
A novel TLS-based Fingerprinting approach that combines feature expansion and similarity mapping
Source: arXiv:2410.03817 · Published 2024-10-04 · By Amanda Thomson, Leandros Maglaras, Naghmeh Moradpoor
TL;DR
This paper tackles a practical weakness in active TLS fingerprinting: as TLS 1.3, CDN termination, and ECH reduce observable variation, hash-based fingerprints such as JARM/JA3 become too coarse and too easy to evade with tiny configuration changes. The authors propose an enrichment pipeline that augments active TLS fingerprints with HTTP header information, then replaces exact hash matching with similarity mapping so analysts can pivot from known-bad infrastructure to previously unseen domains that “look like” it. They borrow from chemical fingerprint visualization (MinHash + LSH forest + TMAP) to handle the high-dimensional, sparse feature space efficiently.
The main result reported is that adding HTTP headers materially increases fingerprint granularity across all three evaluated datasets, especially on Cloudflare-hosted domains where TLS-only profiles are highly compressed. In the final similarity maps, the authors report 67 previously unknown malicious domains detected through similarity to known malicious domains, without relying on any other intelligence. The strongest evidence is visual and cluster-based rather than a conventional supervised benchmark: dense malicious clusters emerge, while benign domains are more branched and dispersed. The paper’s value is therefore in showing a workable analyst workflow for enrichment + approximate nearest-neighbor similarity, not in introducing a new classifier with a standard accuracy table.
Key findings
- Across the three evaluated datasets, HTTP-header enrichment increased fingerprint granularity in every category; on the Cloudflare dataset, the reported minimum increase was 66.7% and the maximum was 4523.7% over TLS-only fingerprints.
- On the mixed-host dataset, granularity gains ranged from 4% to 199%; on the malicious-only dataset, gains ranged from 4% to 118%, which the authors attribute to less HTTP-header diversity among malicious infrastructure.
- The paper reports 67 previously unknown malicious domains detected solely by similarity to known malicious domains.
- In dataset one, a highlighted region contained 211 nodes, of which 166 were known bad, 32 were known good, and 13 were unknown; the authors say 27 were newly identified as malicious and 60% of good-or-unknown domains in that region were reclassified to bad.
- In dataset two (Cloudflare AS 13335), the authors say TLS-only fingerprints were extremely compressed: 59 fingerprints covered the full spectrum of known good domains, while enrichment expanded the graph dimensionality from 5368 x 50 to 5368 x 847.
- For the Cloudflare mixed area in dataset two, 85 nodes were analyzed with 30 unknowns; the authors report 40 newly identified malicious domains and that 72.72% of the good-or-unknown domains in the highlighted area were reclassified to bad.
- The similarity visualization uses 1024 hash functions, 128 prefix trees, and 100 nearest neighbors in the TMAP/LSH pipeline, which the authors claim preserves 1-nearest-neighbor relationships well.
Threat model
The adversary is an operator of malicious infrastructure—phishing, malware hosting, or C2—who can choose TLS server configurations and may try to evade detection by making small changes to cipher suites, extensions, or CDN deployment details. The defender is allowed to actively probe domains with benign TLS handshakes and then enrich the result with HTTP header data. The adversary is assumed not to control the defender’s scanning infrastructure or the reference label sources, but they may try to minimize fingerprint uniqueness, exploit CDN homogenization, or mutate configurations to break exact-hash signatures.
Methodology — deep read
The threat model is operational rather than a formal adversarial ML setup: the authors assume an attacker controls malicious domains (malware, C2, phishing) and may try to blend into benign infrastructure, especially CDNs, by making small TLS changes that break hash-based fingerprints. They also assume defenders can actively scan domains with benign TLS ClientHello probes and then fetch HTTP headers in a post-processing step. The paper explicitly motivates the method with ECH and CDN-driven similarity: if the TLS surface is too uniform, then exact-hash fingerprints are brittle and similarity-based retrieval becomes more useful than point classification.
