
A Review of Several Keystroke Dynamics Methods
Source: arXiv:2502.16177 · Published 2025-02-22 · By Soykat Amin, Cristian Di Iorio
TL;DR
This paper conducts a comparative empirical study of three statistical keystroke dynamics authentication methods—Gaussian Mixture Models (GMM), Mahalanobis Distance, and Gunetti Picardi’s Distance Metrics—on three well-known fixed- and free-text keystroke datasets (Aalto, Buffalo, Nanglae-Bhattarakosol). The authors implement uniform feature extraction focusing on key timing metrics (hold time, up-down time, down-down time) and evaluate authentication performance via standard biometric metrics: False Acceptance Rate (FAR), False Rejection Rate (FRR), Equal Error Rate (EER), and Receiver Operating Characteristic (ROC) curves. Their results show GMM provides the most consistent and lowest EER performance across datasets, with EERs around 0.15, outperforming the Mahalanobis and Gunetti Picardi methods. Notably, the smaller Nanglae-Bhattarakosol dataset yields the best absolute performance for all methods, likely due to simpler intra-user variation.
The study also highlights how dataset properties such as fixed vs free text, session spacing, and dataset size impact performance metrics. For example, Buffalo offers temporally spaced sessions with richer intra-user variation, reducing accuracy. Mahalanobis distance exhibits greater sensitivity to threshold changes, while GMM shows more stable FAR-FRR tradeoffs. Gunetti Picardi's relative and absolute distance measures provide a flexible free-text approach but lag behind GMM in accuracy. Overall, this paper offers a detailed side-by-side comparison of representative classical statistical keystroke authentication methods informed by a diverse set of well-established datasets and consistent experimental protocols.
Key findings
- GMM model achieves EER around 0.15 on all datasets, including 0.156 on Aalto, 0.187 and 0.186 on Buffalo free- and fixed-text, and 0.125 on Nanglae-Bhattarakosol.
- Mahalanobis distance method yields higher EERs approx 0.13 to 0.21, e.g. 0.132 on Aalto, 0.214 on Buffalo free-text, with high sensitivity to threshold changes.
- Gunetti Picardi algorithm focused on Buffalo free-text achieves FAR between 8-13% and FRR between 8-14%, with the best combined R-A measures yielding FAR=8% and FRR=8%.
- Smallest dataset Nanglae-Bhattarakosol shows best absolute performance for all methods, e.g. Mahalanobis EER=0.102, GMM EER=0.125, likely due to reduced intra-subject variability.
- Aalto dataset with largest user count (168,960) but one session per user produces moderately lower performance, probably due to less longitudinal behavior variation.
- Buffalo dataset with fewer users (148) but spaced sessions over 4 months shows higher EERs, capturing temporal variability challenges.
- ROC AUC scores for all methods and datasets are consistently high (~0.86 to 0.96), with Nanglae-Bhattarakosol generally achieving highest AUC (e.g. 0.958 with Mahalanobis).
- ROC curves indicate GMM has a more gradual and controlled decrease in FAR with increasing threshold compared to Mahalanobis which drops steeply.
Threat model
The adversary is an impostor who attempts to authenticate as a genuine user by submitting keystroke timing sequences. The adversary does not have access to internal model information, cannot directly manipulate timing sensors, and can only try to mimic or replay plausible typing timing patterns. The system’s goal is to distinguish genuine users from such impostors based solely on behavioral biometric timing features without auxiliary sensors or active challenge-response.
Methodology — deep read
Threat Model & Assumptions: The adversary is an impostor attempting to impersonate a genuine user by presenting keystroke timing sequences to the authentication system. The attacker does not have control over device keyboard hardware or direct manipulation of timing recordings. The methods rely solely on behavioral biometric input (keystroke timings) with no auxiliary sensor data or challenge-response. Assumes attacker cannot perfectly replicate timing patterns but may attempt similarity-based attacks.
Data: Three datasets were used--Aalto (168,960 users, fixed-text, one session per user typing ~15 sentences), Buffalo (148 users, free- and fixed-text, three sessions spaced over 4 months), and Nanglae-Bhattarakosol (108 users, fixed-text from iPhone touchscreen inputs). The datasets vary across size, text type, and session count to capture different behavioral dynamics and variability. Feature extraction from raw timestamps created hold time (key press duration), up-down time (release to next press) and down-down time (press to next press) used as input features. Each dataset was cleaned to remove invalid or negative timings and converted to CSV format for uniform processing.
