
Exploring Cognitive Bias Triggers in COVID-19 Misinformation Tweets: A Bot vs. Human Perspective
Source: arXiv:2406.07293 · Published 2024-06-11 · By Lynnette Hui Xian Ng, Wenqi Zhou, Kathleen M. Carley
TL;DR
This paper asks a narrow but important question for bot defense: do bots and humans differ in how they embed cognitive-bias triggers inside COVID-19 vaccine misinformation, and do those triggers relate differently to engagement? The authors treat “bias triggers” as content/network cues that can be computed from tweets and user interactions, then compare bot-authored versus human-authored misinformation on Twitter during July 2020–July 2021. The motivating claim is not just that bots spread more misinformation, but that bots may be systematically better at exploiting human heuristics such as availability, confirmation, and cognitive dissonance.
The main contribution is a hand-built misinformation corpus plus an automated labeling pipeline for eight biases spanning representativeness, availability, and anchoring heuristics. The paper reports that Availability Bias, Cognitive Dissonance, and Confirmation Bias are the most common in the dataset, with bots showing stronger prevalence and different usage patterns than humans. The engagement analysis suggests a mixed picture: some bias triggers are associated with higher bot engagement, but others reduce it; for human-authored misinformation, most bias triggers are not meaningfully related to engagement. The paper’s value for practitioners is mostly diagnostic: it proposes a way to operationalize “bias exploitation” in social media content and shows that bot and human misinformation are not equivalent in how these cues appear and how they may work.
Key findings
- The authors constructed a Misinfo Dataset with 1,768,838 bot-authored misinformation tweets from 513,886 bot users and 1,782,122 human-authored misinformation tweets from 1,314,305 human users.
- From the original COVID-19 Dataset, 65.47% of human tweets were misinformation, versus 98.60% of bot tweets being misinformation.
- Bot users had mean bot probability 0.84±0.08 under BotHunter, while human users had mean bot probability 0.37±0.20.
- The paper states that Availability Bias, Cognitive Dissonance, and Confirmation Bias were the most common bias triggers in the misinformation corpus.
- Over half of bot tweets used Availability Bias triggers via frequent retweeting/quoting, while about one third used Cognitive Dissonance triggers through stance change.
- For bot-authored tweets, Cognitive Dissonance triggers were associated with a 6% rise in favorites and a 9% rise in retweets.
- For bot-authored tweets, Availability Bias triggers were associated with a 28% decrease in favorites and a 34% decrease in retweets.
- The authors report that triggers of most biases appeared unrelated to engagement for human-authored misinformation tweets.
Threat model
The implied adversary is a Twitter bot or human account that intentionally spreads COVID-19 vaccine misinformation to maximize persuasion and engagement. The adversary can author tweets, retweet/quote others, and participate in the interaction network; the paper assumes these actions can be observed in tweet text and metadata. The adversary is not assumed to evade bot detection, poison the labeling pipeline, or manipulate the authors’ embedding-based misinformation retrieval beyond what naturally appears in the corpus. The paper does not model an adaptive attacker aware of the bias-trigger detector.
Methodology — deep read
Threat model and assumptions: the paper is not a classic adversarial detection study, but it does assume a social-media adversary that can author or coordinate misinformation posts with the intent to persuade and drive engagement. The adversary is either a bot account or a human account on Twitter; the paper’s central comparison is bot-authored versus human-authored misinformation. What the adversary knows is not modeled explicitly. Instead, the authors assume that bias triggers can be inferred from tweet text and network behavior, and that engagement metrics such as retweets, replies, quote tweets, and favorites are reasonable proxies for persuasive influence. They also implicitly assume that their bot classifier and misinformation retrieval pipeline are accurate enough to support downstream statistical analysis, even though both steps are only approximations.
