
Impact of Data Breadth and Depth on Performance of Siamese Neural Network Model: Experiments with Three Keystroke Dynamic Datasets
Source: arXiv:2501.07600 · Published 2025-01-10 · By Ahmed Anu Wahab, Daqing Hou, Nadia Cheng, Parker Huntley, Charles Devlen
TL;DR
This paper asks a practical question that keystroke-biometrics researchers often assume away: how much dataset breadth (number of subjects) and depth (samples per subject, sequence length, and triplet count) does a Siamese Neural Network actually need before performance stabilizes? Rather than changing architectures, the authors hold the model fixed and vary dataset composition across three public keystroke datasets that occupy different breadth/depth regimes: Aalto (wide, shallow free-text), CMU (narrow, deep fixed-text), and Clarkson II (narrow, deep uncontrolled free-text).
The main contribution is an empirical taxonomy grounded in the notions of feature space and density. The paper argues that breadth mainly helps the model cover more inter-subject variability, while depth helps only when the dataset’s feature space is not already large and sparse. In the reported experiments, increasing breadth on Aalto produced a model that became more stable and less sensitive to additional depth, whereas Clarkson II remained under-trained even with very large triplet counts because its uncontrolled free-text regime creates an expansive feature space with insufficiently dense training coverage. CMU, by contrast, was much easier to train well because repeated fixed text compresses the feature space. The authors report a new CMU state-of-the-art EER of 0.7% and frame the rest of the results as guidance for dataset design and expected returns from collecting more subjects versus more samples.
Key findings
- On CMU, the paper reports 0.7% EER, which the authors state is a 76% improvement over prior work (Deng & Zhong, 2013; Maheshwary et al., 2017).
- The CMU result is achieved despite using 5× less gallery sample data than prior work, according to the authors’ comparison in the contribution list.
- For Aalto breadth-wise training, models trained on larger subject pools became stable enough that additional depth had diminishing effect; the paper explicitly says increasing breadth enabled a well-trained model that better captured inter-subject variability.
- For Clarkson II, the model remained under-trained even with 15.2 million and 30.4 million triplets; the authors state that additional triplet generation is still needed.
- The paper finds that free-text datasets are affected by three depth-wise factors simultaneously: samples per subject, sequence length, and triplet count; fixed-text CMU is much less sensitive to these factors.
- The authors used 1,000 Aalto subjects for testing and trained separate models on 10 random subject groups ranging from 125 to 68,000 subjects.
- Each training run used margin α = 1.5 and was repeated 10 times with random subject selection to reduce variance.
- Training one model took about 14 hours on a 24 GB NVIDIA GeForce RTX 3090, with TensorFlow as the implementation stack.
Threat model
The implied adversary is an impostor attempting to authenticate as a legitimate user by presenting a different keystroke pattern, while the system only sees timing-based keystroke traces. The model is trained on genuine and impostor triplets to separate same-subject from different-subject samples in embedding space. The paper does not consider an adaptive attacker who knows the model internals, nor does it evaluate evasion, poisoning, or replay attacks; the focus is on generalization across unseen subjects and how much data is needed to support that generalization.
Methodology — deep read
Threat model and assumptions: this is an authentication setting, not an explicit attack-paper adversarial evaluation. The SNN is trained to distinguish genuine-user pairs from impostor pairs via triplets. The implicit adversary is an impostor attempting to spoof or match a user’s typing pattern using keystroke traces not seen during training. The paper assumes the attacker cannot tamper with the training pipeline or access the private labels beyond what is represented in the public datasets. It also assumes subject-level train/test separation: the model is evaluated on held-out subjects, so the target is generalization to unseen users rather than closed-set identification.
Data provenance and preprocessing: the authors use three public datasets. Aalto desktop is a controlled free-text dataset with 136 million keystrokes from 168,000 subjects, each typing 15 English sentences drawn from a pool of 1,525 prompts; the paper characterizes it as wide but shallow. CMU contains 51 subjects, each typing the fixed password “.tie5Roanl” 400 times across 8 sessions, with at least one day between sessions. Clarkson II contains 103 subjects, collected over 2.5 years in an uncontrolled free-text setting, with an average of 125,000 keystrokes per subject and about 12.9 million total keystrokes. For preprocessing, the authors extract timing features. CMU already had three time features, while Aalto and Clarkson II were converted into four timing/transition features plus an ASCII-based identifier feature: m (press-release duration), ud (release-to-next-press interval), dd, uu, and id = ASCII/255. They remove rows where digraphs exceed 5 seconds, and each sample is represented as a fixed-length sequence of rows; in the CMU example shown in Fig. 3, the sequence length is 10 rows for illustration, while the experimental setup later uses m = 70 for Aalto breadth-wise training. Inputs are padded with zeros when shorter than the target sequence length.
