
UserBoost: Generating User-specific Synthetic Data for Faster Enrolment into Behavioural Biometric Systems
Source: arXiv:2407.09104 · Published 2024-07-12 · By George Webber, Jack Sturgess, Ivan Martinovic
TL;DR
This work addresses the usability challenge in behavioural biometric authentication systems, specifically reducing the burdensome enrolment phase where users must provide many biometric samples. The authors investigate using generative deep learning to create synthetic, user-specific smartwatch payment gestures from a small number of real samples, aiming to augment training data and reduce enrolment effort. The key novelty lies in combining a regularised variational autoencoder (VAE) with an authentication loss that enforces user clustering in latent space, enabling generation of diverse and high-fidelity synthetic gesture data tailored to individual users. The approach is validated on the publicly available WatchAuth dataset, which captures wrist motions from 16 users making smartwatch contactless payments at multiple payment terminal positions.
Their experiments show that augmenting training data with these synthetic user-specific gestures can reduce the number of real gestures needed for enrolment by over 40% without harming authentication metrics such as False Acceptance Rate (FAR) at zero false rejection or Equal Error Rate (EER). They extensively analyze latent space structure and reconstruction losses, settling on a novel combined loss function (KLB-mod plus feature loss) and demonstrate improved synthetic data quality via a train-synthetic test-real (TSTR) evaluation. This work thus provides a practically useful method to accelerate user enrolment in resource-constrained behavioural biometric systems by leveraging generative modelling to produce personalized synthetic data.
Key findings
- Synthetic data augmented training reduces real gesture enrolment for WatchAuth by more than 40% without increasing error rates.
- Optimal autoencoder reconstruction loss combines modified Keogh’s lower bound (KLB-mod) with a feature-based loss, outperforming MSE or Soft-DTW losses in synthetic data usefulness.
- Latent space regularisation with KL divergence coefficient β=1e-4 balances reconstruction quality and latent space smoothness.
- Adding a rank-based authentication loss (approximate Mean Reciprocal Rank) with weight α enforces user clustering in latent space, improving user-specific synthetic data generation.
- Using a Random Forest (100 trees) classifier on accelerometer and gyroscope features (RF100), synthetic training data improved FAR@0 and Area Under ROC (AUROC) compared to training with real data only.
- The WatchAuth dataset includes 3,484 positive gestures and 30,771 non-gestures across 16 users and 7 spatial terminal positions sampled at 50Hz.
- Conv+GRU deep learning model outperformed RF100 baseline but RF100 was retained for resource constraints on smartwatch deployment.
- Train-Synthetic Test-Real (TSTR) classification scores demonstrate synthetic data quality by training on synthetic samples and testing on held-out real samples.
Threat model
The adversary is a zero-effort attacker who possesses a legitimate user’s unlocked smartwatch and attempts payment authentication by submitting their own biometric signals. The adversary cannot produce or mimic the true user’s payment gesture biometrics but can replay or act in place of the user via the device. The model assumes no physical spoofing or compromised sensors beyond this possession scenario.
Methodology — deep read
Threat Model & Assumptions: The adversary is assumed to possess a legitimate user’s unlocked smartwatch and attempts a zero-effort attack by submitting their own biometric motion data to fool authentication. The adversary cannot mimic the genuine user's gesture biometrics perfectly.
Data: Experiments use the publicly available WatchAuth dataset with 16 users, each performing smartwatch payment gestures at 7 terminal positions. Data is sampled at 50Hz from accelerometer and gyroscope sensors, capturing 4 seconds before NFC contact per gesture. There are 3,484 gesture samples (positive) and 30,771 non-gesture samples. Data preprocessing involves segmenting windows, normalizing channels, and low-pass filtering with a Butterworth filter, resulting in 200 timesteps by 6 channels per gesture.
