
AI and the Future of Digital Public Squares
Source: arXiv:2412.09988 · Published 2024-12-13 · By Beth Goldberg, Diana Acosta-Navas, Michiel Bakker, Ian Beacock, Matt Botvinick, Prateek Buch et al.
TL;DR
This position paper, produced by a large multidisciplinary team spanning Google/Jigsaw, Google DeepMind, MIT, Yale, Georgetown, Reddit, and multiple civil society organizations, argues that LLMs represent a second inflection point for the digital public square — the first being the internet itself. The paper is structured around a convening of over 70 experts held in New York City on April 3, 2024, and synthesizes applied research and normative theory to map both the promise and peril of AI-augmented civic infrastructure. It is explicitly a position and research-agenda paper, not an empirical study, though it cites and summarizes a substantial body of empirical work from others.
The paper organizes its analysis around four functional domains: Collective Dialogue Systems (CDS) such as Polis, Remesh, and Make.org; Bridging Systems that algorithmically surface cross-partisan common ground (e.g., X/Twitter Community Notes, Reddit's Bridgy algorithm); Community-Driven Moderation that shifts governance from platform-centric to community-centric models; and Proof-of-Humanity systems that attempt to distinguish human from AI-generated participation at scale. For each domain, the authors catalog current limitations, enumerate specific LLM-enabled opportunities, and identify attendant risks — covering hallucination, manipulation, centralization of power, erosion of privacy, and the chilling effect of surveillance.
The paper's core argument is that LLMs can reduce the human-labor and expertise bottlenecks that have kept participatory democracy technologies expensive and rare, while simultaneously introducing new attack surfaces: synthetic astroturfing at scale, LLM-mediated homogenization of opinion, and the risk that proof-of-humanity mechanisms become coercive identity-verification regimes. The authors stop short of endorsing any single technical solution and instead issue a research and policy agenda calling for open datasets, interoperable tooling, adversarial red-teaming of civic AI, and governance frameworks that keep humans meaningfully in the loop.
Key findings
- Polis engagements have involved tens of thousands of participants submitting thousands of statements and millions of votes (citing the 'Aufstehen Case Study' 2018), yet fully interpreting these outputs currently requires dozens of hours of skilled human labor per dialogue — a bottleneck the authors argue LLMs can materially reduce.
- Vote prediction in CDS settings using pure LLM prompting has been demonstrated to be 'well calibrated' but is computationally expensive at scale; hybrid LLM-latent factor models (Konya et al. 2022) show 'significantly improved performance characteristics,' though exact accuracy figures are not reported in the truncated text.
- Google DeepMind's Bakker et al. (2022) fine-tuned language models combined with preference aggregation found common ground among individuals with diverse perspectives; follow-on work by Tessler et al. (2024) showed iterative LLM-synthesized 'group statements' refined with participant feedback can maximize participant endorsement on controversial topics.
- Fish et al. (2023) proposed 'generative social choice' as a framework combining LLMs with social choice theory to produce a representative slate of statements from a heterogeneous population — a direct analogue to statistical sampling applied to qualitative deliberation.
- The X/Twitter Community Notes bridging algorithm decomposes note ratings into a global intercept, a rater helpfulness factor, and a low-dimensional factor model capturing ideological alignment; notes score highly only when they receive positive ratings across ideological lines, making coordinated same-faction manipulation structurally difficult.
- A systematic review (Lorenz-Spreen et al. 2023) cited by the authors found that greater digital media use correlates with greater political knowledge and participation internationally, but also with greater polarization — framing the dual-use tension that runs through the entire paper.
- The authors identify that engagement-optimized algorithms can be dominated by small groups of extreme users 'willing to engage more, crowding out the vast majority of more moderate participants' (citing Gillespie 2018; Cunningham et al. 2024), with perceived polarization exceeding actual polarization (Lees and Cikara 2021).
- Proof-of-humanity systems are identified as facing a fundamental trilemma among privacy, free speech/pseudonymity, and authenticity verification — no existing system is described as resolving all three simultaneously, and the paper treats this as an open research problem.
