
Multi-task CNN Behavioral Embedding Model For Transaction Fraud Detection
Source: arXiv:2411.19457 · Published 2024-11-29 · By Bo Qu, Zhurong Wang, Minghao Gu, Daisuke Yagi, Yang Zhao, Yinan Shan et al.
TL;DR
This paper tackles transaction fraud detection from a behavioral-sequence embedding angle rather than a pure tabular modeling angle. The core problem is how to encode user browsing sequences for downstream fraud classifiers while staying efficient enough for real-world e-commerce deployment, where transformers can be too heavy and single-task models can miss shared structure across related fraud types. The authors propose MTCNN, a one-layer CNN with multi-range kernels, positional encoding, and multitask training with random loss weighting.
What is new here is less “CNN for time series” in general and more a specific recipe for fraud-oriented sequence embeddings: categorical page/category IDs plus a scaled continuous dwell-time embedding, positional encoding added into the sequence, multi-kernel convolution over the embedded sequence, and hard-parameter-sharing multitask learning with RLW instead of hand-tuned task weights. In two-stage experiments on proprietary e-commerce data, MTCNN is competitive with a customized TST baseline on direct embedding metrics (KS/IV), and when used as an added feature source for a downstream GBM fraud model it consistently improves over the plain MTGBM baseline; compared with the paper’s TST-based features, MTCNN is slightly better on some operating points and worse on others, but uses far fewer parameters (137K vs 384K).
Key findings
- Stage 1 KS/IV: MTCNN beats the customized TST on all three tasks, e.g. Task 1 KS/IV = 53.8/2.014 vs 52.02/1.943; Task 2 = 64.76/2.832 vs 63.54/2.775; Task 3 = 63.33/2.531 vs 62.55/2.457.
- Stage 2 Task 1 PR-AUC improves from 0.5939 (MTGBM) to 0.6044 with MTCNN features, while MTGBM+MTTST reaches 0.6029.
- Stage 2 Task 2 PR-AUC improves from 0.5876 (MTGBM) to 0.5922 with MTCNN features; MTGBM+MTTST is 0.5934, slightly higher on PR-AUC but with lower recall at the reported precision point.
- Stage 2 Task 3 shows the largest gain over the tabular baseline: PR-AUC rises from 0.3179 to 0.3671 with MTCNN features; MTGBM+MTTST reaches 0.4133.
- At the operating point p≈25%, MTCNN increases recall over MTGBM from 87.9% to 89.4% (Task 1), 88.37% to 90.5% (Task 2), and 67.06% to 81.86% (Task 3).
- At the operating point r≈80%, MTCNN raises precision over MTGBM from 40.95% to 48.95% (Task 1), 39.93% to 44.81% (Task 2), and 14.06% to 25.65% (Task 3).
- The proposed sequence model is much smaller than the transformer baseline: 137K parameters for MTCNN vs 384K for MTTST.
- The paper states both fixed and learnable positional encoding performed similarly, suggesting the simpler fixed PE is sufficient for this task, but it does not report a full ablation table for PE, kernel sizes, or RLW.
Threat model
The implicit adversary is a fraudulent user or account operator generating transaction and browsing behavior to evade detection, including fraud modes like financial theft and account takeover. The model assumes access to historical labeled transaction and behavior sequences for training, and that future traffic can be scored online or near-real-time. The paper does not assume the attacker can corrupt training data, inspect model internals, or adapt online to the detector in a formally specified way, and it does not analyze robust evasion or poisoning explicitly.
Methodology — deep read
Threat model and task framing: the paper is not framed as a classical adversarial-ML security paper, but the operational threat is fraud in e-commerce transactions, including financial theft and account takeover. The model consumes user behavior sequences to predict three fraud-related tasks (Task 1/2/3), each labeled binary fraud vs legitimate. The implicit adversary is a fraudulent user or attacker generating behavioral traces that resemble normal browsing while attempting to trigger one or more fraud outcomes. The paper does not define a white-box or adaptive attacker model, nor does it analyze evasion, poisoning, or mimicry explicitly; the relevant assumption is simply that historical labeled transactions exist and the learned model generalizes to future fraud patterns.
