
F-RBA: A Federated Learning-based Framework for Risk-based Authentication
Source: arXiv:2412.12324 · Published 2024-12-16 · By Hamidreza Fereidouni, Abdelhakim Senhaji Hafid, Dimitrios Makrakis, Yaser Baseri
TL;DR
This paper addresses the critical challenge of improving Risk-based Authentication (RBA) systems by leveraging Federated Learning (FL) to enhance privacy, scalability, and adaptability. Traditional RBA methods tend to be server-centric, relying on centralized data collection that raises privacy concerns, suffers cold-start problems, and poorly handle heterogeneous user data. The authors propose a novel Federated Risk-Based Authentication (F-RBA) framework that distributes risk evaluation locally on user devices while aggregating learning globally. This approach preserves user privacy by keeping raw data on devices and exchanging only model updates.
The key innovation lies in F-RBA's similarity-based feature engineering that reconciles heterogeneous and non-IID data inherent in federated environments, enabling robust and consistent model training across diverse users. Additionally, integration of IPFS and Distributed Ledger Technology (DLT) enables secure, decentralized storage and cross-device user profile synchronization to support continuous risk assessment. Empirical evaluation on a real-world multi-user dataset shows F-RBA achieves higher true positive rates in detecting suspicious logins compared to conventional unsupervised anomaly detection baselines, demonstrating improved security without compromising user experience or privacy.
Key findings
- F-RBA utilizes federated learning combined with similarity-based feature engineering to mitigate challenges of non-IID and heterogeneous user data distributions in RBA.
- Integration of IPFS and Distributed Ledger Technology enables cross-device, real-time risk profile synchronization without centralized user data storage.
- The framework resolves the cold-start problem by combining global aggregated models with personalized risk thresholds for new users.
- Empirical evaluation demonstrates F-RBA outperforms traditional unsupervised anomaly detection models, achieving a superior true positive rate for detecting suspicious logins (exact numerical results not specified).
- Similarity-based feature transformation reduces client feature space divergence and improves federated model convergence stability, as shown by lower MSE in experiments (Figure 4).
- Semi-Synchronous Federated Learning strategy balances local update timings and global aggregation to enhance training efficiency and consistency.
- On-device local risk assessment allows continuous event-driven authentication, enabling adaptive responses to session hijacking by monitoring contextual deviations in real time.
Threat model
The adversary seeks unauthorized access by compromising user credentials, stealing devices, hijacking sessions, or exploiting insufficient adaptive authentication. They have no ability to break encrypted communications or tamper with the authentication server, IPFS, or blockchain-based DLT components. The system assumes secure client devices and communication channels. Attackers cannot manipulate federated learning updates arbitrarily or induce targeted poisoning attacks.
Methodology — deep read
Threat Model & Assumptions: The adversary is assumed to attempt unauthorized access via stolen credentials, device theft, session hijacking, or exploiting weak adaptive authentication. The system assumes secure, reliable client applications, protected communications, and trust in the authentication server and third-party data sources. IPFS and DLT components are assumed to provide secure, efficient decentralized storage. The adversary cannot break encryption or disrupt DLT/IPFS systems effectively.
Data: The authors use a real-world multi-user login dataset capturing contextual information such as timestamp, IP address, user agent, system identity (timezone, language), connection type, RTT, login success, and IP reputation. Labels for suspicious or benign login attempts originate from historical behavior and third-party IP reputation services. The exact dataset size and splits are not fully detailed.
Architecture & Algorithms: The core ML model is a federated autoencoder trained using Horizontal Federated Learning (HFL) with the Federated Averaging (FedAvg) aggregation algorithm. Local client devices train models on their own historical login data transformed through similarity-based feature engineering, which encodes login features relative to previous behaviors to reduce heterogeneity. Similarity measures allow consistent representation despite non-overlapping feature distributions. Semi-synchronous FL scheduling balances update timing and aggregation.