Algorithms: The study implements three statistical algorithms - Mahalanobis Distance based classification, Gaussian Mixture Models (GMM), and Gunetti Picardi’s Distance metrics. Mahalanobis uses the inverse covariance-weighted squared distance between user mean feature vector and test samples. GMM fits multiple weighted Gaussian components for each user’s hold time per digraph, capturing multi-modal distributions of typing timings. Gunetti Picardi computes relative disorder (R) and absolute timing difference (A) across n-graphs of keystrokes, combining these measures to produce a similarity score for free-text samples.
Training Regime: For Mahalanobis and GMM, data was split 70% training, 30% testing per user with 5 impostor samples included for negative testing. GMM models per user and per digraph were trained using an existing repository-based implementation with EM to fit Gaussian components, with validation sets used for threshold tuning. Gunetti Picardi profiling involves building user profiles using timing distributions and comparing input sequences against stored profiles using a distance metric.
Evaluation Protocol: FAR, FRR, EER, and ROC curves were computed for genuine and impostor claims across all datasets and methods. ROC plots demonstrate authentication system tradeoffs. The authors emphasize FAR as more critical for security relevance but report full biometric metrics. For Gunetti Picardi, only Buffalo free-text was evaluated given the method’s free-text design. Model comparisons were empirical; no cross-validation or adversarial robustness tests were reported.
Reproducibility: The authors provide open-source code to process datasets, run algorithms, and reproduce performance graphs, enabling verification. Attribution to referenced public dataset sources and software repositories for baseline models supports reproducibility. However, some implementation details such as hyperparameters and random seeds are not exhaustively detailed, and datasets vary in licensing terms. Overall, the pipeline is transparent with uniform feature inputs enabling fair comparison.
Example: For the Mahalanobis implementation on Aalto, per-user mean keystroke timing vectors were computed on 70% of samples. The covariance matrix of training features was pseudo-inverted to weight feature correlations. For a test sample (30% held out plus 5 impostor samples), the Mahalanobis distance from the user mean was computed. Samples below a threshold were accepted as genuine; otherwise rejected. Varying the threshold swept out ROC curves from which EER was derived. This procedure was repeated across all users and averaged for dataset-level metrics.
Technical innovations
- Systematic empirical comparison of Mahalanobis distance, Gaussian Mixture Model, and Gunetti Picardi methods on identical datasets with uniform feature extraction.
- Expanded evaluation of Gunetti Picardi metrics with combined relative (R) and absolute (A) distance measures for free-text keystroke authentication.
- Integration and detailed analysis of multiple large-scale and diverse keystroke datasets (Aalto, Buffalo, Nanglae-Bhattarakosol) under a consistent experimental framework.
- Insightful characterization of statistical distance-based methods on both fixed-text and free-text keystroke dynamics data, highlighting dataset-specific performance impacts.
Datasets
- Aalto 136M — 168,960 users, fixed-text typing 15 English sentences — public
- Buffalo — 148 users, mixed free-text and fixed-text, 3 sessions over 4 months — public
- Nanglae-Bhattarakosol — 108 users, fixed-text from iPhone touchscreen — public
Baselines vs proposed
- Mahalanobis on Aalto: EER = 0.132 vs GMM: EER = 0.156
- Mahalanobis on Buffalo Free-Text: EER = 0.214 vs GMM: EER = 0.187
- Mahalanobis on Buffalo Fixed-Text: EER = 0.213 vs GMM: EER = 0.186
- Mahalanobis on Nanglae-Bhattarakosol: EER = 0.102 vs GMM: EER = 0.125
- Gunetti Picardi on Buffalo Free-Text: best combined measure (R234A23) FAR = 8%, FRR = 8%, higher than GMM EER ~0.187
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2502.16177.