Architecture/Algorithm: The generative model is a regularised autoencoder architecture with an encoder modeled as a combination of convolutional layers followed by stacked GRU layers (Conv+GRU). The encoder outputs a 10-dimensional latent embedding vector (a mean and variance in VAE setting). The decoder mirrors the encoder with stacked GRUs and upsampling convolutions to reconstruct time series. The loss function combines three terms: a novel reconstruction loss called KLB-mod plus feature-based loss, a KL divergence regularisation term weighted by β to promote latent space continuity and completeness, and an authentication loss weighted by α implemented as a differentiable rank-based loss (approximated mean reciprocal rank) encouraging user clustering in latent space. This latter loss is applied on first 5 latent dimensions.
Training Regime: Models were trained using the Adam optimizer at a learning rate of 1e-4 with early stopping (patience 150 epochs). Hyperparameters β (regularisation) and α (authentication loss) were experimentally varied with final values β=1e-4 and α tuned to balance clustering and reconstruction. The train/test split preserved temporal order, using the first two-thirds of time-ordered user data for training/validation and final third for testing. Batch size and hardware raise are not explicitly specified.
Evaluation Protocol: Quality of synthetic data was evaluated using Train-Synthetic Test-Real (TSTR), training classifiers (Random Forest with 100 trees and Conv+GRU) on synthetic samples and testing on real unseen data. Authentication metrics include False Acceptance Rate at zero false rejection (FAR@0), equal error rate (EER) presented as intervals due to discrete classifier scores, and AUROC. Ablations include varying latent dimensions, β and α, and comparing reconstruction losses. Baselines include WatchAuth RF100 trained only on real data.
Reproducibility: The authors released code for training generative models and preprocessing WatchAuth dataset at https://github.com/GeorgeWebber/WatchAuth-DL. The WatchAuth dataset itself is publicly available. No frozen weights reported. Some implementation details (hardware, seeds) are not explicitly detailed.
Example end-to-end: Given a small set of real target user gestures, the pretrained VAE with α-enforced user clustering encodes these into latent embeddings. Synthetic samples are generated by sampling points close in latent space to the real embeddings of that user, then decoded to produce synthetic gestures. These synthetic gestures augment the small real set and train a RF100 classifier to authenticate gestures. Testing that classifier on held-out real gestures shows improved authentication metrics compared to training with real data alone, demonstrating synthetic data value for reducing enrolment size.
Technical innovations
- Introduction of a combined reconstruction loss (KLB-mod + feature-based loss) tailored for time series gesture reconstruction to improve synthetic quality.
- Application of a VAE regularisation scheme with a novel rank-based authentication loss (approximate MRR) to enforce meaningful user clustering in latent representation for user-specific synthetic data generation.
- Demonstration that user-specific synthetic gestures generated from latent points near real user embeddings can augment training and reduce enrolment sample requirements by over 40% without authentication quality loss.
- Design of a resource-efficient Conv+GRU architecture as both encoder and decoder for timeseries gesture data compatible with smartwatch constraints.
Datasets
- WatchAuth — 3,484 positive gestures and 30,771 non-gestures from 16 users at 7 payment terminal positions — publicly available at https://github.com/GeorgeWebber/WatchAuth-DL
Baselines vs proposed
- WatchAuth RF100 classifier trained on real data only: FAR@0 around baseline level; vs with synthetic data augmentation: FAR@0 decreased by over 40% in enrolment sample reduction without error increase
- Conv+GRU model trained on real data only: higher AUROC than RF100; vs synthetic augmented training: showed further improvement in authentication metrics (exact numbers not specified in abstract)
- Autoencoder trained with MSE loss: lower TSTR classification accuracy than with KLB-mod + feature loss
- Autoencoder trained without latent regularisation (high β): poor latent space clustering and lower synthetic data usefulness, vs β=1e-4 regularised model with structured latent space and better performance
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2407.09104.

Fig 1: Left: A smartwatch user making a payment gesture.
