
Beyond the Crawl: Unmasking Browser Fingerprinting in Real User Interactions
Source: arXiv:2502.01608 · Published 2025-02-03 · By Meenatchi Sundaram Muthu Selva Annamalai, Igor Bilogrevic, Emiliano De Cristofaro
TL;DR
This paper addresses a critical gap in the measurement and detection of browser fingerprinting, an invasive tracking technique used for profiling users online. Prior studies have predominantly relied on automated web crawlers to identify fingerprinting scripts; however, these crawlers fail to replicate nuanced user interactions such as login, CAPTCHA solving, cookie consent, or evading bot detection. To overcome this limitation, the authors conduct a 10-week real-user study involving 30 participants browsing a curated list of 3,000 top-ranked websites under realistic conditions using a Chrome extension that collects script execution telemetry. Comparing this dataset with an automated crawl of identical pages, the authors demonstrate that nearly 45% of fingerprinting websites encountered by real users are missed by the automated crawler. This discrepancy stems mainly from the crawler's inability to access authentication-protected pages, bypass bot defenses, and trigger fingerprinting scripts guarded behind interaction events.
Moreover, the study identifies previously unknown fingerprinting vectors observable only in real user data. Leveraging this dataset, the authors evaluate a federated learning approach to collaboratively train detection models on real user telemetry while preserving privacy. Models trained in this manner achieve an Area Under the Precision-Recall Curve (AUPRC) of 0.98 at privacy parameter ε=5, outperforming models trained solely on automated crawl data (AUPRC 0.96). This work highlights the limitations of automated data collection for understanding fingerprinting prevalence and suggests a path forward through privacy-preserving distributed learning based on real user interactions.
Key findings
- Real user browsing sessions collected 695 fingerprinting scripts, 1.40x more than the 498 scripts detected by the automated crawl on the same 14,895 URLs.
- Automated crawlers missed 211 out of 471 fingerprinting websites (45%) detected by real user sessions.
- Missed fingerprinting sites were mostly due to: 15 sites with failed visits (bot detection blocking), 15 sites fingerprinting on authentication pages, 46 sites on inner content pages, and 135 sites on homepages requiring user interaction (e.g., cookie consent or bot detection bypass).
- Canvas fingerprinting was the most prevalent form in both datasets, followed by Audio, WebRTC, and Canvas Font fingerprinting.
- Real user data revealed potential new fingerprinting vectors absent in automated crawls, though details are not fully enumerated.
- Federated learning models trained on real user data achieved an AUPRC of 0.98 at ε=5 differential privacy, outperforming models trained on automated crawl data (0.96 AUPRC).
- Bug in real user data collection extension prevented iframe instrumentation, potentially underestimating fingerprinting in the user dataset but actual impact deemed minimal.
Threat model
The adversary is a website operator or third-party tracker deploying browser fingerprinting scripts that require dynamic user interactions (e.g., logging in, accepting cookies) to trigger. The adversary's goal is to uniquely identify and track users across visits, assuming the ability to run sophisticated JavaScript and bot detection mechanisms. The adversary cannot directly access the users' raw browsing data or encrypted federated model updates. The study excludes adversaries actively attempting to evade detection models or break privacy protections embedded in federated learning.
Methodology — deep read
The research aims to quantify discrepancies in browser fingerprinting detection between real user browsing and automated crawls, and to evaluate ML detection models trained on these data sources under privacy constraints.
Threat Model & Assumptions: The adversary in this context is the browser fingerprinting vendor embedding scripts on websites that attempt to uniquely identify users based on client-side information. The study assumes fingerprinting triggers often require specific user interactions or navigation beyond main pages, capabilities lacking in automated crawlers. The participant browsing behavior is assumed representative enough to activate user interaction-dependent fingerprinting vectors, though natural browsing is curtailed by assigning predefined site lists.
Data: 30 participants recruited via Amazon Mechanical Turk used Chrome with a custom extension to visit up to 100 assigned websites each (total 3,000 distinct sites sampled from the Chrome User Experience Report top 5,000). The data collection spanned 10 weeks (June-August 2024). To limit privacy risks, participants visited assigned sites only, with instructions to explore at least 10 sub-pages including login, cookie acceptance, and CAPTCHA solving. The extension collected dynamic telemetry of JavaScript API calls and features extracted from script execution traces, excluding raw argument/return values for privacy. Across users, 14,895 unique URLs were visited, averaging 506 URLs per user. Data collection excluded sensitive website categories (e.g., adult, gambling) via Cloudflare API filtering.
Architecture / Algorithm: Fingerprinting detection is based on a high-precision heuristic from prior work (Englehardt and Narayanan 2016; Iqbal et al. 2020) identifying four key fingerprinting categories — Canvas, Canvas Font, AudioContext, WebRTC — by monitoring specific JavaScript API usage patterns. This heuristic serves as ground truth labeling for scripts. For ML, they apply the federated learning system FP-Fed with central differential privacy (parameter ε=5), aggregating model updates from multiple participants without sharing raw data.
