
Assessing Web Fingerprinting Risk
Source: arXiv:2403.15607 · Published 2024-03-22 · By Enrico Bacis, Igor Bilogrevic, Robert Busa-Fekete, Asanka Herath, Antonio Sartori, Umar Syed
TL;DR
This paper addresses the key problem of measuring the fingerprinting risk posed by modern Web APIs. Previous studies estimated browser fingerprinting entropy either on limited datasets or single websites and did not adequately account for correlations between API attributes, leading to potentially exaggerated risk estimations. The authors overcome these limitations by conducting a large-scale measurement involving tens of millions of real Chrome users across over 100,000 websites. They also propose a novel experimental design that respects user privacy by limiting the information collected per user and efficiently estimating entropy using the Chow-Liu tree decomposition to incorporate inter-attribute correlations.
Their analysis reveals substantial variability in Web API usage and fingerprinting risk across different website categories, demonstrates that many Web API attributes are highly correlated, and confirms entropy as a valid proxy metric for fingerprinting threat. The study further evaluates anti-fingerprinting interventions, quantifying the trade-offs between blocking fingerprinting scripts and preserving website functionality. Overall, this work significantly advances the realism, scale, and privacy-preserving rigor of in-the-wild browser fingerprinting risk assessment.
Key findings
- Collected Web API usage data from over 10 million Chrome clients visiting 100,000+ websites, 10x larger than prior studies (Andriamilanto et al., 2021a).
- Analyzed 5383 surfaces derived from 161 Web APIs, selecting 60 popular 'core' surfaces with stable and non-trivial entropy (>0.1 bits).
- Used Chow-Liu upper bound incorporating pairwise mutual information to estimate joint entropy with ≤ 1.5 bits error at 90% confidence.
- Identified 10 distinct Web API surface families and observed website category-dependent surface call patterns (e.g., shopping sites frequently access GPU info).
- Strong, often high mutual information between many attribute pairs reduced joint entropy compared to sum of individual entropies.
- Session entropy distributions over top 10k websites show clear bi-modal pattern: websites either have low or high fingerprinting risk (entropy far below or above 20 bits).
- First-party versus third-party entropy profile varies by vertical, with news sites showing highest third-party entropy linked to ad scripts.
- Strong positive correlation between presence of known fingerprinting signatures and high session entropy (Fig 8), validating entropy as fingerprinting proxy.
- Simulated anti-fingerprinting strategies: blocking scripts on Disconnect’s invasive fingerprinting list reduced entropy moderately, while blocking all scripts with fingerprinting signatures drastically cut entropy (Figs 9,10).
Threat model
The adversary is a passive website operator embedding scripts that invoke Web APIs to collect device fingerprints from a browser visiting their site during a session. They may aggregate attributes observed during multiple visits within a 4-week period but cannot access user-identifiable information beyond these API values or circumvent browser privacy features. They do not control the client device or have direct user information outside web observations.
Methodology — deep read
The authors developed a large-scale, privacy-conscious measurement study to quantify the entropy of Web API calls as fingerprinting risk. Their threat model assumes a passive website adversary who collects API attribute values to fingerprint users but cannot bypass Chrome's existing privacy controls or access extensive centralized user info.
Data was collected from tens of millions of real Chrome clients over multiple phases. Each client visited public websites and reported values for subsets of 5383 candidate Web API "surfaces" (API + input). To limit privacy risks, reporting was randomized and capped: clients reported at most 40 surface values in Phase 2, and phases were disjoint client sets. Values were hashed on-device and any surface values reported by fewer than 50 clients were discarded. Aggregated data was retained only 4 weeks.
Entropy estimation used the Chow-Liu tree decomposition, bounding joint entropy of a subset of surfaces by sum of individual entropies minus mutual informations along a maximum-weight spanning tree. This captured pairwise dependencies between attributes to avoid naïve sums that overestimate uniqueness. Entropy and mutual information terms required O(v) and O(v^2) independent samples respectively, where v is number of distinct attribute values.
