
The Synergy of Automated Pipelines with Prompt Engineering and Generative AI in Web Crawling
Source: arXiv:2502.15691 · Published 2024-12-29 · By Chau-Jian Huang
TL;DR
This study addresses challenges in web crawling caused by webpage diversity and anti-scraping defenses by leveraging generative AI systems, specifically Claude AI (Sonnet 3.5) and ChatGPT-4.0, with thoughtful prompt engineering. Two prompt styles are evaluated: PROMPT I (general inference, tested on Yahoo News) and PROMPT II (element-specific, tested on Coupons.com). The work compares the quality and performance of AI-generated Python scraping scripts on metrics including functionality, readability, modularity, and robustness, with data collected via manual testing and assessor scoring.
Claude AI consistently outperformed ChatGPT-4.0, especially in PROMPT II where detailed element targeting was required. Claude’s scripts demonstrated greater modularity, robust error handling, and adaptability to dynamic, JavaScript-driven content and anti-scraping measures (using tools like undetected_chromedriver and fake_useragent). The paper highlights how generative AI combined with prompt engineering lowers barriers to entry for scraping, improves maintainability, and enhances scalability against real-world challenges.
The results underscore the importance of precise prompt design, showing PROMPT II’s superiority for complex page structures. Integration with anti-bot tools allows generated scripts to bypass detection mechanisms, enabling more reliable data extraction from modern web environments. Overall, the study reveals the transformative potential of combining AI coding agents with prompt engineering to automate and optimize web crawling workflows.
Key findings
- Claude AI-generated scripts showed superior modularity and readability scores compared to ChatGPT-4.0 in both PROMPT I and PROMPT II tasks.
- In PROMPT II (element-specific prompt on Coupons.com), Claude AI’s scripts incorporated reusable functions and robust try-except error handling, whereas ChatGPT-4.0 produced more linear, repetitive code lacking error resilience.
- Anti-scraping tools like undetected_chromedriver, Selenium, and fake_useragent were integrated into Claude AI’s scripts, improving adaptability to JavaScript-heavy pages and bypassing basic bot detection.
- PROMPT II prompts requiring explicit HTML element targeting resulted in higher accuracy and reliability of scraping scripts than PROMPT I’s general inference approach.
- Claude AI’s advanced contextual understanding enables better anticipation of real-world webpage irregularities and dynamic content, leading to more robust and maintainable scraping solutions.
- ChatGPT-4.0 performed adequately on general-purpose scraping tasks (PROMPT I) but often required manual script refinement for complex or element-specific scenarios.
- Scoring by three evaluators confirmed Claude AI’s superiority in functionality, code clarity, and error tolerance, though specific numeric scores were not detailed.
- Scripts generated by Claude AI were more scalable for large projects requiring frequent updates due to modular design.
Threat model
The adversary is an automated web scraper aiming to extract structured data from diverse and protected websites without direct cooperation from the site. The adversary can inspect HTML structure and employ browsing automation tools but confronts anti-scraping defenses such as IP blocking, CAPTCHAs, and JavaScript-driven dynamic content. The scraper cannot break CAPTCHAs or otherwise circumvent sophisticated human verification beyond standard evasion techniques like user-agent spoofing or headless browser detection avoidance.
Methodology — deep read
Threat Model & Assumptions: The study assumes adversaries are web scraping practitioners facing diverse, anti-scraping protected websites. The adversary does not have privileged access to site internals but can inspect page HTML and interact via a browser. The goal is to generate scripts that reliably extract data despite defenses such as IP blocking, CAPTCHAs, and dynamic JavaScript rendering.
Data: Two real-world websites were used as testbeds: Yahoo News (for PROMPT I, general inference scraping) and Coupons.com (for PROMPT II, element-specific scraping). Ground truth labels are implicitly the visible titles and content on these webpages as defined by human evaluators. No large labeled dataset; evaluation was manual with structured scoring.
Architecture/Algorithm: The approach uses two generative AI LLMs—Claude AI Sonnet 3.5 (Anthropic) and ChatGPT-4.0 (OpenAI)—prompted with instructions to generate Python web scraping code. Prompt I directs general data extraction using BeautifulSoup and requests; Prompt II explicitly specifies target HTML elements (e.g., <h1> and <div class="content">). Anti-scraping libraries (undetected_chromedriver, Selenium, fake_useragent) are injected into generated code to handle bot detection and dynamic loading.
Training Regime: Not applicable as the AI models are pre-trained LLMs. The study uses zero-shot or few-shot prompt engineering to elicit code generation.
Evaluation Protocol: Evaluation metrics include functionality (does the script extract required data?), readability (clarity of code and comments), modularity (use of reusable functions), and robustness (error handling and adaptability to webpage changes). Scoring was performed manually by three independent evaluators. No formal quantitative metrics or statistical tests documented, but code snippets and visualizations illustrate differences.