Threat model
The adversary space is heterogeneous and multi-actor. State and non-state political actors are assumed to conduct mass surveillance, targeted advertising, and coordinated inauthentic behavior to manipulate public opinion and suppress dissent. Bot operators and AI-augmented influence operations are assumed capable of generating synthetic participation in CDS at scale, potentially outvoting or drowning out authentic human contributors. Extremist groups are modeled as using platform affordances for radicalization and recruitment. Platform operators themselves are treated as a structural adversary whose engagement-optimization incentives are misaligned with democratic health, even absent malicious intent. The adversary is assumed to have access to the same frontier LLM capabilities as defenders — the paper explicitly warns that LLMs lower the cost of generating persuasive synthetic content, coordinated astroturfing, and personalized manipulation. What the adversary cannot do is not formally specified; the paper does not define capability ceilings or distinguish between nation-state and low-resource threat actors.
Methodology — deep read
This paper is a position/agenda paper, not a primary empirical study. Its methodology is best described as structured expert synthesis combined with literature review. The authors convened over 70 civil society experts and technologists on April 3, 2024, in New York City, though the paper does not describe the selection criteria for these participants, the structured elicitation methods used during the convening (e.g., whether a CDS tool was itself used), or how disagreements among experts were resolved. This is a notable methodological gap for a paper advocating rigorous participatory methods.
The threat model implicit throughout the paper is broad and multi-actor: adversaries include state and non-state political actors conducting surveillance and targeted manipulation, extremist groups using digital platforms for radicalization and recruitment, bot operators generating synthetic public opinion at scale, and well-resourced platform operators whose engagement-optimization incentives are structurally misaligned with democratic health. The adversary is assumed to have access to the same LLM capabilities as defenders, creating an arms-race dynamic that the paper acknowledges but does not fully model. The paper does not assume a single, fixed adversary capability level — it treats the threat landscape as evolving.
For each of the four domains (CDS, Bridging, Community Moderation, Proof-of-Humanity), the authors follow a consistent structure: (1) describe the current state of the art and its limitations, (2) enumerate LLM-specific opportunities, (3) catalog risks introduced by LLM integration, and (4) issue recommendations. This structure is applied descriptively rather than through formal comparative analysis. The paper draws heavily on cited external empirical work — Bakker et al. (2022), Tessler et al. (2024), Fish et al. (2023), Konya et al. (2022, 2023), Small et al. (2021) — but does not re-analyze their data or conduct meta-analysis.
The bridging systems section provides the most technically concrete methodology discussion. The X Community Notes algorithm is described (and illustrated in Fig 3) as decomposing note ratings into a global intercept term, a rater-specific helpfulness factor, and a low-dimensional ideological factor model — a matrix factorization approach structurally similar to collaborative filtering. The key design insight is that a note achieves high score only when positively rated across ideological subgroups, not just within one faction. The paper cites this as empirically reducing partisan capture of the moderation signal, though it does not report specific manipulation-resistance metrics.
The community moderation section references a multi-level governance model (illustrated in Fig 4, attributed to Jhaver, Frey, and Zhang) distinguishing platform-level, community-level, and user-level governance layers, and discusses Reddit's moderator tooling as a case study. The paper describes LLM applications for automating rule drafting, flagging borderline content for human review, and generating plain-language explanations of moderation decisions — but again cites these as opportunities rather than reporting evaluated implementations.
Reproducibility is not applicable in the traditional sense for a position paper, but the paper explicitly calls for the creation of open CDS datasets, open toolboxes for elicitation inference, and shared benchmarks — implicitly acknowledging that current reproducibility in this space is poor. No code, weights, or datasets are released by the authors themselves.
Technical innovations
- The paper synthesizes and extends the concept of 'elicitation inference' in CDS platforms — predicting how participants would have voted on statements they did not see — and proposes hybrid LLM-latent factor models (building on Konya et al. 2022) as a more scalable alternative to pure-LLM prompting approaches (Fish et al. 2023), which are accurate but computationally prohibitive at scale.
- The paper introduces a structured taxonomy of LLM integration points across the full CDS lifecycle (Fig 2: seven discrete stages from participant recruitment through post-deliberation synthesis), which is novel as a design framework even if individual components have precedents.
- The authors propose extending GATE and STaR-GATE (Andukuri et al. 2024) — tools designed for clarifying-question generation with a single user — to multi-participant CDS contexts, enabling personalized follow-up prompting calibrated to an individual's position within the collective opinion landscape.
- The paper frames 'bridging-based comment routing' as a real-time personalization mechanism: using a participant's voting history and demographic context within a CDS to generate individually tailored follow-up prompts that expose them to cross-partisan common ground, distinct from prior static bridging approaches.
- The proof-of-humanity section articulates a three-way trilemma (privacy vs. free speech/pseudonymity vs. authenticity) as a formal design constraint for bot-defense systems in civic contexts, providing a normative framework that is absent from most purely technical bot-detection literature.
