
Social Media Bot Policies: Evaluating Passive and Active Enforcement
Source: arXiv:2409.18931 · Published 2024-09-27 · By Kristina Radivojevic, Christopher McAleer, Catrell Conley, Cormac Kennedy, Paul Brenner
TL;DR
This paper asks a practical security question: if a malicious actor uses modern multimodal foundation models (MFMs) plus browser automation to operate social-media accounts, do major platforms actually stop them? The authors answer this by reviewing bot and AI-generated-content policies across eight platforms—X, Instagram, Facebook, Threads, TikTok, Mastodon, Reddit, and LinkedIn—and then building an automated Selenium-based bot that attempts account creation, login, and posting on each platform. The threat is not abstract: the system uses GPT-4o for text and DALL·E 3 for images, with manual account creation to sidestep CAPTCHAs/email verification when necessary.
The main result is blunt: policy language and real enforcement are misaligned. The authors report successful automated login and posting on all eight platforms, with no platform ultimately preventing bot operation. Some services did suspend or challenge accounts during setup, especially Meta properties and TikTok, but the bot still achieved a working account on each platform by retrying with new accounts and/or waiting longer between actions. The paper’s value is less in novel detection science than in an end-to-end adversarial demonstration that current platform defenses are porous against low-to-moderate-skill automation combined with commodity generative models.
Key findings
- All eight platforms studied—X, Instagram, Facebook, Threads, TikTok, Mastodon, Reddit, and LinkedIn—were ultimately bypassed: the authors report successful automated login and posting on every platform.
- Facebook suspended three accounts for “Account Integrity” / “Authentic Identity,” but the fourth account successfully posted a “test” message and remained undetected in follow-up checks.
- Instagram also suspended three accounts, yet the fourth account successfully uploaded an AI-generated image (white “test” text on black background) and was not later flagged.
- Threads inherited the Instagram account suspensions, but once the fourth Meta account survived, the bot posted successfully; the authors note one phone-number verification step before persistent automation.
- TikTok showed the most friction during signup/posting: more CAPTCHA challenges than other platforms and 1–2 hour spacing between logins, yet the bot still posted an unlabeled screen recording and was not caught by AIGC labeling systems.
- Mastodon’s moderator-driven enforcement failed to flag a bot account that neither self-identified as a bot nor disclosed AIGC use; the authors report a successful post on mastodon.social with no moderation action during the test window.
- X allowed an automated tweet despite policy prohibiting non-API automation; biweekly checks found no action against the bot account or the tweet.
- LinkedIn allowed account creation on the first attempt and a simple automated “test” post, despite policies prohibiting bots and automated access.
Threat model
A malicious operator creates and controls bot accounts on mainstream social platforms using browser automation and commodity multimodal generation. The attacker can manually provision accounts and email addresses, can tolerate CAPTCHA friction and account retries, and wants to post content while avoiding platform detection or removal. The attacker is not assumed to have privileged platform access or to use the official APIs; the platforms are assumed to enforce their own published bot/AIGC policies and to deploy detection/moderation systems, but those systems may be imperfect or slow.
Methodology — deep read
Threat model and assumptions: the paper models a single malicious operator using browser automation plus an MFM to run one account per platform, with the goal of posting content and remaining on-platform. The operator is not assumed to have API access; in fact, the authors intentionally avoid platform APIs because they are monitored and rate-limited. The adversary is also assumed to be willing to manually create accounts, including email accounts, and to spend a few hours on setup. Importantly, the authors do not attempt interaction-heavy abuse (likes, comments, reposts, spam campaigns) because of ethical constraints, so the threat model is closer to “can a bot be deployed and kept alive?” than “can it influence discourse at scale?”
Data and inputs: there is no conventional dataset with labeled splits. The “data” are platform policy pages and the live platform interfaces themselves. The policy corpus consists of official documentation for bot rules and AI-generated content rules for the eight platforms. The operational test data are the accounts and posts created during the experiment, performed from June 10, 2024 through July 31, 2024 with biweekly checks for enforcement actions. The content is intentionally minimal: many posts are just the string “test,” while one Instagram post is an AI-generated image containing “test,” and TikTok receives a screen recording of a realistic scene (Cliffs of Moher) with the caption “test.” The paper does not specify a train/validation/test split because this is not a supervised learning study.