Reproducibility: The paper does not mention code or prompt release; Claude AI platform access is commercial. Data (public websites) and common scraping libraries are standard. Exact prompt texts PROMPT I and PROMPT II are described in detail.
Concrete Example: For PROMPT II on Coupons.com, Claude AI generated a modular Python script with function extract_element(tag, class_name) called separately for <h1> titles and <div class="content"> descriptions. The script included try-except blocks to handle missing elements gracefully. It integrated Selenium with undetected_chromedriver and fake_useragent to manage dynamic content and evade scraping defenses — ensuring robust extraction performance even under page structure changes.
Technical innovations
- Use of prompt engineering to elicit modular, maintainable web scraping scripts from generative AI models (Claude AI and ChatGPT-4.0).
- Integration of anti-scraping libraries (undetected_chromedriver, fake_useragent, Selenium) directly into AI-generated code to enhance real-world scraping robustness.
- Design and evaluation of two distinct prompt strategies: general inference (PROMPT I) vs. element-specific targeting (PROMPT II) to improve scraping accuracy.
- Leveraging Claude AI’s advanced contextual reasoning to create reusable functions with robust error handling for dynamic and heterogeneous webpages.
Datasets
- Yahoo News — Public website used for general inference prompt evaluation.
- Coupons.com — Public website used for element-specific prompt evaluation.
Baselines vs proposed
- ChatGPT-4.0 (PROMPT I): functional code with less modularity and readability vs. Claude AI (PROMPT I): higher modularity and readability with reusable functions and robust error handling.
- ChatGPT-4.0 (PROMPT II): linear, hardcoded scraping logic lacking error handling vs. Claude AI (PROMPT II): modular, maintainable, error-resilient scripts with scalable design.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2502.15691.

Fig 3: 1 Example of code (PROMPT I)

Fig 2 (page 3).
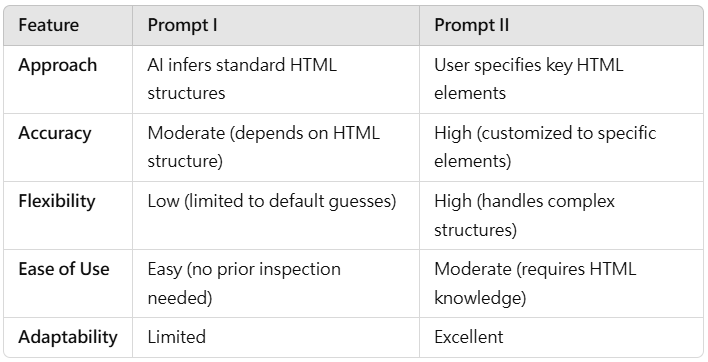
Fig 3 (page 3).
Limitations
- Evaluation relies on manual scoring by three evaluators without formal quantitative metrics or inter-rater reliability statistics.
- Limited to two websites; Yahoo News and Coupons.com may not represent full web heterogeneity or anti-scraping complexity.
- No adversarial testing against advanced bot detection or CAPTCHA systems beyond undetected_chromedriver/fake_useragent integration.
- The study uses pre-trained commercial LLMs without ability to inspect internal model mechanisms or fine-tune for scraping tasks.
- Absence of scalability tests on large-scale or highly dynamic crawling workflows with multiple page navigations.
- No publicly released code or prompts limits exact reproducibility and external validation.
Open questions / follow-ons
- How well do generative AI-assisted scraping scripts perform on highly dynamic, multi-page, or infinite scroll websites?
- What enhancements in prompt design or AI model training could improve resilience against aggressive anti-bot defenses such as CAPTCHAs or behavioral analysis?
- Can AI-generated scraping scripts be extended to perform complex workflows involving multi-step navigation, login, or stateful interactions?
- What are best practices to automate prompt refinement and iterative feedback loops for continuous script improvement in evolving web environments?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work demonstrates that generative AI can create sophisticated scraping scripts that are modular, error-resilient, and can incorporate anti-scraping evasion techniques such as undetected_chromedriver and fake user agents. This raises the bar for automated attackers by lowering the technical proficiency needed to generate effective crawlers that adapt quickly to page changes and bypass basic defenses. It highlights the need for dynamic, multi-layered bot detection strategies that can counter AI-generated scraping workflows, especially those capable of integrating headless browser evasions.
From a CAPTCHA perspective, the study implies that basic evasion techniques integrated into AI-generated code are insufficient for blocking scraping at scale. Defenders should consider additional challenges including client-side fingerprinting, adaptive CAPTCHAs, and behavioral analytics to detect such advanced automated agents. Overall, it underscores the evolving threat landscape where generative AI accelerates the sophistication and maintainability of scraping tools, informing the design of more robust bot mitigation systems.
Cite
@article{arxiv2502_15691,
title={ The Synergy of Automated Pipelines with Prompt Engineering and Generative AI in Web Crawling },
author={ Chau-Jian Huang },
journal={arXiv preprint arXiv:2502.15691},
year={ 2024 },
url={https://arxiv.org/abs/2502.15691}
}