Data provenance and labeling: the corpus begins with a “COVID-19 Dataset” collected via the Twitter Developer API for English tweets related to COVID-19 vaccine discovery and dissemination from July 2020 to July 2021. This initial scrape contained 2,249,611 unique users and 4,375,917 unique tweets. To isolate misinformation, the authors used an existing hand-annotated “Annotated Misinfo Dataset” of pandemic narratives and retained only misinformation categories: conspiracy, fake cure, fake fact, fake treatment, and false public health responses, which they say comprise 37.2% of that source dataset. They then embedded tweets using TwHIN-BERT embeddings from Hugging Face, after removing artifacts such as URLs and mentions. To validate the embeddings, they trained a multiclass logistic classifier on an 80/20 split of the annotated dataset; the classifier achieved 50.13% accuracy, compared with 20% random chance across five misinformation classes. For retrieval, each tweet from the larger COVID-19 scrape was embedded and compared to annotated misinformation tweets; if cosine distance was at least 0.8, the tweet was assigned the closest annotation’s misinformation class. The paper acknowledges possible false positives here, but proceeds under the assumption that close semantic matches are likely true positives. For bot labeling, they used BotHunter, a tiered random-forest-based detector using username, post text, and user metadata (followers, likes, etc.). Users with bot probability >= 0.70 were labeled bots, resulting in 519,337 bot accounts (23.1% of users) and 1,738,645 human accounts.
Architecture / algorithm: the core technical piece is an automated bias-trigger extraction pipeline for eight biases: Homophily, Authority, Availability, Illusory Truth, Affect, Negativity, Cognitive Dissonance, and Confirmation Bias. The paper organizes these under three heuristics from judgment theory: representativeness, availability, and anchoring. Although the full extraction details are truncated in the provided text, the described approach combines linguistic and statistical methods plus social-network signals. A key preprocessing step is stance labeling: the authors propagate stance over the tweet interaction network to assign pro-, anti-, or neutral-vaccine stance labels, and then use stance as an opinion signal for biases such as cognitive dissonance and confirmation. The algorithm also appears to use retweet/quote behavior, author characteristics such as professional identity, lexical sentiment/emotion cues, and repeated-message patterns to identify the remaining biases. The novelty is not a new neural architecture; it is a rule/feature-engineered operationalization of cognitive-bias triggers that can be applied at tweet scale.
Training regime, hardware, and example flow: the paper gives limited training detail beyond the 80/20 logistic regression validation split for the misinformation embedding classifier and the use of BotHunter’s pre-trained/random-forest ensemble. No epochs, batch size, optimizer, random seed strategy, or hardware are reported in the provided text. A concrete end-to-end example is this: the authors start from a tweet in the full COVID-19 scrape, strip URLs and mentions, embed it with TwHIN-BERT, compare it to annotated misinformation exemplars, and if its nearest semantic neighbor exceeds the cosine-distance threshold, they assign a misinformation narrative label. They then classify the author as bot or human using BotHunter probability >= 0.70, compute the tweet’s bias-trigger indicators using the heuristic algorithm, and finally associate those triggers with engagement outcomes (favorites, retweets, replies, quote tweets). The paper’s empirical logic is therefore two-stage labeling followed by descriptive statistics and engagement modeling.
Evaluation protocol and reproducibility: the paper evaluates the misinformation-classification proxy with the 50.13% accuracy figure, but that is not a full retrieval benchmark and is weak as a validation standard by modern IR/NLP norms. For the bias-trigger analysis, the paper reports descriptive prevalence, co-occurrence heatmaps, and engagement comparisons; Figures 2–5 (as referenced in the captions) summarize co-occurrence, engagement by bias triggers, the relationship between the number of biases triggered and engagement, and a final association summary. The reported engagement effects include percentage changes for bot tweets under certain bias triggers, but the truncated text does not disclose whether these are regression coefficients, normalized differences, or adjusted effects, nor whether statistical significance tests or controls were used. Reproducibility is partial: the paper is on arXiv and uses public components like TwHIN-BERT and BotHunter, but the underlying Twitter collection is not publicly redistributable, and the paper does not state that code or frozen labels were released in the provided text.
Technical innovations
- A tweet-scale operationalization of eight cognitive-bias triggers, bridging judgment-heuristic theory with automated social-media text/network analysis.
- A bot-versus-human misinformation corpus for COVID-19 vaccine tweets, built by combining semantic retrieval against an annotated misinformation seed set with BotHunter account labeling.
- An engagement analysis that separates bot and human misinformation, showing that the same bias trigger can correlate with opposite engagement effects across author types.
- Use of stance propagation as an intermediate signal for identifying cognitive dissonance and confirmation-related behavior in misinformation discourse.
