
More Efficient Sybil Detection Mechanisms Leveraging Resistance of Users to Attack Requests
Source: arXiv:2501.16624 · Published 2025-01-28 · By Ali Safarpoor Dehkordi, Ahad N. Zehmakan
TL;DR
This paper tackles sybil detection from a graph-algorithms angle rather than as a pure machine-learning classification task. The central new idea is user resistance to attack requests: some benign users reject friendship/follow requests from sybils, while others accept them. The authors argue that this resistance directly shapes the observed sybil-to-benign edge set, so treating it as an explicit signal lets you synthesize more realistic graphs and design preprocessing that improves downstream sybil detection.
The paper contributes two main things. First, it defines a synthetic graph generation framework with three attack strategies (random, preferential attachment, and BFS-based) that interact with resistance probabilities. Second, it studies two preprocessing problems: selecting a limited budget of users whose resistance should be revealed to maximize newly discovered benigns, and selecting users to maximize discovery of potential attack edges. The key result is that the benign-discovery problem is hard to approximate beyond the classic 1 - 1/e threshold, while the exact expectation is #P-hard to compute; nevertheless, the authors propose a Monte Carlo greedy method and a lightweight traversing heuristic. In experiments, these preprocessing steps reportedly improve SybilSCAR, SybilWalk, and SybilMetric on the authors’ synthetic graphs, but the truncated excerpt does not provide the exact numeric gains.
Key findings
- The Maximizing Benigns problem is shown to have no polynomial-time (1 - 1/e)-approximation unless NP ⊆ DTIME(n^{O(log log n)}), via reduction from Maximum Coverage (Theorem 3.2).
- Computing the expected number of newly discovered benigns f(A) is #P-hard (Theorem 3.3), via a reduction from a-b Connectedness for Induced Subgraphs.
- The Monte Carlo greedy algorithm estimates f(A) by repeated resistance sampling; the paper sets the number of simulations to R ≥ k^2 Δ_in^2 ln(1/(1-α)) / (2ε^2) for error ε and confidence α.
- The traversal-based benign-discovery heuristic runs in O((n+m)+k·(n+Δ_in·Δ_out)), which the authors further upper-bound by O(k n^2).
- For Potential Attack Edge discovery, the paper claims the optimal reveal set is simply the k benign nodes maximizing (1 - p_r(v)) · |Γ_in(v) \ (B ∩ S)|, yielding a linear-time top-k selection.
- The paper evaluates three attack strategies for synthetic graph generation: random requests, modified preferential attachment, and BFS-based targeting of a sybil’s dual neighborhood.
- The authors report that resistance-based preprocessing improves the accuracy of SybilSCAR, SybilWalk, and SybilMetric on multiple real-world social networks embedded in the synthetic framework, but the excerpt does not include exact metric values or datasets in the results section.
Threat model
The adversary is a sybil attacker operating in a social network graph. They can create many fake accounts, connect sybils to each other, and send friendship/follow requests to benign users using different strategies (random targeting, preferential attachment toward vulnerable users, or BFS-like neighborhood expansion from sybil duals). The defender can query the resistance of only a budget k users and has probabilistic estimates p_r(v) of resistance, but does not know the true resistance labels globally. The attacker cannot directly control the defender’s resistance estimates or the network’s full structural constraints, but may partially adapt request behavior to mimic benign patterns.
Methodology — deep read
The threat model is a graph-structure adversary in a social network. The attacker creates sybil accounts, connects sybils to each other to look benign, and then attempts to form sybil-to-benign edges by sending friendship/follow requests. The key modeling assumption is that benign users differ in whether they accept such requests: a user is either resistant (rejects all sybil requests) or non-resistant (accepts all sybil requests). The attacker can choose the request-sending strategy, but the defenders do not know resistance exactly; they only have a probability estimate p_r(v) for each node. The paper also allows sybil nodes to have “resistance” behavior for realism, but the preprocessing algorithms themselves start from known benign nodes and exploit only the resistance estimates for candidate nodes.
