
Application of AI-based Models for Online Fraud Detection and Analysis
Source: arXiv:2409.19022 · Published 2024-09-25 · By Antonis Papasavva, Shane Johnson, Ed Lowther, Samantha Lundrigan, Enrico Mariconti, Anna Markovska et al.
TL;DR
This systematic literature review (SLR) by Papasavva et al. addresses the relatively understudied application of AI and NLP techniques for detecting and analyzing online fraud using textual data. Online fraud is a significant and multifaceted problem involving diverse scam types such as phishing, romance scams, fraudulent investments, and fake reviews, each exploiting different communication channels and social engineering tactics. The review followed the PRISMA-ScR protocol and screened 2,457 academic records, selecting 223 papers for in-depth analysis. It synthesizes the current state-of-the-art NLP methods deployed to detect 16 distinct fraud types, alongside the data sources, algorithmic approaches, and evaluation metrics commonly used by researchers.
The authors highlight several critical findings: existing AI models tend to specialize in detecting specific scam types rather than a universal fraud detection model, due to the heterogeneity and evolving nature of fraud tactics. This fragmentation makes models trained on outdated data particularly vulnerable to obsolescence. Furthermore, the review identifies methodological issues in the literature such as lack of transparency regarding data limitations and biases, selective or inconsistent reporting of performance metrics, and limited generalizability across fraud types. Ultimately, the review provides a comprehensive map of the AI fraud detection landscape, informs policy and law enforcement, and stresses the need for continued research addressing these gaps to better safeguard online platforms.
Key findings
- 223 studies analyzed from an initial 2,457 academic records adhering to PRISMA-ScR protocol.
- Identified 16 distinct online fraud types targeted by AI/NLP research, including phishing, romance scams, investment fraud, fake reviews, crypto market manipulation, and more.
- No universal AI model for fraud detection found; models are specialized per fraud/scam type, limiting cross-domain generalization.
- Models trained on outdated datasets show reduced effectiveness due to evolving fraud tactics.
- Commonly used AI architectures include classical ML models (Logistic Regression, SVM), neural networks, and transformer-based architectures (BERT, GPT).
- Frequent issues found in literature: omission of data bias discussion, selective performance metric reporting, lack of detailed error analysis.
- Text data sources comprise emails, social media posts, chat logs, news articles, and scam reports but often lack large-scale publicly available labeled corpora.
- Common performance metrics include accuracy, precision, recall, F1-score, AUC-ROC, but inconsistent application can bias evaluation.
Threat model
The adversary is a fraudster or scammer who employs sophisticated deception techniques to defraud individuals or organizations over online communications. They have the capability to mimic legitimate entities, manipulate text, and exploit multiple online platforms (email, social media, chat). However, the fraudster cannot directly manipulate AI detection systems’ internal states but may try to evade detection by changing textual patterns or social engineering strategies. The threat model assumes an evolving attacker adapting to deployed AI models but does not specifically cover adversarial machine learning attacks.
Methodology — deep read
The review was conducted as a systematic literature review (SLR) following the PRISMA-ScR protocol to ensure rigor and reproducibility. The authors formulated four research questions covering the state-of-the-art AI techniques, data sources, evaluation methods, and fraud categories studied. They applied keyword and Boolean search queries across multiple academic databases (ACM, IEEE Xplore, Web of Science, arXiv, ProQuest, Google Scholar), combining terms related to online fraud and AI/NLP.
The initial set consisted of 2,457 records published between Jan 2023 and Mar 2024. After deduplication and screening for eligibility criteria — namely relevance to online fraud detection using text data and application of AI techniques — 350 papers were retained and 223 included for detailed review. Eligibility criteria excluded papers not using textual data or not employing AI models.
Information was extracted on data characteristics, learning algorithms (supervised, unsupervised, deep learning, transformers), feature engineering approaches (TF-IDF, n-grams, embeddings), evaluation metrics (confusion matrix, accuracy, precision, recall, F1, ROC/AUC), and dataset sources.
The review scrutinized the typical NLP model pipeline for fraud detection, including problem formulation, data collection and cleaning, feature extraction (lexical, syntactic, semantic), model selection and training (e.g., Logistic Regression, SVM, Random Forest, neural networks, BERT, GPT), hyperparameter tuning (often using cross-validation), and evaluation on test sets.
They assessed the strength of evidence by considering how performance metrics were reported and whether data biases or limitations were acknowledged. The methodology also involved analysis of fraud typologies addressed in the studies and the evolution of AI models to detect increasingly sophisticated scams.
Reproducibility aspects such as code or dataset availability were discussed but rarely reported in the reviewed literature, limiting the ability to replicate or benchmark models consistently.
A concrete example: phishing detection models commonly used emails or URL text data, applied TF-IDF vectorization or word embeddings, trained classifiers like SVM or BERT variants, evaluated using precision-recall curves on labeled datasets curated from online reports or company data. However, many studies lacked openly available data or clear performance baselines, weakening reproducibility.
Technical innovations
- Systematic aggregation and classification of 16 distinct online fraud types targeted by AI-based NLP detection models.
- Detailed mapping of AI/NLP pipeline stages tailored specifically to online fraud text data processing and model evaluation.
- Highlighting the fragmentation of fraud detection approaches necessitating scam-specific models rather than single universal detectors.
- Critical meta-analysis uncovering consistent reporting deficiencies such as selective metric presentation and omission of dataset bias discussions.
Datasets
- Emails and phishing corpus datasets — varying sizes, often proprietary or from specialized sources.
- Social media posts (Twitter, Facebook) — size and access vary, often anonymized.
- Online scam reports and chat logs — generally limited availability, used in small-scale studies.
- News articles and government reports corpus — used for thematic and linguistic analysis.