Datasets
- COVID-19 Dataset — 4,375,917 unique tweets, 2,249,611 unique users — Twitter Developer API (English tweets, July 2020–July 2021)
- Annotated Misinfo Dataset — size not stated in provided text — hand-annotated source dataset from prior work [83]
- Bot Misinfo Dataset — 1,768,838 tweets, 513,886 users — derived from COVID-19 Dataset plus BotHunter and semantic filtering
- Human Misinfo Dataset — 1,782,122 tweets, 1,314,305 users — derived from COVID-19 Dataset plus BotHunter and semantic filtering
Baselines vs proposed
- Multiclass logistic classifier on TwHIN-BERT embeddings: accuracy = 50.13% vs random chance = 20% (for the five misinformation classes)
- BotHunter thresholding at 0.70: bot users = 519,337 (23.1% of users) vs human users = 1,738,645
- Bot-authored tweets: Cognitive Dissonance triggers = +6% favorites and +9% retweets vs no-trigger condition
- Bot-authored tweets: Availability Bias triggers = -28% favorites and -34% retweets vs no-trigger condition
- No explicit human baseline metrics were reported in the provided text for the bias-trigger engagement comparisons
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2406.07293.

Fig 1: Overview of Dataset Formation Methodology. This figure illustrates the pipeline