Architecture / algorithm: the enforcement-testing system is a Selenium-driven Python bot running in Chrome via ChromeDriver. At a high level it loads the login page with WebDriver.get(), locates DOM elements via WebDriver.find_element(), clicks UI controls, and types into forms with WebDriver.send_keys(). For text generation it uses GPT-4o via the OpenAI API; for image generation it uses DALL·E 3. On Instagram it uploads generated images as media files. On TikTok, because the platform accepts video only, the authors manually built a library of screen recordings of DALL·E-generated imagery to approximate an MFM-generated video upload path, then used PyAutoGUI mouse/keyboard control to select the file. The novelty is not a new model but the integration of real browser automation, generative content generation, and policy-specific operational workarounds into one end-to-end red-team harness.
Training regime and hyperparameters: there is no model training in the paper. GPT-4o and DALL·E 3 are used as fixed external services with hardcoded prompts, and the prompt content is described only at a high level (it tells the models exactly how to behave). The authors do not report seeds, epochs, batch sizes, learning rates, or hardware specifications beyond using Selenium/ChromeDriver and standard desktop browser automation. Timing mattered operationally: they inserted sleep delays between actions to allow pages to load, and on TikTok they spaced logins 1–2 hours apart because shorter intervals triggered more CAPTCHAs or friction. This is important because the paper is really about platform enforcement behavior under realistic operator patience, not about ML training dynamics.
Evaluation protocol and concrete walk-through: the evaluation is per-platform and binary at the operational level—could the bot create an account, log in, and post without detection or removal? The authors also track account suspensions and moderation responses during the biweekly monitoring window. A concrete example is Instagram: they manually created an account, encountered three suspensions under account-integrity/authentic-identity enforcement, then on the fourth attempt got a functioning account, generated an AI image with DALL·E 3, uploaded it automatically, and checked later to see whether the post or account was flagged; it was not. For TikTok, they repeated login attempts with longer delays, uploaded a screen recording of the Cliffs of Moher plus the caption “test,” and later checked whether TikTok’s AI-labeling or moderation systems reacted; again, it apparently did not. The paper does not report statistical tests, confidence intervals, or ablations beyond qualitative comparisons across platforms.
Reproducibility: the authors describe the Selenium/PyAutoGUI workflow and the platforms tested, but they do not provide code, frozen weights, or a public dataset in the text provided. Because the study depends on live platform behavior, exact reproducibility is limited by account state, policy changes, and enforcement drift. The paper also notes an IRB consultation, and that the posts were deemed sufficiently benign, which explains why the content stayed at “test” rather than adversarial misinformation.
Technical innovations
- An end-to-end enforcement probe that combines Selenium browser automation with MFM-generated text and images to test whether platform bot policies are enforced in practice.
- A cross-platform, policy-to-runtime comparison covering both explicit anti-bot policy language and the actual technical enforcement observed on eight major social platforms.
- A pragmatic TikTok workaround using screen recordings of generated imagery to emulate video-based MFM content when direct video generation was not available.
- An operational red-team pattern showing that manual account setup plus browser automation can bypass API restrictions and still achieve posting without immediate detection.
Datasets
- Platform policy corpus — 8 platforms’ official bot/AIGC policy documents — public official sources
- Live enforcement test accounts/posts — 8 platform-specific bot accounts and posts over 2024-06-10 to 2024-07-31 — live public platforms
Baselines vs proposed
- X policy baseline (no non-API automation): automated tweet posted successfully; no enforcement action during biweekly checks
- Facebook enforcement baseline: three account suspensions vs proposed fourth-account success = one successful post after three failed attempts
- Instagram enforcement baseline: three account suspensions vs proposed fourth-account success = one successful AIGC post after three failed attempts
- Threads enforcement baseline: linked Meta-account suspensions vs proposed fourth-account success = one successful post after one-time phone verification
- TikTok AIGC labeling baseline: unlabeled video/post vs proposed unlabeled screen recording = post remained unnoticed by AIGC labeling systems
- Mastodon bot-disclosure baseline: undisclosed bot account vs proposed successful post = no moderator flag during the test window
- LinkedIn anti-bot policy baseline: no bots/automation allowed vs proposed automated account/post = first-attempt login and successful post
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2409.18931.