Training Regime: Local models periodically retrain on updated local datasets after fetching history from IPFS using content identifiers (CIDs) stored on the DLT. After local training, model updates and personalized risk thresholds are encrypted and sent to the authentication server. When updates from enough clients are received, the server performs weighted FedAvg aggregation, considering dataset sizes, then distributes the global model back to clients. Specific hyperparameters, epochs, batch sizes, or hardware details are not explicitly provided.
Evaluation Protocol: The main evaluation metric reported is the true positive rate for detecting suspicious logins compared to baseline unsupervised anomaly detection models such as One-Class SVM or Local Outlier Factor. Ablation studies on feature engineering and federated strategies are indicated by comparative performance and mean squared error plots (Figures 3 and 4), demonstrating better model convergence and risk discrimination. Cross-validation or distribution shift tests are not explicitly stated. The cold-start problem performance is discussed qualitatively.
Reproducibility: The authors do not indicate a public code or dataset release. Some third-party APIs are used for IP reputation and geolocation data. DLT and IPFS integration details are described but code is not linked. The results rely on real-world proprietary datasets with privacy constraints.
Example end-to-end: A user login attempt generates contextual data locally, which the client transforms using similarity-based features based on local history retrieved via IPFS/DLT. The transformed features serve as input to the on-device autoencoder model, which outputs a risk score. This score is sent with credentials to the server, which decides on access or triggers adaptive authentication. Successful logins update the history encrypted and stored to IPFS, and local models periodically retrain and share updates to the global federated model.
Technical innovations
- Introduction of similarity-based feature engineering to address non-IID, heterogeneous data distributions for federated learning in RBA.
