
Positional-Unigram Byte Models for Generalized TLS Fingerprinting
Source: arXiv:2405.07848 · Published 2024-05-13 · By Hector A. Valdez, Sean McPherson
TL;DR
This paper addresses the problem of reliably fingerprinting TLS client applications based on their client hello messages in the presence of adversarial modifications, specifically cipher stunting. Cipher stunting randomizes the order of cipher suites in the client hello message, which causes widely used fingerprinting methods like JA3 to fail catastrophically by producing unknown or misleading fingerprints. The authors propose a generalized TLS fingerprinting method based on positional-unigram byte models and maximum likelihood classification. Their method models the probability distributions of byte values at each position in the client hello message, capturing richer structural information beyond the limited JA3 fields.
By training positional-unigram byte models labeled using JA3 repositories on over 48,000 unique client hello samples across 121 classes, the authors demonstrate that their maximum likelihood approach remains robust as cipher suite lists are synthetically permuted, whereas JA3 performance degrades rapidly to near zero. They also study the effect of using all client hello bytes versus just JA3-extracted bytes, showing that all-byte models perform better under heavy randomization. The approach is computationally efficient, requires no side-channel or header information, and can be updated online. Overall, the paper presents a principled statistical method for TLS fingerprinting that significantly improves robustness to attacker manipulation via cipher stunting, a key evasion technique in network defense.
Key findings
- Positional-unigram byte models using maximum likelihood maintain unbiased F1 scores above 0.91 when one ordered cipher suite swap is applied, compared to JA3 performance dropping from 1.0 to as low as 0.018 (with GREASE) and 0.0 (without GREASE).
- Using all bytes in the client hello message for the model yields marginally better performance (approx. 0.92 F1) than using only JA3 bytes (approx. 0.93 F1) as shown in ordered cipher suite permutation experiments.
- Maximum likelihood classification with positional-unigram byte models remains robust across increasing fractions of random cipher suite permutations, maintaining high F1 scores, while JA3 suffers catastrophic failure.
- Positional-unigram byte models built with all bytes have lower variance and better robustness to cipher stunting than models built only with JA3 bytes under random cipher suite permutation (Fig 6).
- Dataset included 48,906 unique client hello samples across 121 classes with high class imbalance; top 4 classes covered 75% of data, bottom 12 classes had only 2 samples each.
- Removing irrelevant fields (random bytes, session ID, server name) preserves useful statistical signal while avoiding noise.
- Inference time complexity is linear in the shorter length of client hello or model length (O(M)) with constant space complexity.
- Their method can be updated on-the-fly as new client hello samples arrive, supporting adaptability in deployment.
Threat model
An adversary capable of modifying the TLS client hello message to evade detection by manipulating cipher suite order and composition (cipher stunting), but unable to spoof or modify the client hello byte distributions in a way that completely mimics another legitimate client without altering relevant positional byte statistics. The attacker cannot change immutable message structural fields or overload irrelevant byte regions to mislead the statistical model. The defender does not rely on easily spoofed packet metadata such as IP addresses or ports.
Methodology — deep read
Threat Model and Assumptions: The adversary is assumed to be a client application or process that manipulates the TLS client hello message to evade fingerprint detection, specifically by deploying cipher stunting—randomizing the order of the cipher suite list. The adversary cannot modify irrelevant fields consumed by the method (random bytes, session ID) and cannot spoof or modify positional byte distributions reliably enough to mimic other classes. The method does not rely on header metadata (like IP or ports) which attackers can spoof.
Data: The dataset was collected from an internal network comprising ~25 GB of packet captures with 11 GB of TLS traffic, split into 8 pcap files. After removing Unknown labels (from JA3) and duplicate client hello messages (based on byte sequences after stripping irrelevant fields), they obtained 48,906 unique client hello samples across 121 quasi-label classes (labels generated automatically using the JA3 fingerprint and external repositories). Label distribution was highly imbalanced.
Architecture/Algorithm: The core algorithm builds positional-unigram byte models per class label. For each byte position i up to the maximum client hello length ml of a label, the frequency of each byte value (0-255) is counted and normalized into a probability distribution pi(x=b). This forms a positional unigram model P(l) of shape ml x 256, representing independent categorical distributions for each position.
Inference computes the mean log-likelihood over the minimum length between input client hello and model length by summing the log probabilities of observed bytes under each model distribution. The predicted label is the one maximizing mean log-likelihood.
Byte sequences are preprocessed to remove irrelevant or randomized fields including random values, session IDs, key shares, and server name extensions that would add noise.
Training Regime: Frequency counts were constructed from training folds during 8-fold cross validation (each pcap representing a fold). Additive smoothing with δ=1×10^-8 was applied to frequencies. Labels were assigned automatically by JA3 hash mapping from multiple online repositories.