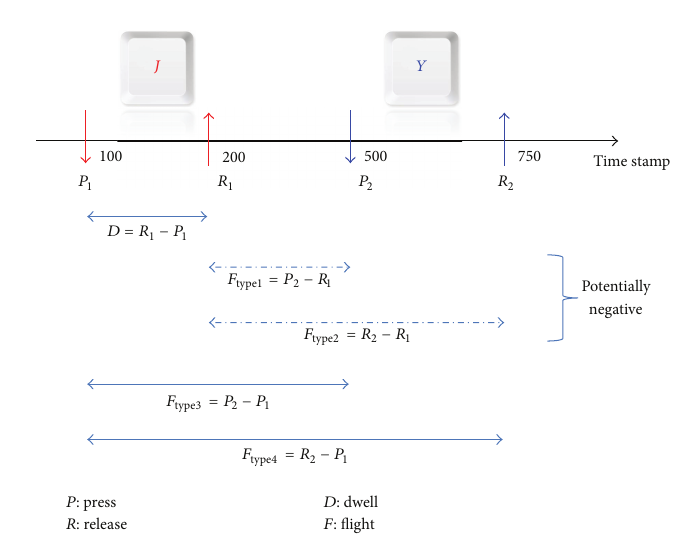
Fig 1: Relevant keystroke events
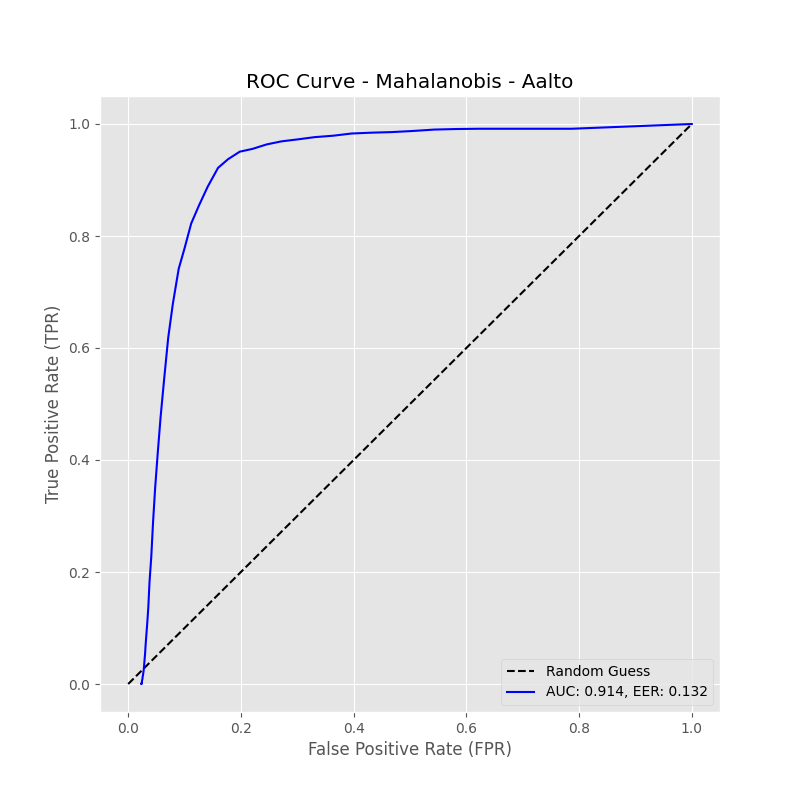
Fig 2: Aalto AUC = 0.914, EER = 0.132
Fig 3: Buffalo Free-Text AUC = 0.867, EER = 0.214
Fig 4: Buffalo Fixed-Text AUC = 0.863, EER = 0.213