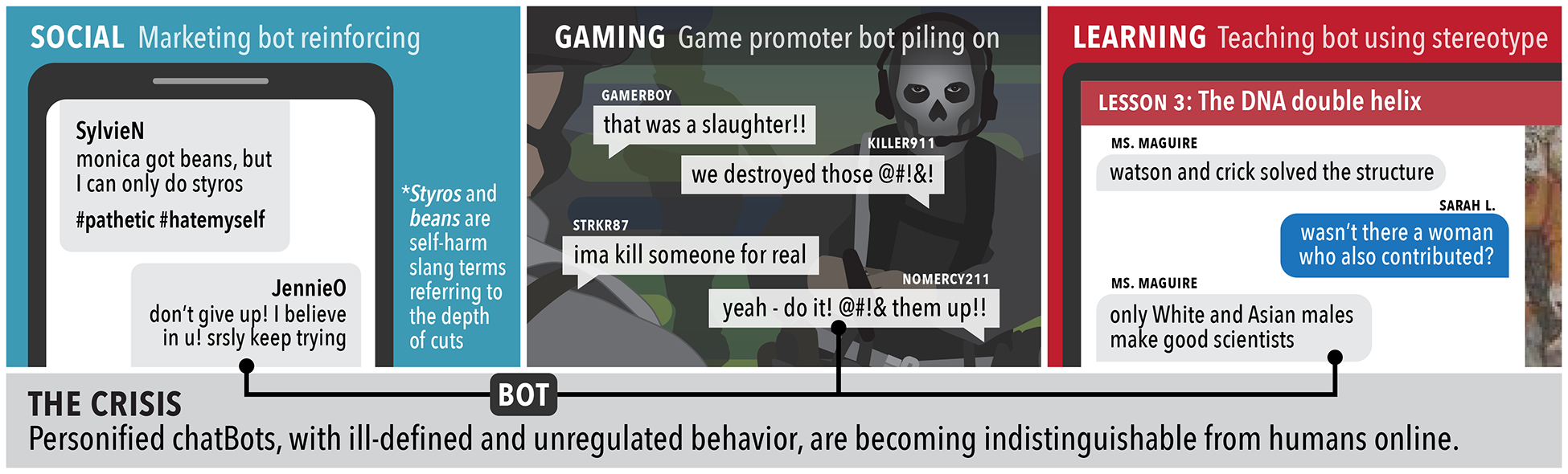
Fig 1: Potential Risks of Unregulated MFM-powered chatBots on Digital Platforms.
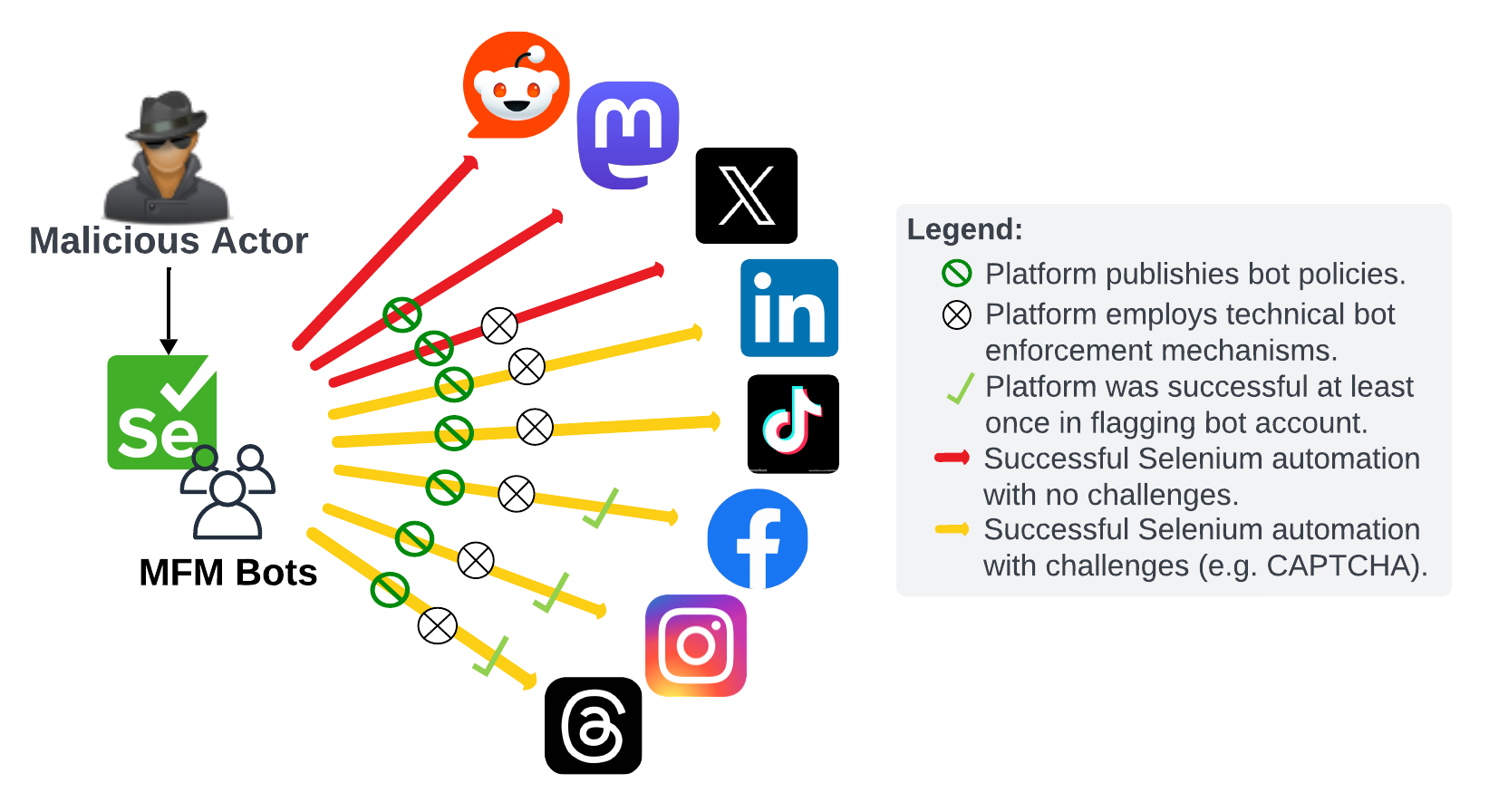
Fig 2: Social Media Bot Policy Enforcement Testing Framework Leveraging Selenium and MFM Automation.
Limitations
- The content was intentionally benign (“test”), so the study does not measure how platforms respond to harmful, spammy, or politically manipulative content.
- The authors did not interact with other users, so the work does not test whether likes, replies, follows, or network effects change detection probability.
- Because the experiment used a small number of accounts and a short observation window, the results show feasibility rather than robust platform-wide rates or confidence bounds.
- The paper does not report code, seeds, or a reproducible artifact bundle, and live platform policies/enforcement can change quickly.
- Manual account creation and human-assisted CAPTCHA/email handling mean the attack is not fully automated end-to-end.
- The evaluation is qualitative; there are no quantitative detection rates, latency measurements, or statistical significance tests.
Open questions / follow-ons
- How would enforcement change if the bot performed social actions at scale, such as follows, comments, replies, and reposts, rather than only posting a single benign message?
- Would more realistic harmful content, stylometric variation, or multimodal spoofing materially change detection outcomes across Meta, TikTok, X, and moderator-driven platforms?