Phase 1 measured which surfaces were called but not values, to identify surface families and frequencies. Phase 2 assigned clients random surface families for reporting, aiming for unbiased samples with PC = min(1, 40/n) reporting probability calibrated per client. Phase 3 focused on dense sampling of 60 popular core surfaces to estimate mutual information across pairs.
The methodology balanced maximizing data for precise entropy estimates against strict privacy guarantees. Statistical confidence on entropy estimates was ±1.5 bits (90%). The authors clustered surfaces by pairwise correlation (total variation) and mutual information, and assigned websites to verticals via an automated method.
Evaluation included entropy distributions per website category, correlation with fingerprinting signatures, and simulation of script-blocking mitigation strategies. Baselines included naïve entropy sums ignoring correlations. The authors did not disclose code or raw data due to privacy, but described parameter choices and detailed their multi-phase data collection rigorously.
An example derives the session entropy for a given user’s observed surfaces on a site by computing the Chow-Liu upper bound: summing estimated entropies of observed surfaces and subtracting mutual information terms corresponding to edges in the maximum spanning tree over these surfaces, accounting for correlations (e.g., WebGL parameters highly correlated). This yields a tighter and more realistic measure of fingerprinting risk per browsing session than prior naïve sums or small-sample studies.
Technical innovations
- Applying Chow-Liu tree decomposition to estimate upper bounds on joint Web API entropy, capturing pairwise dependencies to improve fingerprinting risk accuracy.
- Novel multi-phase experimental design collecting partial surface values across tens of millions of Chrome clients while limiting per-client information to under 20–40 bits to preserve privacy.