Architecture and algorithm: the model is a TypeNet-style Siamese Neural Network built from identical sub-networks sharing weights. Each branch takes a time-series input of shape m × n and outputs a 128-dimensional embedding. The sub-network includes a masking layer to ignore zero-padded rows, batch normalization, two tanh-activated LSTM layers to model temporal structure, and a dropout layer for regularization. The triplet formulation uses an anchor xA, a positive xP from the same subject, and a negative xN from an impostor subject. The triplet loss is standard margin-based metric learning: Lt = max{0, ||f(xA) − f(xP)||2 − ||f(xA) − f(xN)||2 + α}, with α = 1.5 chosen as the best-performing margin in their experiments. The novelty is not the loss itself but the controlled study of how breadth/depth interact with a fixed SNN architecture across different dataset regimes.
Training regime and concrete example: experiments were implemented in TensorFlow on a 24 GB Nvidia GeForce RTX 3090. One model run averaged about 14 hours. They repeat each experiment 10 times with random subject selection. In breadth-wise experiments, the authors fix samples per subject at 15, gallery size G = 10, and sequence length m = 70, then vary training breadth over 10 subject-group sizes: 125, 250, 500, 1,000, 2,000, 4,000, 8,500, 17,000, 34,000, and 68,000 subjects. They estimate possible triplets via the equations in Section 5.1 and note the combinatorial explosion: roughly 24 million possible triplets for 125 subjects versus 7.28 trillion for 68,000 subjects, but they only sample 7.6 million triplets for training because enumerating all is computationally expensive and memory-heavy. A concrete end-to-end example is the Aalto breadth-wise case: 1,000 subjects are held out for testing, a training group of 68,000 subjects is sampled from the remaining pool, each subject contributes 15 sentences, inputs are truncated/padded to length 70, and 7.6 million triplets are generated to train the Siamese model. In depth-wise experiments, they vary the number of samples per subject, the sequence length, and the number of triplets to see whether performance saturates or remains unstable.
Evaluation protocol, baselines, and reproducibility: the primary metric is Equal Error Rate (EER). The authors compare against prior keystroke SNN and classifier results in the literature, but the paper excerpt provided does not include a full tabulated baseline matrix beyond the stated CMU improvement and references to prior EERs (e.g., 3.5%, 3%, 4.45%, 1.2%, 7.9%, 26.8% for different related works and datasets). They also use repeated trials with random subject selection as a variance-control strategy rather than formal statistical testing; no cross-validation protocol is described in the excerpt. Reproducibility is partial: the datasets are public, the architecture is described, and some hyperparameters are reported, but the excerpt does not mention code release, frozen weights, or complete seed disclosure. A key evaluation idea is stability: a sufficiently trained model should show consistent EER as gallery size G changes and as data is resampled or expanded; fluctuating performance is interpreted as under-training. That criterion is then used qualitatively across Aalto, CMU, and Clarkson II to infer when additional breadth or depth is still beneficial.
Technical innovations
- They introduce a breadth/depth taxonomy for keystroke datasets, borrowing the idea of feature space and density to explain why some datasets support stable SNN training and others do not.
- They evaluate a single fixed TypeNet-style Siamese LSTM architecture across three public keystroke datasets to isolate dataset effects from architectural effects.
- They show that for uncontrolled free-text data like Clarkson II, triplet count becomes a bottleneck: even 15.2M and 30.4M triplets were insufficient to fully train the model.
- They report a new CMU EER of 0.7% and position it as substantially better than prior fixed-text keystroke baselines.
- They distinguish depth effects by data regime: fixed-text CMU is largely insensitive to more samples per subject, while free-text datasets are sensitive to samples, sequence length, and gallery size.
