
The 23andMe Data Breach: Analyzing Credential Stuffing Attacks, Security Vulnerabilities, and Mitigation Strategies
Source: arXiv:2502.04303 · Published 2025-02-06 · By Ryan Holthouse, Serena Owens, Suman Bhunia
TL;DR
This paper is a descriptive case study of the October 2023 23andMe breach, focused on how a relatively small credential-stuffing event escalated into a much larger exposure because of the platform’s relational features. The core story is not a novel detection algorithm or a new attack primitive; it is the interaction between reused credentials, weak authentication controls, and 23andMe’s DNA Relatives / Family Tree sharing model, which allowed access through roughly 14,000 compromised accounts to fan out into millions of exposed profiles.
The authors frame the incident as a warning about security design in consumer genetic platforms. Their main contribution is synthesizing public reporting, 23andMe’s own statements, and prior research on password hygiene, rate limiting, MFA, and passwordless auth to argue that the breach was preventable or at least materially containable. The reported outcome is that approximately 5.5 million DNA Relatives profiles and 1.4 million Family Tree profiles were exposed, after attackers used credential stuffing against less than 0.1% of 23andMe’s ~14 million customers.
Key findings
- 23andMe said attackers accessed fewer than 0.1% of its customers, about 14,000 accounts, yet that access propagated to approximately 5.5 million DNA Relatives profiles and 1.4 million Family Tree profiles through the platform’s relationship graph.
- The paper states the initial intrusion was credential stuffing using reused usernames/passwords from prior leaks, not exploitation of a novel zero-day or malware payload.
- 23andMe’s login API reportedly lacked rate limiting at the time of the breach, which the authors identify as a key enabler for large-scale automated login attempts.
- After the breach, 23andMe required all users to reset passwords and enabled mandatory email-based two-step verification for all new and existing customers (timing given as Nov. 6 and Dec. 1, 2023 in Fig. 1).
- The paper cites prior work showing a 24-hour lockout after three failed logins can reduce brute-force success on a six-digit PIN to under 1% over ten years (Florêncio et al.), illustrating why even basic throttling matters.
- It cites Heiding et al. reporting Fail2Ban rules reduced SSH login attempts by 99.2%, with average attempts per IP falling from 101.1 to 4.6, as evidence that rate limiting can sharply cut automated abuse.
- The paper cites Li et al.’s 12306 password study: 123456 was the most common password at 0.296% of >300,000 compromised passwords, underscoring why credential stuffing remains effective.
- It notes TechCrunch and 23andMe-confirmed reports that the leaked data included names/display names, sex, birth year, ancestry information, relationship labels, and some geographic/family details, but not raw genetic sequence data.
Threat model
The adversary is a credential-stuffing attacker with access to previously leaked username/password pairs and the ability to automate login attempts against 23andMe’s web/API endpoints. They can exploit weak password reuse and any missing controls such as rate limiting, and they can use a valid account to access connected DNA Relatives and Family Tree data. The paper assumes they do not have 23andMe’s internal credentials, do not need a zero-day exploit, and do not necessarily obtain raw genetic data; their power comes from account takeover and feature amplification.
Methodology — deep read
The paper’s threat model is straightforward: a cybercriminal actor (“Golem”) with access to credentials stolen in prior breaches attempts automated logins against 23andMe. The adversary is assumed to have large credential lists, scriptable infrastructure, and the ability to probe the login API at scale. They do not need to know anything about the victim’s genetics; they only need reused credentials and enough time to test them. The authors also assume 23andMe’s social-graph-like product features are security-relevant because a single valid account can reveal data about many linked profiles. This is not a formal adversarial model with quantified attacker budgets; it is a public-incident reconstruction.
Data provenance is entirely secondary/public-source based. The paper does not introduce a new dataset or a lab-built benchmark. Instead, it compiles facts from 23andMe’s incident disclosures, TechCrunch reporting, BreachForums/Hydra forum descriptions, and prior academic work on brute force, password reuse, and credential stuffing. The main numerical anchors are public estimates: ~14,000 compromised accounts, ~14 million total customers, ~5.5 million DNA Relatives profiles exposed, and ~1.4 million Family Tree profiles exposed. The paper also references a 12306 compromised-password dataset (>300,000 passwords) and prior studies on password-alert systems and rate limiting. Because the sources are heterogeneous and largely observational, the paper does not describe train/test splits, preprocessing, or labeling in the machine-learning sense.
