
Generating Realistic Forehead-Creases for User Verification via Conditioned Piecewise Polynomial Curves
Source: arXiv:2501.13889 · Published 2025-01-23 · By Abhishek Tandon, Geetanjali Sharma, Gaurav Jaswal, Aditya Nigam, Raghavendra Ramachandra
TL;DR
This paper tackles a very specific bottleneck in forehead-crease biometrics: there are too few real identities and too little within-subject variation to train a verification system that generalizes across databases. The authors’ core idea is to synthesize new forehead-crease identities not by directly hallucinating images, but by first drawing realistic crease geometry on a grid using parametric curves, then translating those edge-like prompts into full images with a diffusion-based image-to-image model. In parallel, they also generate extra edge maps with an unconditional DDPM, giving them a second synthetic pipeline that is more distribution-driven than geometry-driven.
What is new here is the combination of three pieces: a constrained geometric renderer for crease layouts, a diffusion-based Edge-to-Forehead-Creases translator trained on real self-quotient edge maps, and two diversity mechanisms that try to preserve identity while increasing sample variety. In their cross-database protocol, adding the synthetic data to real FH-V1 training improves the downstream forehead-crease verifier over a real-only baseline. The best reported result comes from mixing synthetic IDs from both the B-spline route and the diffusion-edge route, reaching TMR 59.23% at FMR 0.1% and 43.63% at FMR 0.01%, with EER around 9.63%, on the held-out FH-V2′ evaluation.
Key findings
- Real-only FH-V1 training yields EER 12.35%, TMR 40.12% at FMR 0.1%, and TMR 22.46% at FMR 0.01% on FH-V2′.
- Adding SA-PermuteAug [23] without curriculum is worse than real-only: EER rises to 13.76%, TMR drops to 33.62% at 0.1% FMR and 17.04% at 0.01% FMR.
- Using the proposed training curriculum with SA-PermuteAug improves to EER 10.53%, TMR 51.43% at 0.1% FMR, and 32.97% at 0.01% FMR.
- Real + BSpline-FC with curriculum gives EER 10.03% and TMR 57.06% / 41.83% at FMR 0.1% / 0.01%.
- Real + BSpline-VPD with curriculum achieves the best EER among the B-spline variants: 9.18%, with TMR 57.44% at 0.1% FMR and 40.39% at 0.01% FMR.
- Real + DiffEdges-VPD reaches TMR 58.49% at 0.1% FMR and 42.19% at 0.01% FMR, outperforming BSpline-VPD on TMR but not on EER.
- The merged Real + (DiffEdges + BSpline)-VPD setup gives the strongest TMR overall: 59.23% at 0.1% FMR and 43.63% at 0.01% FMR, with EER 9.63%.
- Synthetic realism/diversity tradeoff is visible in Table 3: BSpline-VPD diversity is 19.198 vs SA-PermuteAug 11.236, while DiffEdges-VPD has the lowest FID among the proposed methods at 67.776 (vs BSpline-VPD 162.709).
Threat model
The adversary is effectively a domain-shift challenge rather than an active attacker: the verifier must handle unseen subjects and cross-database variation between FH-V1 and FH-V2′, while the synthetic generator must avoid collapsing identities or leaking real examples. The system assumes the attacker does not control the training pipeline or the synthetic generation process, and the paper does not model presentation attacks, spoofing, or a generator-aware adversary trying to mimic the synthetic pipeline itself.
Methodology — deep read
The threat model is implicit rather than formally adversarial: the paper assumes the verifier will be trained on a mix of real and synthetic forehead-crease identities, and the main challenge is poor generalization under cross-database shift rather than an active attacker trying to spoof the system. The synthetic generation process itself is not framed as a security boundary; instead, the concern is whether the generated IDs are realistic enough to improve verification without leaking real identities or collapsing intra-subject variation. The comparison baseline is a real-only FHCVS model, and the authors also compare against the subject-agnostic synthetic set from SA-PermuteAug [23].