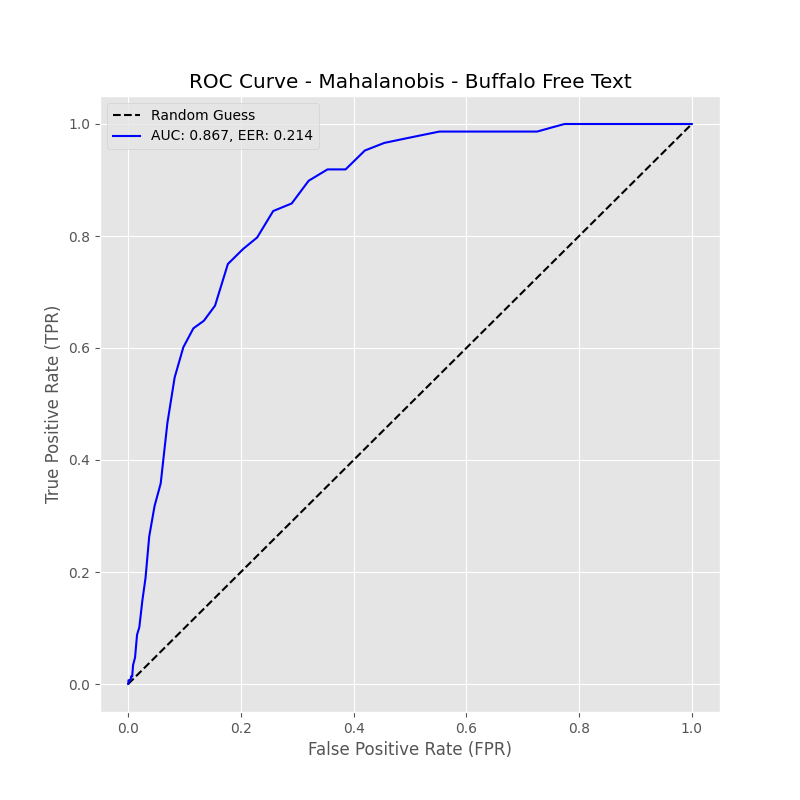
Fig 5: Nanglae-Bhattarakosol AUC = 0.958, EER = 0.102
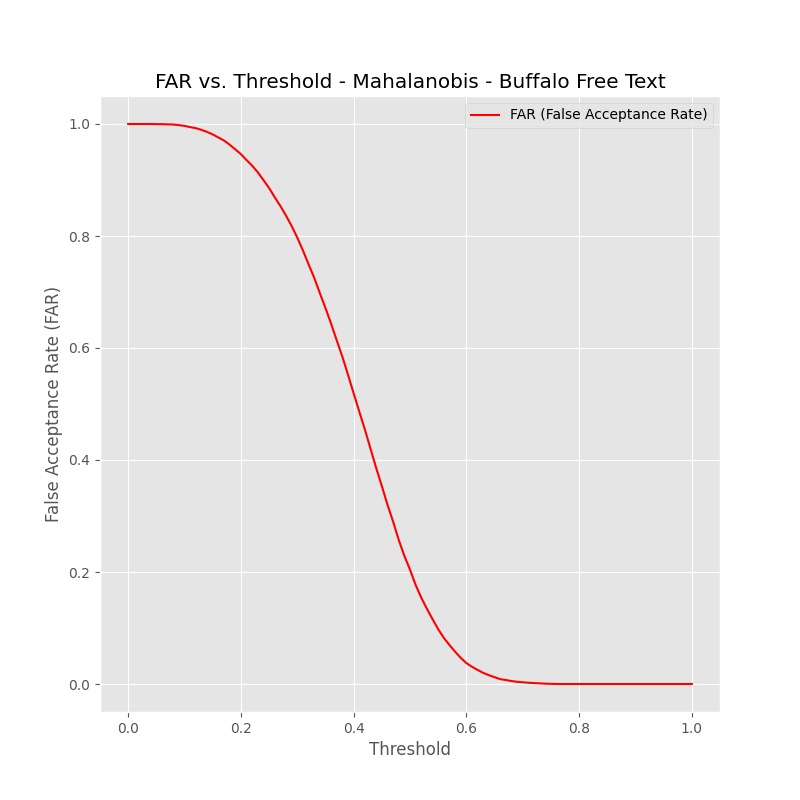
Fig 6 (page 11).
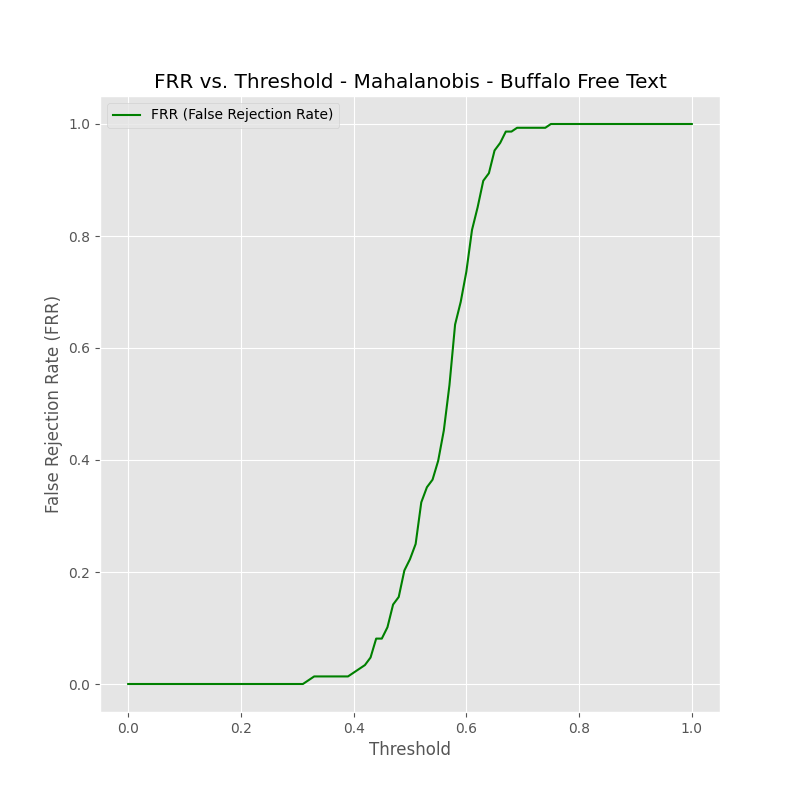
Fig 7 (page 11).