Datasets
- Aalto desktop — 168,000 subjects; 136 million keystrokes; 15 sentences per subject — public dataset
- CMU — 51 subjects; 400 samples per subject (50 repeats × 8 sessions) — public dataset
- Clarkson II — 103 subjects; ~12.9 million keystrokes total; ~125,000 keystrokes per subject on average — public dataset
Baselines vs proposed
- Deng & Zhong (2013) / Maheshwary et al. (2017) on CMU: EER = 3.5% / 3.0% vs proposed: 0.7%
- Ayotte et al. (2019) on Clarkson II (50 sequence length): EER = 7.9% vs proposed: not numerically stated in the provided excerpt
- Acien et al. (2021) TypeNet on Aalto: EER = 1.2% vs proposed: not numerically stated in the provided excerpt
- Acien et al. (2021) cross-dataset Aalto → Clarkson II: EER = 26.8% vs proposed: not numerically stated in the provided excerpt
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2501.07600.
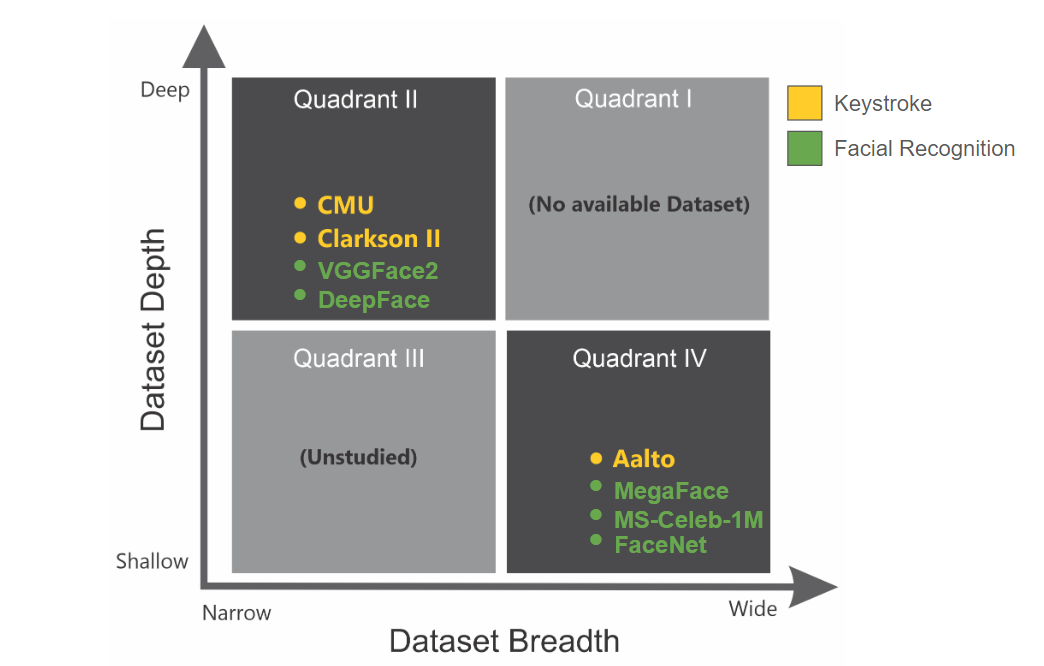