Data and preprocessing: the first-stage data are user page-view sequences from an e-commerce website, with each timestep containing three variables: page ID, item category, and page view time. The paper says page ID and category are label-encoded, rare categories are filtered, missing values are assigned a constant, and dwell time is log-normalized as t′ = log(t/1000). All sequences are padded/truncated to a fixed maximum length N, and in the experiments N is set to 100. Table I gives the dataset sizes. Stage 1 train/test totals are 7,588,890 / 4,412,299 with Task 1 fraud counts 29,811 / 12,081, Task 2 fraud counts 16,097 / 6,731, and Task 3 fraud counts 6,561 / 3,014. Stage 2 uses a larger later snapshot: 12,400,377 / 5,350,661 total rows, with fraud counts 99,023 / 31,137; 59,495 / 15,087; and 13,449 / 4,714 for the three tasks. Because legitimate transactions dominate, the authors apply random downsampling of legitimate examples. Stage 2 is explicitly six months after Stage 1, which is important because it makes the downstream evaluation less cherry-picked than a near-temporal holdout.
Model architecture and novelty: the embedding block treats categorical and continuous variables differently. For categorical page/category IDs, the model uses standard embedding lookup tables initialized with Xavier uniform. For the continuous dwell-time feature, it uses a single embedding vector multiplied by the scalar normalized value, i.e. t′ × Et′(0), and concatenates the three per-timestep embeddings into S′i = [Ed(pi); Ed(ci); t′i × Et′(0)]. This is the paper’s “scaling embedding” idea: a continuous feature is represented through a learned basis vector rather than discretized. The model then adds positional encoding to inject sequence order, with two options: fixed sinusoidal PE or a learnable random matrix of the same shape. The paper reports similar results for both, so fixed PE is used in the main experiment. The CNN itself is a single convolutional layer with multiple kernel sizes to capture different behavioral spans; in the main run these are [8, 16, 32, 64], with 50 channels per kernel, batch normalization, max pooling over time, ReLU, then a fully connected layer with dropout 0.5 and a final task-output layer. The key architectural claim is that multi-range kernels let one shallow CNN capture both short and longer local patterns while staying much smaller and more scalable than LSTM/Transformer alternatives.
Multitask learning and optimization: the shared backbone uses hard parameter sharing across the three fraud tasks, with task-specific output heads oi,task = Wtask(o). The authors motivate this by arguing that unauthorized chargebacks, stolen financial information, and account takeovers share useful behavior patterns, so learning a shared embedding should generalize better than single-task training. Losses are weighted using Random Loss Weighting (RLW): at each iteration, task weights are sampled from a normal distribution and softmax-normalized, then used in a weighted sum of cross-entropy losses. The paper’s equations (7)–(9) define this as a dynamic weighting scheme intended to avoid manual tuning and potentially escape local minima. Training details that are explicitly given for the MTCNN stage are: Adam optimizer, learning rate 1e-4, dropout 0.5, kernel sizes [8,16,32,64], channels [50,50,50,50], and fixed PE. The paper does not specify batch size, number of epochs, seed strategy, weight decay, early stopping, or learning-rate schedule, so those are unknown.
