
Evaluation Scheme to Analyze Keystroke Dynamics Methods
Source: arXiv:2407.16247 · Published 2024-07-23 · By Anastasia Dimaratos, Daniela Pöhn
TL;DR
This paper is not proposing a new keystroke-dynamics classifier; it is trying to make comparison itself more disciplined. The authors argue that published results are hard to compare because studies mix different input texts, participant counts, feature sets, preprocessing, and error metrics. Their main contribution is an evaluation scheme built from biometric-authentication requirements plus keystroke-specific criteria, then applying that scheme to three representative mobile keystroke-dynamics approaches.
The practical result is a comparative judgment rather than a new benchmark score: the SVM+RBF approach from Krishnamoorthy et al. appears strongest among the three examples, while the two distance-vector/statistical approaches have materially worse EERs. The paper’s broader conclusion is cautious: keystroke dynamics can be a useful additional authentication factor on smartphones, but it is not robust against stronger adversaries and is highly sensitive to device, context, and evaluation setup. The authors explicitly call for a shared dataset and more open experimental protocols to make future comparisons meaningful.
Key findings
- The paper compares 3 mobile keystroke-dynamics approaches under a unified evaluation scheme, but the source studies use different metrics, inputs, and datasets, making direct comparison unreliable.
- Krishnamoorthy et al. (2018) report accuracy = 0.9740 and F1-score = 0.9701; the paper converts this to EER = 0.026 for cross-paper comparison.
- Al-Obaidi and Al-Jarrah (2016) achieve average EER = 0.1219 with standard deviation 0.1337 across their tested thresholds/settings.
- Alghamdi and Elrefaei (2015) achieve average EER = 0.0789, which the authors interpret as better than the median-vector-proximity approach but worse than the SVM+RBF approach.
- The strongest reported result in the comparison is the SVM+RBF concept, with 155 extracted features from 77 users after preprocessing 94 participants’ data.
- The paper states that using a given input (fixed password/message) performs better than free input, based on the selected studies.
- The authors conclude that pure typing rhythm is too weak on its own, while adding features such as pressure and size improves performance.
Threat model
The assumed adversary is an attacker attempting to bypass keystroke-dynamics authentication on a smartphone by imitating the victim’s typing behavior, replaying observed patterns, or exploiting weaknesses in the capture/classification pipeline. The authors distinguish ordinary observers from stronger adversaries who could use key tracking, broader impersonation infrastructure, or protocol and feature biases. The system is assumed to protect a mobile device, but the paper does not model a fully privileged on-device attacker who can directly tamper with sensors or training data in detail.
Methodology — deep read
The paper is a literature-driven evaluation study, not a fresh end-to-end ML experiment. Its threat model is implicit rather than formal: the authors assume an authentication attacker trying to imitate or replay typing behavior on a smartphone, and they distinguish weaker observers from stronger adversaries who may combine key-tracking, protocol weakness exploitation, or broader impersonation resources. They also emphasize that keystroke dynamics is behavioral, so performance depends on conditions like stress, illness, device differences, and whether the user is typing on a touchscreen keyboard, number pad, or some other input surface.
For the data basis, the authors do not build one new dataset; instead they review prior biometric-requirements literature and analyze three externally published keystroke-dynamics systems. The three compared approaches are: (1) Krishnamoorthy et al. (2018), using an Android app and password .tie5Roanl; 94 participants typed it 30 times, and the authors report 77 users after feature extraction; (2) Al-Obaidi and Al-Jarrah (2016), where 17 participants typed a message five times using an Android app; and (3) Alghamdi and Elrefaei (2015), where 22 participants typed password 766420 100 times. Preprocessing differed per paper: concept 1 removed duplicates, filtered below-threshold samples, removed geolocation, found action types and corrected errors, then generated features; concept 2 normalized and min-max scaled; concept 3 evaluated min-max scaling, standard scaling, Euclidean distance, and Manhattan distance, then chose Manhattan distance plus standard scaling. Because the source papers do not share a common split protocol, the evaluation here is a meta-comparison over published results rather than a re-run on one controlled dataset.
Architecturally, the paper’s own contribution is an evaluation framework, not a model. The framework first extracts biometric-authentication requirements from prior survey papers and turns them into criteria: universality, uniqueness, circumvention resistance, permanence, measurability, security, user-friendliness, acceptability, and economic feasibility. It then adds keystroke-dynamics-specific observables: time-dependent features such as DU, UD, DD, UU, and DU2 intervals, and time-independent features such as x/y position, pressure, size, and device-specific signals. On the modeling side, the three analyzed systems differ: concept 1 uses linear SVM and then RBF kernel; concept 2 uses distance vector classification with two vectors; concept 3 uses distance vector classification with median. The paper does not specify full hyperparameter grids, optimizer details, or random-seed strategy for the source papers, and it explicitly notes that some study details are undisclosed.