Datasets
- Polis engagement data ('Aufstehen Case Study' 2018) — tens of thousands of participants, thousands of statements, millions of votes — non-public, referenced but not released
- Community Notes (X/Twitter) — public rating data used by the bridging algorithm — partially public via X data access programs
- Policy Synth automated web research outputs (GovLab / Citizens Foundation, Bjarnason et al. 2024) — size unspecified — non-public
Baselines vs proposed
- Pure LLM prompting for CDS vote prediction (Fish et al. 2023): described as 'well calibrated' but 'expensive for larger datasets' vs. hybrid LLM-latent factor model (Konya et al. 2022): 'significantly improved performance characteristics' — exact accuracy figures not reported in available text
- Traditional human-only CDS facilitation and analysis: described as requiring 'dozens of hours of labor per dialogue' vs. LLM-augmented pipeline: qualitative improvement claimed, no quantitative benchmark reported
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2412.09988.
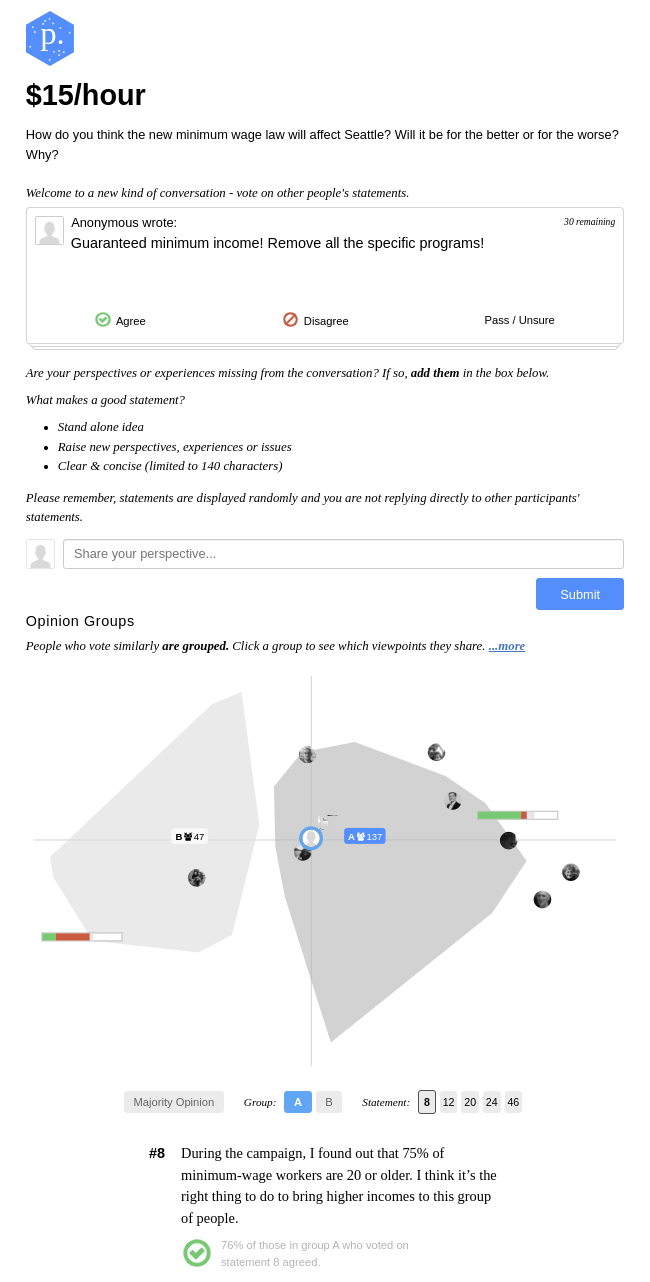
Fig 1: The participation interface for a demonstrative Polis conversation. The figure shows a conversation

Fig 2: Illustrative overview of a collective dialogue system. While CDSes may extend before and after the seven
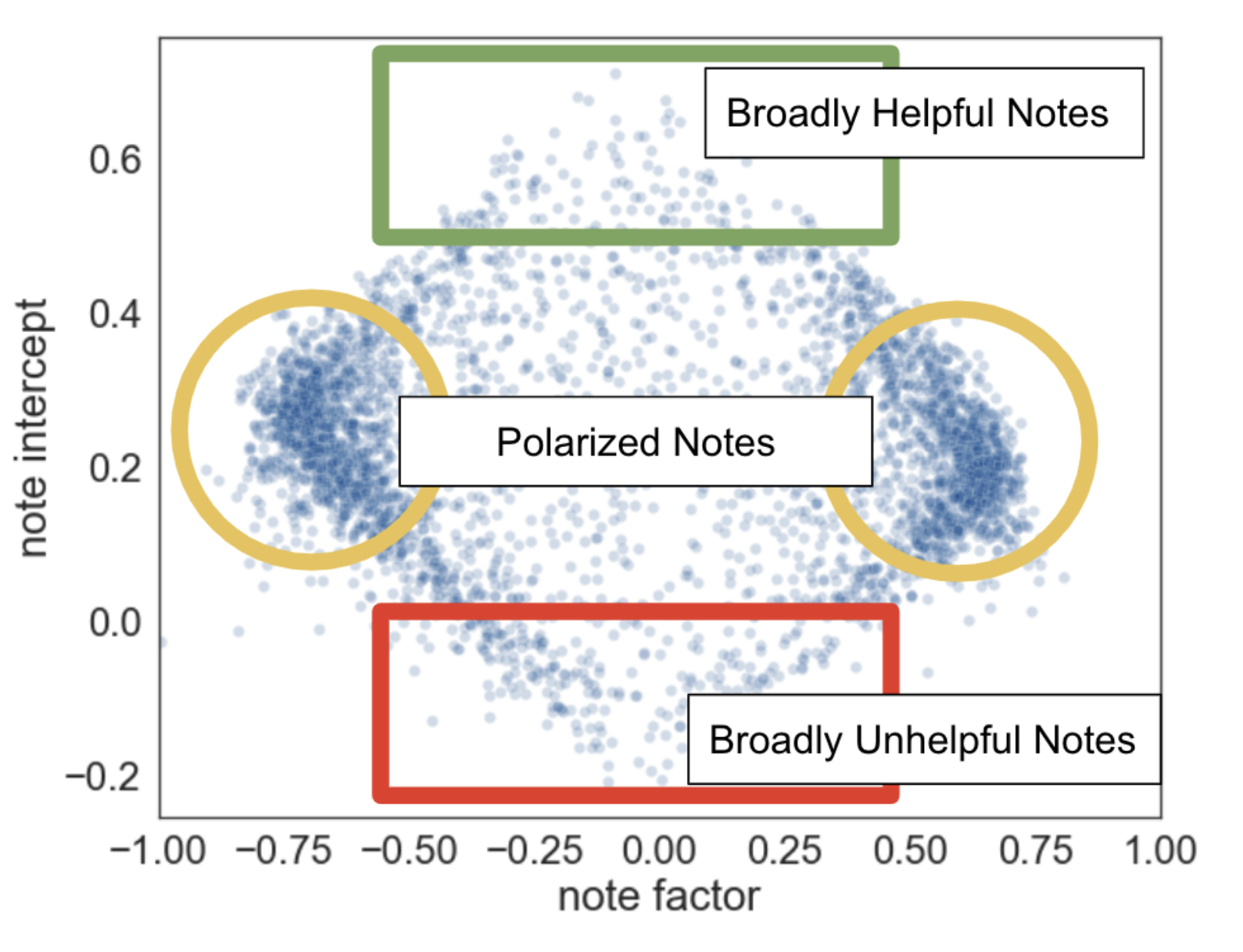
Fig 3: This diagram illustrates how the X Community Notes algorithm works. Note ratings are decomposed into
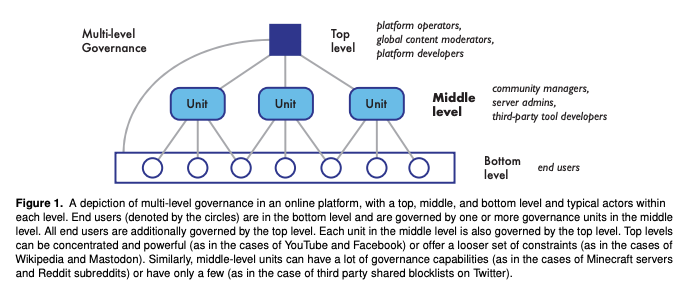
Fig 4: A simplified illustration from Jhaver, Frey, and Zhang of multi-level governance of an online
Limitations
- No primary empirical data is collected or re-analyzed by the authors; all quantitative claims derive from cited third-party studies with heterogeneous methodologies, making it impossible to assess effect sizes or generalizability from this paper alone.