Evaluation protocol and a concrete end-to-end example: Stage 1 trains MTCNN and a customized TST on the same multitask supervised labels. The TST baseline uses the original paper’s self-supervised pretraining plus supervised multitask fine-tuning, with 2 transformer layers, 4 attention heads, BatchNorm, GELU, random masking, and geometric-distribution segment lengths; during fine-tuning the authors test several pooling heads and report one-layer CNN pooling as best. Stage 1 evaluates the sequence model outputs using KS and IV. Stage 2 takes the outputs of the trained sequence model as extra features and feeds them into a modified MTGBM with default-ish parameters (learning rate 0.03, max bin 20, max depth 7, 80 leaves, bagging fraction 0.9, feature fraction 0.8). They train three downstream models: MTGBM alone, MTGBM+MTCNN features, and MTGBM+MTTST features. Evaluation on the Universal Control Group (UCG), which is about 10% of the overall test set, uses dollar-amount-weighted PR-AUC and weighted recall at specific precision points. One concrete path is: a user browsing session is padded to length 100; each timestep’s page ID/category are embedded, dwell time is log-scaled and multiplied by an embedding vector, PE is added, the four-kernel CNN produces a shared representation, task heads output fraud scores for Tasks 1–3, and those scores/vectors are then appended to tabular features for MTGBM training. Reproducibility is limited: the dataset is proprietary and cannot be shared; the paper says source code availability depends on internal legal review and audits, and it does not mention frozen checkpoints or an artifact release.
Technical innovations
- A single-layer multi-range CNN for fraud behavior sequences, positioned as a lighter alternative to LSTM and Transformer encoders for multivariate time series.
- A continuous-variable embedding trick that scales a learned embedding vector by the normalized dwell-time value instead of discretizing the feature.
- Adding positional encoding to a CNN sequence encoder to recover order information that plain convolutions may miss.
- Using hard-parameter-sharing multitask learning with Random Loss Weighting to avoid manual task-weight tuning in correlated fraud objectives.
Datasets
- Proprietary e-commerce behavioral sequence dataset — Stage 1: 7,588,890 train / 4,412,299 test; Stage 2: 12,400,377 train / 5,350,661 test — internal company data
- Task 1 fraud labels — Stage 1: 29,811 train / 12,081 test; Stage 2: 99,023 train / 31,137 test — internal company data
- Task 2 fraud labels — Stage 1: 16,097 train / 6,731 test; Stage 2: 59,495 train / 15,087 test — internal company data
- Task 3 fraud labels — Stage 1: 6,561 train / 3,014 test; Stage 2: 13,449 train / 4,714 test — internal company data
Baselines vs proposed
- TST (Stage 1, Task 1): KS/IV = 52.02/1.943 vs proposed MTCNN = 53.8/2.014
- TST (Stage 1, Task 2): KS/IV = 63.54/2.775 vs proposed MTCNN = 64.76/2.832
- TST (Stage 1, Task 3): KS/IV = 62.55/2.457 vs proposed MTCNN = 63.33/2.531
- MTGBM (Stage 2, Task 1): PR-AUC = 0.5939 vs proposed MTGBM+MTCNN = 0.6044
- MTGBM (Stage 2, Task 1): r@p≈25% = 87.9% vs proposed = 89.4%
- MTGBM (Stage 2, Task 1): p@r≈80% = 40.95% vs proposed = 48.95%
- MTGBM (Stage 2, Task 2): PR-AUC = 0.5876 vs proposed MTGBM+MTCNN = 0.5922
- MTGBM (Stage 2, Task 2): r@p≈25% = 88.37% vs proposed = 90.5%
- MTGBM (Stage 2, Task 2): p@r≈80% = 39.93% vs proposed = 44.81%
- MTGBM (Stage 2, Task 3): PR-AUC = 0.3179 vs proposed MTGBM+MTCNN = 0.3671
- MTGBM (Stage 2, Task 3): r@p≈25% = 67.06% vs proposed = 81.86%
- MTGBM (Stage 2, Task 3): p@r≈80% = 14.06% vs proposed = 25.65%
- MTGBM+MTTST (Stage 2, Task 1): PR-AUC = 0.6029 vs proposed MTGBM+MTCNN = 0.6044
- MTGBM+MTTST (Stage 2, Task 2): PR-AUC = 0.5934 vs proposed MTGBM+MTCNN = 0.5922
- MTGBM+MTTST (Stage 2, Task 3): PR-AUC = 0.4133 vs proposed MTGBM+MTCNN = 0.3671
- MTTST parameter size: 384K vs proposed MTCNN = 137K
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2411.19457.