Evaluation Protocol: The main evaluation metric is unbiased F1 score accounting equally for all classes despite imbalance. Experiments synthetically permuted cipher suites lists in client hello messages to simulate cipher stunting: (a) ordered cipher suite swap (single swap between adjacent suites), (b) random fraction permutation of cipher suites with grid search from 0.1 to 1.0 fraction.
Each experiment ran multiple trials per fold with 95% confidence intervals reported. Comparisons were made between positional-unigram models built from (i) all bytes in client hello and (ii) JA3 extracted bytes only against the JA3 baseline.
- Reproducibility: Dataset is internal and not public. Code or numerical seeds are not explicitly mentioned, but the method’s components (JA3 labeling, positional unigram frequency counting, likelihood inference) are straightforward to reproduce given access to similar TLS client hello captures and JA3 hash mappings.
Concrete example end-to-end: A single client hello message x is labeled first by computing its JA3 hash and retrieving or assigning a label l. After preprocessing (removing irrelevant bytes), x is compared against all labeled positional-unigram byte models P(l') via mean log-likelihood. The label l' with the maximum mean log-likelihood is predicted as the generating client application. For robustness testing, permutations are applied to the cipher suite list in x prior to inference, demonstrating the model’s stability vs JA3.
Technical innovations
- Introducing positional-unigram byte models that capture byte value distributions conditioned on each position in the TLS client hello message.
- Using maximum likelihood estimation with positional-unigram models for TLS client hello fingerprint classification instead of fixed hash strings like JA3.
- Leveraging entire client hello messages (excluding irrelevant fields) rather than subsets of fields to reduce collisions and improve robustness to manipulation.
- Demonstrating robustness to cipher stunting attack vectors common in evasion by evaluating ordered and random permutations of the cipher suite list.
Datasets
- Internal TLS dataset — 48,906 unique client hello samples across 121 classes — private corporate network traffic captured in 8 pcap files totaling ~25 GB
Baselines vs proposed
- JA3: unbiased F1 = 1.0 on unpermuted client hellos vs maximum likelihood positional-unigram: 0.9285 (all bytes), 0.9314 (JA3 bytes) on unpermuted
- JA3: unbiased F1 drops to 0.018 ± 0.0007 (with GREASE) and 0.0 (without GREASE) on ordered cipher suite swap vs maximum likelihood: 0.9206 ± 0.0016 (all bytes) and 0.9330 ± 0.0013 (JA3 bytes) with GREASE, 0.9205 ± 0.0016 (all bytes) and 0.9332 ± 0.0013 (JA3 bytes) without GREASE
- On random cipher suite permutations increasing fraction from 0.1 to 1.0, maximum likelihood with all bytes maintains high unbiased F1 scores with lower variance, while JA3 baseline degrades catastrophically (plots in Fig 6).
- Maximum likelihood with JA3 bytes degrades faster than all bytes under high randomization but still outperforms JA3 baseline.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2405.07848.
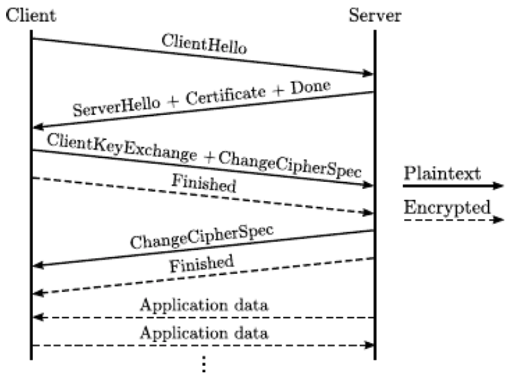
Fig 1: TLS handshake between Client and Server. From [Martin Hus´ak and

Fig 2: client hello message viewed in Wireshark. Fixed fields are enclosed
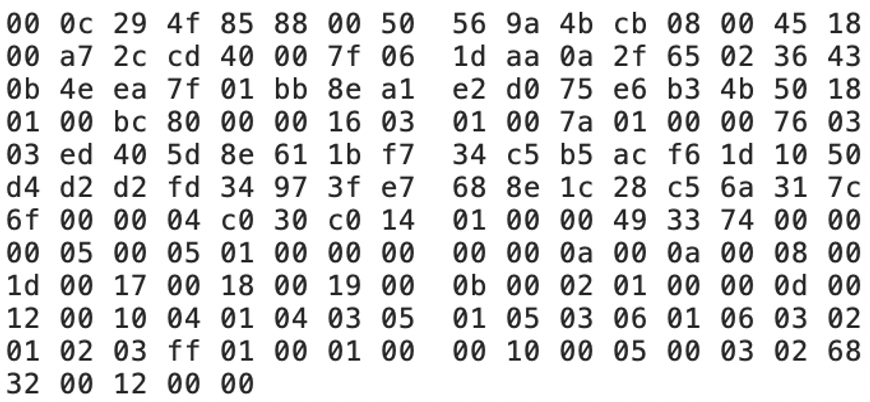
Fig 3: client hello message in hexadecimal form.