Data comes from three sources of labels: Tranco for known-good domains; UrlHaus, Hunt.io, Cert.pl, and OpenPhish for known-bad domains; and Shreshtait for unknown domains. The paper states that all good domains were taken from the Tranco list and that malicious and unknown domains were gathered from the sources in Table 1. The raw workflow resolves domains to IPs using MassDNS, then appends a fixed set of 10 curated ClientHello messages from the ActiveTLS tool so that scans are comparable across datasets. The scan order is randomized to distribute load across the 10 probes, and TLS extended output is enabled. Importantly, HTTP scanning is not done inside ActiveTLS; instead, headers are collected in a post-processing step so their order can be preserved and header deconfliction across scans avoided. Labels are mapped as good = 0, bad = 1, unknown = 3. The paper says the final dataset sizes were approximately 17,711 mixed-origin servers, 5,368 Cloudflare AS 13335 servers, and 4,475 purely malicious domains.
The architecture is a feature-expansion and similarity-mapping pipeline rather than a learned classifier. First, the ActiveTLS output is broken into constituent TLS components: version, ciphers, extensions, encrypted extensions, and certificate extensions; the raw fingerprint is retained but SHA256-encoded for easier readability. They also enrich each sample with AS number data from pyasn.dat. For HTTP enrichment, they capture the HTTP header keys in order and by default discard most values; the only value retained in base usage is the Server header value. The authors intentionally exclude volatile headers like Date, Last-Modified, and E-Tag because those would create too much transient granularity. They then hash the header string with MurmurHash3 (MMH3), chosen for speed, compactness, distribution, and familiarity from tools like Shodan. The paper’s Table 2 illustrates that two domains can share the same TLS fingerprint while differing in HTTP-header fingerprint, which is exactly the kind of extra separation the method is supposed to exploit.
For similarity mapping, the enriched fingerprint is transformed into a very high-dimensional binary vector: the code iterates over all unique TLS features and HTTP headers seen across the dataset, builds a dictionary of unique entries, initializes them to 0, then flips an entry to 1 when a feature appears in a row. The authors report dimensionality ranging from roughly 80 columns up to 3,000 columns when HTTP headers are included, and in one visualization the final matrix reaches 16,254 x 2,124. They then use MinHash to compress the binary set representation while preserving similarity, and place the signatures into a TMAP LSH forest for approximate k-nearest-neighbor search. The four-stage graph process is: build MinHash signatures, index them in an LSH forest, create an approximate c-k-NNG graph using k-NN retrieval, then compute a minimum spanning tree with Kruskal’s algorithm and lay it out on the Euclidean plane. The authors explicitly prefer this over naive all-pairs Jaccard because exact similarity matrices do not scale to thousands or millions of TLS/header fingerprints.
The evaluation is mostly descriptive, graph-based, and cluster-analysis oriented. They compare TLS-only versus TLS+HTTP enrichment and examine whether the graphs become more separable and whether known-bad domains cluster near unknown domains that later match VirusTotal verdicts. For the similarity stability check, they query 20 random IDs per dataset and retrieve their 10 nearest neighbors, plotting distance from 0.0 (exact match) to visualize whether nearby nodes remain stable. They do not report silhouette scores because, as they note, this is not a conventional clustering method. The main concrete end-to-end example is the Cloudflare dataset: TLS-only fingerprints are highly collapsed, but after HTTP enrichment the graph expands from 5368 x 50 to 5368 x 847, and the authors say this improves the ability to distinguish malicious and benign domains within the same CDN. The paper also notes that reclassification is based on VirusTotal: if one or more vendors returns anything other than clean, the status is amended. Reproducibility is partial: the paper names the tools and parameter settings (ActiveTLS, MassDNS, pyasn.dat, MMH3, MinHash, 1024 hash functions, 128 prefix trees, k = 100), but the excerpt does not mention code release, frozen weights, or a public dataset release beyond the listed sources.
Technical innovations
- Adds ordered HTTP-header key sequences to active TLS fingerprints, rather than relying on TLS metadata alone or a single overwritten Server header.