The data story is synthetic-plus-real-graph rather than a single curated benchmark. The paper uses real-world social-network graphs as the benign core and then synthesizes sybil regions by copying a benign induced subgraph B′ into a sybil set S, with each sybil node having a dual benign counterpart. Edges inside S mimic the copied benign structure. Attack edges from S to B are then created according to the chosen attack strategy and the resistance of target benign nodes: if a benign node is resistant, the attack request is rejected; otherwise it becomes an observed edge. The excerpt explicitly says the authors want diverse datasets because prior synthetic models hard-code homophily or uniform random attack edges, but the truncated text does not list the exact datasets, sizes, or split protocol. The paper states the code and data are public on GitHub, which helps reproducibility, but the excerpt does not specify frozen snapshots, seeds, or exact preprocessing steps beyond the synthetic construction.
Algorithmically, the paper first defines the Benign and Sybil Classification (BSC) problem in which some nodes are labeled benign, sybil, or unknown, and the goal is to maximize correct labeling of the unknowns. The core novel variable is the resistance bit r(v)∈{0,1}. For Maximizing Benigns (MB), the defender can reveal the resistance of up to k nodes; a newly discovered benign is any unknown node that has a path to a known benign where every node on that path has revealed resistance 1 (except possibly the endpoint). The authors prove MB is NP-hard to approximate within 1 - 1/e by reducing Maximum Coverage to a special case where all nodes are known resistant and the graph encodes set membership. They then show the expectation f(A) of newly discovered benigns is #P-hard to compute by reducing from a-b Connectedness for Induced Subgraphs. Because exact evaluation is intractable, they propose two practical approximations: a Monte Carlo greedy algorithm that repeatedly samples resistance assignments and estimates marginal gain, and a traversing heuristic that maintains a frontier of nodes whose resistance revelation can cascade to incoming neighbors. A concrete example of the heuristic is: if a revealed node v turns out resistant, then every incoming neighbor of v becomes newly eligible to be marked benign, and the algorithm updates per-node in-neighbor counts so that later selections focus on nodes with the largest remaining expected cascade.
For Discovering Potential Attack Edges (PAEs), the setup is simpler. A potential attack edge is an incoming edge to a benign node that is actually non-resistant, i.e., an edge from outside B∪S into a benign node with r(v)=0. Since the expected number of such edges revealed by checking a node v is (1 - p_r(v)) times the count of its incoming edges from outside the already known benign/sybil sets, the optimal strategy is to pick the k benign nodes with the largest such score. The authors say this can be done in linear time using a median-of-medians top-k routine. The excerpt does not include any statistical testing, cross-validation, or hyperparameter sweeps; the key theoretical claims are approximation hardness, #P-hardness, and algorithmic running time. The experimental protocol is described only at a high level in the excerpt: the preprocessing methods are applied before SybilSCAR, SybilWalk, and SybilMetric, and performance is compared across multiple synthetic attack strategies. The paper claims notable improvements, but the exact metrics, confidence intervals, and dataset-by-dataset numbers are not visible in the provided text.
Reproducibility appears relatively strong at the artifact level because the authors provide a public GitHub repository for code and data. However, the excerpt leaves several important details unclear: exact graph sources, the precise way resistance probabilities p_r(v) are estimated, the values of k and other evaluation hyperparameters, whether results are averaged over random seeds, and whether the synthetic graphs are held out across attack strategies or reused across methods. As a result, the theoretical parts are well specified, but the empirical pipeline is only partially recoverable from the excerpt alone.
Technical innovations
- Introduces user resistance to attack requests as an explicit graph signal for modeling sybil-to-benign edge formation, instead of assuming static homophily or uniform random attack edges.
- Defines a synthetic graph generation framework with three attack strategies—random, modified preferential attachment, and BFS-based targeting—that interact with resistance probabilities.
- Formulates the Maximizing Benigns problem and proves it is hard to approximate beyond 1 - 1/e, while also proving exact expectation evaluation is #P-hard.
- Provides two practical preprocessing algorithms for benign discovery: a Monte Carlo greedy estimator and a traversing heuristic that updates frontier structure incrementally.
- Shows that potential attack edge discovery has a closed-form top-k solution based on (1 - p_r(v)) · |Γ_in(v) \ (B ∩ S)|, enabling linear-time selection.
Datasets
- No named public benchmark is specified in the excerpt — size not stated — real-world social-network graphs used as benign cores, plus synthetic sybil regions generated by the authors — code/data public on GitHub
Baselines vs proposed
- SybilSCAR: performance improves after resistance-based preprocessing, but the excerpt does not give the exact metric or value.
