Studio Platform
Source: arXiv:2504.00786 · Published 2025-04-01 · By Xin Tong, Xuanhe Zhou, Bingsheng He, Guoliang Li, Zirui Tang, Wei Zhou et al.
TL;DR
FeatInsight addresses the crucial challenge of managing online ML features across their entire lifecycle in large-scale, dynamic real-world environments. Feature management is often a bottleneck in online ML applications, consuming up to 70% of latency and causing degraded model generalization when features are misconfigured. Existing solutions typically focus on offline or online feature generation in isolation, lacking integrated, user-friendly tooling for feature design, computation, verification, and lineage tracking. FeatInsight unifies these capabilities with a visual interface, a high-performance execution engine (OpenMLDB), and compact data storage techniques to handle trillion-dimensional feature spaces with millisecond-level updates.
The system enhances feature design efficiency via a drag-and-drop SQL visual editor, accelerates feature deployment with unified offline-online executors and consistency verification, and optimizes online feature computation for low-latency, high-throughput scenarios. Demonstrated in over 100 real-world cases on 4Paradigm's Sage Studio platform, FeatInsight significantly reduces feature deployment time by over 60% and achieves sub-20ms response latency with over 1000 QPS in a large-scale online fraud detection use case. The codebase is openly available, facilitating reproducibility.
Key findings
- Feature management latency can constitute up to 70% of total prediction latency in sales prediction service scenarios.
- FeatInsight handles up to a trillion-dimensional feature space, supporting millisecond-level updates in real-time environments.
- In online fraud detection, FeatInsight achieves response times under 20 ms with QPS exceeding 1000, outperforming naive Spark (200 ms) and customized Spark (50 ms) baselines.
- FeatInsight enables designing over 784 online features for fraud detection, including seven-day transaction aggregates and device-related features, improving recall.
- The integrated visual drag-and-drop SQL design reduces feature development-to-deployment time to about five person-days, improving efficiency by over 60%.
- Compact in-memory data storage using lock-free skiplist structures sorted by key and timestamp minimizes contention and supports on-the-fly feature updates.
- Consistency verification between offline and online feature computation eliminates costly manual checks, reducing validation from months to days.
- FeatInsight supports diverse data import formats (CSV, Hive, Parquet, SQL) and automated lineage tracking of feature derivations.
Threat model
Not explicitly a security-focused paper; adversaries are not modeled. The threat context is operational—handling challenges of complex, large-scale, and dynamic data in online ML pipelines while ensuring consistency, low latency, and rapid deployment without system faults or data inconsistency.
Methodology — deep read
Threat model & assumptions: The paper assumes a typical ML deployment scenario where the adversary is not explicitly modeled but the system must handle dynamic data streams, frequent updates, consistency between offline training and online serving, and high-dimensional complex features without degradation in performance or accuracy.
Data: FeatInsight supports heterogeneous large-scale datasets including relational tables, with examples from scenarios like fraud detection having billions of records (e.g., 1.7 billion transactions daily) and hundreds of features (784+ designed features). Data formats supported include CSV, Hive, Parquet, and SQL imports. No specific train/test splits are described, as the system facilitates feature engineering before model training.
Architecture/algorithm: FeatInsight provides a visual SQL-based feature design tool that transforms directed acyclic graphs constructed by drag-and-drop UI blocks into executable SQL statements. These SQLs are compiled into performant C++ machine code with optimizations like parsing optimization, cycle binding, and caching. Feature views group related features by single SQL computations, enabling lineage and versioning management.
The execution engine OpenMLDB powers both offline and online computations with optimizations: offline parallel window operations with dynamic skew mitigation, and online pre-aggregation, dynamic data reordering, and lock-free skiplist data structures sorted by key and timestamp. This supports rapid feature updates, millisecond-level latency, and high throughput. Consistency verification is done by executing test data through both online/offline engines and comparing results.