Data comes from two real forehead-crease datasets. FH-V1 [4] is the training source for both the verifier and the Edge-to-Forehead-Creases generator; the paper says it contains 247 subjects. FH-V2′ from [23] is used only for cross-database evaluation and is reported to have 29,200 genuine pairs and 8,497,200 imposter pairs. The paper does not give a train/validation/test split for FH-V1 in the excerpt, nor does it report per-subject image counts beyond the synthetic sampling totals. For the diffusion translator, each real ROI image is preprocessed into an edge map via Gaussian blur (15×15, σ=30.0), self-quotient normalization, Otsu binarization, dilation with a 3×3 kernel for one iteration, and inversion. The ROI segmentation procedure is taken from [4].
The generation pipeline is two-stage. First, a diffusion-based image-to-image translator called Edge2FC is trained on paired inputs: the dilated self-quotient edge map sqI_i^j and its corresponding real forehead-crease image I_i^j. The paper uses the BBDM formulation [16], with a UNet predicting noise during diffusion. They define the diffusion path directly between edge map and target image: q_t = (1-r_t)x_0 + r_t y + sqrt(δ_t)ϵ, where r_t=t/T, T=1000, and δ_t=2(r_t-r_t^2). Training minimizes a noise-prediction objective over the image pairs, but the excerpt does not disclose optimizer, learning rate, batch size, epochs, or seed strategy. Once trained, this translator can produce a forehead-crease image from any compatible edge-like prompt.
The novel part is how those prompts are built. The canvas is a 6×6 grid; a random mask decides which rows contain principal creases, which contain non-prominent creases, and which are empty. Principal creases span an entire row and are rendered with B-splines of degree sampled from U(3,4), while non-prominent creases are short localized structures rendered with degree-2 Bézier curves over merged 1×2 cells. The number of active rows is sampled from U(3,6), the number of principal rows from U(1,r), and non-prominent rows from U(1,r-rc). Control points for principal creases are initialized along the baseline from start to end points and then perturbed by small bounded noise m in [0.3, 0.6], preserving the row identity while changing local shape. This is intended to mimic up to six prominent horizontal forehead creases plus scattered minor wrinkles.
To increase intra-subject diversity, the authors use two mechanisms. Control Point Diversity (CPD) perturbs the stored curve parameters for a fixed identity, leveraging the localized control of B-splines so the crease locations remain consistent while the curve shape changes slightly. Visual Prompt Diversity (VPD) instead perturbs the rasterized prompt itself using imgaug operations such as dropout, elastic transform, piecewise affine, and perspective transforms. The paper also trains an unconditional DDPM on dilated self-quotient edge maps to generate new edge prompts; these are then translated by Edge2FC into synthetic images, giving the “DiffEdges” family. A concrete example end-to-end is: real FH-V1 image → self-quotient edge extraction → train Edge2FC → draw a 6×6 grid prompt with, say, three principal B-spline rows and one non-prominent Bézier row → optionally perturb control points or apply VPD transforms → feed prompt into Edge2FC → obtain a synthetic forehead-crease image representing a novel synthetic ID.
Evaluation is twofold. For synthetic-image quality they report FID, intra-subject diversity, and SSIM in Table 3; for verification utility they report EER and TMR at FMR 0.1% and 0.01% in Table 2. The verifier backbone is FHCVS [4], specifically ResNet-18 with spatial and channel attention modules, trained using AdaFace and focal loss. A noteworthy methodological piece is their training curriculum: instead of mixing all synthetic IDs at once, they fine-tune on real data, then add 50 synthetic IDs at a time, carrying forward previously added synthetic IDs, and finally fine-tune the best checkpoint on real data again. This curriculum is critical; without it, the synthetic augmentation can hurt performance. They do not report statistical significance tests, confidence intervals, or multiple-run variance in the excerpt.
On the reproducibility side, the paper says code and synthetic datasets are available at github.com/abhishektandon/bspline-fc. However, the trained Edge2FC weights, DDPM weights, and any exact hyperparameter schedule beyond the grid/curve rules are not fully specified in the excerpt. The authors are transparent that the B-spline synthetic images have high FID because the prompts are texture-poor relative to the texture-rich training pairs used for Edge2FC, so realism is imperfect even when verification improves. That distinction is important: the pipeline is optimized for utility in recognition, not for photorealism as judged by FID alone.