The “architecture” under analysis is the authentication and data-sharing design of 23andMe, not a learned model. The authors explain credential stuffing as the attack primitive: attackers automate login attempts with previously leaked username/password pairs, then pivot from any successful account into the DNA Relatives and Family Tree features. The novel mechanism is the amplification effect of those features. In practical terms, if an attacker logs into one account, the platform may reveal display names, relationship labels, shared-DNA estimates, ancestry reports, family names, profile photos, and optional locations for connected profiles. That means the security boundary is not just the account; it is the connected relationship graph. The paper describes this qualitatively with Fig. 3 and Fig. 4 screenshots of sample profile views, but it does not provide a technical reverse-engineering of 23andMe’s backend.
The “training regime” section is mostly absent because there is no original model training. Where the authors discuss mitigation, they summarize external research rather than evaluating their own implementation. Rate limiting is discussed through the lens of prior experiments (for example, Fail2Ban reducing SSH attacks by 99.2% in Heiding et al.). Password policy is discussed via Shay et al.’s 3class12 standard (12+ characters and three character classes). Password breach notification is discussed via Thomas et al., where 26% of alerted users changed passwords. MFA and passwordless authentication are presented as standard defensive controls, not as newly benchmarked systems. No epoch counts, batch sizes, optimizer settings, seed strategy, or hardware details are given because the paper does not train or test a system.
Evaluation is narrative and comparative rather than experimental. The authors contrast the 23andMe incident with other credential-stuffing and credential-exposure cases such as Canva, COMB, LinkedIn scraping, Parler, and other breach events cited in the references. Their key evaluation criterion is whether a proposed defense would have reduced the blast radius of the breach: rate limiting would have slowed automated login, MFA would have raised the cost of account takeover, passwordless auth would have removed password reuse as an attack surface, and breach-alert systems could have prompted more users to reset reused passwords. There are no statistical tests, no ablation study, and no held-out attacker simulation. The paper’s evidence chain depends on public incident reporting and prior literature, not controlled experiments on 23andMe’s systems.
For reproducibility, this is a closed-source, open-web reconstruction. The paper is reproducible only to the extent that the cited public sources remain accessible: 23andMe’s incident page, forum screenshots/posts, and prior papers. There is no released code, no dataset, and no frozen artifact from the authors. A concrete end-to-end example the paper implies is: an attacker uses a reused credential pair from a prior breach to log into one 23andMe account; because rate limiting is absent, they can test many pairs quickly; once inside, they enumerate DNA Relatives-linked profiles and associated metadata; the attacker then harvests display names, ancestry-related fields, relationship labels, and optional profile details from connected users, increasing the compromised set far beyond the initially logged-in accounts.
Technical innovations
- No new algorithm is introduced; the paper’s contribution is a case-study synthesis of how credential stuffing plus relationship-graph exposure amplified a breach from ~14,000 accounts to millions of profiles.
- It reframes 23andMe’s DNA Relatives and Family Tree features as a blast-radius multiplier, not merely a privacy feature, and uses that lens to explain why account-takeover defenses must protect downstream social-graph exposure.
- It organizes mitigation guidance into a concrete defense stack: rate limiting, stronger password policy, breach-notification services, MFA/two-step verification, and passwordless authentication.
- It connects public incident reporting with prior rate-limiting and password research to argue that even basic controls would have materially constrained automated abuse.
Datasets
- No original dataset — case study built from public incident reports, forum postings, and cited prior literature.
- 12306 password dataset — >300,000 compromised passwords — public dataset cited from Li et al. (used only as background evidence).
Baselines vs proposed
- Florêncio et al. brute-force baseline: 24-hour lockout after 3 failed attempts reduced six-digit PIN brute-force success to <1% over 10 years vs proposed: cited as support for rate limiting.
- Heiding et al. honeypot SSH baseline: 101.1 attacks/IP vs with Fail2Ban: 4.6 attacks/IP (99.2% reduction).
- Thomas et al. breach-alert baseline: no alerting vs alerted users: 26% changed passwords after notification.
- 23andMe incident response baseline: password-only access vs mandatory email two-step verification and password reset; the paper reports the policy change but no before/after security metric.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2502.04303.