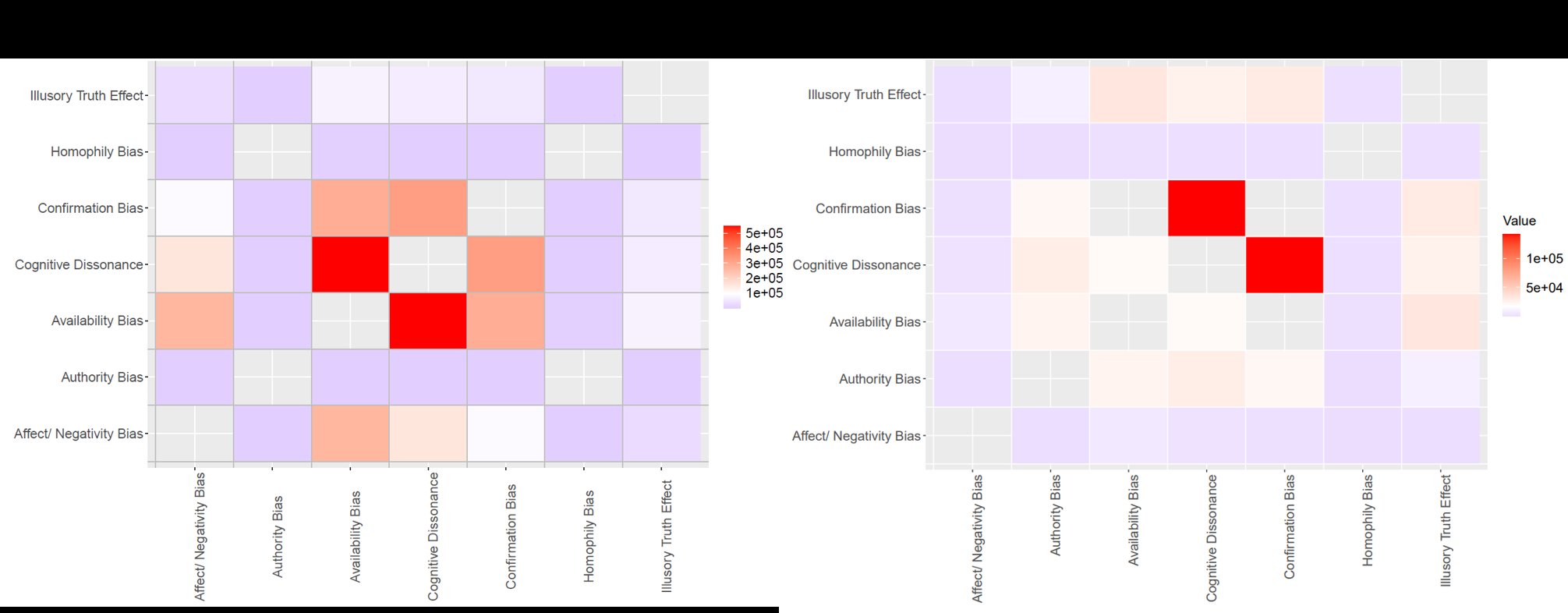
Fig 3: Co-Occurrence of Bias Triggers in Misinfo Tweets. The heatmap is colored
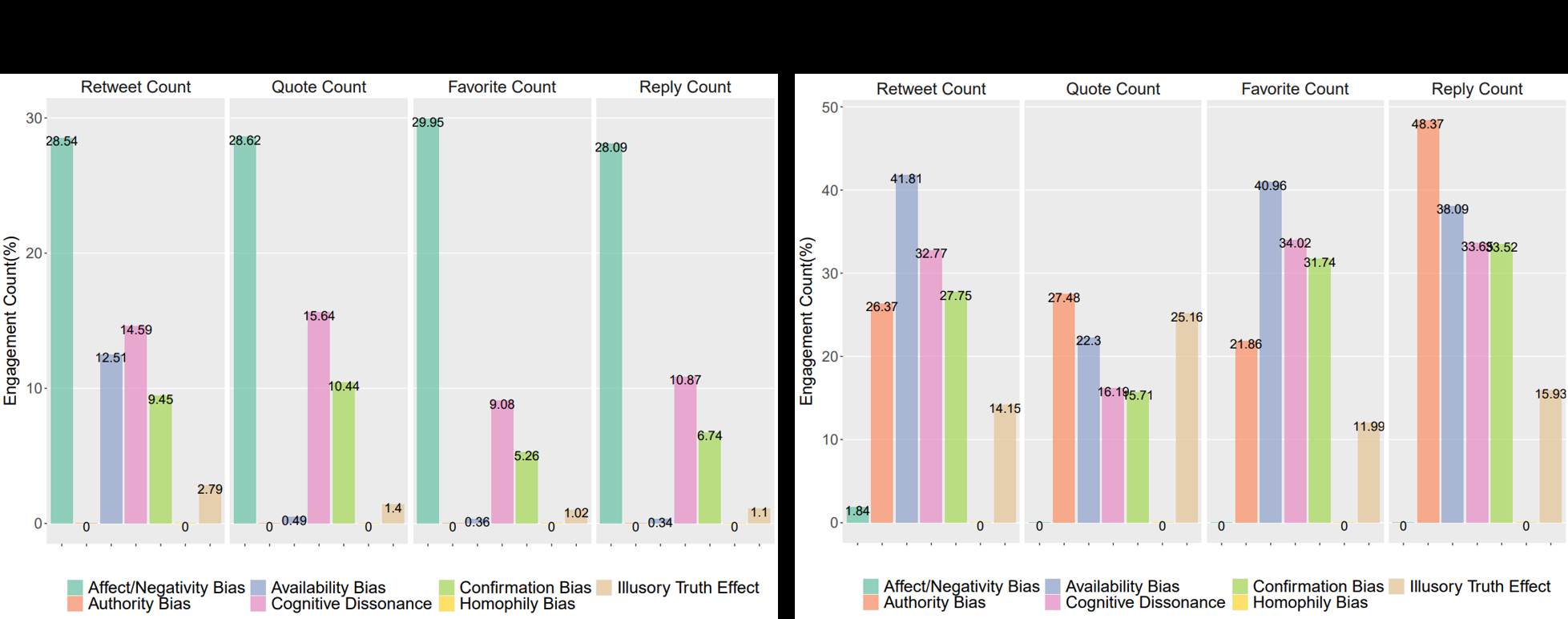
Fig 4: Engagement by Bias Triggers. This presents the proportion of engagement from
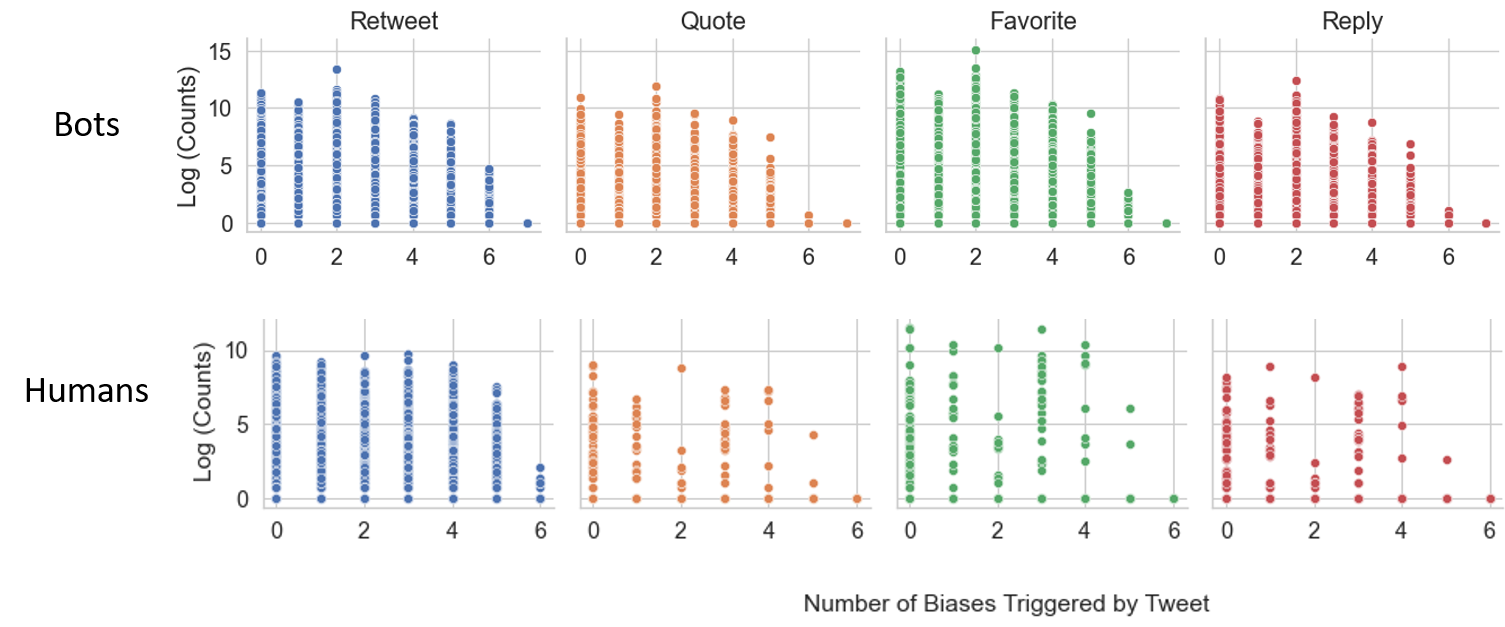
Fig 5: Relation between the Number of Biases Triggered and Engagement This
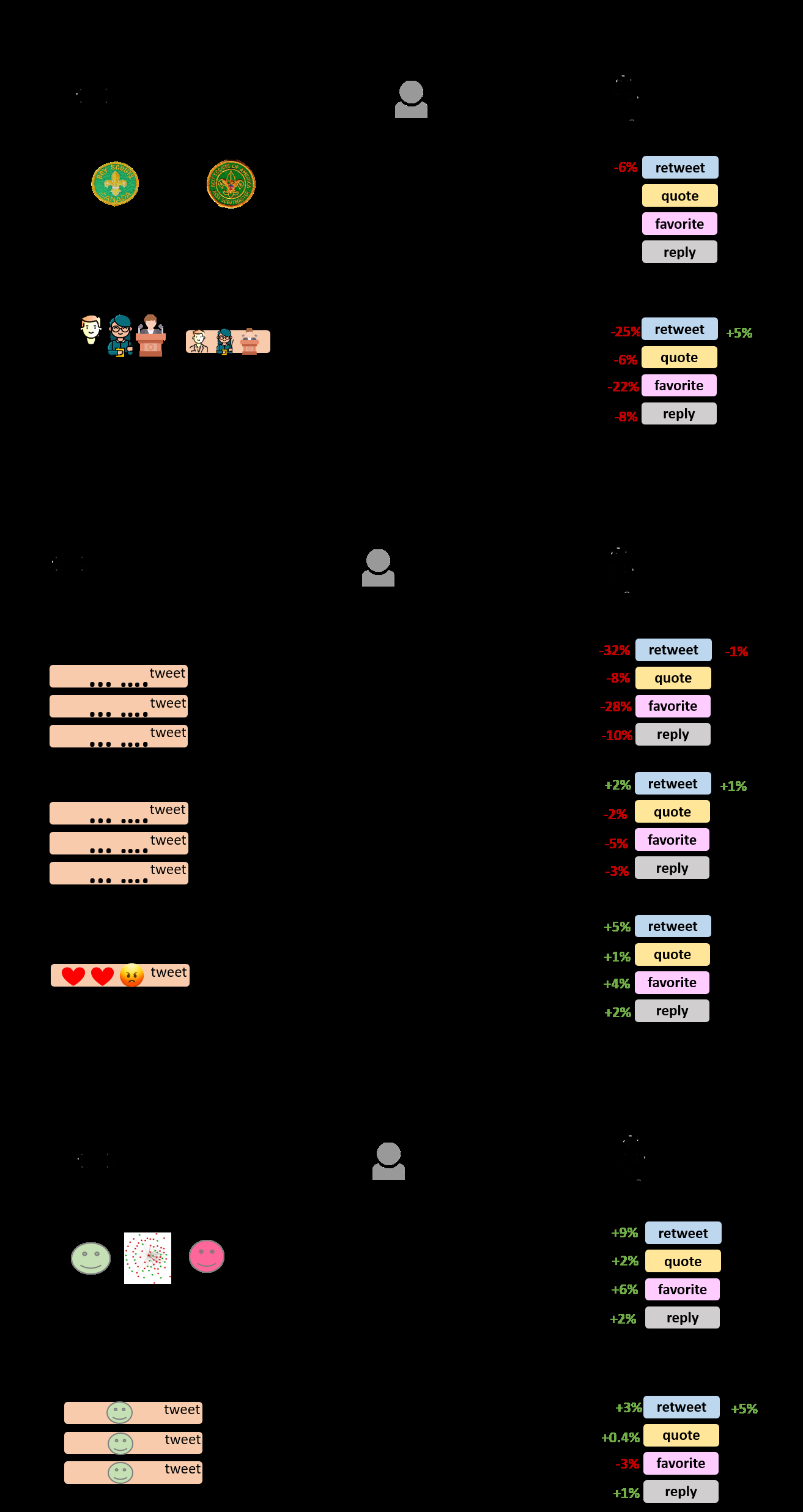
Fig 6: Illustrated Summary of the Association between Bias Triggers and Misin-
Limitations
- The misinformation extraction step is approximate: semantic nearest-neighbor matching at cosine distance >= 0.8 can admit false positives, and the authors explicitly acknowledge this.
- The 50.13% validation accuracy for the misinformation classifier is only modestly above chance and does not strongly establish high-quality labels.
- The provided text does not specify whether the bias-trigger effects are adjusted for confounders such as follower count, account age, topic, or baseline engagement.
- The paper appears to rely on BotHunter with a fixed 0.70 threshold; bot labels may be noisy, especially for borderline or coordinated human-assisted accounts.