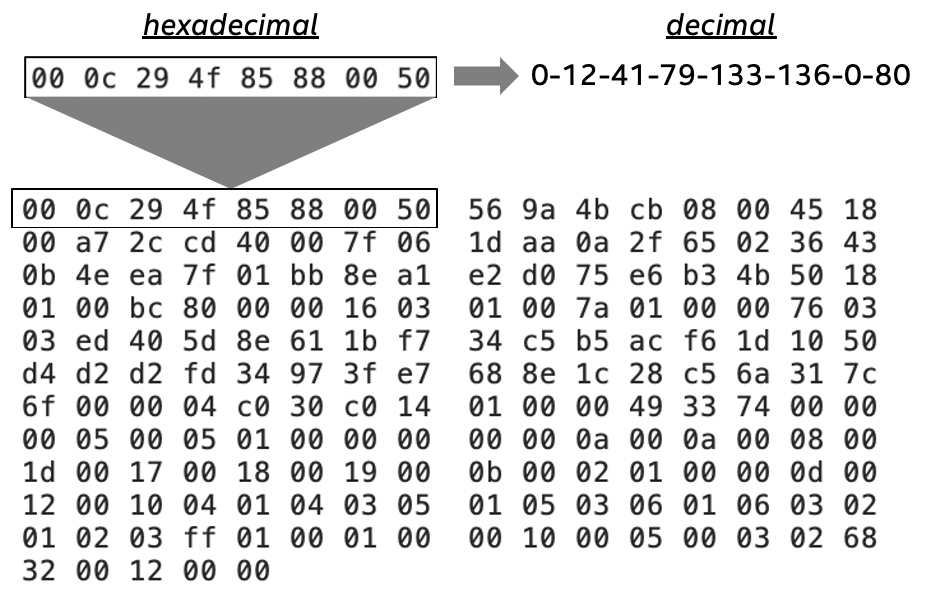
Fig 4: Top line of client hello packet converted from hexadecimal to decimal.
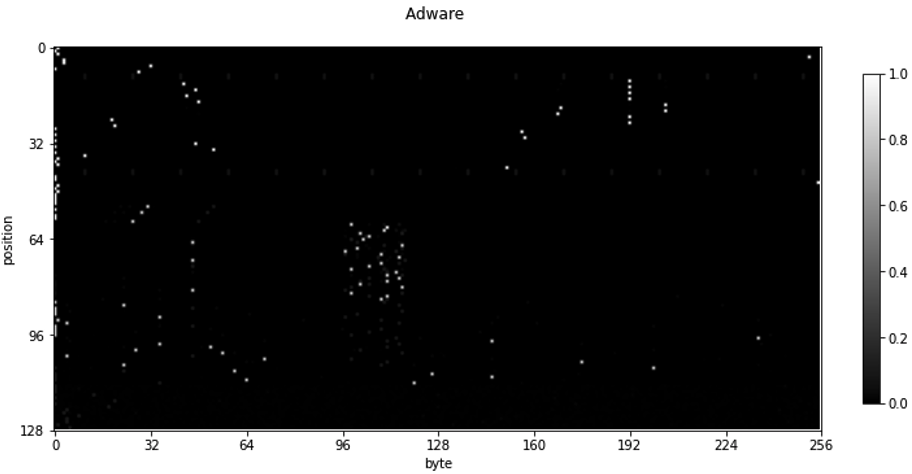
Fig 5: Visualization of a JAdware positional-unigram byte model built from
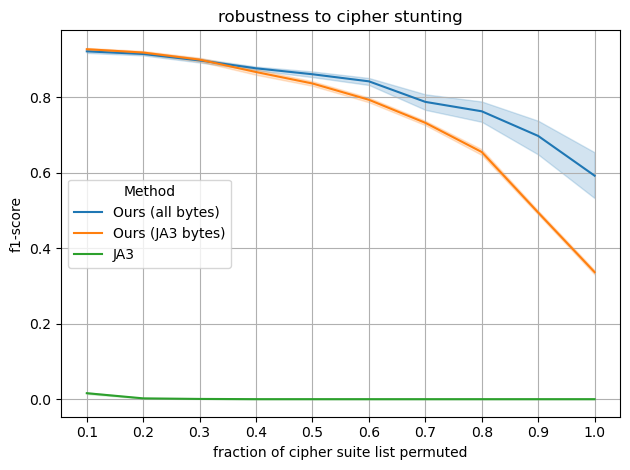
Fig 6: The maximum likelihood of positional-unigram byte models, given a
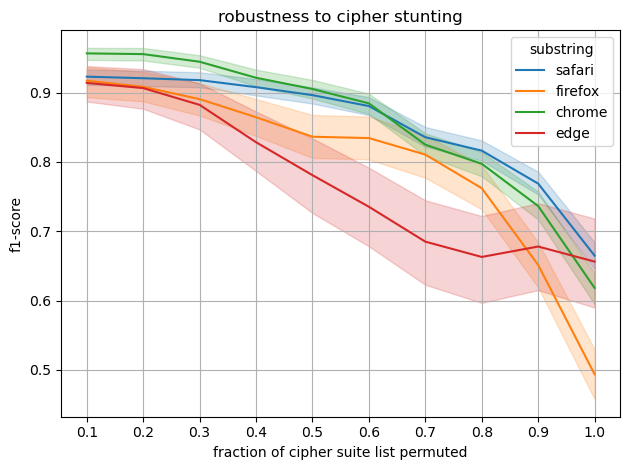
Fig 7: We perform a substring search across all class labels and average
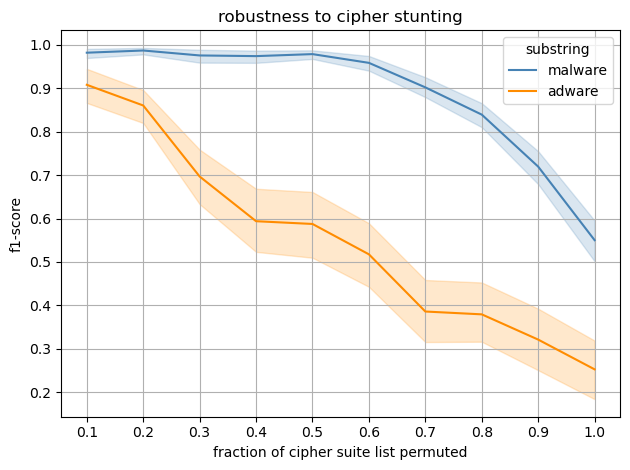
Fig 8: We perform a substring search across all class labels and average the
Limitations
- Labels are generated via JA3 hashes and external repositories, constituting quasi-labels rather than verified ground truth, introducing label noise.
- Dataset is internal and limited to a single network environment, limiting generalizability to different network contexts or novel malware.
- Does not incorporate server hello or other handshake messages which might add discriminatory power.
- Evaluations use synthetic cipher stunting permutations rather than real adversarial traffic with sophisticated obfuscations.
- Unigram models ignore conditional dependencies between bytes, possibly losing information that could be captured by bigram/trigram models.
- No adversarial evaluation against adaptive attacker strategies beyond cipher suite permutation.
Open questions / follow-ons
- How would incorporating higher-order n-grams (bigrams or trigrams) impact robustness and classification accuracy under cipher manipulations?
- Can integrating server hello or other handshake messages further disambiguate client applications and improve robustness?
- What is the performance of positional-unigram models on real-world adversarial TLS client hellos actively designed to evade fingerprinting?