Fig 1: Quadrant plots of datasets based on breadth and depth
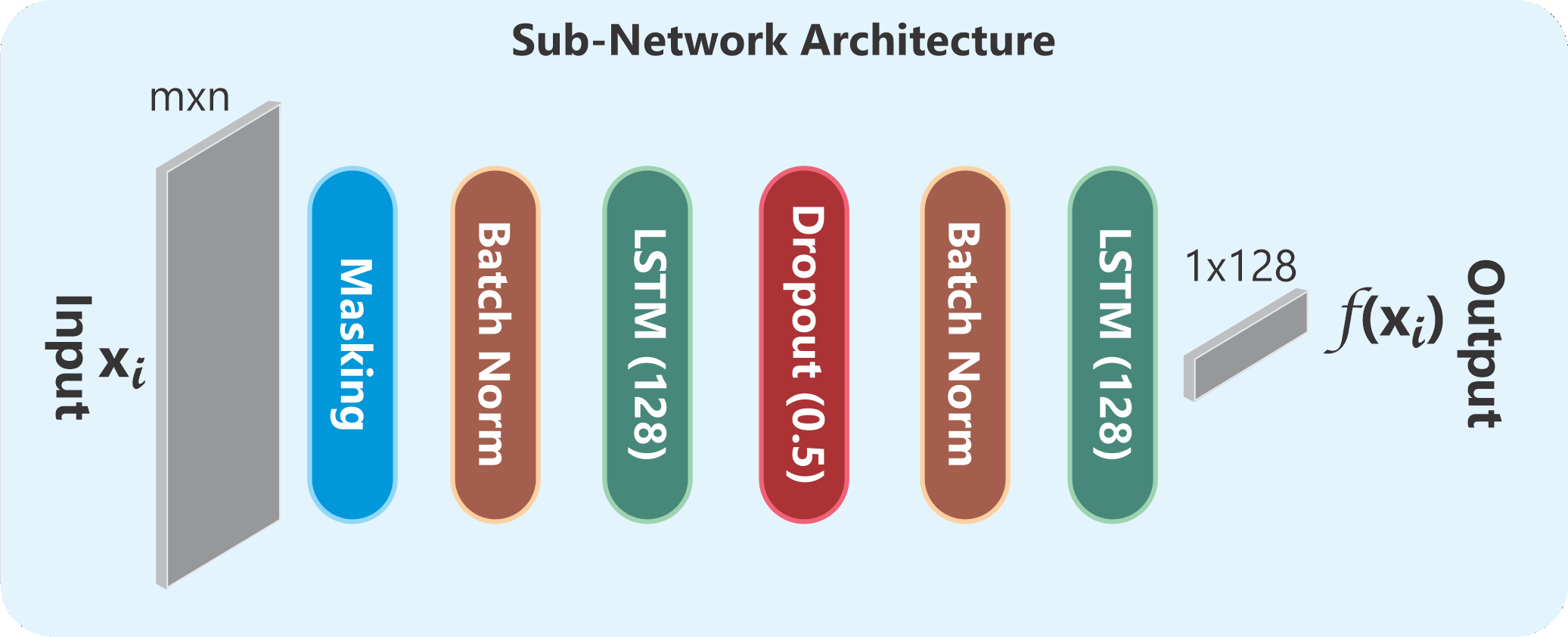
Fig 2: (a) The Siamese sub-network, taking a time series input (xi) of shape m × n and returning an output vector (em-
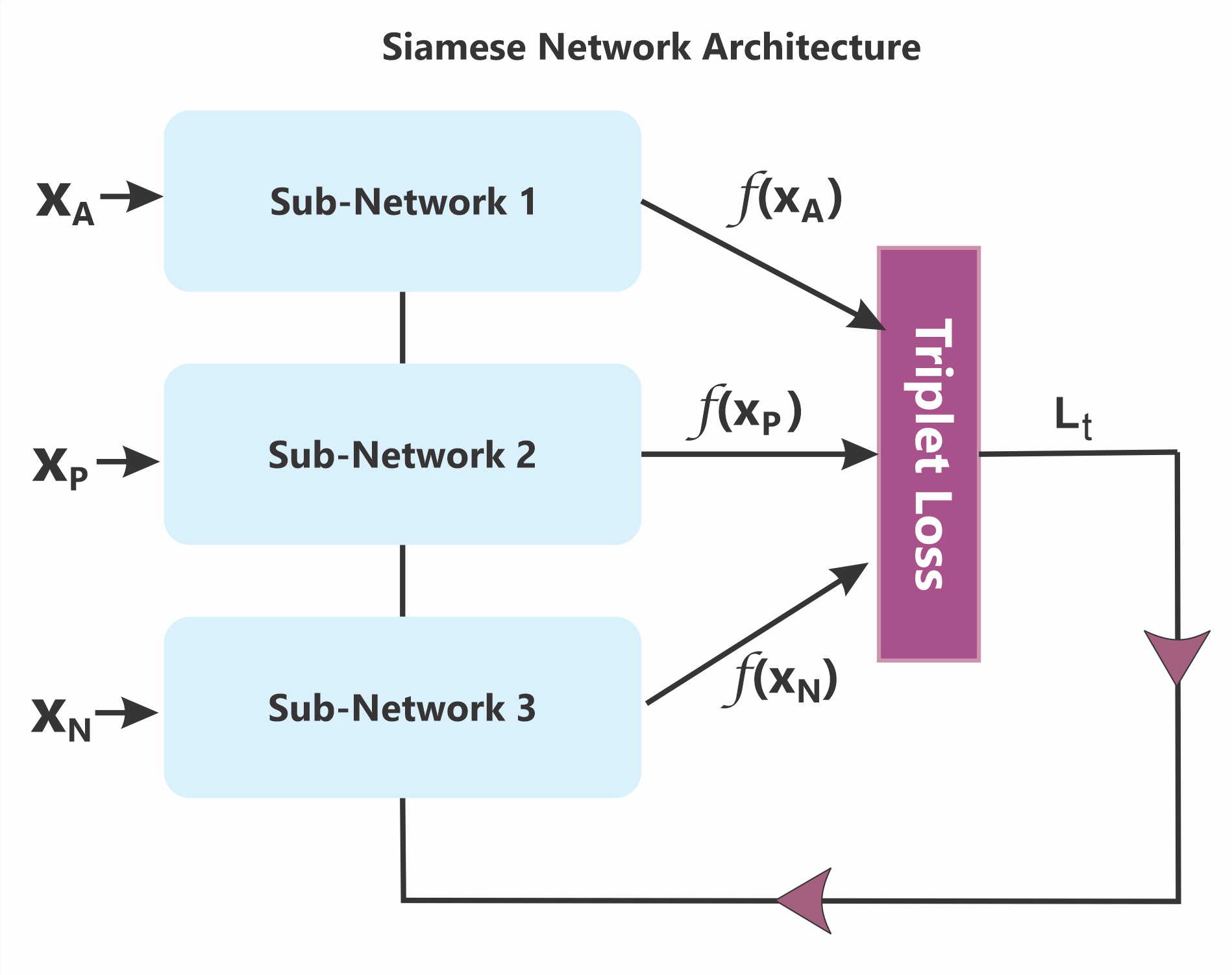
Fig 3: A screenshot of the preprocessed CMU dataset highlighting its four distinctive features (m, ud, dd, and id).
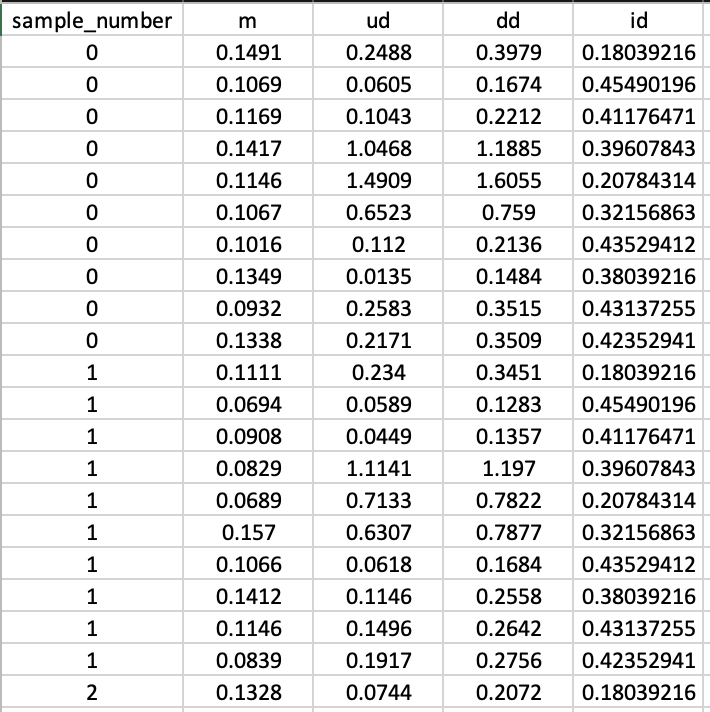
Fig 4 (page 9).