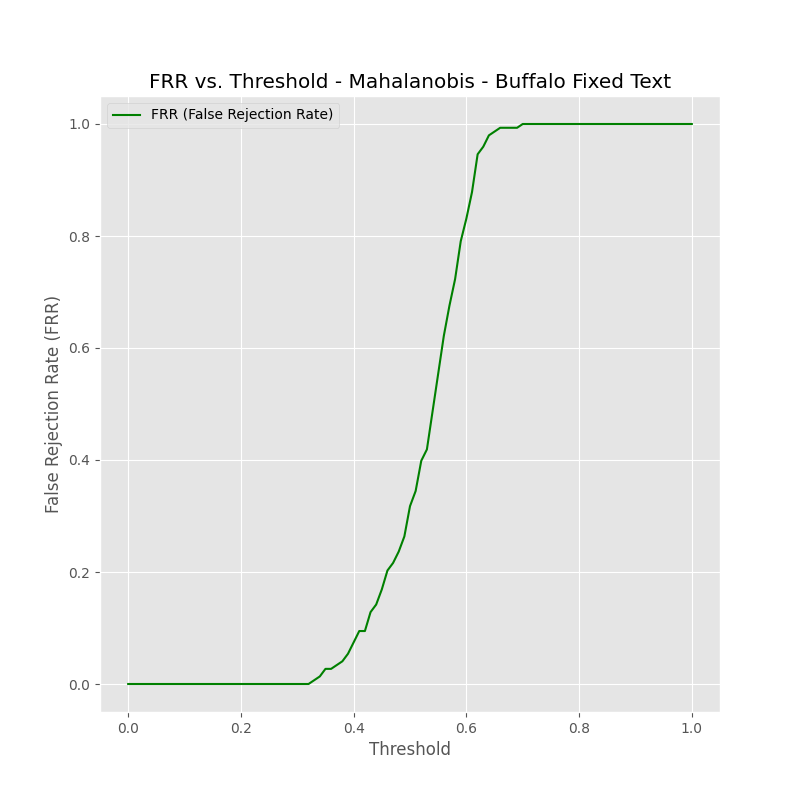
Fig 8 (page 12).
Limitations
- No adversarial attack evaluation or robustness testing to mimic intelligent impostors.
- Absence of cross-validation; results could be sensitive to random train-test splits or user selection.
- Gunetti Picardi method evaluated only on one free-text dataset, limiting generality claims.
- No exploration of hyperparameter sensitivity such as number of Gaussian components in GMM.
- Temporal shifts and long-term variability only partially addressed (Buffalo dataset spaced sessions).
- Deep learning or more advanced machine learning methods were excluded, limiting state-of-the-art comparison.
Open questions / follow-ons
- How do advanced deep learning architectures or hybrid methods compare with the evaluated statistical models on the same datasets?
- Can adversarial training or robustness evaluation improve resilience of keystroke biometrics against mimicry or replay attacks?
- What is the impact of temporal variability beyond the few months considered in Buffalo dataset on long-term model performance?
- How does the authentication performance vary with alternative or additional timing features beyond hold, up-down and down-down times?
Why it matters for bot defense
This work provides bot-defense practitioners with a rigorous benchmark comparing classical keystroke dynamics algorithms on large-scale and varied datasets, highlighting strengths and weaknesses relevant for behavioral bot or fraud detection. The clear demonstration that Gaussian Mixture Models outperform simpler Mahalanobis and graph-based distance measures suggests that probabilistic modeling of multi-modal timing patterns is promising for real-world keystroke authentication. The paper’s emphasis on how dataset characteristics, especially session time gaps and free- vs fixed-text input, affect error rates is critical for designing keystroke-based continuous authentication systems or CAPTCHAs relying on behavioral biometrics. However, practitioners should note the limitations around limited adversarial evaluation and the absence of modern machine learning baselines. These traditional statistical methods remain interpretable and lightweight, relevant for settings requiring low compute overhead and transparency, but future integration with deep learning or adversarially hardened schemes could enhance robustness against sophisticated bots or impostors.
Cite
@article{arxiv2502_16177,
title={ A Review of Several Keystroke Dynamics Methods },
author={ Soykat Amin and Cristian Di Iorio },
journal={arXiv preprint arXiv:2502.16177},
year={ 2025 },
url={https://arxiv.org/abs/2502.16177}
}