- Uses a binary set representation of unique TLS and HTTP features, then compresses it with MinHash before approximate retrieval in a TMAP LSH forest.
- Applies chemical-fingerprint style nearest-neighbor preservation and minimum-spanning-tree visualization to TLS infrastructure hunting, instead of exact hash matching.
- Keeps the fingerprint operationally useful against small adversarial changes by shifting from exact signature equality to similarity-based pivots.
Datasets
- Tranco LJNY4 — not stated in paper — public list (tranco-list.eu)
- UrlHaus — not stated in paper — public source (urlhaus.abuse.ch)
- Hunt.io — not stated in paper — public source (hunt.io)
- Cert.pl — not stated in paper — public source (hole.cert.pl)
- OpenPhish — not stated in paper — public source (openphish.com)
- Shreshtait — not stated in paper — source indicated as unknown domains (shreshtait.com)
Baselines vs proposed
- TLS-only ActiveTLS fingerprinting vs TLS+HTTP enrichment: granularity increased on all three datasets; on Cloudflare the minimum increase was 66.7% and the maximum was 4523.7%
- TLS-only graph vs enriched graph on Cloudflare: dimensionality increased from 5368 x 50 to 5368 x 847
- TLS-only graph vs enriched graph on mixed dataset: the enriched representation produced visibly more separated benign and malicious regions, but the paper does not provide a scalar accuracy delta
- The paper references JARM/JA3 conceptually as prior hash-based baselines, but does not provide a direct numeric head-to-head table in the excerpt
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2410.03817.
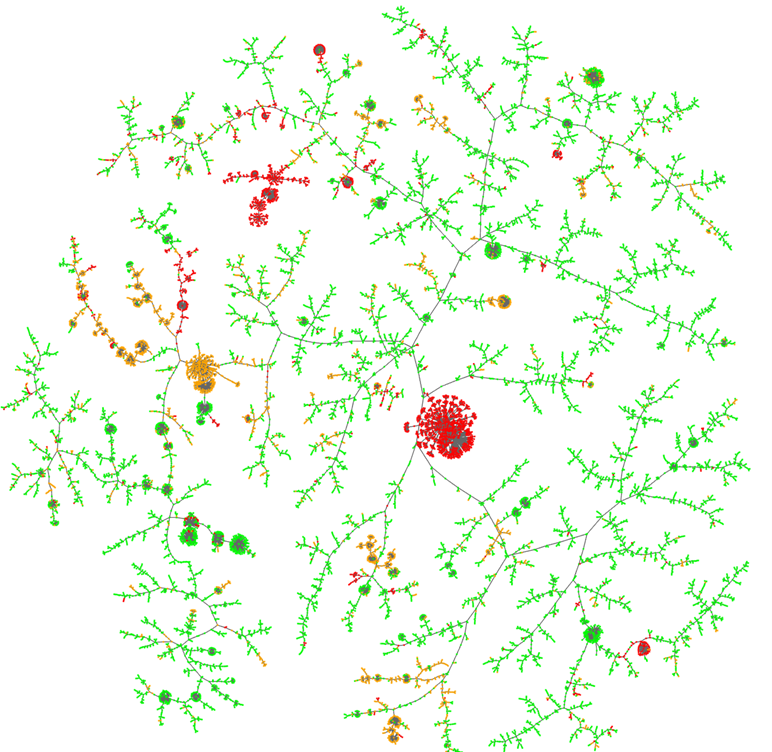
Fig 1: Graph displaying TLS features enriched with HTTP header data. Known good
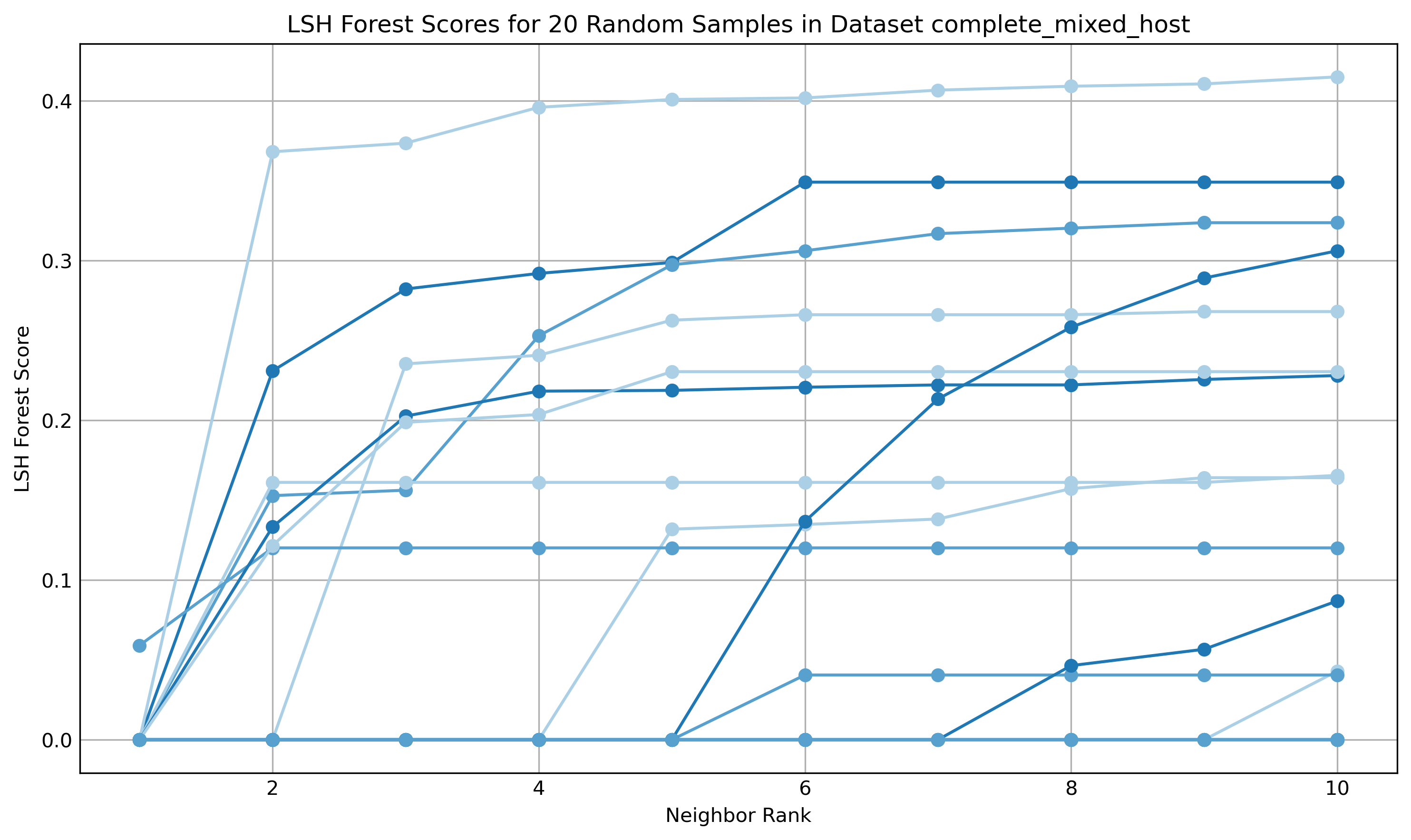
Fig 5: The cf mixed dataset displays
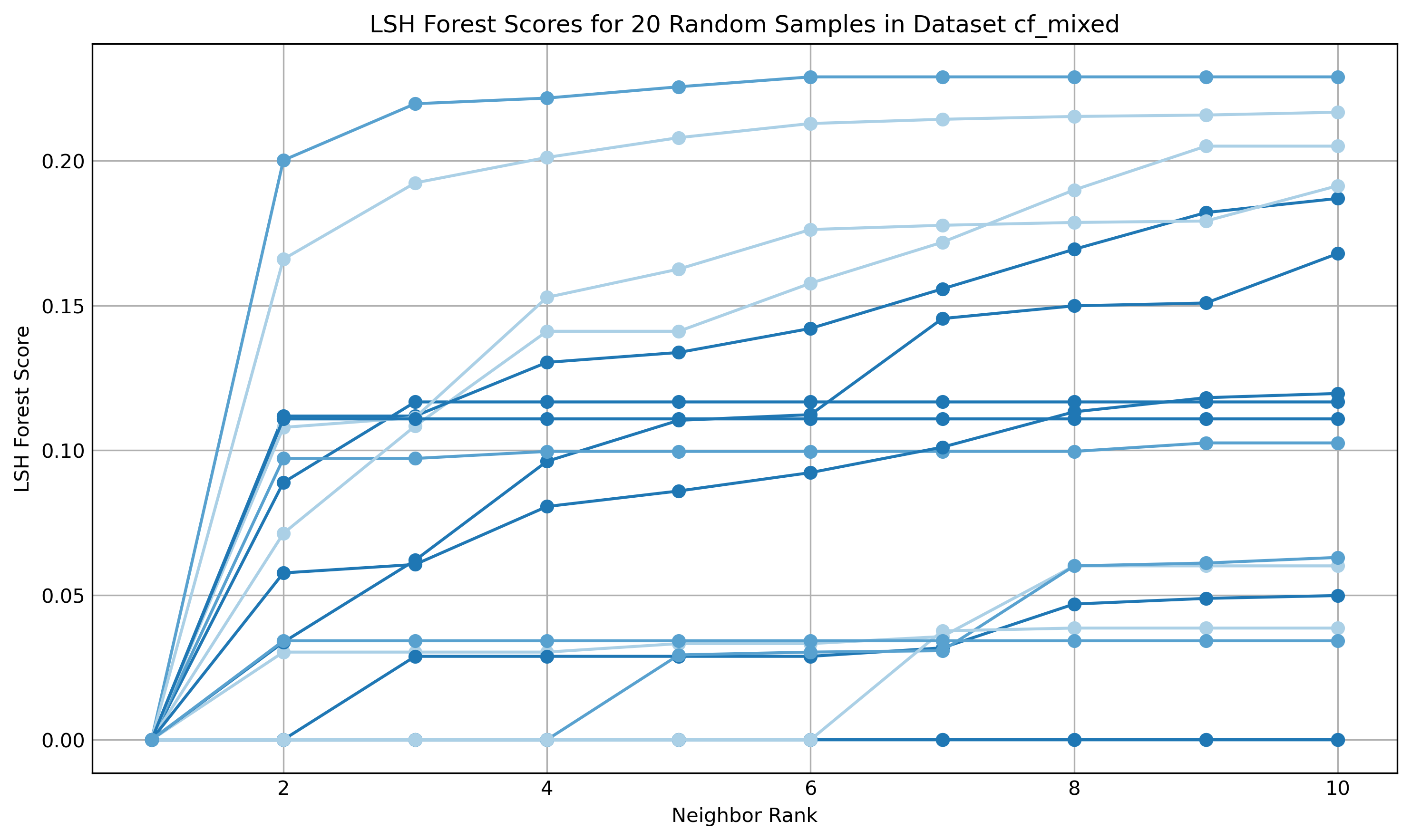
Fig 6: shows a proportion of the final
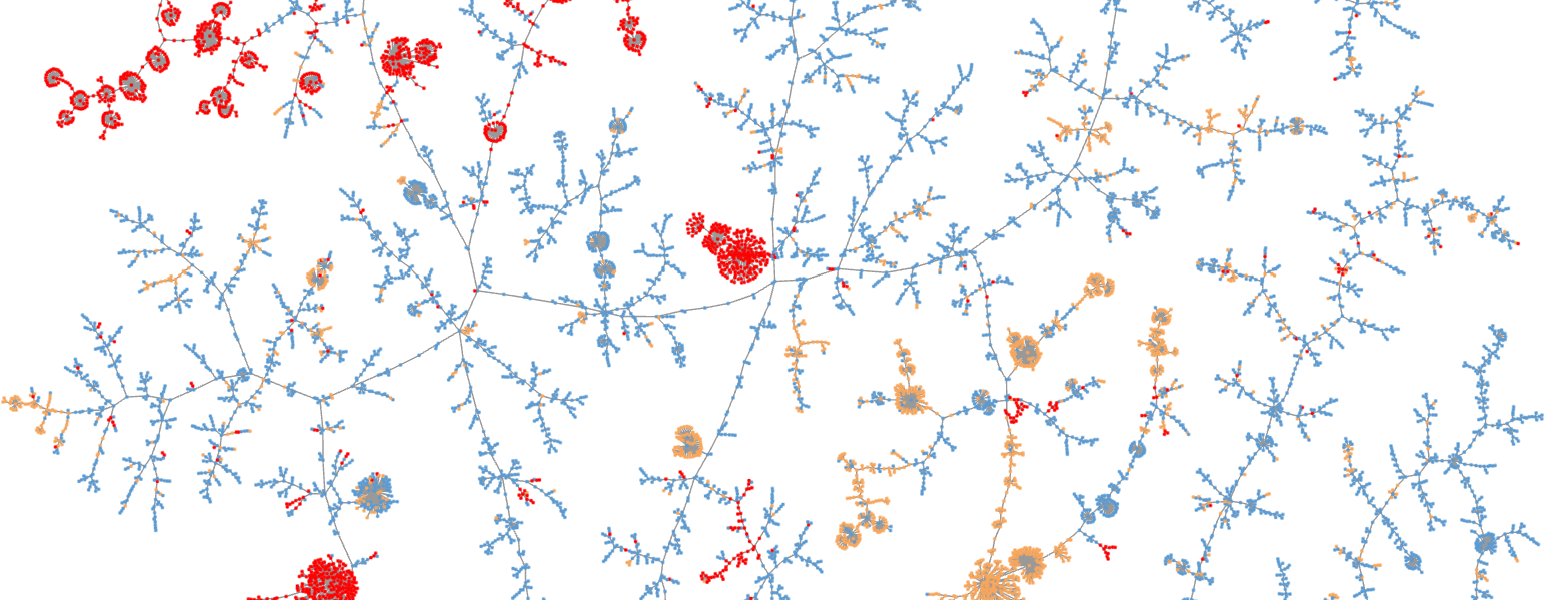
Fig 7: Cloudflare CDN domains visualised with TLS and HTTP header data. Known

Fig 8: Cloudflare CDN domains visualised with just TLS features, demonstrating a

Fig 9: displays the final plot based on the enriched TLS with HTTP header