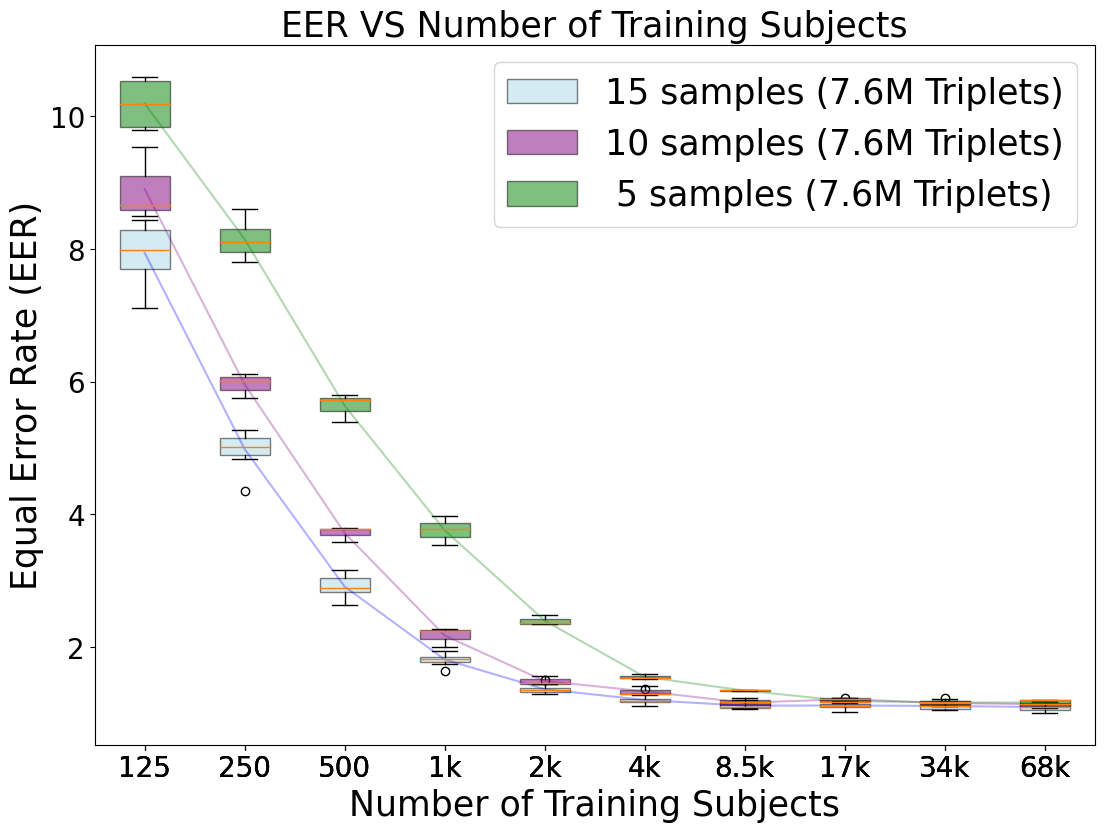
Fig 4: Aalto Dataset: Box plots for both the breadth-wise experiments (as seen horizontally with varying number of subjects),
Limitations
- The paper excerpt does not provide a full numeric table of all breadth-wise and depth-wise results, so several claims are qualitative in the supplied text.
- Clarkson II results are described as under-trained even at 15.2M and 30.4M triplets, but the excerpt does not show the exact EER values for those runs.
- There is no explicit attacker simulation, adaptive spoofing evaluation, or adversarial training study; the work is about training data scale, not robustness to active attacks.
- The stability criterion for “well-trained” versus “under-trained” is heuristic, based on performance trends with gallery size G and resampling, rather than a formal statistical test.
- Reproducibility is incomplete in the excerpt: no code URL, fixed random seeds, or frozen checkpoints are mentioned.
- The findings are dataset-regime-specific to keystroke dynamics and may not transfer directly to other behavioral biometrics without re-checking feature-space/density assumptions.
Open questions / follow-ons
- How does the breadth/depth tradeoff change under adaptive spoofing or mimicry attacks, where impostors intentionally approximate target timing patterns?
- Would the same feature-space/density interpretation hold for other behavioral signals such as mouse dynamics, touch dynamics, or gait?
- Can one predict the marginal benefit of adding more subjects versus more samples per subject using a data-scaling law for triplet-trained biometric models?
- What sampling strategy for triplet construction is best for uncontrolled free-text datasets like Clarkson II: random triplets, hard triplets, or curriculum-based mining?
Why it matters for bot defense
For a bot-defense engineer, the useful takeaway is that model performance is not just about architecture; it depends heavily on whether the training set adequately covers the behavioral feature space. In a CAPTCHA or continuous-authentication setting, this argues for measuring subject breadth and per-subject depth explicitly when planning data collection. A wide but shallow set can still support a useful model if the signal is fairly constrained, but free-form behavior with high intra-subject variance will need much more depth and far more triplets before metric learning stabilizes. Practically, that means you should expect diminishing returns from adding more samples in fixed-text tasks sooner than in free-text tasks, and you should be cautious about interpreting good validation EER on a narrow data regime as evidence that the model will hold up in production under broader user diversity.
Cite
@article{arxiv2501_07600,
title={ Impact of Data Breadth and Depth on Performance of Siamese Neural Network Model: Experiments with Three Keystroke Dynamic Datasets },
author={ Ahmed Anu Wahab and Daqing Hou and Nadia Cheng and Parker Huntley and Charles Devlen },
journal={arXiv preprint arXiv:2501.07600},
year={ 2025 },
url={https://arxiv.org/abs/2501.07600}
}