Training regime: Not applicable—FeatInsight focuses on feature management infrastructure rather than model training.
Evaluation protocol: The system is evaluated in real-world production use cases. Metrics used include feature deployment time (reduced to five person-days, 60% improvement), response latency for online inference (<20 ms vs 50 ms and 200 ms baselines), throughput (>1000 QPS), and recall improvements due to richer feature sets. Comparisons with naive Spark and customized Spark systems establish performance gains. Consistency verification reports eliminate manual validation delays.
Reproducibility: The source code is publicly available at https://github.com/4paradigm/FeatInsight, including the feature design tools and execution backend OpenMLDB. Some datasets stem from proprietary deployments (e.g., Vipshop, Akulaku, Fortune Global 500 bank) and IEEE-CIS Fraud Detection dataset (public). No explicit pretrained weights or model checkpoints are applicable.
Technical innovations
- A unified feature lifecycle management system combining visual SQL-based feature design, storage, computation, verification, and lineage tracking.
- Use of a drag-and-drop graphical SQL builder that compiles feature DAGs into optimized C++ machine code for efficient execution.
- Integration of an optimized online/offline execution engine (OpenMLDB) supporting consistent, parallel, skew-mitigated feature computation.
- Compact in-memory time-series data structures using lock-free skiplists sorted by key and timestamp enabling millisecond-latency online updates.
- Automated offline-online feature consistency verification reducing feature validation time from months to days.
Datasets
- IEEE-CIS Fraud Detection Dataset — large-scale multi-table transactional data — public from Kaggle
- Vipshop Order Records — 720 million daily records — proprietary
- Fortune Global 500 Bank Transaction Data — 1.7 billion daily transactions — proprietary
Baselines vs proposed
- Naive Spark system: response latency ≈ 200 ms vs FeatInsight: < 20 ms
- Customized Spark system: response latency ≈ 50 ms vs FeatInsight: < 20 ms