- SybilWalk: performance improves after resistance-based preprocessing, but the excerpt does not give the exact metric or value.
- SybilMetric: performance improves after resistance-based preprocessing, but the excerpt does not give the exact metric or value.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2501.16624.
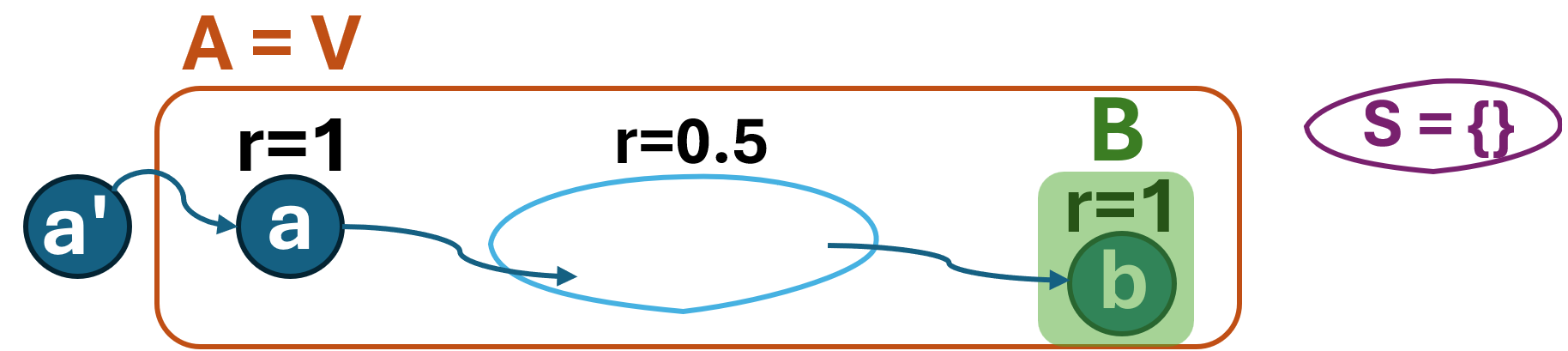