Technical innovations
- A constrained 6×6 grid-based parametric renderer that uses B-splines for principal forehead creases and Bézier curves for minor creases to generate identity-consistent visual prompts.
- A diffusion-based Edge-to-Forehead-Creases translator trained on dilated self-quotient edge maps and real forehead-crease images, enabling prompt-to-image synthesis for novel biometric identities.
- Two diversity controls for synthetic identities: control-point perturbation (CPD) and image-space prompt augmentation (VPD) tailored to crease patterns.
- An auxiliary unconditional DDPM that generates edge maps directly, providing a second synthetic path (DiffEdges) that is complementary to geometry-driven prompts.
- A staged training curriculum that adds synthetic identities in 50-ID increments to reduce the synthetic/real domain gap during verifier training.
Datasets
- FH-V1 — 247 subjects — public dataset from [4]
- FH-V2′ — 29,200 genuine pairs and 8,497,200 imposter pairs — introduced in [23]
- SA-PermuteAug — 247 subjects, 2,717 images — [23]
- BSpline-FC — 247 subjects, 2,470 images — synthetic, generated by the authors
- BSpline-CPD — 247 subjects, 2,470 images — synthetic, generated by the authors
- BSpline-VPD — 247 subjects, 3,458 images — synthetic, generated by the authors
- DiffEdges-FC — 247 subjects, 2,470 images — synthetic, generated by the authors
- DiffEdges-VPD — 247 subjects, 2,470 images — synthetic, generated by the authors
Baselines vs proposed
- FH-V1 (real only): EER = 12.35% vs proposed best mixed synthetic setup = 9.63%
- FH-V1 (real only): TMR @ FMR 0.1% = 40.12% vs proposed best mixed synthetic setup = 59.23%
- FH-V1 (real only): TMR @ FMR 0.01% = 22.46% vs proposed best mixed synthetic setup = 43.63%
- Real + SA-PermuteAug [23] without curriculum: EER = 13.76% vs with curriculum = 10.53%
- Real + SA-PermuteAug [23] without curriculum: TMR @ FMR 0.1% = 33.62% vs with curriculum = 51.43%
- Real + SA-PermuteAug [23] without curriculum: TMR @ FMR 0.01% = 17.04% vs with curriculum = 32.97%
- Real + BSpline-FC: EER = 10.03% vs Real + BSpline-VPD = 9.18%
- Real + BSpline-FC: TMR @ FMR 0.1% = 57.06% vs Real + BSpline-VPD = 57.44%
- Real + BSpline-CPD: EER = 10.05% vs Real + BSpline-VPD = 9.18%
- Real + DiffEdges-FC: EER = 9.49% vs Real + DiffEdges-VPD = 9.42%
- Real + DiffEdges-VPD: TMR @ FMR 0.1% = 58.49% vs Real + (DiffEdges + BSpline)-VPD = 59.23%
- Real + DiffEdges-VPD: TMR @ FMR 0.01% = 42.19% vs Real + (DiffEdges + BSpline)-VPD = 43.63%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2501.13889.
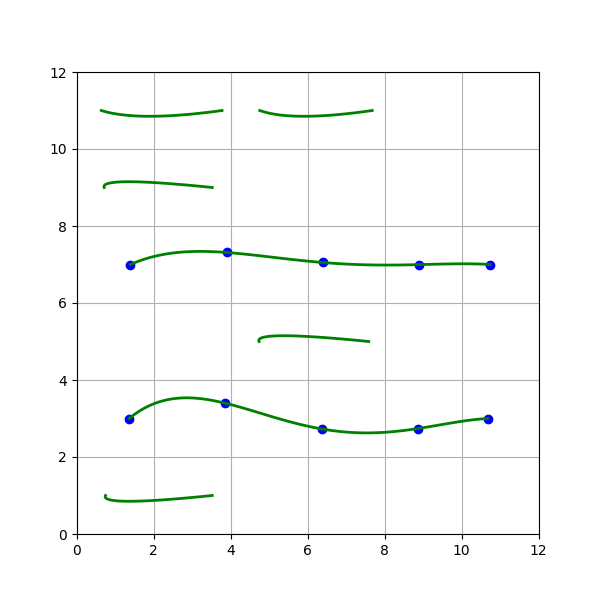
Fig 1: Proposed Method: Geometrically rendered visual prompts use an Edge-to-Forehead Creases model to generate novel synthetic

Fig 2: Edge Extraction: A forehead-creases image at each pre-

Fig 3 (page 3).