- Manual feature deployment effort: several months to 1 year vs FeatInsight: 5 person-days (60%+ improvement)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2504.00786.
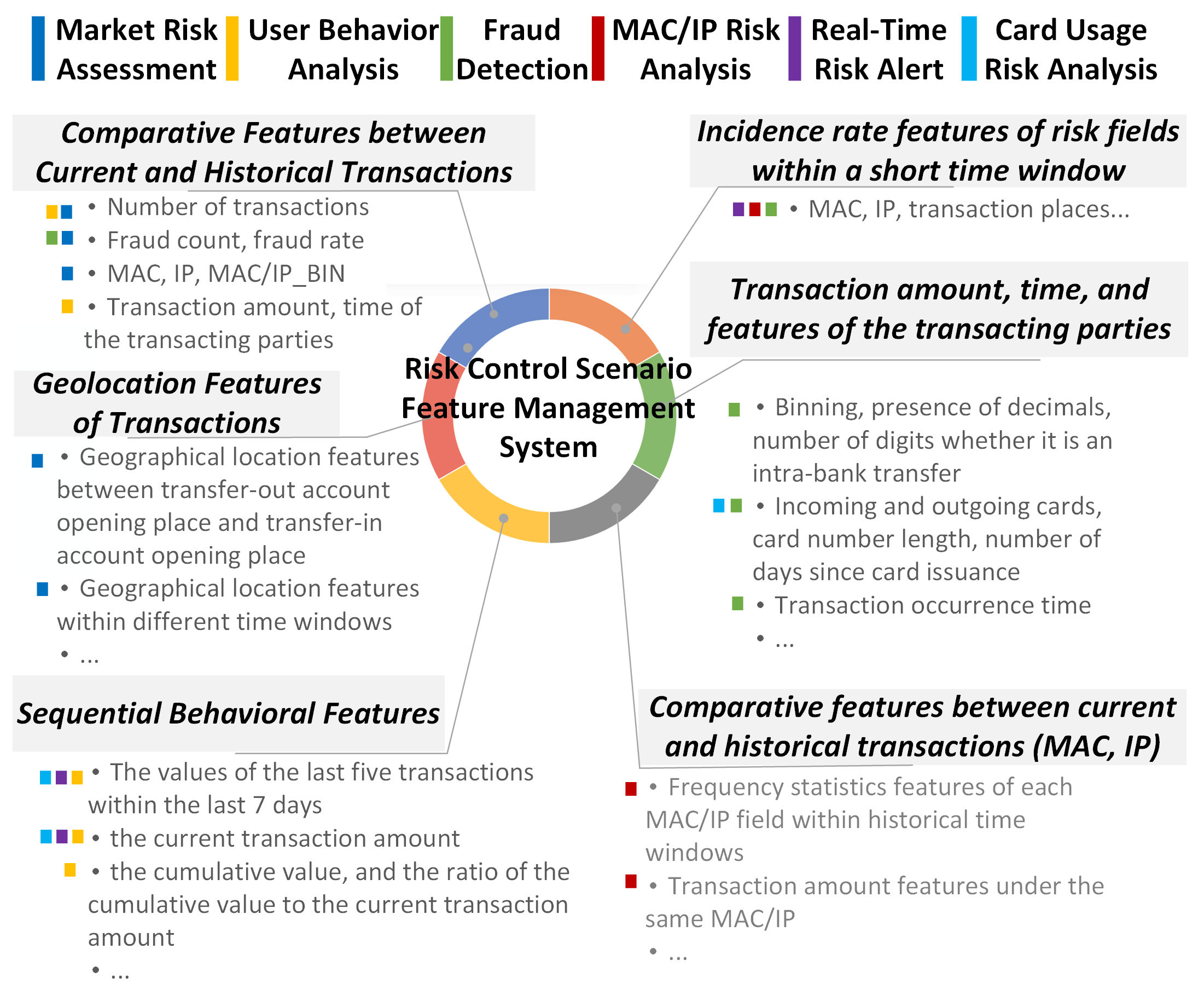
Fig 1: Online ML Features – The complexity of managing
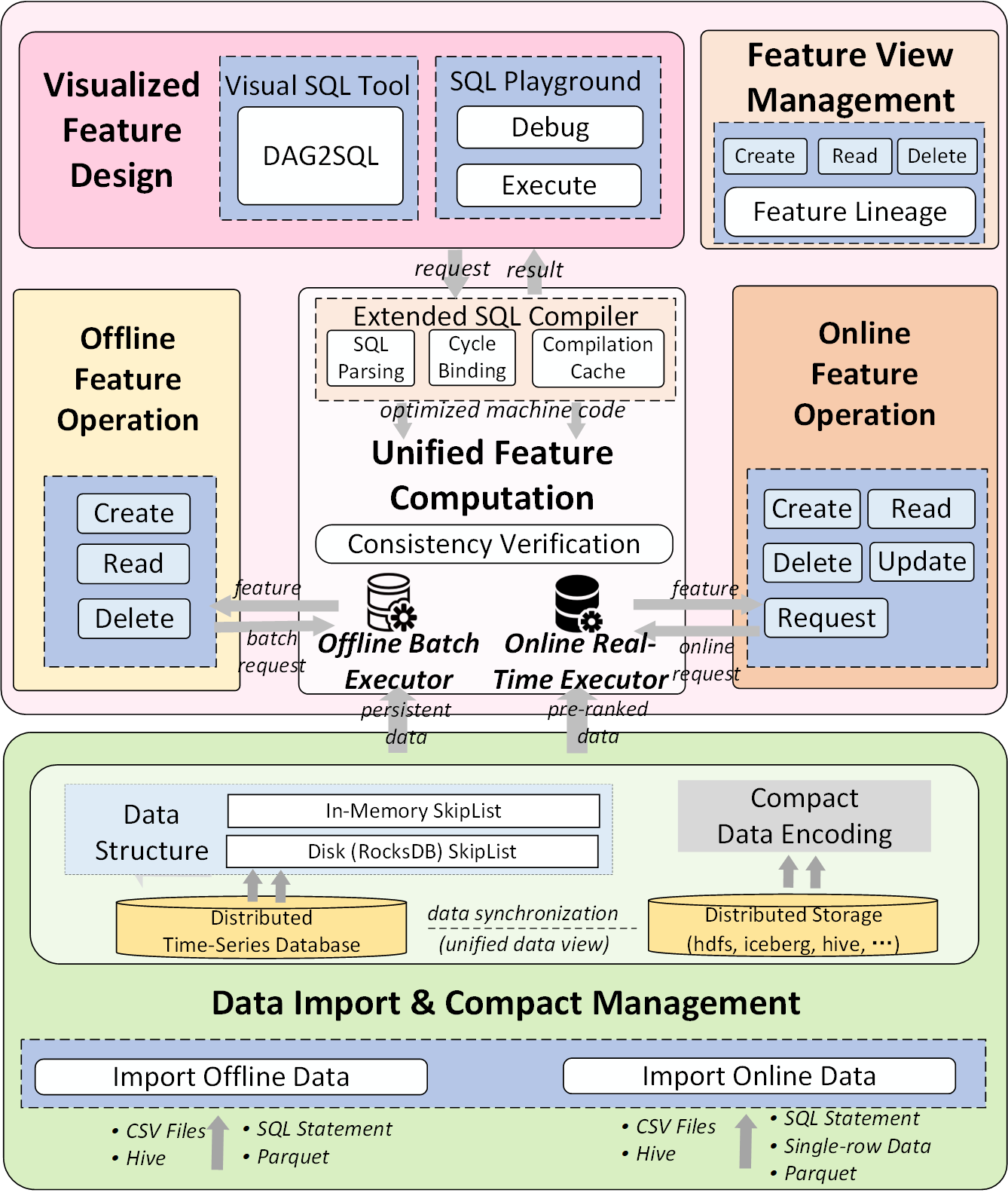
Fig 2: The Architecture of FeatInsight.

Fig 3: A Screenshot and Running Example of FeatInsight.
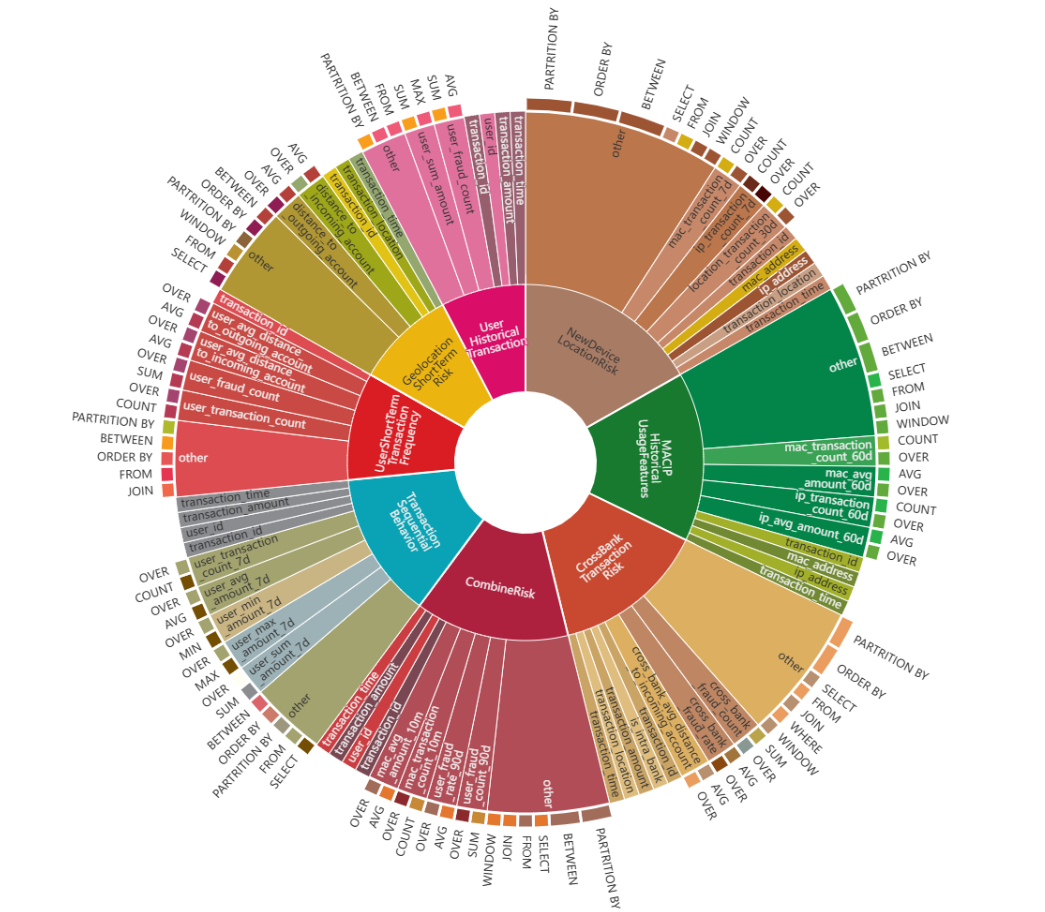
Fig 4: The Distribution of 784 Features (designed within
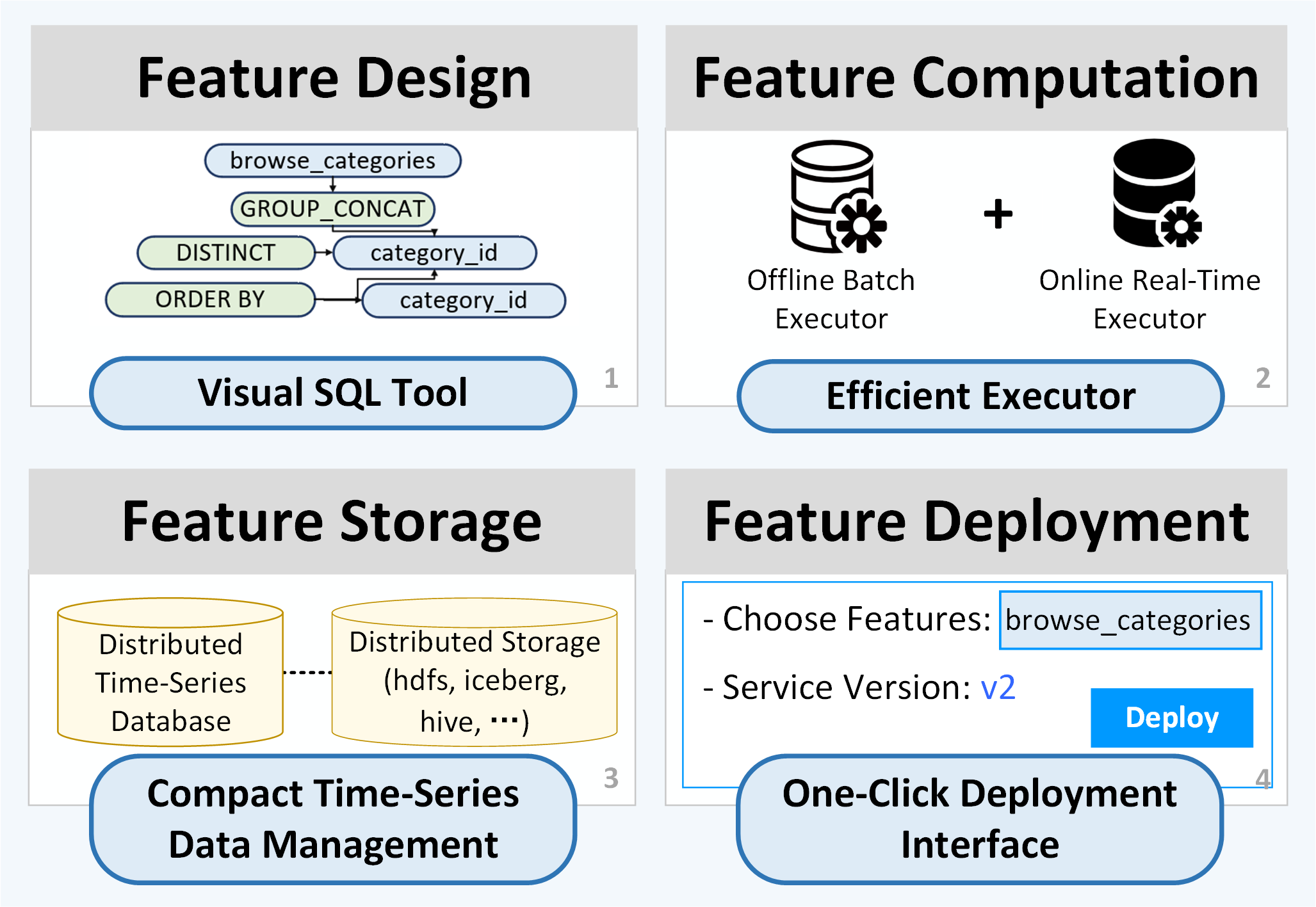
Fig 5: Efficient Feature Deployment by FeatInsight.
Limitations
- No formal adversarial robustness evaluation or attack modeling presented.
- Details of internal optimizations (e.g., SQL compilation, skiplist concurrency) are high-level and lack quantitative ablation.
- No discussion of scalability limits or degradation beyond reported trillion-dimensional feature space.
- Datasets used for evaluation are largely proprietary corporate data, limiting open reproducibility of full performance claims.