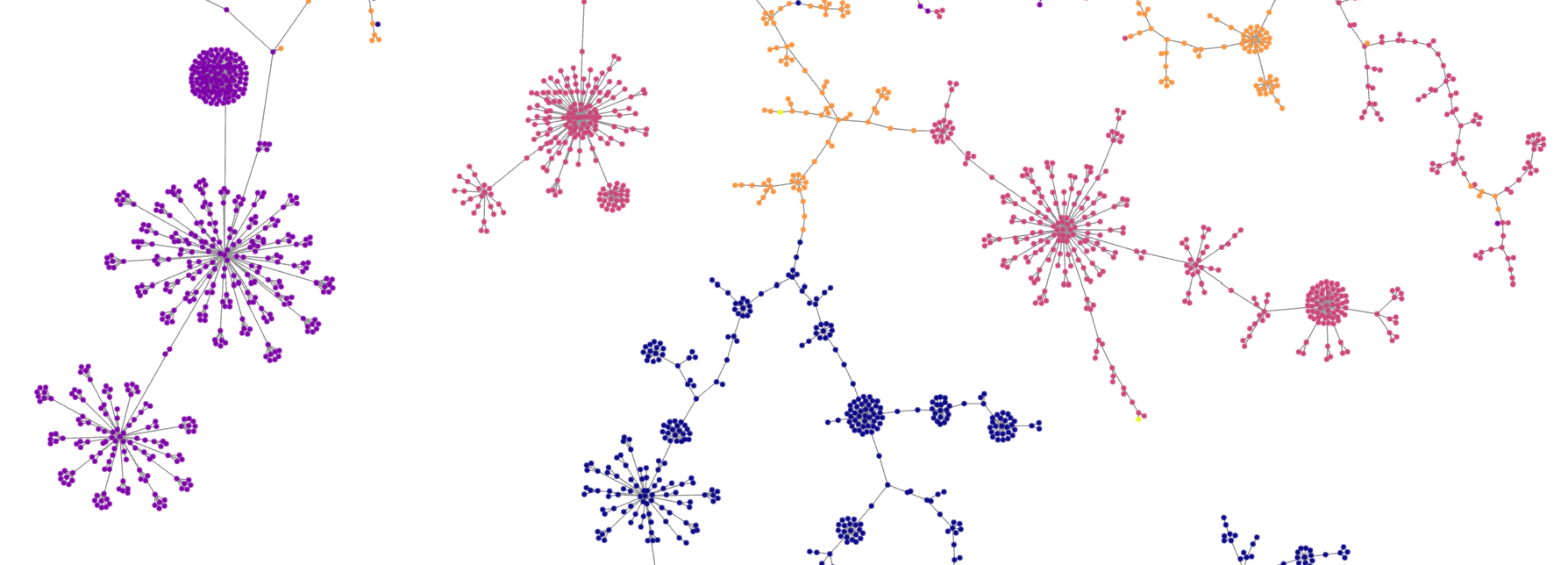
Fig 7 (page 19).
Limitations
- The evaluation is largely visual and cluster-based; there is no standard classification metric table with precision/recall/F1/AUC for the proposed method.
- The paper does not clearly report a held-out attacker split, temporal split, or domain-level train/test separation, since the method is not trained as a supervised model.
- VirusTotal-based reclassification can leak label noise and time dependence; the paper does not state vendor count thresholds or when scans were performed relative to reputation changes.
- HTTP headers are intentionally partially discarded, which avoids transient noise but may also miss useful discriminative signals such as application-specific values.
- The extracted text does not show a full reproducibility package: no code release, no frozen corpus snapshot, and no exact per-dataset sample counts for the raw sources in Table 1.
- The claims about 67 unknown malicious domains are not paired with an independent ground-truth validation protocol beyond similarity and VirusTotal amends.
