
TempCharBERT: Keystroke Dynamics for Continuous Access Control Based on Pre-trained Language Models
Source: arXiv:2411.07224 · Published 2024-11-11 · By Matheus Simão, Fabiano Prado, Omar Abdul Wahab, Anderson Avila
TL;DR
TempCharBERT tackles a narrow but important gap in biometrics: how to adapt pre-trained language models to keystroke dynamics, where the signal is not just character identity but timing information such as hold time and flight time. The paper’s core observation is that standard BERT/RoBERTa-style tokenization is the wrong granularity for this problem, and that even character-aware PLMs like CharBERT still ignore temporal typing cues. Their answer is a minimal architectural change: inject temporal features into CharBERT’s character embedding path so the model can learn user-specific typing rhythm alongside character content.
The paper evaluates this on free-text keystroke data from the LSIA dataset and reports large gains over CharBERT and several classic baselines on both user identification and user authentication. In the reported identification setting, TempCharBERT reaches 90.14% accuracy versus 59.26% for CharBERT; for authentication, it reports EER 0.0022 versus 0.0781 for CharBERT. They also show that the learned TempCharBERT embeddings can be reused by an LSTM and that a federated-learning training setup is feasible, with only a modest drop relative to centralized training.
Key findings
- On LSIA user identification, TempCharBERT reports 90.14% accuracy versus 59.26% for CharBERT, a +30.88 point absolute gain.
- On LSIA user authentication, TempCharBERT reports EER = 0.0022 versus 0.0781 for CharBERT, a 35x lower error rate by the paper’s numbers.
- Against an LSTM baseline, TempCharBERT improves identification from 87.50% to 90.14%; against SVM, from 61.10% to 90.14%.
- The Manhattan-distance baseline is weakest in identification at 25.74% accuracy and in authentication at EER = 0.3337.
- The paper reports that LSTMTempCharBERT reaches 93.09% identification accuracy, outperforming the standalone TempCharBERT embedding-only classifier.
- In the federated-learning experiment on identification, TempCharBERT reports 88.16% accuracy versus 61.43% for CharBERT under the same FL regime, indicating the temporal embedding still helps after decentralization.
- The authors state they used 100 clients with sample ratio 0.1 in FL, trained for 5 rounds with 10 users selected per round.
- Figure 4 / t-SNE visualization is used qualitatively to argue that TempCharBERT embeddings cluster by user better than CharBERT embeddings, but no quantitative clustering metric is reported.
Threat model
The implicit adversary is an impostor attempting to impersonate a legitimate user in either authentication or continuous access-control settings by submitting keystroke sequences that should be rejected. The system assumes the defender has enrollment data for each user and can observe timing features such as hold time and flight time; the attacker is not assumed to control the model, but the paper does not formally model adaptive mimicry, replay, or poisoning. In the federated-learning variant, the goal is to reduce raw data centralization, but no explicit protection against malicious clients or inference from updates is analyzed.
Methodology — deep read
Threat model and assumptions: the paper’s implicit adversary is a spoofing or impostor user attempting to pass either one-shot authentication (claimed identity verification) or continuous access control (free-text monitoring after login). The model assumes the attacker may know the system exists and may supply arbitrary keystroke sequences, but the paper does not define an adaptive attacker, mimicry attacker, or replay attacker model in any formal way. The security goal is behavioral discrimination from timing traces, not content understanding. In the federated-learning setting, the authors additionally assume decentralized data ownership is desirable for privacy, but they do not analyze gradient leakage, poisoning, or client compromise.
Data: the experiments use the LSIA dataset from González and Calot (2023), a free-text keystroke dataset with 137 users. Each record includes user ID, key code, hold time, and flight time in milliseconds. The paper says samples per user vary from 4 to 100. The authors explicitly state they only use real-user keystroke dynamics and do not use the synthetic/artificial profiles present in the original dataset. They hold out 20% of the data for testing, but the paper does not describe whether the split is stratified by user, whether sessions are separated to avoid leakage, or whether multiple samples from the same sentence/phrase can appear across train and test. No validation split, cross-validation, or subject-disjoint protocol is described in the excerpt.