- Focus is primarily on feature management infrastructure rather than downstream ML model accuracy or automated feature selection.
Open questions / follow-ons
- How does FeatInsight perform under adversarial manipulation or noisy/corrupted input data for features?
- Can the system automatically assist in feature selection or dimensionality reduction to mitigate curse of dimensionality?
- What are the trade-offs between feature update latency, memory consumption, and throughput at extreme scale?
- How generalizable is the approach to non-relational or semi-structured data for feature ingestion?
Why it matters for bot defense
FeatInsight provides a valuable case study in building scalable, low-latency feature management pipelines essential for online ML applications such as fraud detection, credit risk assessment, and product recommendation. Bot-defense and CAPTCHA practitioners interested in enhancing ML-based detection systems could draw lessons in tightly integrating offline and online pipelines, ensuring feature consistency, and using compact, lock-free data structures to meet strict latency SLAs. Visual feature design and automatic pipeline deployment could streamline production ML workflows, reducing time and human effort.
Given the performance improvements shown in high QPS scenarios with stringent latency requirements, adopting similar feature management patterns could benefit bot detection models where real-time responses and frequent feature updates are necessary to catch evolving attack patterns. However, direct adoption requires adapting to security-specific adversarial threat models and possibly extending to features designed for bot activity signals.
Cite
@article{arxiv2504_00786,
title={ FeatInsight: An Online ML Feature Management System on 4Paradigm Sage-Studio Platform },
author={ Xin Tong and Xuanhe Zhou and Bingsheng He and Guoliang Li and Zirui Tang and Wei Zhou and Fan Wu and Mian Lu and Yuqiang Chen },
journal={arXiv preprint arXiv:2504.00786},
year={ 2025 },
url={https://arxiv.org/abs/2504.00786}
}