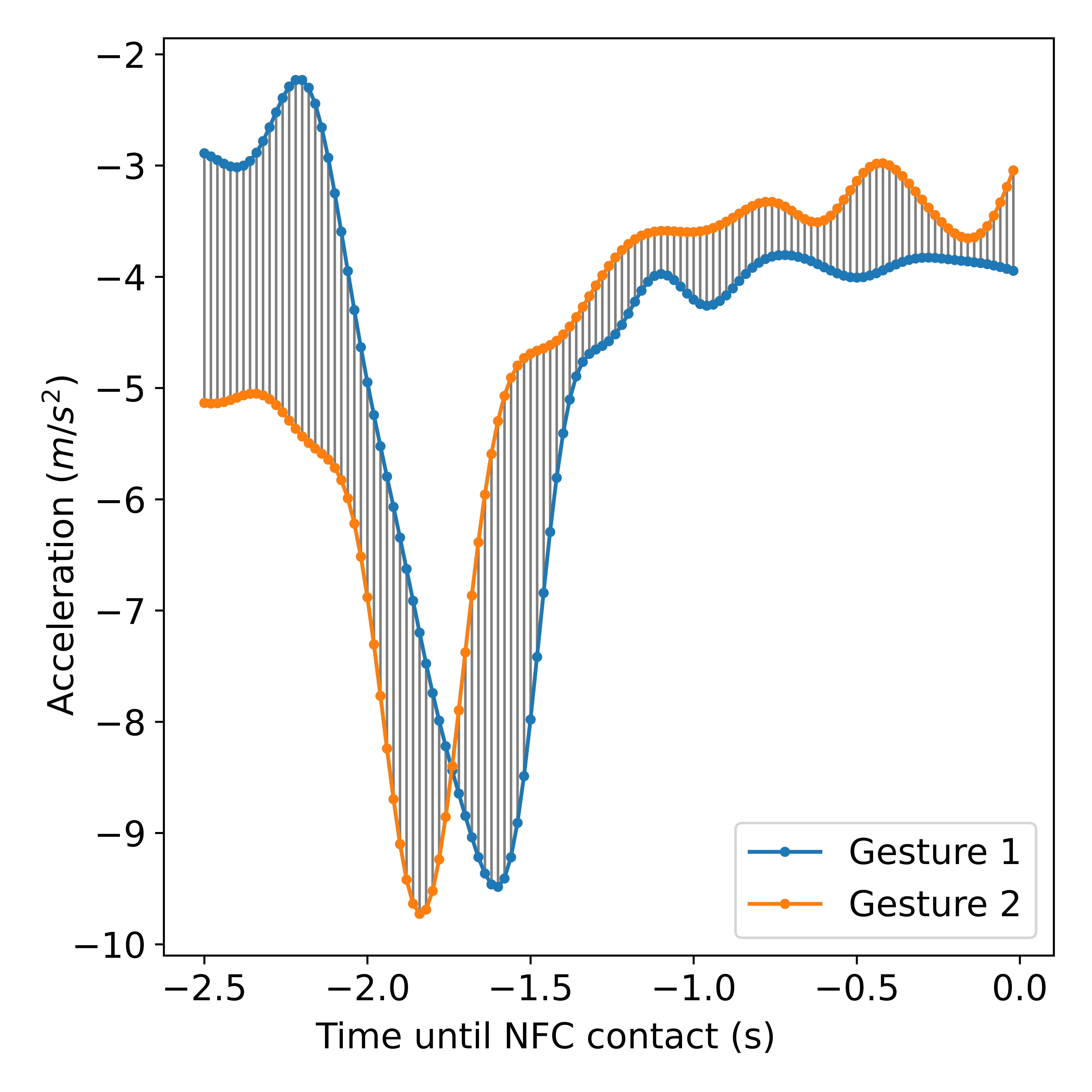
Fig 2: The dissimilarity of two WatchAuth gestures, measured with (a) Mean Square Error (MSE) distance, (b) Dynamic Time Warping
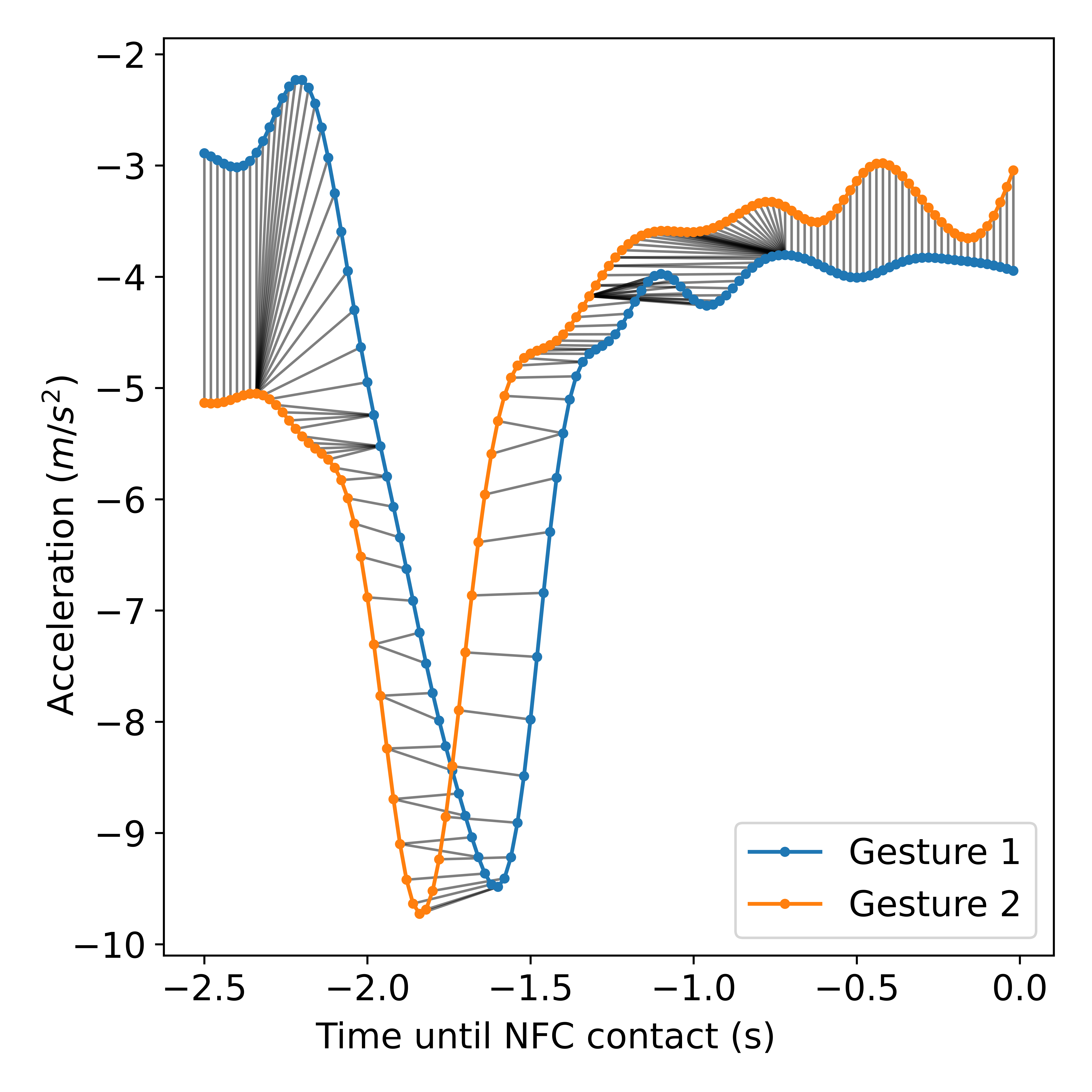