- Combining federated autoencoder models with weighted FedAvg aggregation and semi-synchronous update schemes tailored for RBA risk engines.
- Use of IPFS and Distributed Ledger Technology to enable secure, decentralized, and real-time cross-device user profile synchronization supporting continuous authentication.
- A hybrid global model aggregation combined with adaptive personalized risk thresholds effectively mitigating the cold-start problem for new users.
Datasets
- Real-world multi-user login dataset — size and provenance unspecified — includes contextual login features, IP reputation, timestamps, user agent, RTT, and login success labels.
Baselines vs proposed
- Unsupervised anomaly detection (One-Class SVM, Local Outlier Factor): TPR < F-RBA true positive rate (exact numerical values not reported)
- Federated learning with conventional feature encoding: Higher MSE and lower convergence stability vs similarity-based feature engineering approach in F-RBA (Fig 4).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2412.12324.
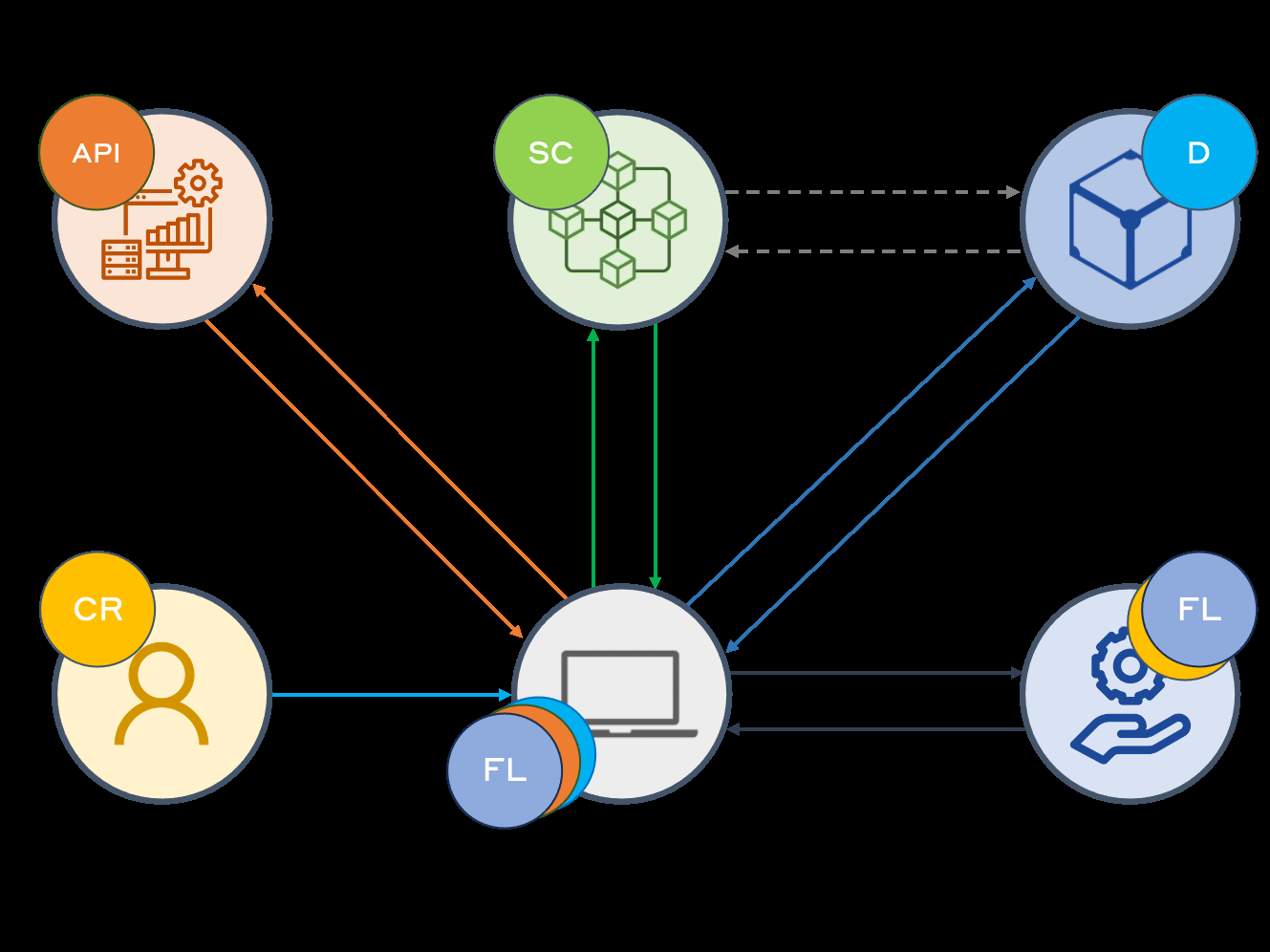
Fig 1: System Model of our Proposed Framework (F-RBA)
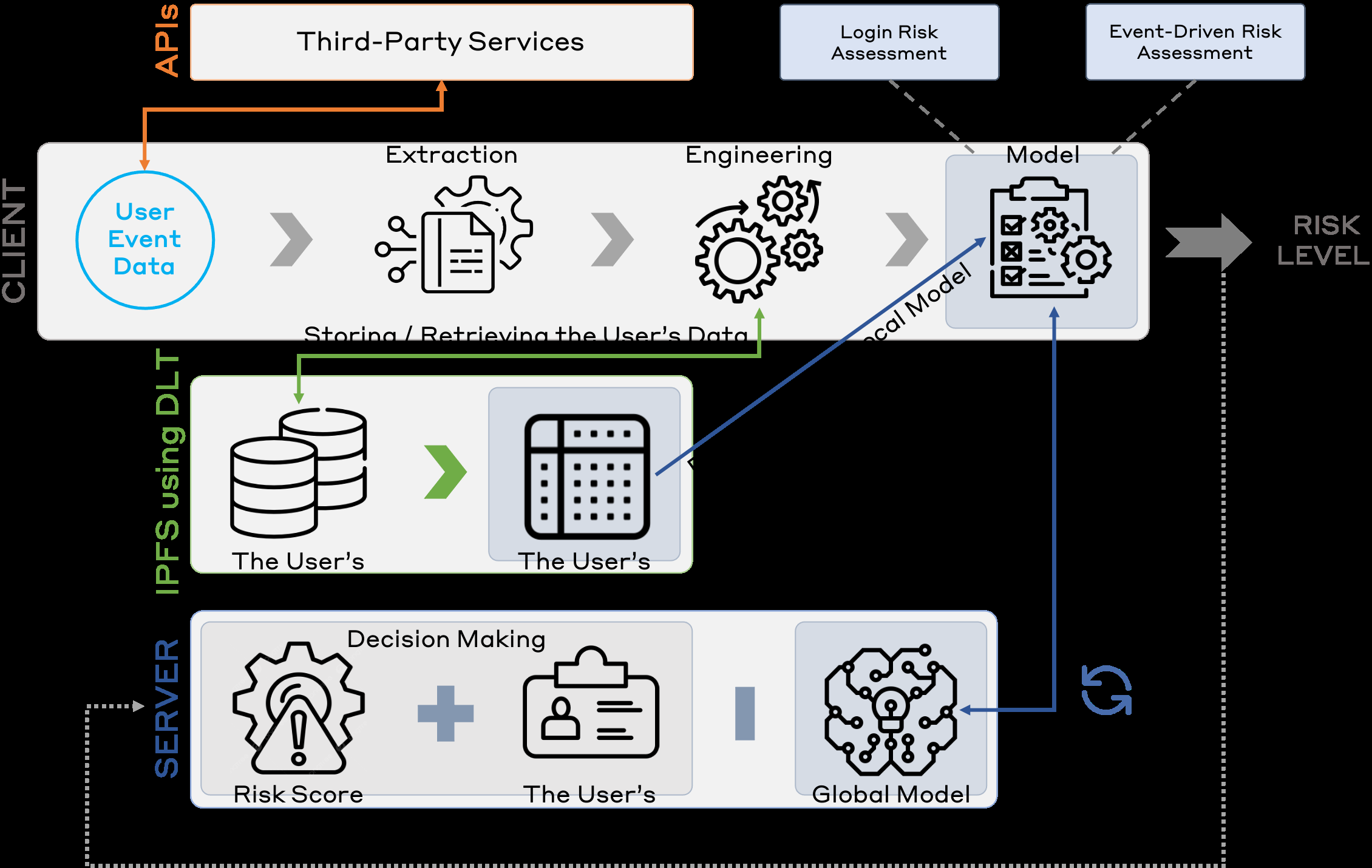
Fig 2: The Risk Assessment Workflow
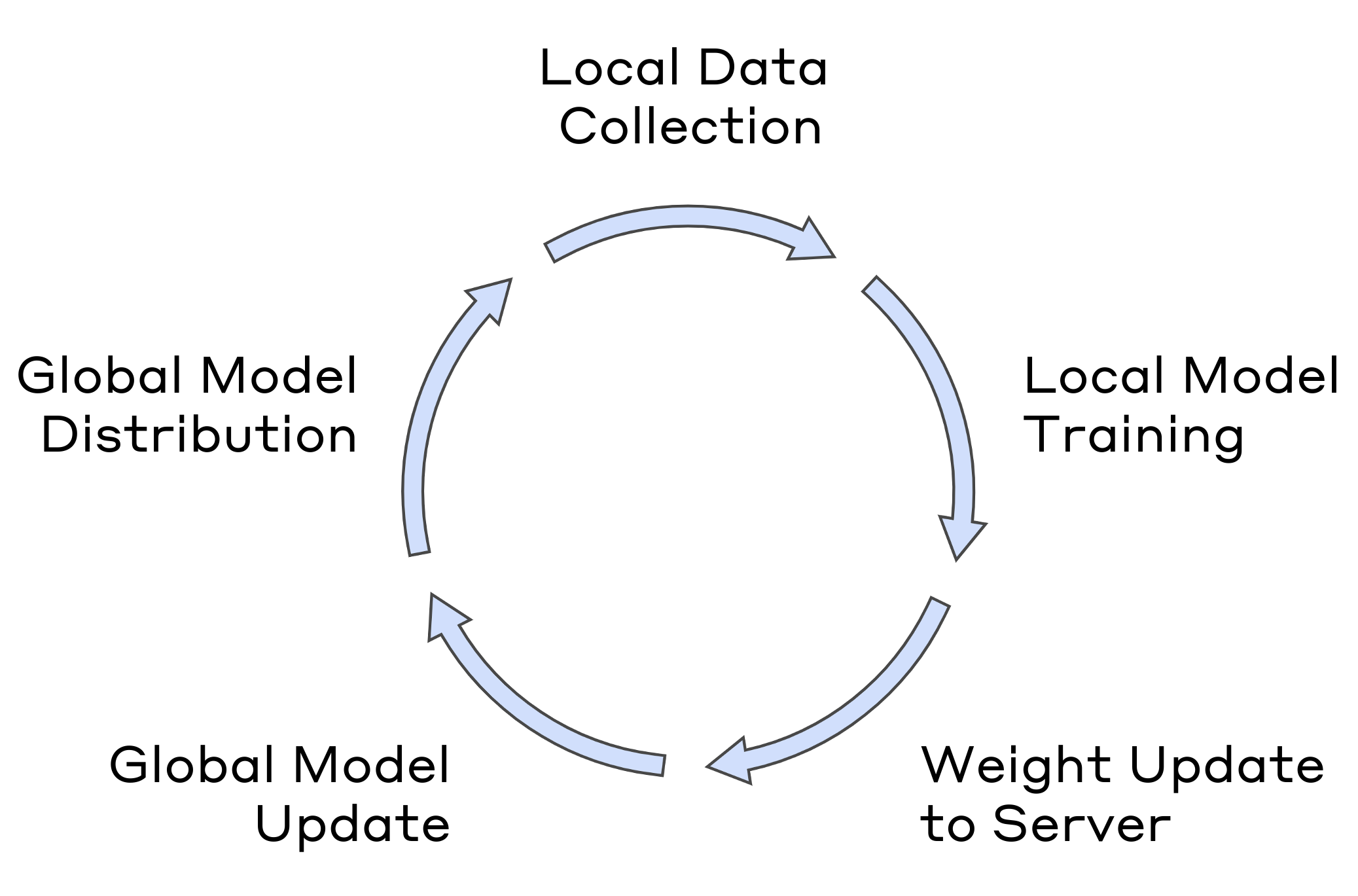
Fig 3: Local Model Update Cycle
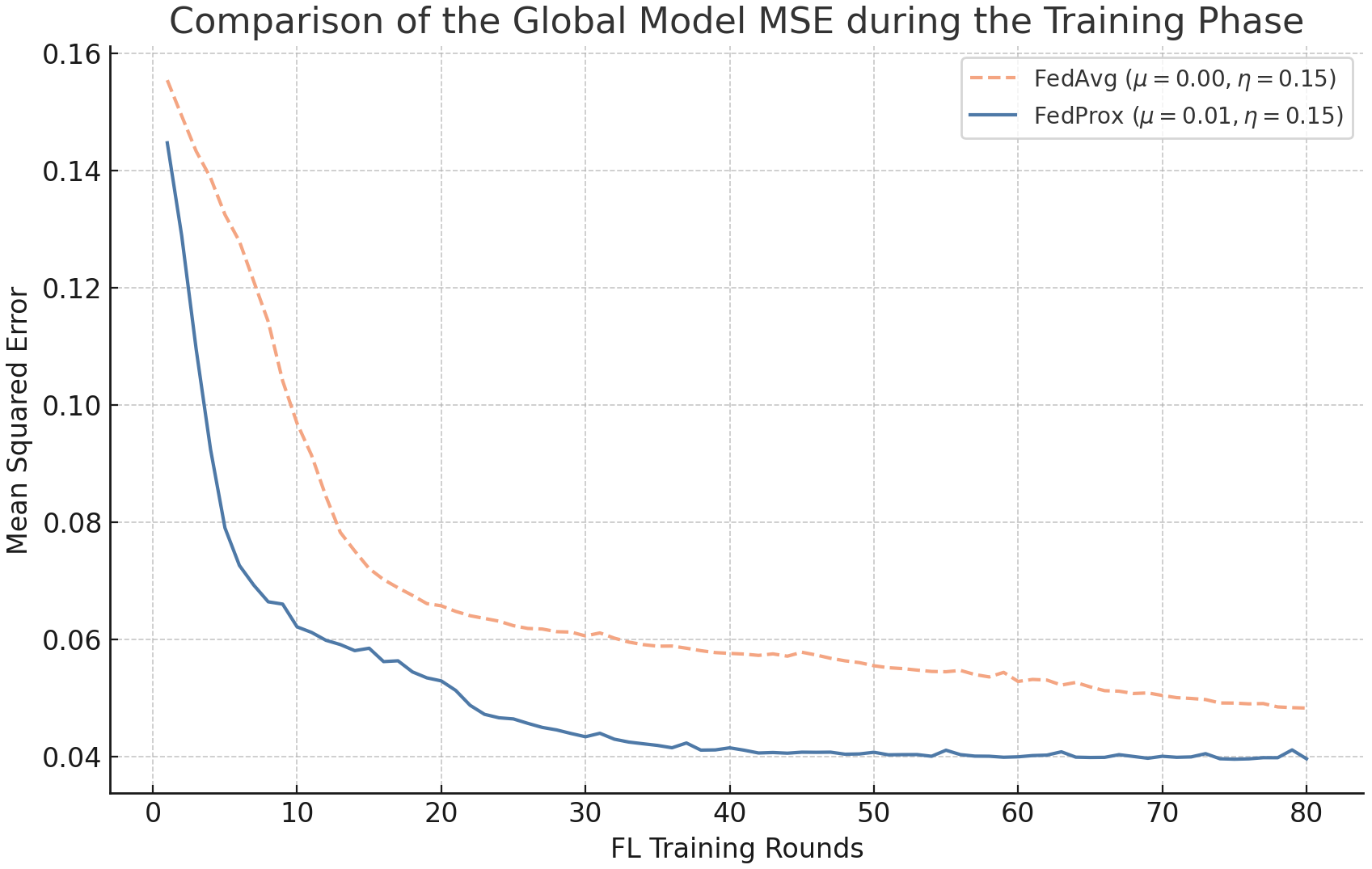
Fig 4: Mean Squared Error (MSE) with Different µ
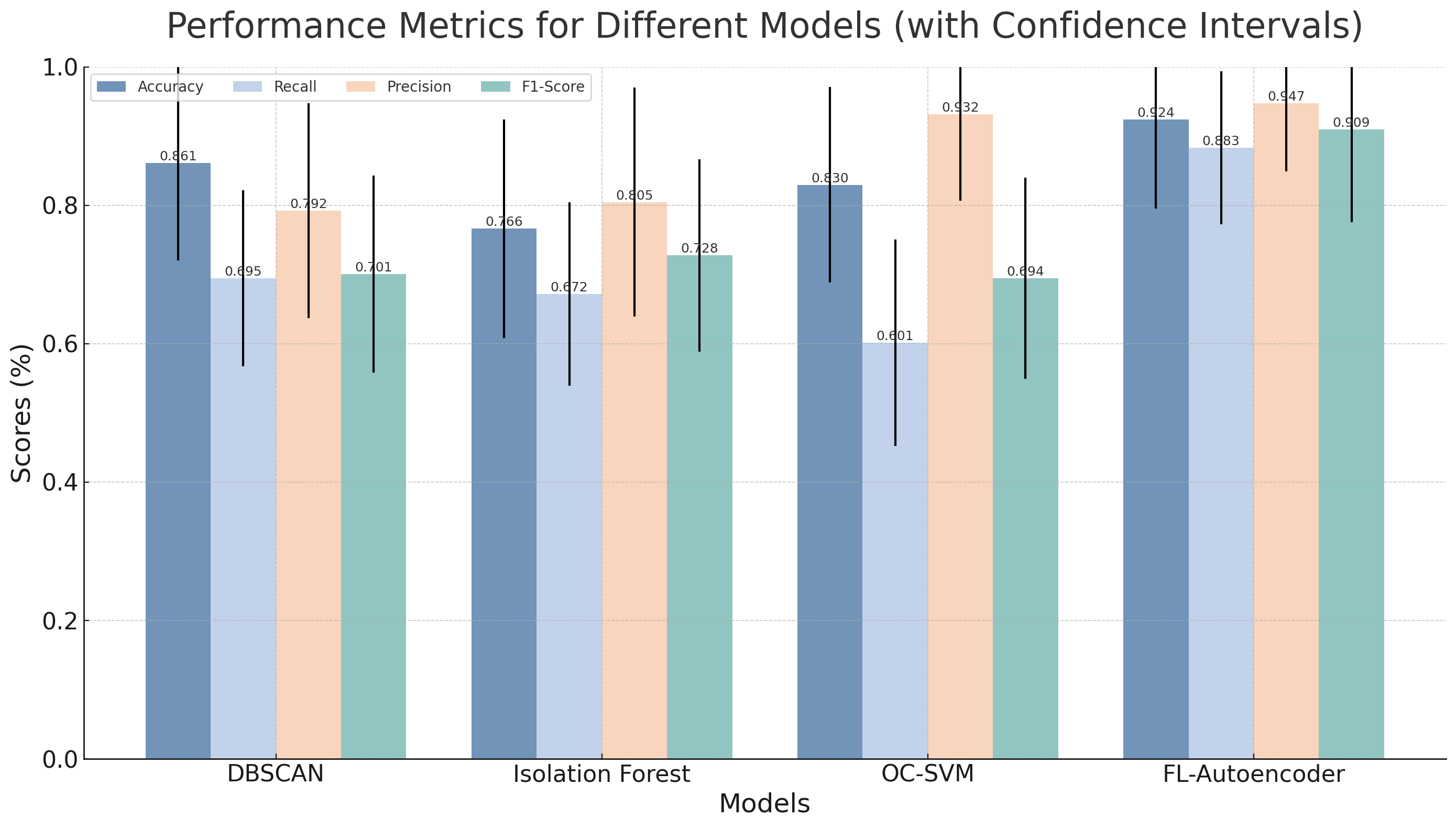
Fig 5: Comparative Performance Metrics Across Model Variants
Limitations
- Dataset size, exact data splits, and labeling methodology are not fully detailed, limiting reproducibility and generalizability assessment.
- No quantitative evaluation of false positive rate or overall authentication system usability impact is presented.
- Security evaluation is limited to performance metrics; adversarial robustness against adaptive attackers (e.g., mimicry attacks) is not tested.
- Assumes reliable and secure third-party APIs, IPFS, and DLT infrastructure without discussing potential attacks or failures in these components.