Training and inference are described at a conceptual level. Keystroke systems generally have data collection, preprocessing, feature selection/extraction, and classification; some systems also include relearning/adaptation because typing behavior changes over time. In a concrete example, the Krishnamoorthy setup: 94 Android users repeatedly type the password .tie5Roanl; the pipeline removes duplicate samples, drops records below a threshold, strips geolocation, derives action types and corrected errors, and generates 13 feature types yielding 155 features for 77 users. Those features are then fed to an SVM classifier, and the RBF variant is compared against plain SVM. The paper’s evaluation does not retrain the models itself; instead it converts reported accuracy to EER where needed using the relationship accuracy = 1 - EER, and it compares the published FAR/FRR/EER-style results across studies.
Evaluation is mostly comparative and criterion-based. The authors discuss classical binary-classification metrics (accuracy, precision, recall, F1), biometric error rates (FRR, FAR, EER, FER, FTA), and why these can be misleading across studies if threshold choice, data collection, and label definition differ. They also introduce a qualitative scale for ease of imitation and attacker effort. Table 5 summarizes the three selected approaches under the scheme, showing concept 1 with accuracy 0.9740 and F1 0.9701, concept 2 with average EER 0.1219 and sigma EER 0.1337, and concept 3 with average EER 0.0789. The paper argues these values are only partially comparable because the setups differ so much. Reproducibility is therefore weak: the paper synthesizes public prior work, but it does not release a new dataset, frozen model, or code, and it repeatedly calls for a common open dataset and more transparent protocols.
Technical innovations
- Defines a keystroke-dynamics evaluation scheme by combining biometric-authentication requirements with task-specific metrics and attacker-effort categories.
- Normalizes heterogeneous published results by translating accuracy/F1 into EER where possible to enable rough comparison across studies.
- Separates keystroke-dynamics evaluation into data collection, preprocessing, feature extraction, classification, and relearning, then maps each stage to comparison criteria.
- Introduces a qualitative security discussion that distinguishes observability/imitation difficulty from classifier error rates, which are not the same thing.
Datasets
- Krishnamoorthy et al. (2018) Android keystroke dataset — 94 participants, 30 password repetitions, 77 users after feature extraction — private / not stated public
- Al-Obaidi and Al-Jarrah (2016) Android message-typing dataset — 17 participants, 5 repetitions — private / not stated public
- Alghamdi and Elrefaei (2015) Android password-typing dataset — 22 participants, 100 repetitions — private / not stated public
Baselines vs proposed
- SVM (linear) vs SVM + RBF: accuracy = not reported for linear SVM in the paper vs proposed/selected concept = 0.9740, F1-score = 0.9701 (Krishnamoorthy et al. 2018)