Fig 1: The construction used in the proof of #P-hardness.
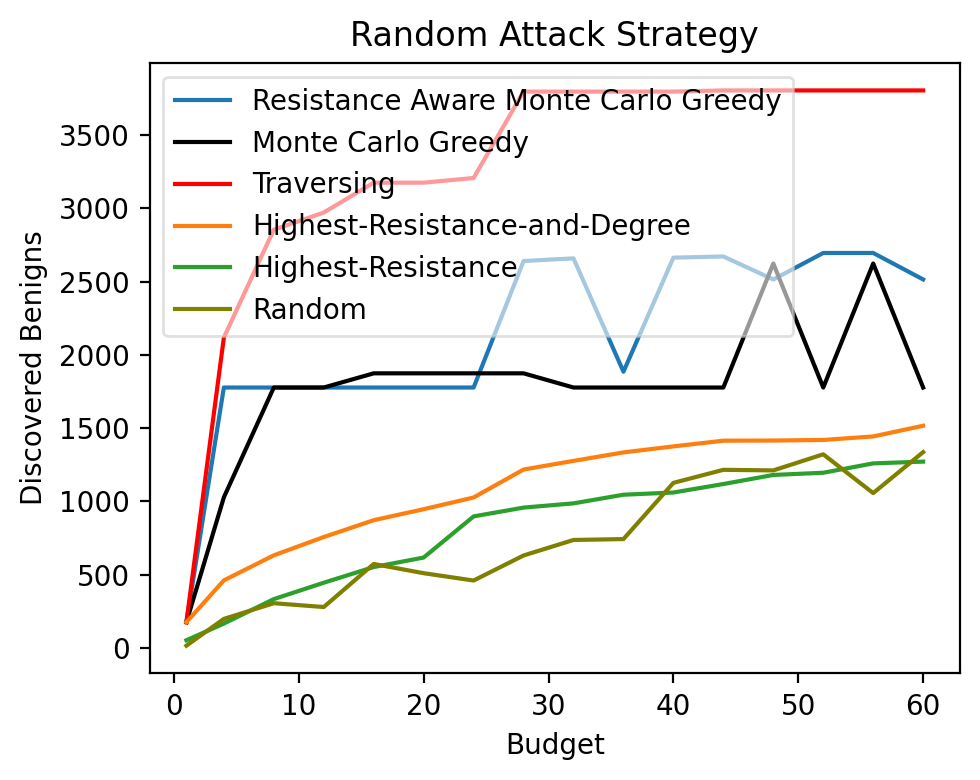
Fig 2: The number of discovered benigns by each algorithm when the budget ranges from 1 to 𝑘in the maximizing benigns
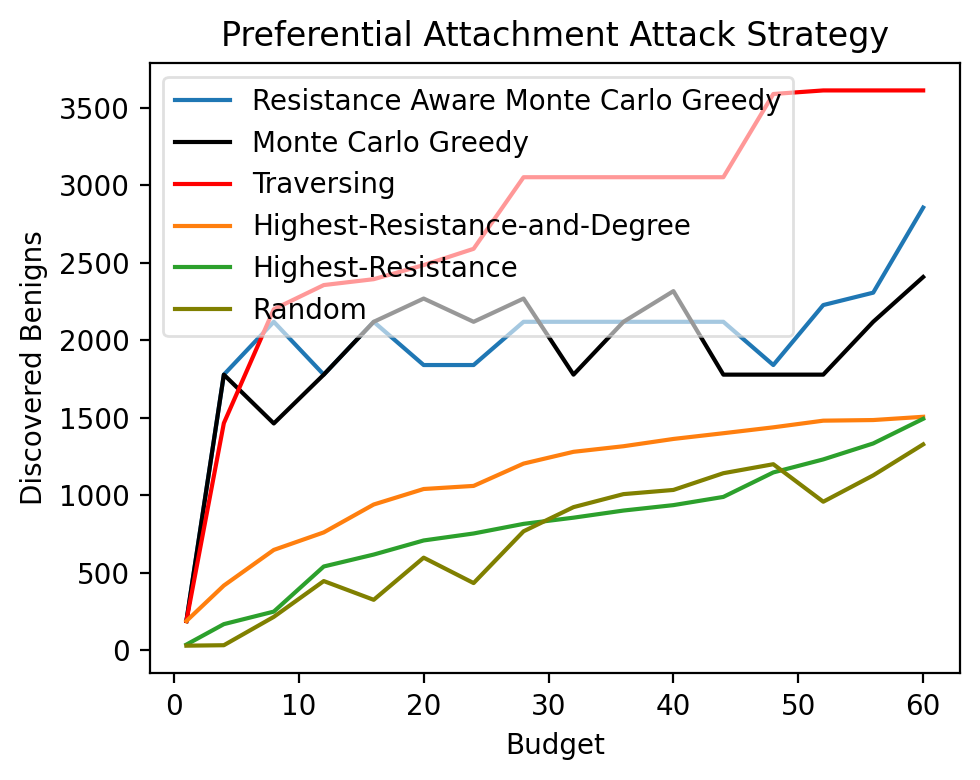
Fig 3: The number of discovered PAEs for different bud-
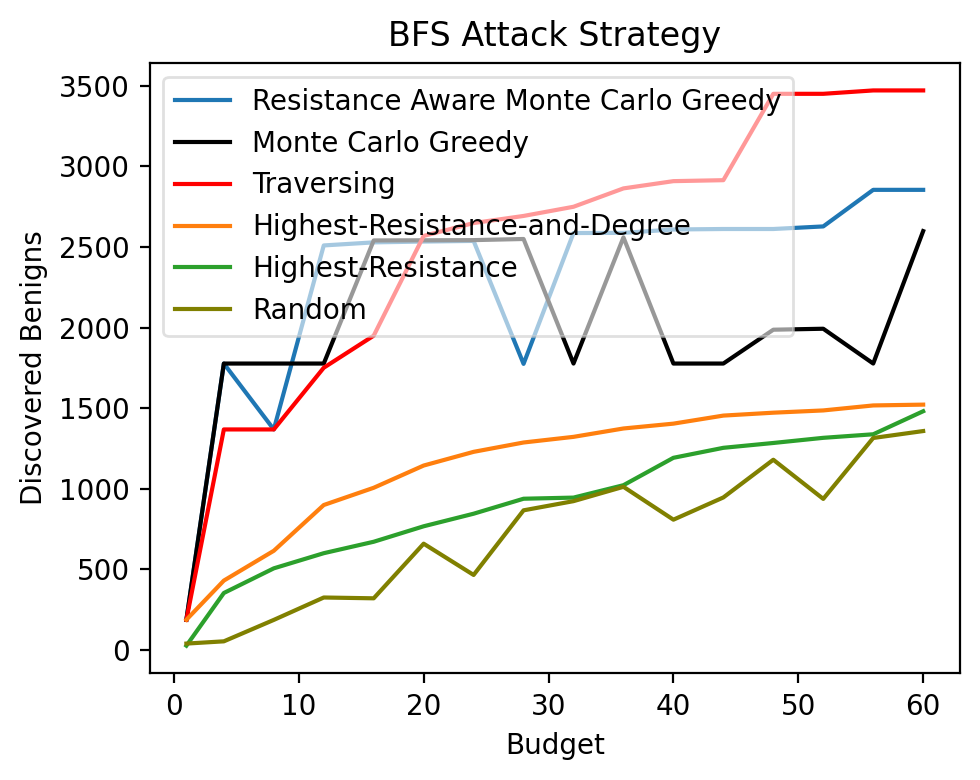
Fig 4 (page 8).