- Model training hyperparameters, hardware specs, and experimental seeds are unspecified, hindering reproducibility.
- No public code or dataset release to facilitate independent validation.
Open questions / follow-ons
- How does F-RBA perform under adversarial attacks, such as model poisoning or evasion during risk assessment?
- What is the trade-off between detection accuracy and false positive rates in large-scale deployments?
- How does the system handle user privacy in the context of sharing model updates combined with DLT-based metadata?
- Can the approach extend to continuous authentication beyond login attempts, e.g., behavioral biometrics integration?
Why it matters for bot defense
From a bot-defense and CAPTCHA perspective, F-RBA provides a promising privacy-preserving risk assessment model that performs anomaly detection locally on user devices while collectively improving model accuracy through federated learning. This enables the deployment of adaptive challenges with minimized user friction and strong privacy guarantees, mitigating risks from credential theft and session hijacking.
The similarity-based feature engineering approach accommodating heterogeneous client data distributions is particularly relevant for reducing false positives in diverse bot detection environments. Moreover, the decentralized architecture and cross-device synchronization via IPFS and blockchain offer novel ways to maintain persistent user risk profiles without centralized data collection, a major privacy advantage in large-scale bot mitigation systems where centralized data pooling is often infeasible or risky. However, the approach needs further validation against adversarial attacks common in bot scenarios, as well as integration with existing CAPTCHA risk engines for practical deployment.
Cite
@article{arxiv2412_12324,
title={ F-RBA: A Federated Learning-based Framework for Risk-based Authentication },
author={ Hamidreza Fereidouni and Abdelhakim Senhaji Hafid and Dimitrios Makrakis and Yaser Baseri },
journal={arXiv preprint arXiv:2412.12324},
year={ 2024 },
url={https://arxiv.org/abs/2412.12324}
}