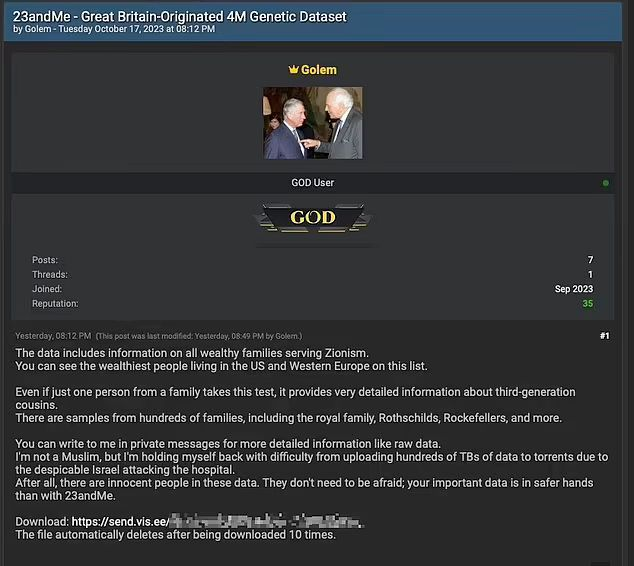
Fig 2: displays Golem’s post on BreachForums,
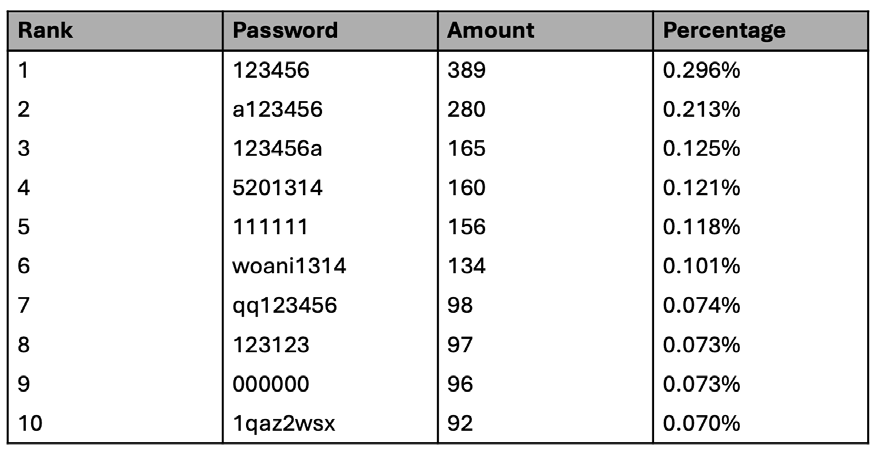
Fig 3: In application view of a sample profile for a
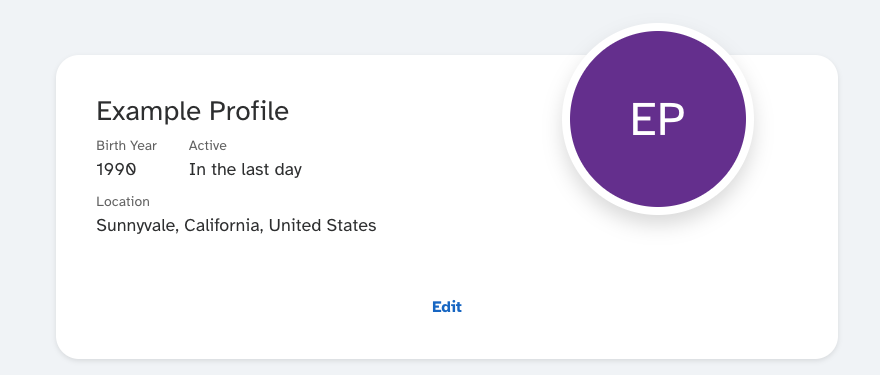
Fig 4: Another sample GUI element, showing some of
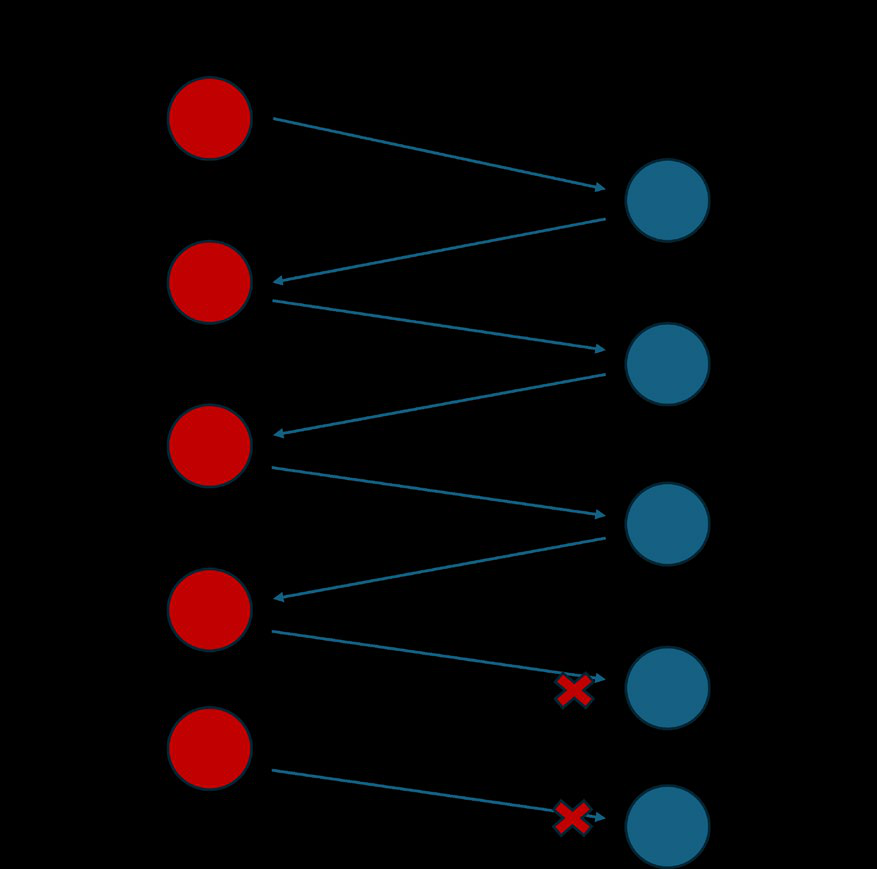
Fig 5: A basic example of rate limiting and how it
Fig 5 (page 6).
Limitations
- The paper is not an empirical security evaluation; it does not test the proposed defenses on 23andMe-like infrastructure.
- It relies heavily on public reporting and company statements, so several details are secondhand and some attacker claims remain unverified.
- No adversarial simulation, no attack-volume measurement, and no quantification of how much each defense would reduce the real breach were presented.
- Demographic claims about who was affected (for example, Jewish Ashkenazi or Chinese users) are discussed from reports, but the paper does not validate the distribution independently.
- The paper does not analyze the UX/security tradeoff of mandatory MFA or recovery failures in depth beyond brief mention.
- There is no formal threat-intelligence or forensic analysis of the attacker’s tooling, infrastructure, or credential source corpus.
Open questions / follow-ons
- How much would per-account and per-IP rate limiting, bot detection, and credential-stuffing detection have reduced the real incident’s blast radius if deployed before October 2023?
- Would relationship-graph minimization, finer-grained consent, or privacy-preserving default settings for DNA Relatives have prevented the multi-million-profile exposure even after some account takeovers?