- The engagement analysis is reported in percentage terms, but the statistical model, significance testing, and confidence intervals are not visible in the provided text.
- The study is limited to English COVID-19 vaccine misinformation on Twitter during one time window, so generalization to other topics, languages, platforms, or later platform conditions is unclear.
Open questions / follow-ons
- Can the bias-trigger extraction pipeline be validated against human annotation, and how stable are its labels across annotators or across different misinformation domains?
- Are the observed engagement effects causal, or do they disappear after controlling for account popularity, network position, topic, and baseline sentiment?
- Do the same bias triggers behave similarly on other platforms or later periods, especially after major changes in moderation and recommender systems?
- Can bias-trigger signals improve bot or misinformation detection when used as features in a downstream classifier?
Why it matters for bot defense
For a bot-defense engineer, the paper is useful less as a detector and more as a feature-engineering map of persuasion tactics. It suggests that some bot activity is not just about volume or coordination; it may leave textual/network signatures tied to cognitive biases, especially repeated retweeting/quoting, stance shifting, and emotionally loaded or confirmation-aligned phrasing. Those signals could inform risk scoring for content moderation, investigation queues, or bot campaign analysis, but they are not sufficient on their own because humans can exhibit the same cues.
For CAPTCHA and abuse mitigation practitioners, the main takeaway is that content-based persuasion patterns can complement account-level signals when deciding whether an interaction stream is suspicious. However, the paper also warns implicitly that engagement is not monotonic: some bias triggers correlate with lower engagement for bots, so simple heuristics like “more emotionally charged means more dangerous” will miss nuance. A practical response would be to combine these bias-trigger features with stronger account, network, and temporal signals before making enforcement or friction decisions.
Cite
@article{arxiv2406_07293,
title={ Exploring Cognitive Bias Triggers in COVID-19 Misinformation Tweets: A Bot vs. Human Perspective },
author={ Lynnette Hui Xian Ng and Wenqi Zhou and Kathleen M. Carley },
journal={arXiv preprint arXiv:2406.07293},
year={ 2024 },
url={https://arxiv.org/abs/2406.07293}
}