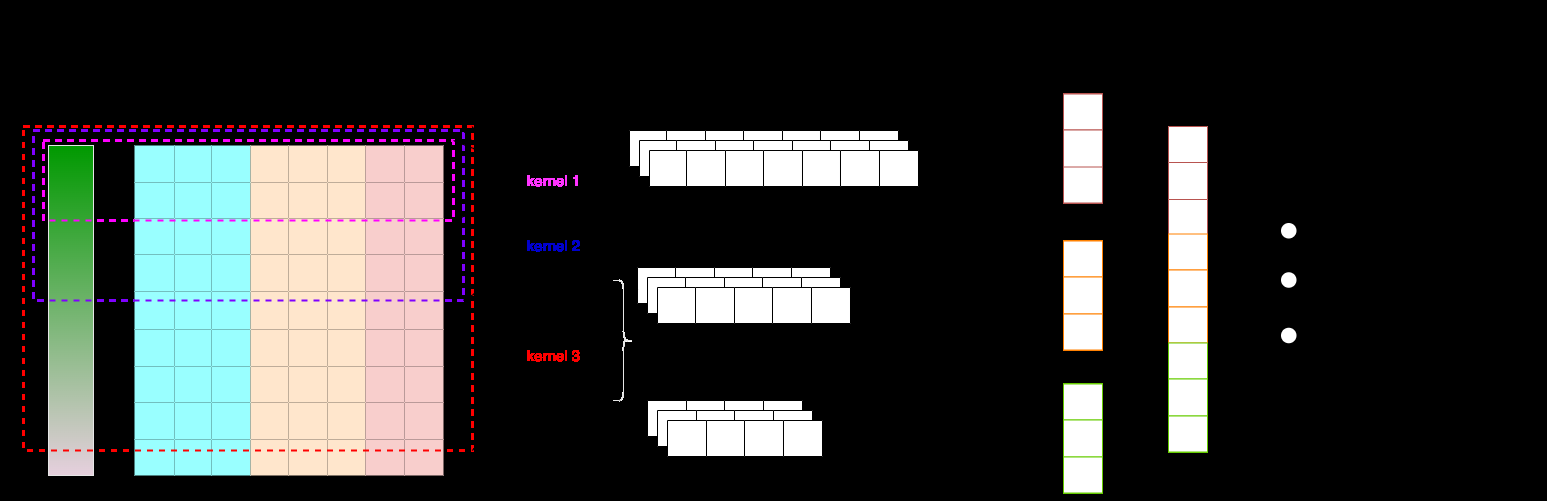
Fig 1: MTCNN model architecture with three channels as example.
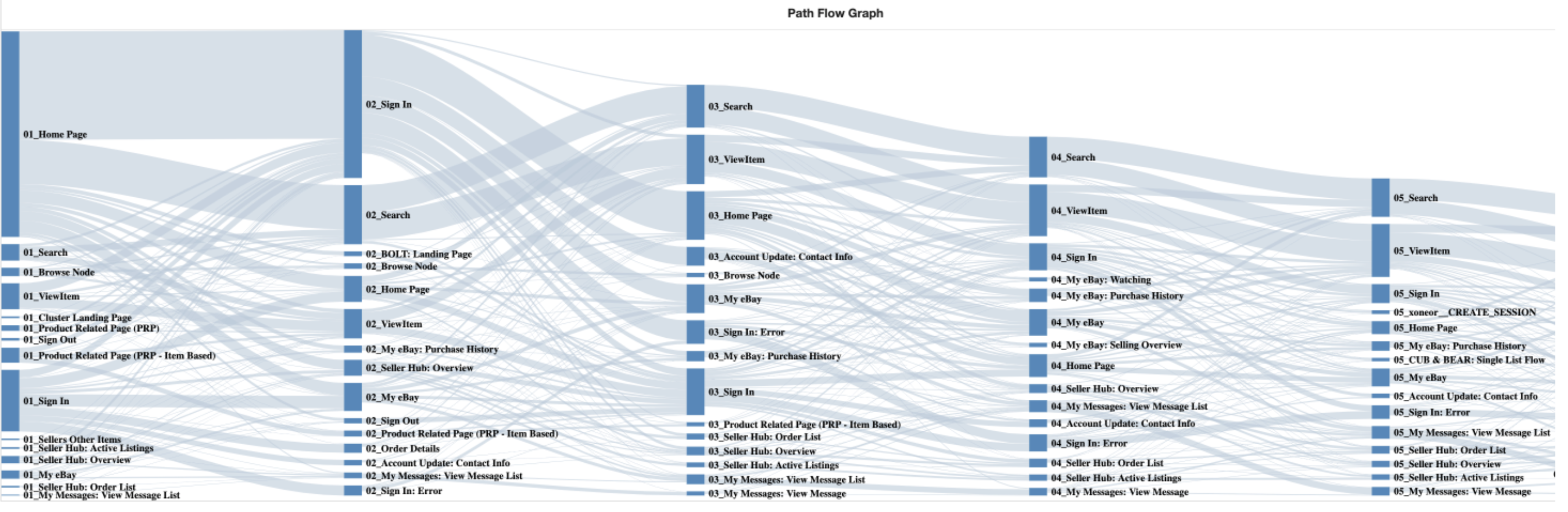
Fig 2: Illustration of user behavior flow of page browsing.
Limitations
- The data are proprietary, so neither the raw dataset nor a public benchmark can be used to independently reproduce the exact results.
- The paper does not report batch size, number of epochs, random seeds, optimizer extras, or confidence intervals, so variance across runs is unknown.
- There is no explicit adaptive-attacker evaluation; the fraud setting is practical, but the model is not stress-tested against evasion or poisoning.
- Stage 2 depends on a custom modified MTGBM implementation, which limits apples-to-apples comparison unless that code is released.
- The paper reports only one set of main hyperparameters and no full ablation table for positional encoding, kernel sizes, RLW, or the continuous embedding trick.
- Some comparisons are mixed: MTCNN is better on certain operating points, but the customized TST is better on Stage 2 PR-AUC for Task 2 and Task 3, so the claim is competitive rather than uniformly superior.
Open questions / follow-ons
- How much of the gain comes from the architecture itself versus the downstream feature-stacking with MTGBM, and would the same features transfer to other fraud classifiers?
- Would the multi-range CNN still win under a true temporal generalization test, e.g. training on one season and testing on a later fraud campaign with stronger drift?
- Does RLW materially help versus fixed equal weights, GradNorm, or uncertainty weighting on this specific multitask fraud setup?