Architecture / algorithm: TempCharBERT keeps the overall CharBERT structure but changes the embedding path for the character channel. CharBERT normally has a token/subword channel and a character channel, with token and character representations fused through the transformer and heterogeneous interaction modules. TempCharBERT replaces the pure character input in that channel with a temporal-character encoder that adds dwell time and flight time. The paper gives equations (1)–(6): characters are mapped to embeddings via a character matrix Wc; temporal values are mapped via a temporal embedding matrix Tc; then character and temporal embeddings are summed and passed through a bi-GRU. The final token-level representation is formed by concatenating the first and last hidden states. In other words, the novelty is not a new transformer stack or a new loss, but a keystroke-aware embedding layer that attempts to encode timing at the same granularity as characters. The paper also says the resulting embedding is qualitatively more clustered by user in a t-SNE plot (Fig. 4), implying the representation contains more user-discriminative information than CharBERT’s original embeddings.
Training regime: the model is fine-tuned with batch size 8, Adam optimizer, learning rate 5e-5, for 5 epochs, using BERT-base dimensions (12 layers, 768 hidden units, 12 heads) as the backbone configuration. The paper does not specify warmup, weight decay, dropout settings, seed handling, mixed precision, early stopping, or whether any hyperparameter search was performed. For federated learning, the data are split among 100 clients with sample ratio 0.1; training runs for 5 rounds with 10 users selected per round, and FedAvg is used for aggregation. The authors characterize FL as a privacy-preserving setting, but the paper does not report communication costs or client heterogeneity statistics.
Evaluation protocol: the work reports two tasks. For user identification, the metric is accuracy. For user authentication, the metric is Equal Error Rate (EER), defined as the operating point where FAR equals FRR. Baselines include CharBERT, LSTM, SVM, Manhattan distance, plus two hybrid variants that feed CharBERT or TempCharBERT embeddings into an LSTM (LSTMCharBERT and LSTMTempCharBERT). The paper presents three experiments: identification, authentication, and federated-learning identification. The strongest reported result is that TempCharBERT beats all baselines on both metrics. However, there is no mention of confidence intervals, significance testing, ROC/DET curves, or per-user variance; the conclusions rely on point estimates in Tables I–III. One concrete end-to-end example: a user types a free-text sample; the system extracts each character plus its dwell/flight timings; the temporal-character encoder embeds each char-time pair; the transformer layers produce a user representation; a classifier or distance rule then decides which user it is (identification) or whether the claimed identity matches the template (authentication).
Reproducibility: the paper cites the LSIA dataset and gives optimizer / epoch / batch settings, but it does not indicate code release, frozen checkpoints, or exact preprocessing/tokenization details needed to reproduce CharBERT/TempCharBERT alignment between text tokens and key events. It also does not explain how the character and timing streams are synchronized for free-text inputs when token boundaries do not neatly match key events, which is a crucial implementation detail. The federated-learning setup is described only at a high level, so reproduction of FL results would require guessing client partitioning and round-level sampling details beyond the paper text.
Technical innovations
- Adds dwell time and flight time directly into CharBERT’s character embedding path via a temporal-character encoder instead of treating timing as a post-hoc feature.
- Uses a bi-GRU over summed character and temporal embeddings to produce a token-level representation that preserves both character identity and typing rhythm.
- Shows that the learned embeddings are transferable to another sequence model (LSTM), suggesting the representation is not tied to the transformer classifier head.
- Demonstrates a federated-learning variant with FedAvg for privacy-preserving training on user keystroke data.
Datasets
- LSIA — 137 users; samples per user vary from 4 to 100; 20% held out for testing — González and Calot (2023), real-user subset only
Baselines vs proposed
- CharBERT: identification accuracy = 59.26% vs proposed = 90.14%
- LSTM: identification accuracy = 87.50% vs proposed = 90.14%
- SVM: identification accuracy = 61.10% vs proposed = 90.14%
- Manhattan Distance: identification accuracy = 25.74% vs proposed = 90.14%
- LSTMCharBERT: identification accuracy = 50.62% vs proposed = 90.14%
- LSTMTempCharBERT: identification accuracy = 93.09% vs proposed = 90.14%
- CharBERT: authentication EER = 0.0781 vs proposed = 0.0022
- LSTM: authentication EER = 0.0498 vs proposed = 0.0022
- SVM: authentication EER = 0.0822 vs proposed = 0.0022
- Manhattan: authentication EER = 0.3337 vs proposed = 0.0022
- CharBERT (FL): identification accuracy = 61.43% vs proposed = 88.16%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2411.07224.