Fig 4 (page 3).
Fig 5 (page 3).

Fig 6 (page 3).
Fig 7 (page 3).
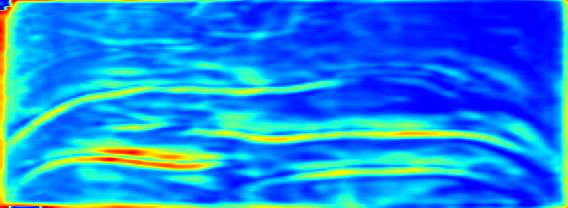
Fig 4: Intermediate feature maps visualization for images from
Limitations
- The paper admits the B-spline visual prompts lack texture and skin-tone detail, which likely explains the high FID values for the B-spline-based synthetic sets.
- Geometry-based forehead modeling does not fully capture the complexity of real forehead crease appearances, especially in extreme cases.
- The excerpt does not report optimizer, learning rate, batch size, number of epochs, or random seed handling for either the diffusion model or verifier training.
- There is no statistical significance analysis or variance across multiple runs shown in the excerpt, so the stability of the gains is unclear.
- The evaluation is cross-database, but the paper does not describe a strong held-out attacker or spoof-specific adversarial evaluation; the main goal is recognition generalization, not security against forgery.
- The synthetic sets are all generated from only 247 identities, so identity-scale diversity is still limited compared with large-scale biometric datasets.
Open questions / follow-ons
- Can texture and skin-tone conditioning be added to the B-spline prompt generation so that geometry and photorealism improve together, instead of trading one off against the other?
- Would the same geometry-plus-diffusion recipe transfer to other sparse biometric traits, such as periocular wrinkles or neck folds, or is forehead-specific anatomical structure essential?
- How robust are the gains under stronger distribution shifts, including different capture devices, lighting, face masks, age variation, and compression artifacts?
- Can the curriculum be replaced with a principled synthetic-real mixture schedule learned automatically, rather than the fixed 50-ID increments used here?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the main takeaway is that geometry-constrained synthetic generation can be more useful than unconstrained image synthesis when the target modality is sparse and structurally regular. If you are building liveness or user-verification systems around subtle skin or crease cues, this paper suggests a practical recipe: encode domain structure explicitly, then use a generative model to fill in appearance. That is relevant when you have few real samples but need many synthetic identities for training or stress testing.
At the same time, the results also show a common operational lesson: synthetic data can improve verifier utility even when standard image-fidelity metrics look poor. For a bot-defense engineer, that means evaluating synthetic augmentation only with FID or visual inspection is not enough. You would want cross-database verification, held-out identity tests, and sensitivity to intra-subject diversity, because the training signal may come from structure-preserving variation rather than photorealism. The paper also highlights a useful failure mode: if synthetic and real data are mixed naively, performance can get worse, so staged curricula or domain-balancing are likely important in production pipelines.
Cite
@article{arxiv2501_13889,
title={ Generating Realistic Forehead-Creases for User Verification via Conditioned Piecewise Polynomial Curves },
author={ Abhishek Tandon and Geetanjali Sharma and Gaurav Jaswal and Aditya Nigam and Raghavendra Ramachandra },
journal={arXiv preprint arXiv:2501.13889},
year={ 2025 },
url={https://arxiv.org/abs/2501.13889}
}