Fig 3: A plot of FAR and FRR against decision threshold𝑇from a
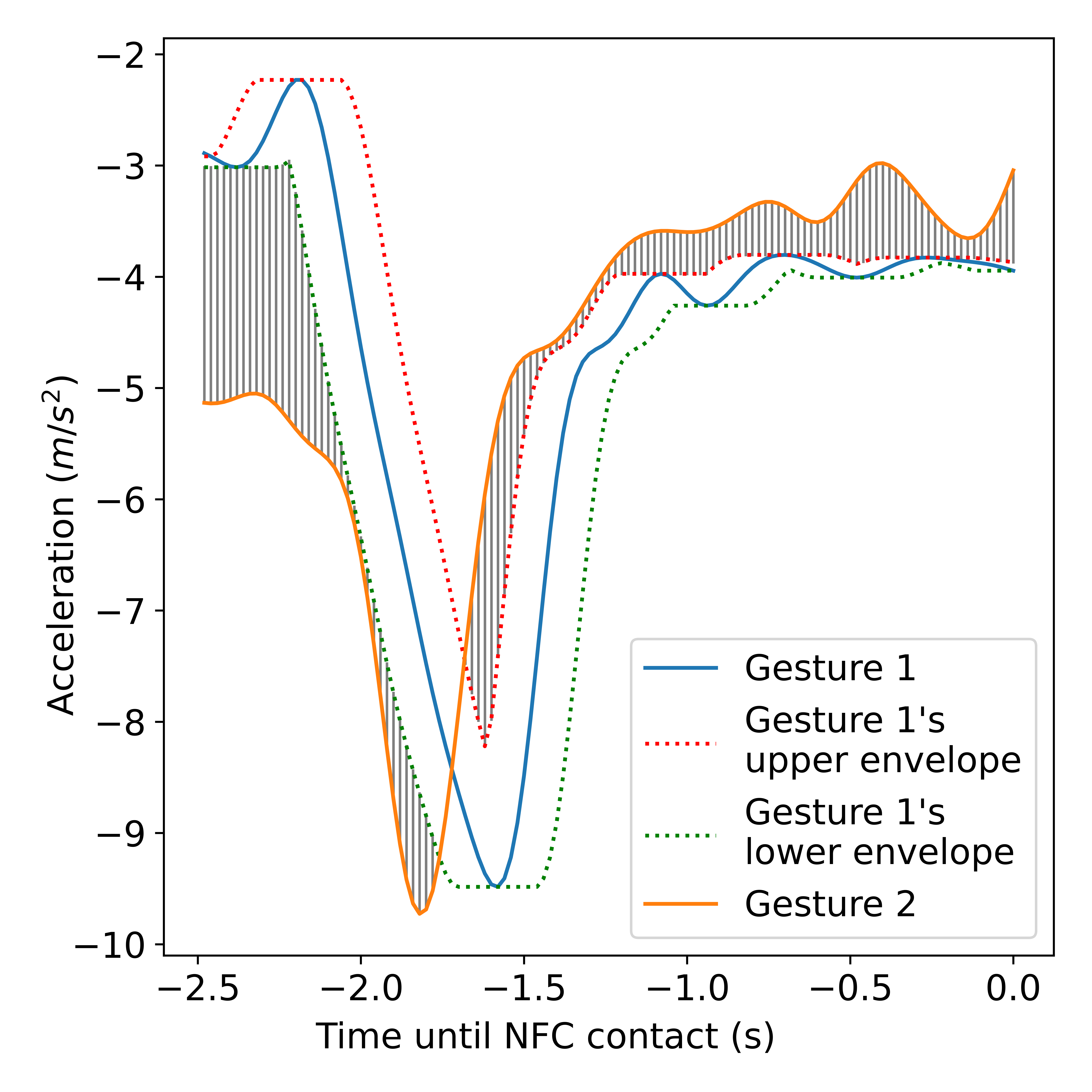
Fig 4 (page 3).