Training Regime: ML models are trained collaboratively in rounds using federated averaging on participants’ local telemetry data extracts. Training details such as batch size, epochs, optimizer specifics are not fully detailed but align with the FP-Fed prior work. The privacy budget (ε) balances model utility and privacy protection.
Evaluation Protocol: The main evaluation metrics are the number of fingerprinting scripts and websites detected, and the Area Under the Precision-Recall Curve (AUPRC) for ML detection models. Comparisons are performed between data collected from real user sessions versus an automated crawl of identical URLs using a Puppeteer-based Chrome crawler with mimicry of scrolling and stealth plugins but excluding cookie acceptance. Differences in coverage are analyzed by website page type to identify missed fingerprinting triggers (login pages, content pages, homepages). A manual investigation of a sample of false negatives further characterizes missing scripts. The effectiveness of federated models is compared directly against non-private models trained on crawl data. No mention of cross-validation or adversarial robustness testing is provided.
Reproducibility: The automated crawler code is publicly available on GitHub. The real user telemetry dataset is private due to privacy concerns and ethical constraints. Model training frameworks follow prior published FP-Fed implementations. Limitations include a discovered Chrome extension bug that blocked iframe instrumentation, potentially causing mild underreporting in the real user data. While the sample size of 30 users is modest, the large coverage of URLs and controlled website list bolster the validity of findings within this scope.
Example Walkthrough: A participant with the extension visits a subset of the assigned websites, interacts with login pages, accepts cookie banners, and solves CAPTCHAs as instructed. The extension instruments JavaScript execution and extracts counts of API calls related to Canvas, WebRTC, Audio, etc. These processed features are sent to the server for fingerprinting script labeling via heuristics. This data is used locally to train a federated detection model update, which is then aggregated centrally with noise added to ensure differential privacy. The trained global model thus reflects real user behavioral fingerprinting triggers not captured by automated crawl, achieving superior detection performance.
Technical innovations
- Empirical demonstration that automated crawlers miss 45% of fingerprinting websites encountered by real user browsing sessions due to interaction-dependent triggers.
- Discovery of new browser fingerprinting vectors uniquely identified in real user telemetry but absent from automated crawl-based datasets.
- Adaptation and deployment of a Chrome extension to instrument real user browser API calls and extract privacy-preserving dynamic features at scale.
- Evaluation of a differentially private federated learning system (FP-Fed) trained on real user browsing data, achieving improved detection AUPRC (0.98) compared to models trained solely on automated crawl data (0.96).
Datasets
- Real User Browsing Dataset — 14,895 unique URLs visited over 10 weeks by 30 participants — collected via Chrome extension under IRB approval (private due to privacy)
- Automated Crawl Dataset — 14,895 URLs crawled using Puppeteer with stealth plugins and simulated interaction — code public at https://github.com/spalabucr/beyond-the-crawl