- The expert convening methodology is underdescribed: selection criteria for the 70+ participants, facilitation methods, whether consensus was sought or disagreements documented, and how expert input was weighted against the literature are all opaque.
- The paper does not seriously engage with adversarial evaluation of any proposed LLM application — e.g., how a well-resourced actor would game LLM-assisted summarization to bias perceived consensus, or how prompt injection attacks might subvert AI-mediated facilitation in a live CDS.
- Proof-of-humanity coverage is thin on technical specifics: existing approaches (World ID/Worldcoin biometrics, OpenAI's device-signal-based attestation, behavioral biometrics) are mentioned but not comparatively evaluated on the privacy-authenticity-speech tradeoff the paper claims is central.
- The paper treats LLM capabilities as relatively uniform and improving monotonically, without accounting for the significant variation in performance across languages, cultural contexts, and low-resource settings — directly relevant given the paper's stated concern for marginalized and non-English-speaking communities.
- Conflict of interest is not formally disclosed: multiple authors are employed by Jigsaw (Google), Google DeepMind, and Reddit — organizations with direct commercial and reputational stakes in the tools and platforms discussed. The paper does not acknowledge this limitation.
Open questions / follow-ons
- How can elicitation inference (vote prediction for unvoted statements) be made robust to adversarial manipulation, where a coordinated group strategically votes on a subset of statements to bias the inferred votes of others — and what is the minimum detectable attack size?
- What is the empirical effect of LLM-generated 'group statements' or summaries on participant belief updating versus authentic peer-generated statements? Is there a homogenization effect where LLM synthesis narrows the expressed opinion distribution relative to the true underlying distribution?
- Can a proof-of-humanity system be designed that provides meaningful bot-exclusion guarantees without requiring biometric enrollment or persistent identity linkage — and what formal privacy model (e.g., differential privacy, zero-knowledge proofs) would be required to make such guarantees credible?
- How do bridging-based ranking algorithms perform under coordinated same-faction manipulation at scale, and is the matrix-factorization-based approach used by Community Notes robust to adversaries who recruit ideologically diverse but coordinated rater pools?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the most directly relevant section is the proof-of-humanity discussion, which frames the problem the industry works on as one component of a broader civic infrastructure challenge. The paper's trilemma — privacy vs. pseudonymity vs. authenticity — maps precisely onto the design tensions in modern bot-defense: passive signals and behavioral biometrics preserve anonymity but are increasingly defeatable by headless browsers and AI-driven behavior simulation; biometric enrollment (e.g., Worldcoin's iris scanning) provides strong humanity guarantees but is a privacy and civil liberties red flag at scale. The paper does not resolve this trilemma but usefully positions it as a first-class design constraint rather than a secondary concern, which should inform how bot-defense teams communicate tradeoffs to product and policy stakeholders.
The CDS elicitation inference problem — predicting how a participant would have voted based on partial observation — is structurally analogous to bot-detection problems where a defender must infer whether an account is human based on incomplete behavioral signals. The hybrid LLM-latent factor approach described (Konya et al. 2022) is worth examining as a modeling pattern. More practically, the paper's warning that LLMs dramatically lower the cost of generating synthetic public input — indistinguishable in surface form from authentic human contributions — should be treated as a direct threat-landscape update for any system that relies on text-based signals (comment content, survey responses, review text) as part of its authenticity signal. The paper implies, without stating explicitly, that text-based humanity signals are becoming rapidly less reliable, which shifts the defense burden toward behavioral, temporal, and network-graph signals that are harder for LLM-powered bots to fake convincingly.
Cite
@article{arxiv2412_09988,
title={ AI and the Future of Digital Public Squares },
author={ Beth Goldberg and Diana Acosta-Navas and Michiel Bakker and Ian Beacock and Matt Botvinick and Prateek Buch and Renée DiResta and Nandika Donthi and Nathanael Fast and Ravi Iyer and Zaria Jalan and Andrew Konya and Grace Kwak Danciu and Hélène Landemore and Alice Marwick and Carl Miller and Aviv Ovadya and Emily Saltz and Lisa Schirch and Dalit Shalom and Divya Siddarth and Felix Sieker and Christopher Small and Jonathan Stray and Audrey Tang and Michael Henry Tessler and Amy Zhang },
journal={arXiv preprint arXiv:2412.09988},
year={ 2024 },
url={https://arxiv.org/abs/2412.09988}
}