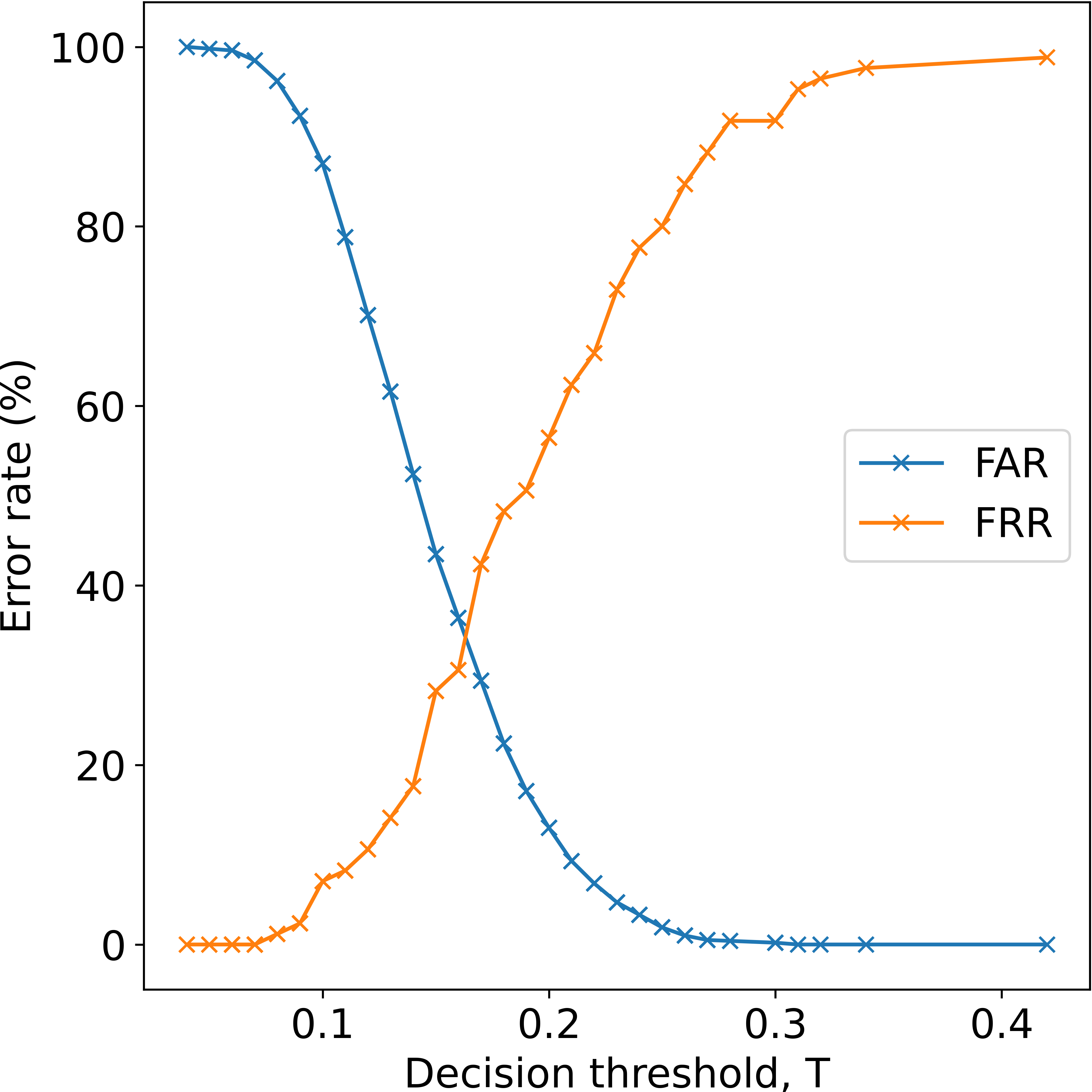
Fig 4: The first two principal components (PCs) of the training
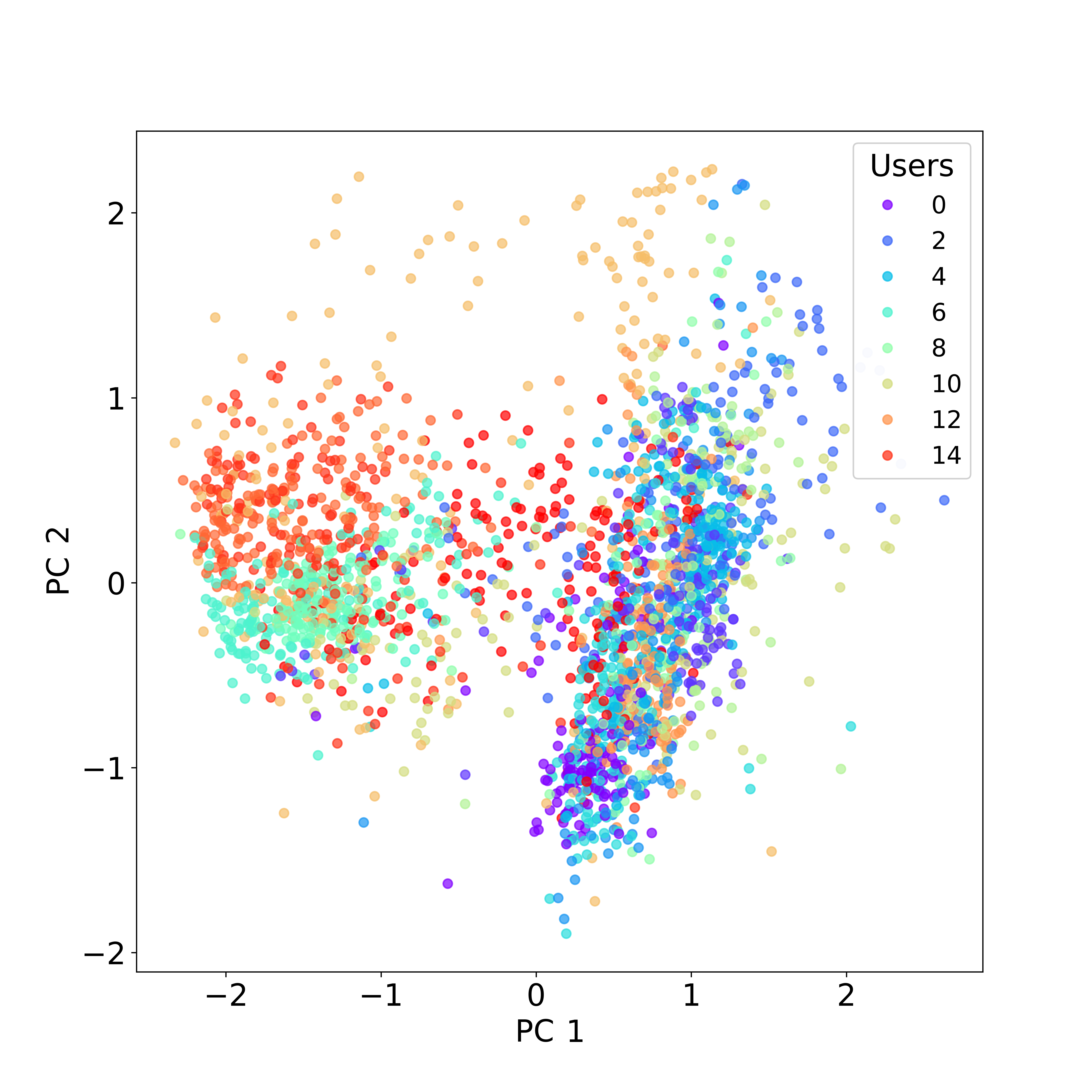
Fig 5: Training data latent space mean embeddings for VAEs
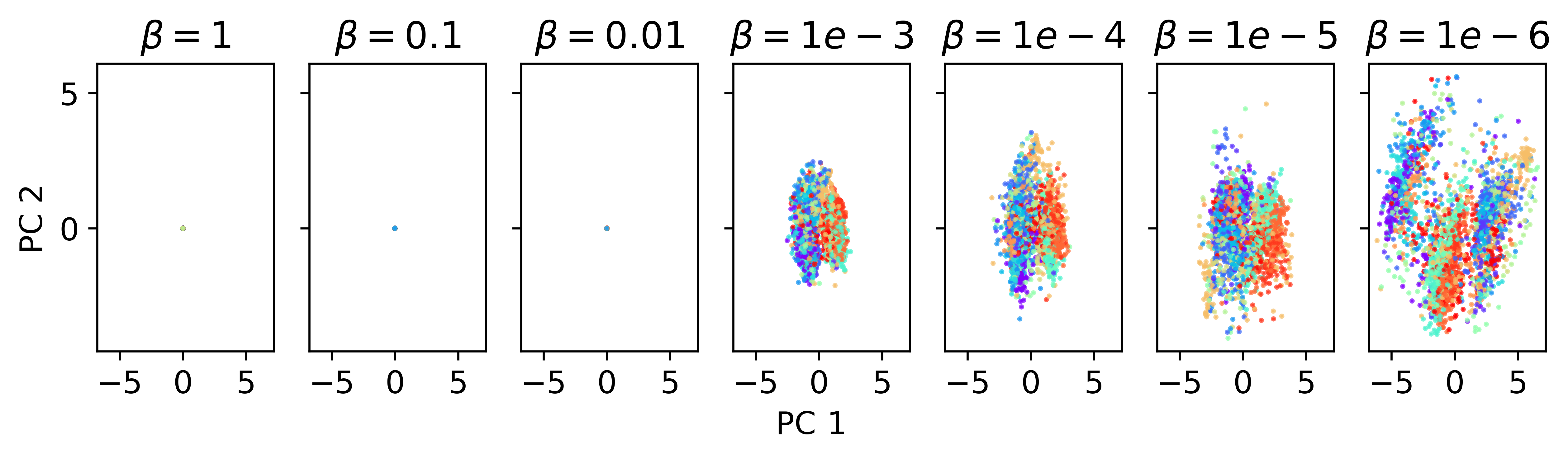
Fig 6: Latent space visualisation for VAE-based generative
Fig 7: t-distributed Stochastic Neighbour Embedding (t-SNE)
Limitations
- Experiments are conducted on a relatively small dataset with 16 users, limiting generalizability to larger populations.
- No extensive adversarial evaluation to test robustness against mimicry or adaptive forgery attacks was reported.
- The approach relies on availability of a large corpus of other users’ data to train the generative model before generating synthetic samples for a new user.
- Training and sampling require relatively high compute resources not feasible on-device; synthetic data generation is thus offloaded.
- The model only considers accelerometer and gyroscope data, not other possible biometric sensors (e.g., heart rate).