- How should genetic-data platforms measure and limit downstream exposure from one compromised account when features are inherently networked?
- What recovery and friction design for MFA/paswordless auth best balances account security with accessibility for a consumer health platform?
Why it matters for bot defense
For bot-defense practitioners, this case is a reminder that account takeover risk is not just about the login form. A seemingly ordinary credential-stuffing campaign can become a high-impact breach when the product exposes linked data through social or familial graphs. CAPTCHA, rate limiting, device reputation, and anomaly detection would have served as front-line friction here, but the more important lesson is architectural: if successful login reveals data about many other users, then the downstream data model determines the blast radius.
A bot-defense team would read this as an argument for layered controls. Challenge systems can reduce automated login volume, but they are not sufficient if reused credentials still succeed at scale or if the application exposes rich relationship data after a single auth event. The paper also supports defending against the whole account lifecycle: breach monitoring, password-reuse detection, MFA enrollment, and tighter authorization on graph traversal are all relevant, especially for platforms with sensitive or immutable personal data.
Cite
@article{arxiv2502_04303,
title={ The 23andMe Data Breach: Analyzing Credential Stuffing Attacks, Security Vulnerabilities, and Mitigation Strategies },
author={ Ryan Holthouse and Serena Owens and Suman Bhunia },
journal={arXiv preprint arXiv:2502.04303},
year={ 2025 },
url={https://arxiv.org/abs/2502.04303}
}