Open questions / follow-ons
- How well does the method work under temporal drift, where CDN behavior and malicious infrastructure both change over weeks or months?
- Can the similarity pipeline be turned into a calibrated risk score with measurable precision/recall instead of only visual cluster interpretation?
- How robust is ordered HTTP-header enrichment against header normalization, reverse proxies, or deliberate adversarial header padding?
- Would the same approach still work once ECH deployment reduces what can be observed from the ClientHello and handshake path?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the main lesson is that exact fingerprint equality is often too brittle for infrastructure tracking; similarity-based retrieval can be more useful when adversaries or shared platforms introduce small but meaningful variation. If you are building reputation systems, challenge-routing, or pre-CAPTCHA risk scoring, this paper suggests enriching transport fingerprints with higher-level protocol metadata and then using approximate nearest-neighbor search to find “looks-like-known-bad” clusters instead of waiting for an exact signature match.
A practical reaction would be to treat TLS+HTTP similarity as one feature source among several, not as a standalone detector. It is promising for early discovery of new malicious domains that share stack characteristics with known bad infrastructure, especially on CDNs where TLS alone collapses. But because the evidence here is mainly exploratory and graph-based, a production bot-defense system would still need calibration, drift monitoring, and a validation loop that checks whether similarity clusters actually predict abuse before using them to block or escalate challenges.
Cite
@article{arxiv2410_03817,
title={ A novel TLS-based Fingerprinting approach that combines feature expansion and similarity mapping },
author={ Amanda Thomson and Leandros Maglaras and Naghmeh Moradpoor },
journal={arXiv preprint arXiv:2410.03817},
year={ 2024 },
url={https://arxiv.org/abs/2410.03817}
}