- There is no explicit testing of distributional shift such as varying watch placement, user fatigue, or temporal variation.
Open questions / follow-ons
- Can synthetic data generation be extended to larger, more diverse user populations with multiple device types or sensors?
- How robust is the UserBoost synthetic data augmentation against adaptive adversarial mimicry or replay attacks?
- Could the latent space user clustering be further improved with semi-supervised or contrastive learning methods?
- What is the tradeoff between synthetic data generation complexity and gains in enrolment reduction for other behavioural biometrics beyond smartwatch gestures?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work demonstrates an effective approach to reducing enrolment friction in behavioural biometric systems using user-specific synthetic data augmentation via generative deep learning. Since many bot-defense systems rely on behavioural biometrics such as mouse dynamics or touch gestures, generating synthetic user data to bootstrap classifiers could similarly reduce the challenge for legitimate users without sacrificing security.
Moreover, the insight that latent space regularisation with user clustering losses helps generate high-fidelity, user-specific synthetic samples may inspire more advanced synthetic data generation frameworks in CAPTCHA-like systems where limited real user data is available. The use of reconstruction losses tailored for time series and the train-test evaluation protocol (TSTR) are useful evaluation practices for synthetic data quality. However, bot-defense engineers should carefully consider threat model differences, notably adversarial attack vectors that more actively try to mimic or replay signals, and evaluate robustness in such scenarios.
Cite
@article{arxiv2407_09104,
title={ UserBoost: Generating User-specific Synthetic Data for Faster Enrolment into Behavioural Biometric Systems },
author={ George Webber and Jack Sturgess and Ivan Martinovic },
journal={arXiv preprint arXiv:2407.09104},
year={ 2024 },
url={https://arxiv.org/abs/2407.09104}
}