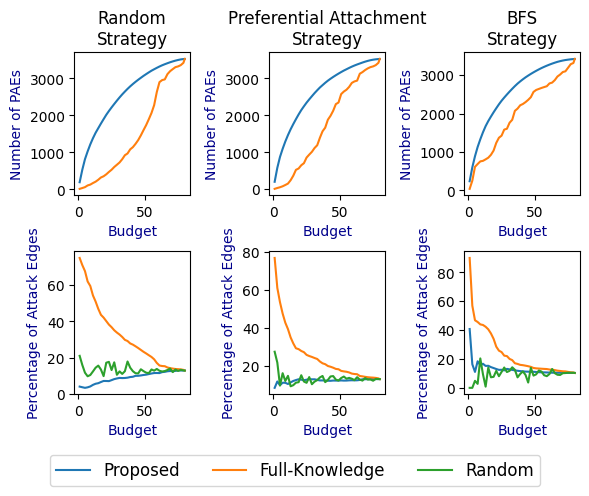
Fig 5 (page 8).
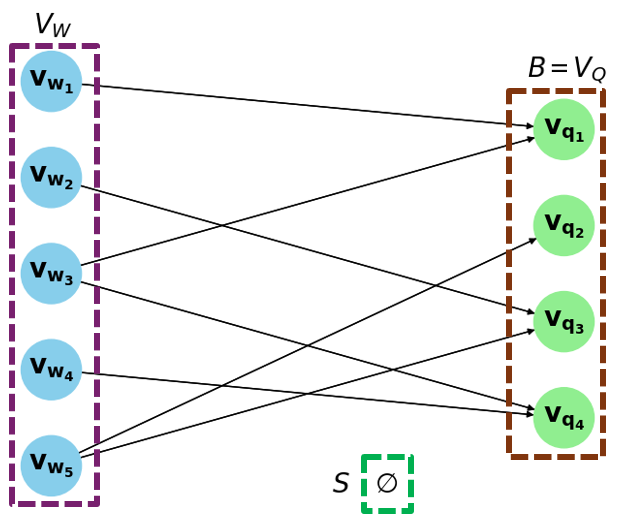
Fig 6 (page 10).
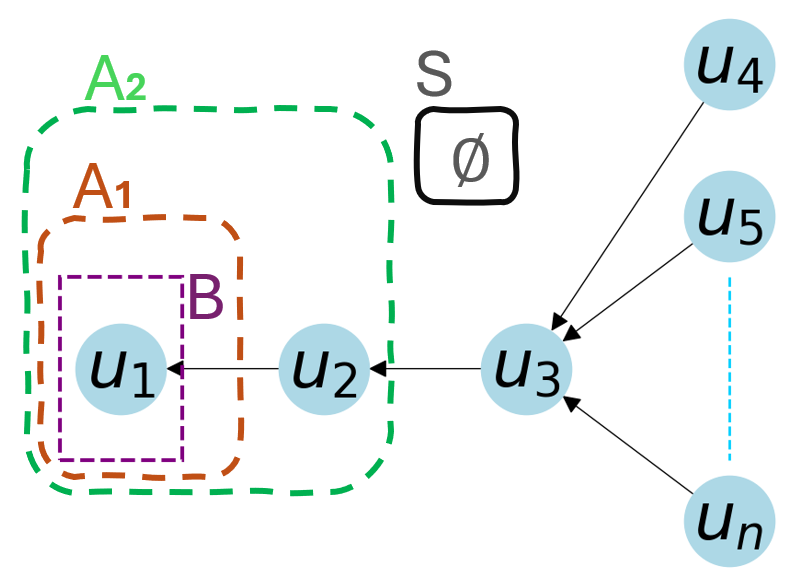
Fig 7 (page 11).