Baselines vs proposed
- Automated Crawl ML Model: AUPRC = 0.96 vs Federated Learning on Real User Data: AUPRC = 0.98 at ε=5 privacy budget
- Fingerprinting Scripts Detected: Automated crawl = 498 vs Real User Data = 695
- Fingerprinting Websites Detected: Automated crawl = 260 (471 - 211 missed) vs Real User Data = 471
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2502.01608.
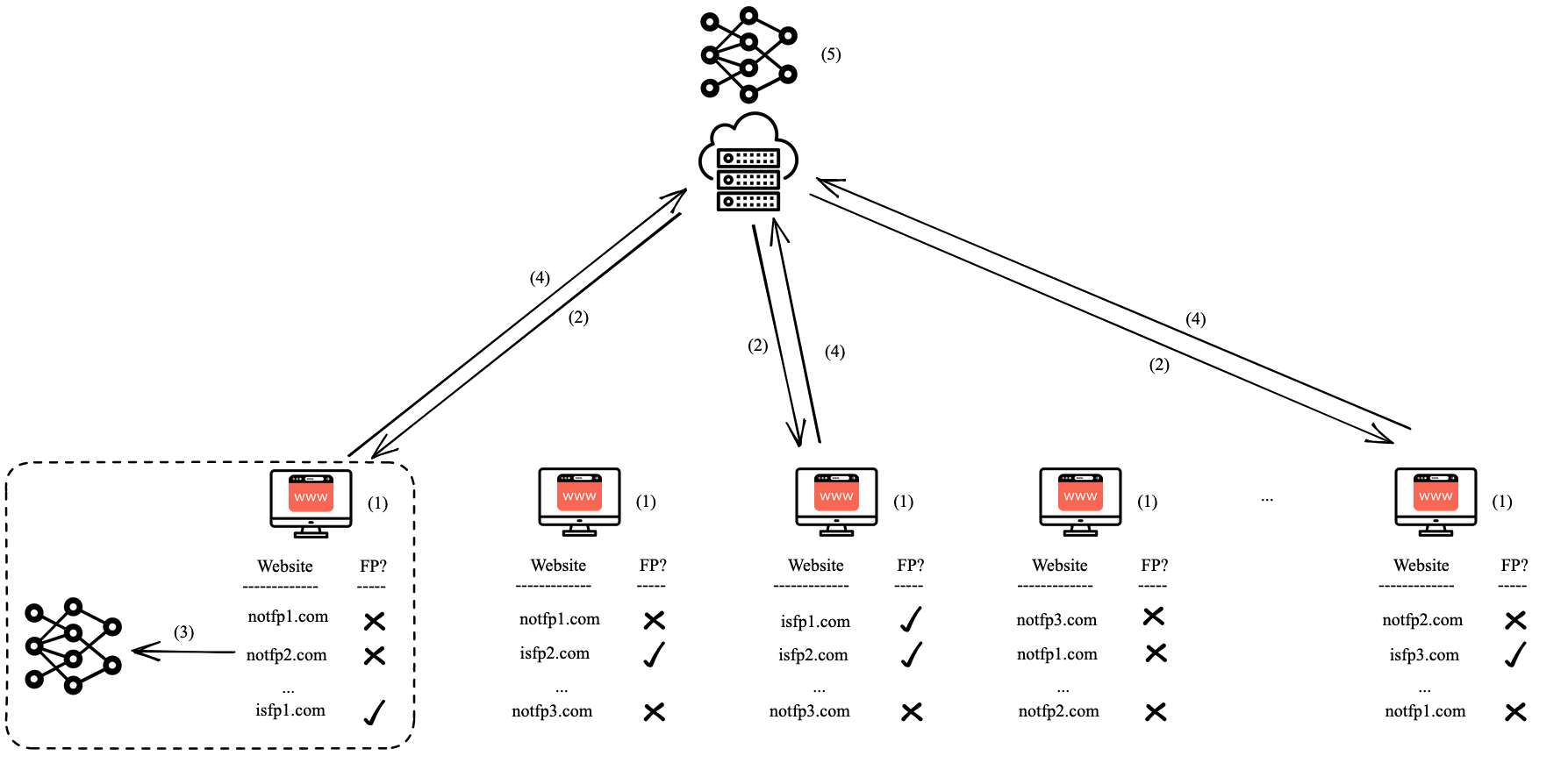
Fig 4: An overview of FP-Fed [8]: (1) Participants browse websites and collect script execution data. (2) For each round
Limitations
- Small participant sample size (30 users) limits generalizability and natural browsing diversity compared to uncontrolled real-world behavior.
- Study constrained to a predetermined list of 3,000 websites, excluding sensitive categories and potentially missing analysis on less popular or niche sites.
- Chrome extension bug prevented injection of instrumentation into iframes, likely underestimating fingerprinting detection in real user data.
- Automated crawler simulated limited interactions but did not accept cookie banners, which may affect direct comparisons.
- No adversarial evaluation against adaptive fingerprinting scripts or bot-detection evasion techniques.
- No reported validation under distribution shifts such as different browser versions, devices, or geographic locations.
Open questions / follow-ons
- What additional new fingerprinting vectors remain undiscovered even with real user telemetry, especially on mobile and emerging web APIs?
- How robust are federated learning detection models under adversarial adaptation and obfuscation by fingerprinting scripts?
- Can deployment of real-user federated fingerprinting detection scale efficiently on a global level with heterogeneous browsing behaviors and privacy constraints?
- How do different privacy parameters (ε) in federated learning impact utility-privacy tradeoffs in browser fingerprinting detection across diverse populations?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work critically highlights the limitations of relying solely on automated crawlers to detect browser fingerprinting scripts. Automated approaches systematically miss almost half of fingerprinting vectors because many require real user interactions such as login, CAPTCHA solving, or cookie acceptance to trigger. This means bot detection mechanisms that rely on blacklist signatures or ML models trained on crawl-based datasets may have significant blind spots.
Leveraging real user telemetry through privacy-preserving federated learning can improve fingerprinting detection robustness and coverage, potentially integrating better with CAPTCHA challenges to identify suspicious scripted behavior. Deploying such models can also help dynamically adapt to new fingerprinting methods activated by nuanced user interaction patterns. Overall, this research suggests a path forward towards stronger fingerprinting detection mechanisms that complement traditional bot defense techniques by incorporating real-world interaction signals under privacy constraints.
Cite
@article{arxiv2502_01608,
title={ Beyond the Crawl: Unmasking Browser Fingerprinting in Real User Interactions },
author={ Meenatchi Sundaram Muthu Selva Annamalai and Igor Bilogrevic and Emiliano De Cristofaro },
journal={arXiv preprint arXiv:2502.01608},
year={ 2025 },
url={https://arxiv.org/abs/2502.01608}
}