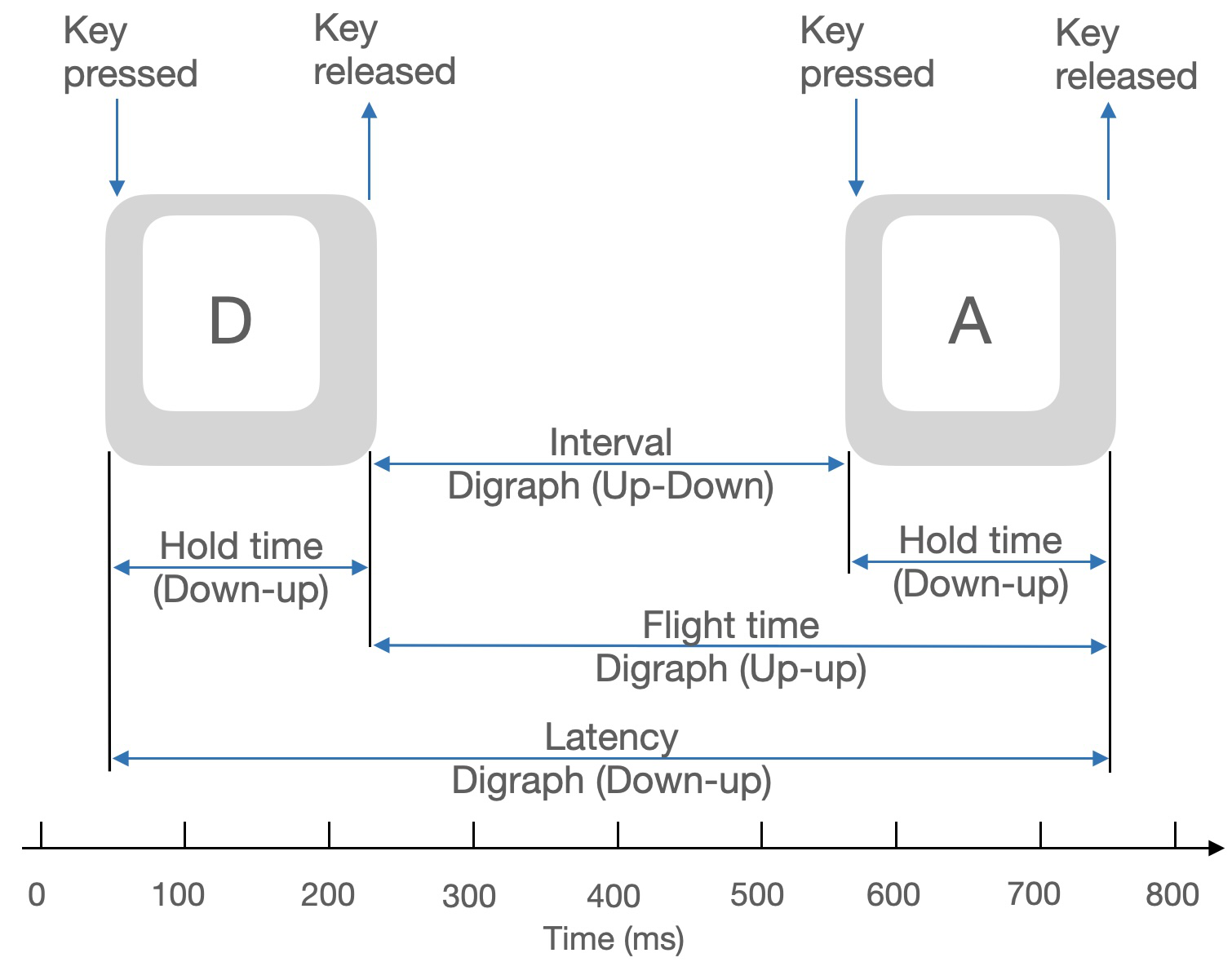
Fig 1: Keystroke metrics based on pressing and releasing
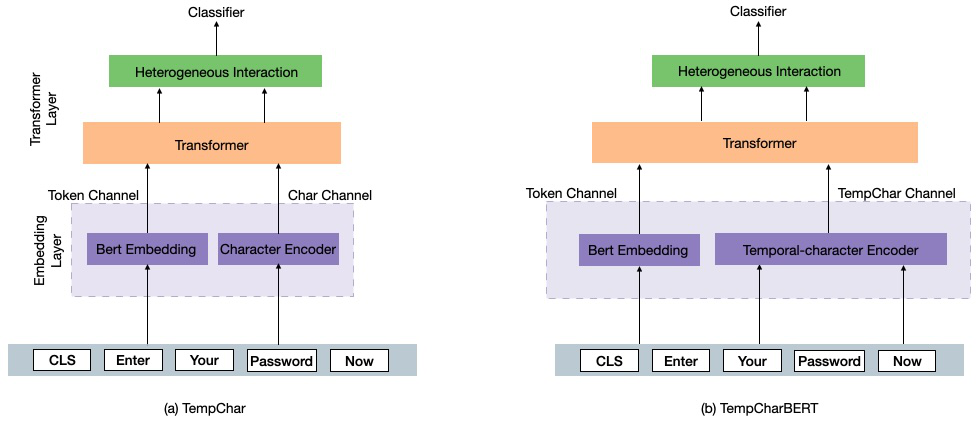
Fig 2: Comparison of the contextual word representation in CharBERT and the TempCharBERT architecture with the proposed
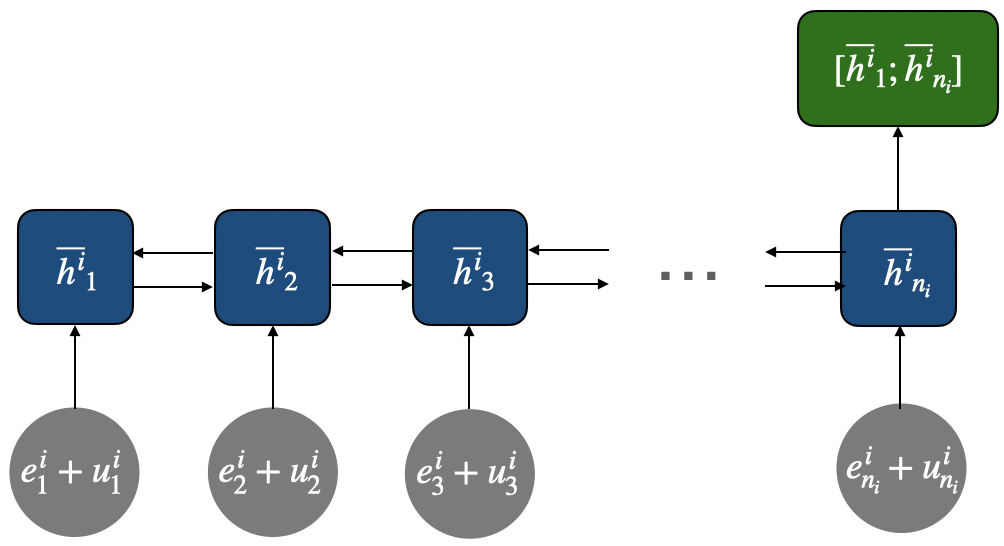
Fig 3: Temporal-character Encoder that captures full word in-
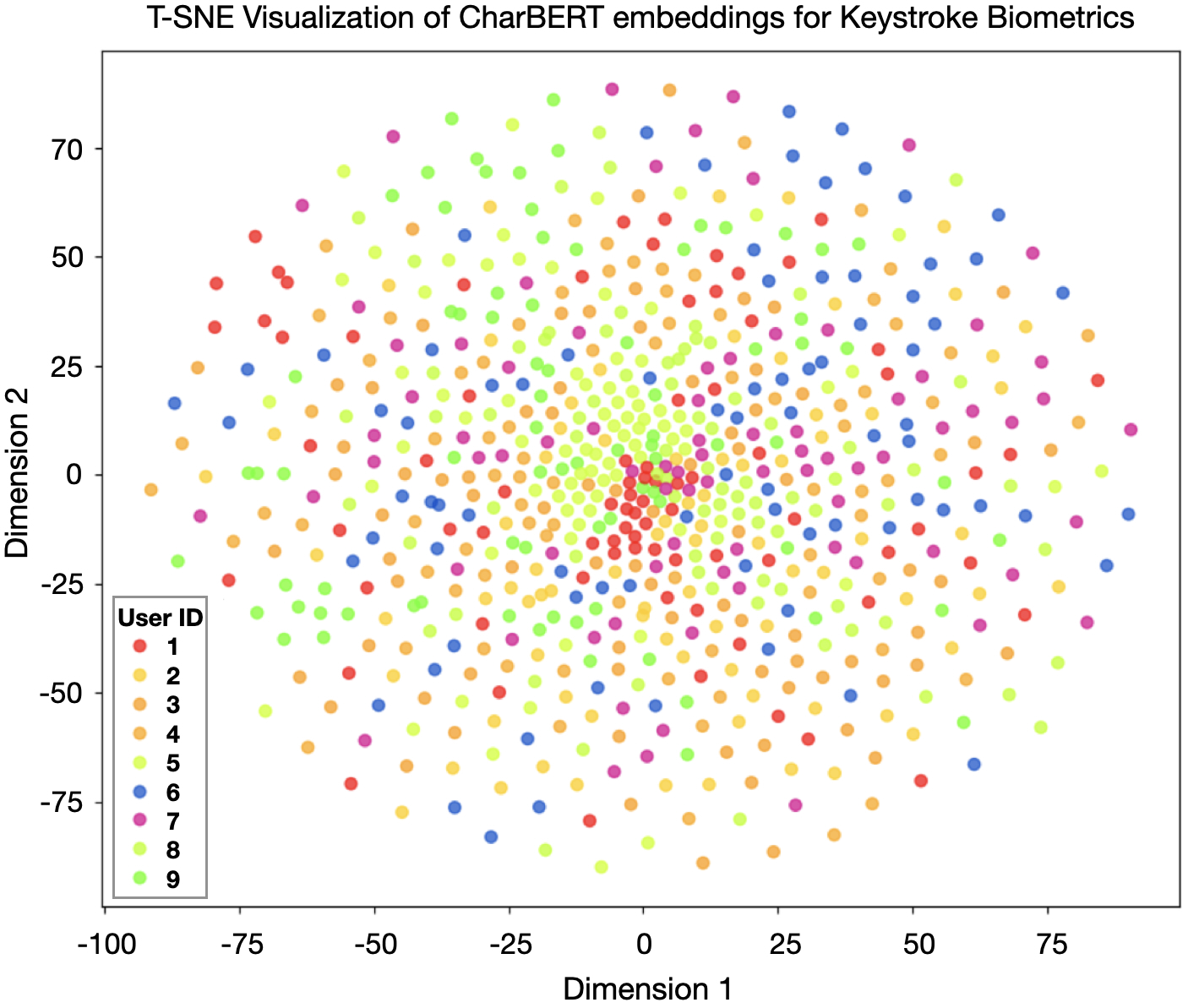
Fig 4: T-SNE visualization of CharBERT embeddings and TempCharBERT embeddings . Temporal keystroke information
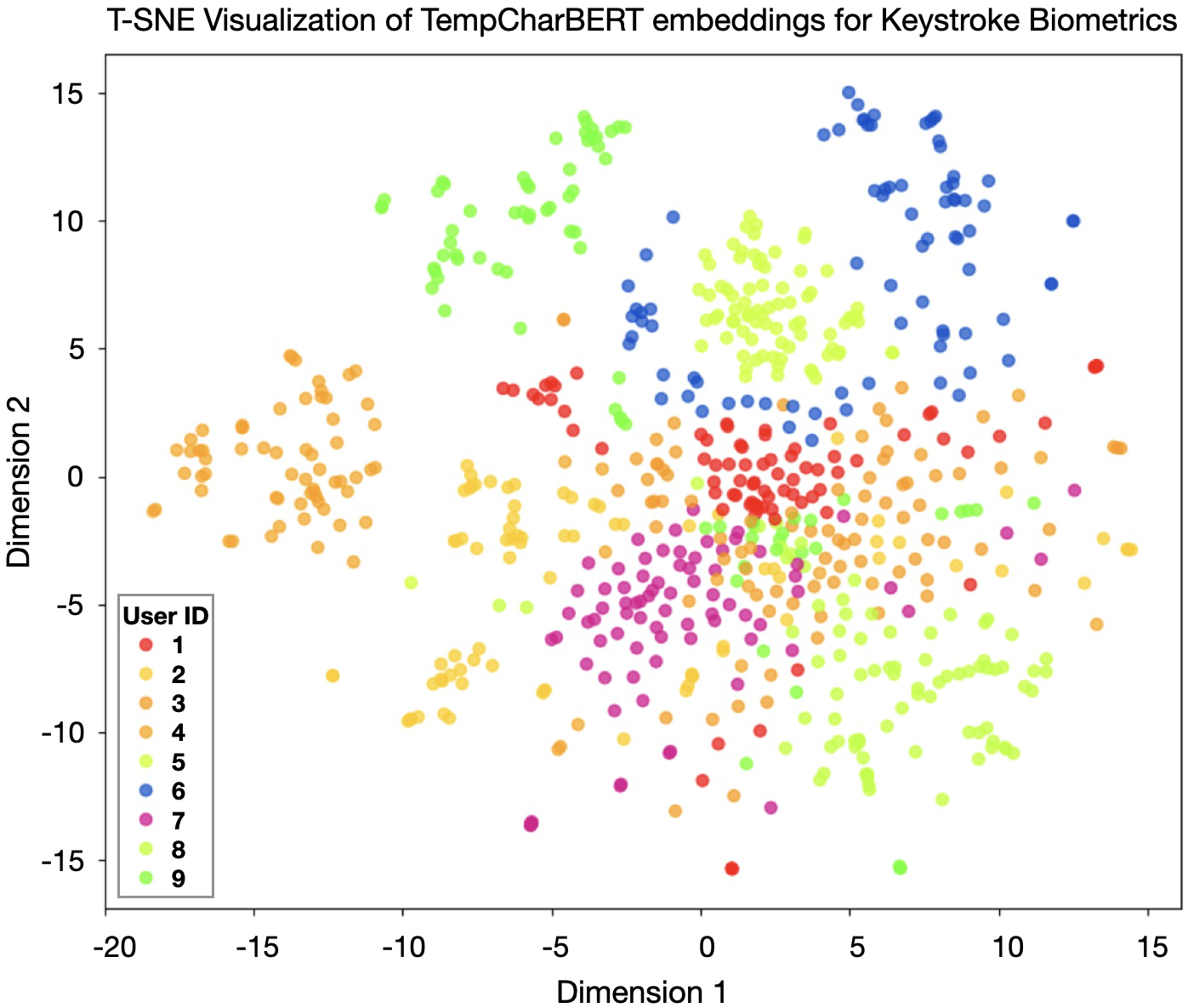
Fig 5 (page 5).
Limitations
- The paper does not provide confidence intervals, standard deviations, or statistical significance tests, so it is hard to tell how stable the reported gains are.
- The train/test protocol is only described as an 80/20 split; it is unclear whether splitting avoided leakage across sessions, sentences, or repeated text patterns.