- Distance vector classification with two vectors: øEER = 0.1219 vs proposed/selected concept = 0.1219; EER σ = 0.1337 (Al-Obaidi and Al-Jarrah 2016)
- Distance vector classification with median: øEER = 0.0789 vs proposed/selected concept = 0.0789 (Alghamdi and Elrefaei 2015)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2407.16247.
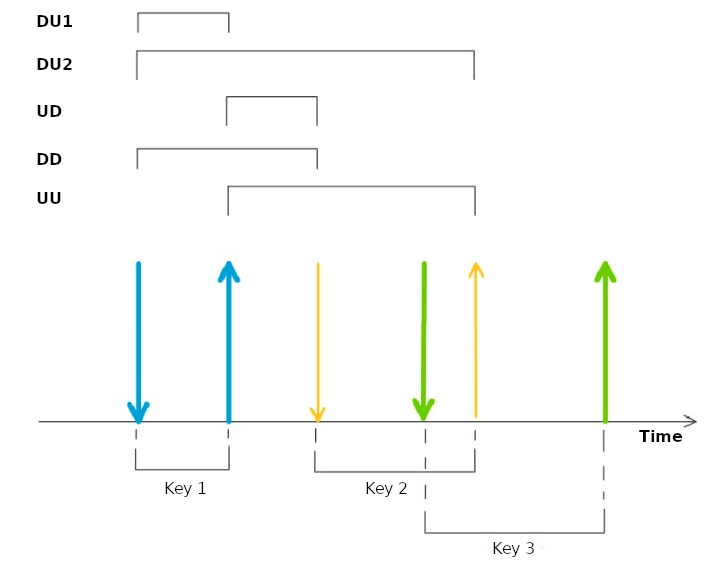
Fig 1: illustrates the most relevant time-
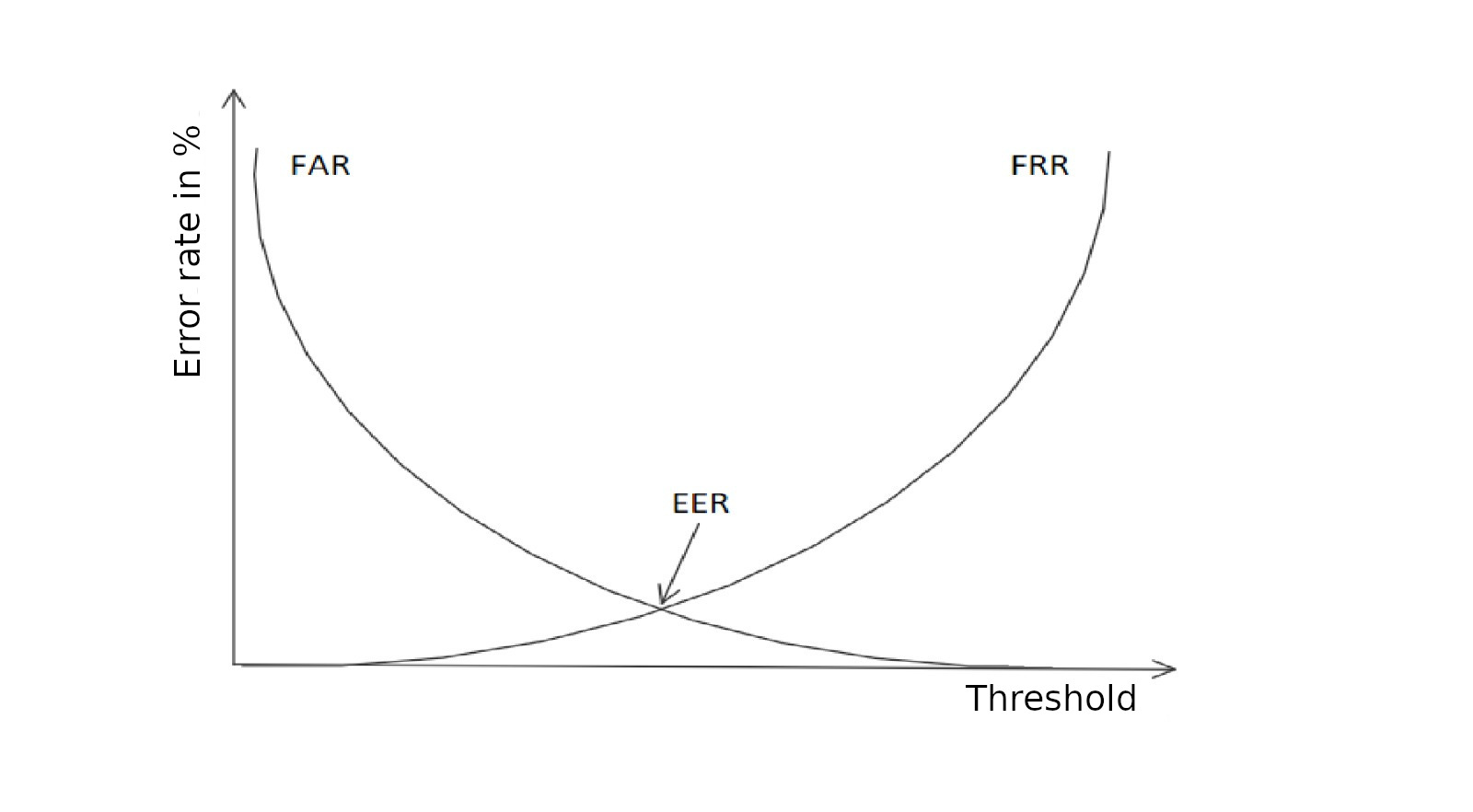
Fig 2: Correlation of error rates
Limitations
- No common dataset: each compared paper uses different input text, participant count, feature set, and preprocessing, so cross-paper comparison is only approximate.
- Several source studies do not disclose all experimental details, including thresholds and some setup specifics, which weakens reproducibility and comparability.
- The evaluation is secondary analysis; the authors do not re-run all three systems under one unified protocol.
- The paper’s security claims are qualitative and threat-model-driven rather than backed by a new adversarial evaluation against modern attack tooling.
- Accuracy is converted to EER for one study, which is only valid as a rough proxy and not a substitute for matched evaluation conditions.
- The work focuses on mobile keystroke dynamics and does not test cross-device, cross-session, or long-term drift under a controlled shared protocol.
Open questions / follow-ons
- How stable are these keystroke features across sessions, device models, keyboard layouts, and emotional or physical state changes?
- What is the right shared benchmark protocol for mobile keystroke dynamics, including fixed text, free text, and cross-device evaluation?
- How do modern adversaries with malware, accessibility abuse, or remote observation change the measured FAR/EER in practice?
- Which features add the most robustness per unit of usability cost: timing only, pressure/size, motion sensors, or device-specific signals?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the paper is mainly a caution against overinterpreting biometric-style typing signals as a standalone trust signal. The authors’ own comparison suggests that timing-only keystroke dynamics is weaker than systems that incorporate richer sensor features, but even those stronger variants remain vulnerable to better-resourced adversaries and to drift across devices and contexts.
In practice, this points toward using keystroke dynamics only as one feature in a broader risk engine, not as a hard gate by itself. It is most relevant for mobile login flows where you can capture rich interaction telemetry and want a low-friction step-up signal. But the paper also reinforces that without a shared benchmark and common thresholds, it is hard to set reliable operating points for FAR/FRR tradeoffs, so any deployment would need its own calibration, monitoring, and adversarial testing.
Cite
@article{arxiv2407_16247,
title={ Evaluation Scheme to Analyze Keystroke Dynamics Methods },
author={ Anastasia Dimaratos and Daniela Pöhn },
journal={arXiv preprint arXiv:2407.16247},
year={ 2024 },
url={https://arxiv.org/abs/2407.16247}
}