- How effective is on-the-fly incremental updating of positional-unigram models in dynamic network environments with evolving client software?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper is highly relevant because TLS fingerprinting is a critical technique to identify and characterize client applications and distinguish automated malicious clients from legitimate ones. However, attackers increasingly use cipher stunting to evade traditional fingerprints like JA3, creating a blind spot in network-level detection. This work demonstrates a robust statistical method resistant to such evasion by modeling the full positional byte distribution instead of relying on brittle fixed fingerprints. Bot-defense engineers can apply positional-unigram byte models to improve fingerprinting resilience against obfuscation without metadata reliance, yielding more reliable application identification upstream of CAPTCHA challenges.
Implementing such an approach enhances early detection pipelines, reducing unknown or ambiguous TLS client hellos that complicate bot classification. Additionally, the method’s ability to update incrementally lends itself to operational deployments in evolving threat landscapes. Overall, this paper provides a practical and principled foundation to improve TLS fingerprinting under adversarial conditions, a critical gap in current anti-bot and network defense systems.
Cite
@article{arxiv2405_07848,
title={ Positional-Unigram Byte Models for Generalized TLS Fingerprinting },
author={ Hector A. Valdez and Sean McPherson },
journal={arXiv preprint arXiv:2405.07848},
year={ 2024 },
url={https://arxiv.org/abs/2405.07848}
}