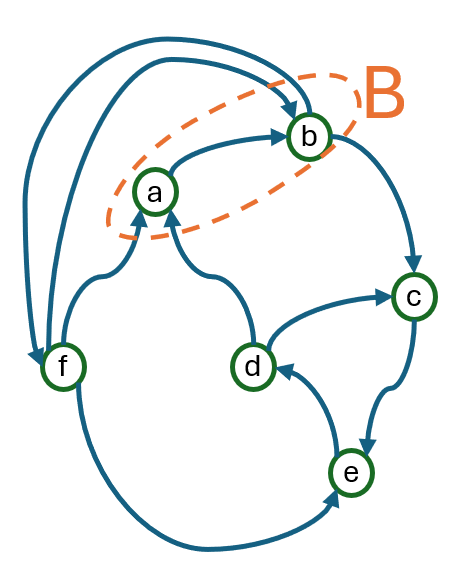
Fig 8 (page 13).
Limitations
- The excerpt does not provide exact experimental numbers, so the magnitude of the claimed improvements cannot be audited from the text provided.
- The synthetic data model depends on a resistance probability p_r(v) supplied as input; if these probabilities are misspecified, the preprocessing can be poorly targeted.
- The evaluation appears to rely on synthetic sybil injection into real benign graphs, so the realism of the attack and resistance model is only as good as the construction.
- The benign-discovery objective is estimated by Monte Carlo because exact computation is #P-hard, which introduces approximation variance and seed sensitivity.
- The traversing heuristic is motivated by intuition and complexity analysis, but the excerpt does not show approximation guarantees for its output quality.
- The paper focuses on graph-structure signals and does not appear to test robustness against adaptive attackers who know the preprocessing rule and strategically manipulate resistance or request patterns.
Open questions / follow-ons
- How sensitive are the preprocessing gains to calibration error in p_r(v), and can resistance estimates be learned robustly from limited probe requests?
- How do the proposed strategies behave under an adaptive attacker that anticipates resistance probing and intentionally skews acceptance patterns?
- Can the benign-discovery and PAE-selection ideas be integrated directly into a joint sybil detector rather than used only as preprocessing?
- What happens on real OSN datasets with known sybil ground truth, or on more realistic synthetic models that include temporal evolution and content signals?
Why it matters for bot defense
For a bot-defense engineer, the main takeaway is that sybil exposure can be improved by modeling how likely users are to accept suspicious requests, rather than assuming all edge formation follows a single homophily rule. In practice, that suggests a two-stage defense: first estimate which accounts are likely to be resistant or vulnerable to sybil outreach, then use that signal to prune suspected attack edges or expand the set of benign seeds before running a graph-based detector. That is especially relevant when the downstream detector is sensitive to attack-edge contamination, as with random-walk or belief-propagation style methods.
From an operational perspective, the paper also highlights a tradeoff: probing users with dummy sybil requests can improve detection, but only under a strict budget and with uncertainty in the resistance model. That makes the approach more like active graph auditing than passive classification. A CAPTCHA or onboarding system would not directly implement this method, but a fraud or trust-and-safety pipeline could borrow the idea of limited, targeted probing to increase signal on suspicious regions of the graph. The main caution is that the method’s effectiveness depends on how realistic the synthetic resistance and attack models are, so a deployment would need careful validation against adversarial adaptation and calibration drift.
Cite
@article{arxiv2501_16624,
title={ More Efficient Sybil Detection Mechanisms Leveraging Resistance of Users to Attack Requests },
author={ Ali Safarpoor Dehkordi and Ahad N. Zehmakan },
journal={arXiv preprint arXiv:2501.16624},
year={ 2025 },
url={https://arxiv.org/abs/2501.16624}
}