- Can the continuous-variable embedding scheme be extended to richer mixed-type event streams, and does it outperform standard numeric normalization plus linear projection?
Why it matters for bot defense
For bot-defense and fraud pipelines, the main takeaway is that short shallow CNNs can be a strong sequence encoder when you need a compact, deployable model that still captures local behavioral motifs. The paper suggests that positional information matters even for convolutional encoders, which is relevant if your pipeline uses session/page-event histories rather than just aggregated counters. The multtask setup is also interesting operationally: if several fraud labels are correlated, a shared encoder with dynamic task weighting may reduce hand-tuning and improve generalization.
A CAPTCHA or bot-defense engineer would not treat this as a CAPTCHA paper, but the design pattern is transferable: encode event streams, combine categorical and continuous signals in a lightweight representation, and use the sequence model as a feature generator for a downstream risk model. The strongest practical caution is that the results are proprietary and partly downstream-dependent, so you would want to test whether the gains hold on your own traffic and whether the same improvements survive distribution shift, adversarial adaptation, and the latency constraints of your production decision path.
Cite
@article{arxiv2411_19457,
title={ Multi-task CNN Behavioral Embedding Model For Transaction Fraud Detection },
author={ Bo Qu and Zhurong Wang and Minghao Gu and Daisuke Yagi and Yang Zhao and Yinan Shan and Frank Zahradnik },
journal={arXiv preprint arXiv:2411.19457},
year={ 2024 },
url={https://arxiv.org/abs/2411.19457}
}