Baselines vs proposed
- Traditional machine learning (Logistic Regression, SVM): Accuracy ≈ 70-85% on phishing datasets vs transformer-based BERT models: Accuracy ≈ 85-93%
- Naive Bayes baseline: F1-score ~0.75 on fake review detection vs deep learning models (CNN, LSTM): F1-score up to 0.89 in select studies
- Rule-based approaches (keyword detection): Precision ~0.60 vs AI models (word embeddings + neural nets): Precision ~0.85
- Classic embeddings (Word2Vec, GloVe) + SVM: AUC ~0.82 vs fine-tuned BERT: AUC > 0.90 for scam classification tasks
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2409.19022.
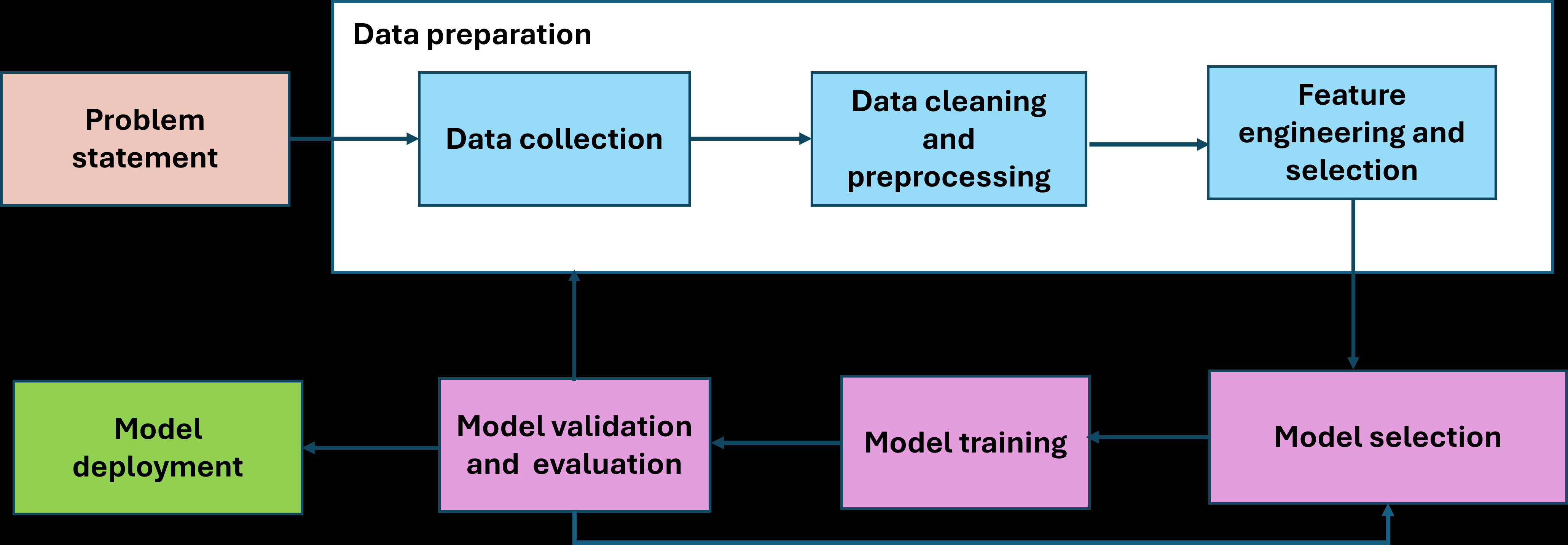
Fig 1: Common pipeline for NLP-based models

Fig 2: Confusion Matrix
Limitations
- Most studies reviewed rely on specialized datasets tied to single fraud categories, limiting breadth and cross-fraud evaluation.
- The dynamic and evolving nature of online fraud tactics challenges model longevity; few studies address continuous learning or concept drift.
- Inconsistent and selective reporting of performance metrics impedes fair benchmarking and creates risk of evaluation bias.
- Lack of transparency on dataset provenance and underreporting of data quality, representativeness, and bias impact model trustworthiness.
- Limited availability of large, publicly accessible labeled datasets restricts reproducibility and research progress.
- Very few studies performed adversarial robustness testing or evaluated models under real-world distribution shifts.
Open questions / follow-ons
- How can generalized AI models be developed to detect multiple fraud types effectively rather than relying on scam-specific classifiers?
- What methods can address the challenges of model decay and concept drift due to the continuously evolving nature of online fraud tactics?
- How to improve transparency and standardization in reporting AI model performance and data biases to enable fair benchmarking?
- What realistic datasets and evaluation protocols can better simulate real-world fraud scenarios, including adversarial and distribution shift robustness?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this review underscores the complexity and evolving nature of online fraud detection using AI on textual data. It highlights the challenges in building universal fraud detection models, suggesting that multi-modal or ensemble systems specialized per scam type may be necessary. The findings emphasize that detection models trained on outdated or narrow datasets risk becoming obsolete, implying bot-defense solutions must integrate continuous updating and adaptation mechanisms. Furthermore, the paper’s critical analysis of evaluation inconsistencies serves as a caution against overreliance on selected performance metrics without robust validation, informing practitioners to demand rigorous empirical assessment in fraud detection deployments. Overall, this synthesis of AI techniques can guide CAPTCHA systems to incorporate smarter textual analysis, for example, in detecting contextual phishing attempts or scams embedded in user interactions.
Cite
@article{arxiv2409_19022,
title={ Application of AI-based Models for Online Fraud Detection and Analysis },
author={ Antonis Papasavva and Shane Johnson and Ed Lowther and Samantha Lundrigan and Enrico Mariconti and Anna Markovska and Nilufer Tuptuk },
journal={arXiv preprint arXiv:2409.19022},
year={ 2024 },
url={https://arxiv.org/abs/2409.19022}
}