- Only one dataset is used, and it is a specific free-text keystroke dataset; generalization to other languages, keyboards, mobile input, or fixed-text authentication is untested.
- The federated-learning experiment is brief: only 5 rounds and 10 users per round are reported, with no analysis of communication cost, client imbalance, or robustness to non-IID partitioning.
- The paper does not analyze adversarial mimicry, template theft, replay, or poisoning attacks, so the security claims are about recognition performance rather than attack resistance.
- Implementation details for aligning temporal features to subword/character tokens are not fully specified, which makes faithful reproduction difficult.
Open questions / follow-ons
- Would the temporal-character embedding still help under stricter subject-disjoint or session-disjoint splits, where memorizing user-specific text patterns is harder?
- How sensitive is TempCharBERT to keyboard layout, device type, typing speed drift, and long-term behavioral change?
- Can the temporal encoder be simplified or replaced with a more direct continuous-time module without losing the gains?
- Does federated learning preserve accuracy under stronger non-IID partitions and realistic client dropout?
Why it matters for bot defense
For bot-defense practitioners, the paper is a reminder that timing alone can be a strong biometric signal when it is fused at the representation level rather than appended as a shallow feature. If a product already captures keystroke timings for risk scoring, this work suggests that a character-aware encoder can learn a more discriminative user profile than classical distance-based features or generic sequence models.
The practical caution is that the evaluation here is a single-dataset recognition study, not a robustness study against adaptive attackers or automation tools. A CAPTCHA or continuous-auth system could borrow the embedding idea for higher-friction risk scoring, but it should not assume these gains transfer directly to production without testing for distribution shift, drift, accessibility constraints, and mimicry attacks. The federated-learning result is also relevant: if keystroke biometrics must stay on-device or partitioned by tenant, the paper suggests the representation can survive a decentralized training regime, though the evidence is still preliminary.
Cite
@article{arxiv2411_07224,
title={ TempCharBERT: Keystroke Dynamics for Continuous Access Control Based on Pre-trained Language Models },
author={ Matheus Simão and Fabiano Prado and Omar Abdul Wahab and Anderson Avila },
journal={arXiv preprint arXiv:2411.07224},
year={ 2024 },
url={https://arxiv.org/abs/2411.07224}
}