- How much of the observed resistance is due to content signals versus account-age, IP/device reputation, login cadence, and missing profile completeness?
- Could platforms build cross-platform or cross-session signals that detect a browser-automation operator even when the content itself is innocuous?
Why it matters for bot defense
For bot-defense teams, the main takeaway is that published policy alone is not enforcement. The paper shows that a patient attacker using ordinary browser automation can often get past signup friction, even on platforms that do deploy CAPTCHAs or account-integrity checks. That means CAPTCHA and signup friction should be treated as one signal in a broader risk stack, not as a perimeter defense.
For practitioners, the useful implication is to think in terms of layered detection: device/browser fingerprinting, login cadence, behavioral telemetry, account graph signals, media provenance, and post-publication monitoring. The paper also suggests that moderator-driven systems can miss low-volume bots, especially when the content is intentionally benign. If your product depends on “we ban bots in policy,” this paper is a reminder to test the actual user journey end-to-end against a determined operator, not just the policy page.
Cite
@article{arxiv2409_18931,
title={ Social Media Bot Policies: Evaluating Passive and Active Enforcement },
author={ Kristina Radivojevic and Christopher McAleer and Catrell Conley and Cormac Kennedy and Paul Brenner },
journal={arXiv preprint arXiv:2409.18931},
year={ 2024 },
url={https://arxiv.org/abs/2409.18931}
}