- Clustering Web API surfaces into families based on total variation distance and mutual information to structure entropy estimation and surface sampling.
- Using observed Web API calls during real user browsing sessions (passive telemetry) rather than crawler-driven or synthetic tests to provide realistic fingerprints.
- Quantitative evaluation of anti-fingerprinting mitigation impact by simulating script blocking on large crawled website corpus.
Datasets
- Chrome telemetry — >10 million real user clients — private Google Chrome telemetry data collected with user consent
- Tranco Top 10,000 websites — 10,000 - public website list used for session entropy analysis
- Crawler dataset — 6.4 million websites — crawled scripts and function call arguments for simulated mitigation evaluation
Baselines vs proposed
- Naïve entropy sum without accounting for correlations: often overestimated joint entropy by several bits vs Chow-Liu upper bound accounting for mutual information (+/- 1.5 bits accuracy)
- Disconnect invasive fingerprinting list script blocking: reduced average session entropy moderately (Fig 9), exact deltas not numerically reported
- Blocking all scripts with known fingerprinting signatures (Acar et al., 2014): caused large reductions in session entropy compared to no blocking (Fig 10)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2403.15607.
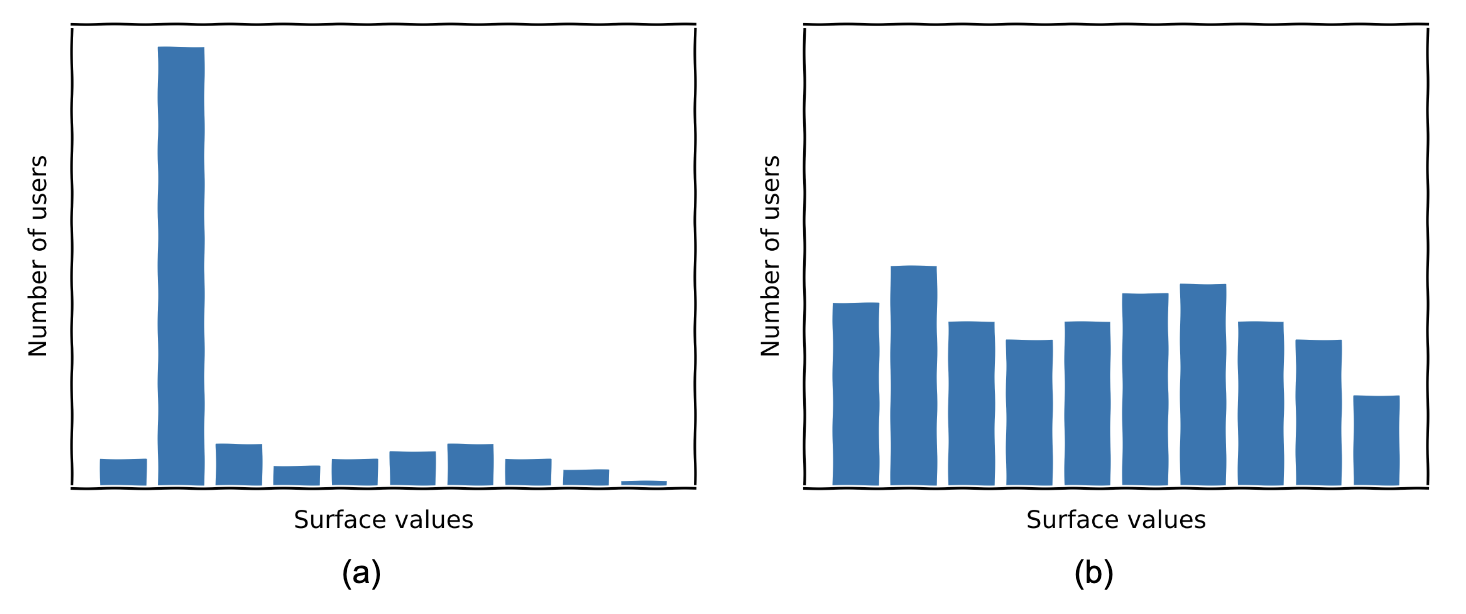
Fig 1: Two possible value distributions for a Web API, (a) low entropy and
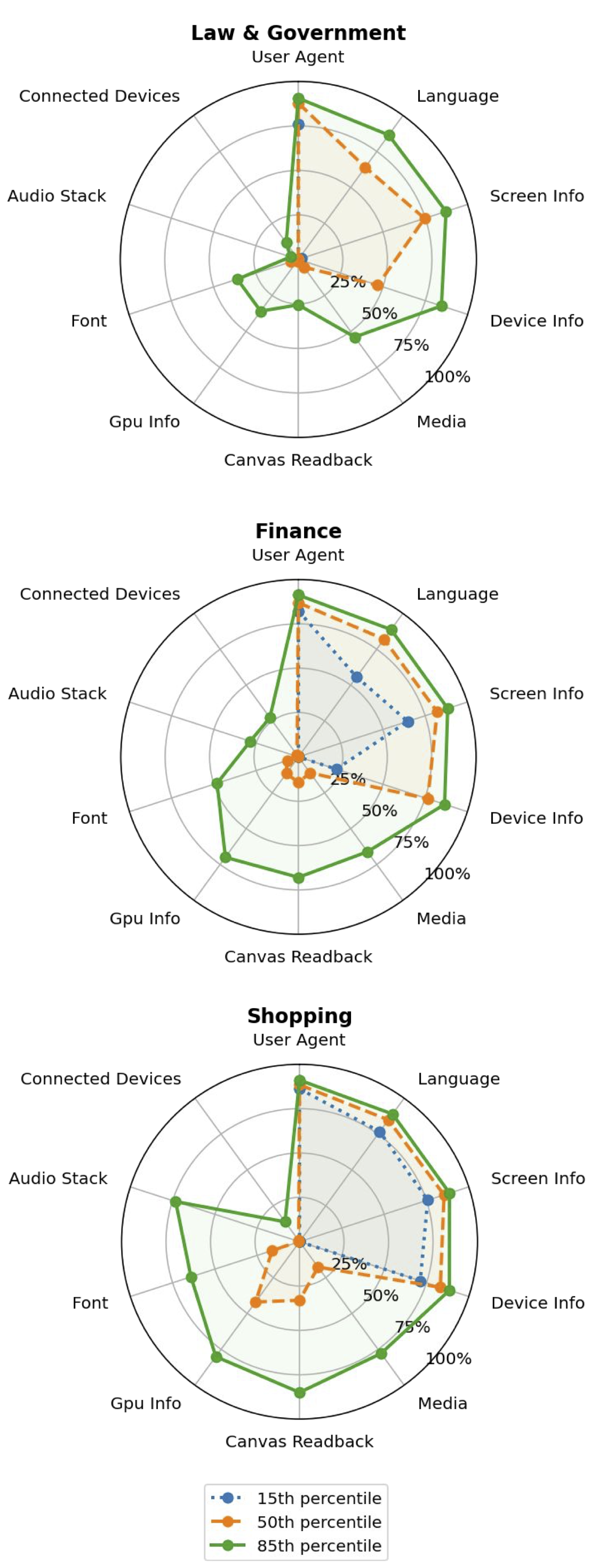
Fig 2: Surface call frequency for several website verticals

Fig 3: Surface clustering determined by pairwise correlations. Clusters are
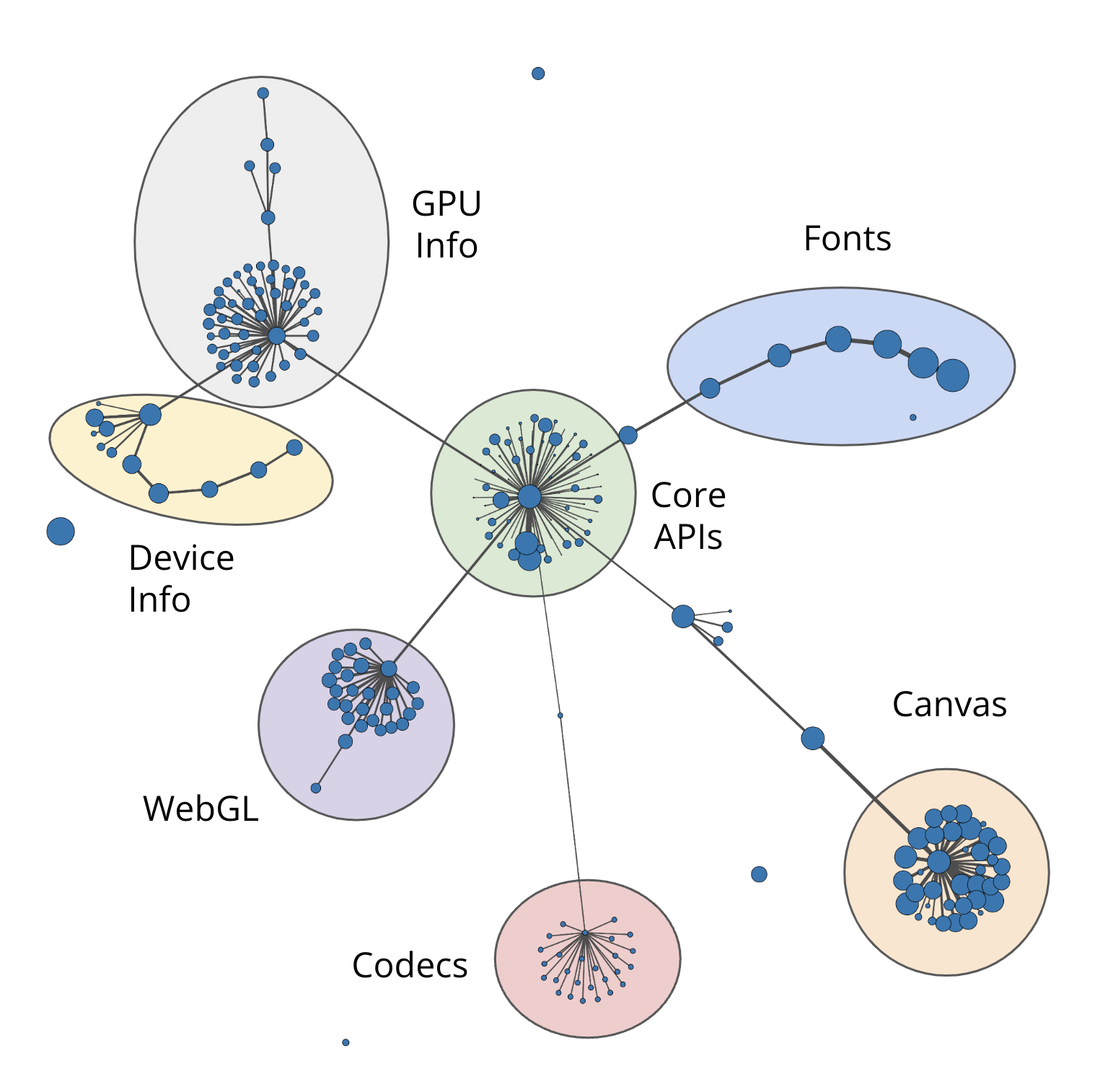
Fig 4: Surface clustering determined by mutual information. Clusters are
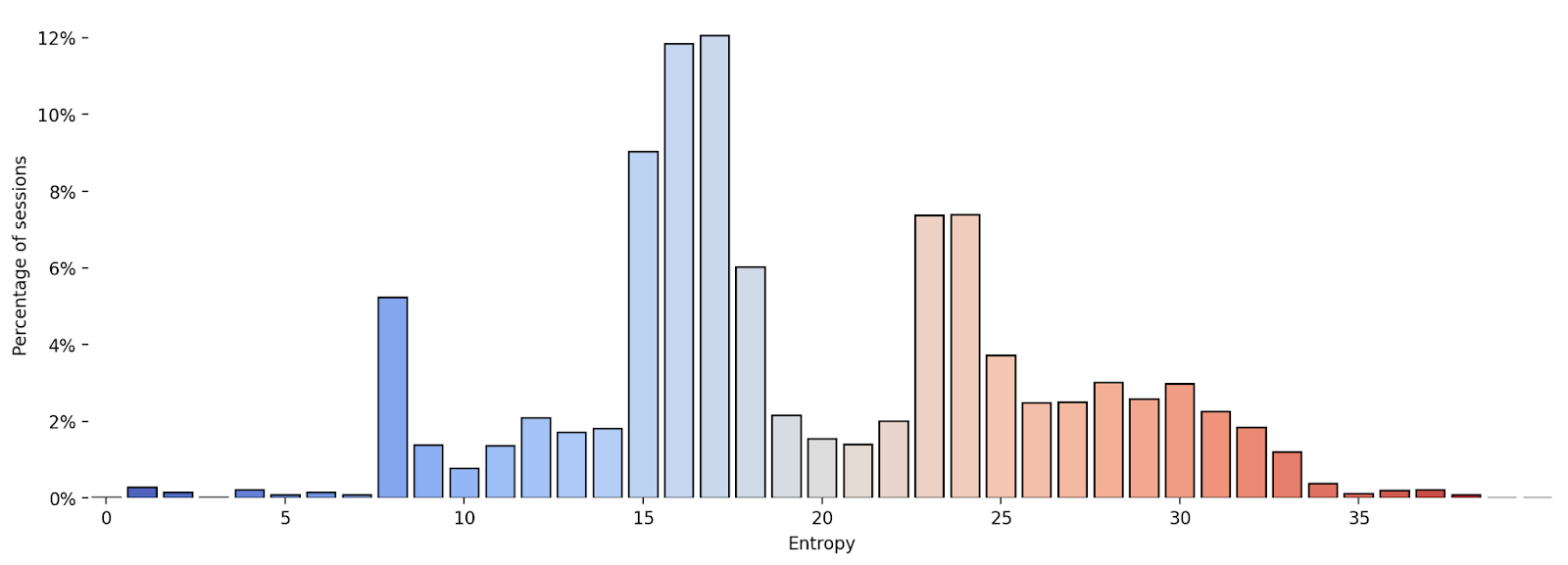
Fig 5: Entropy distribution of the web
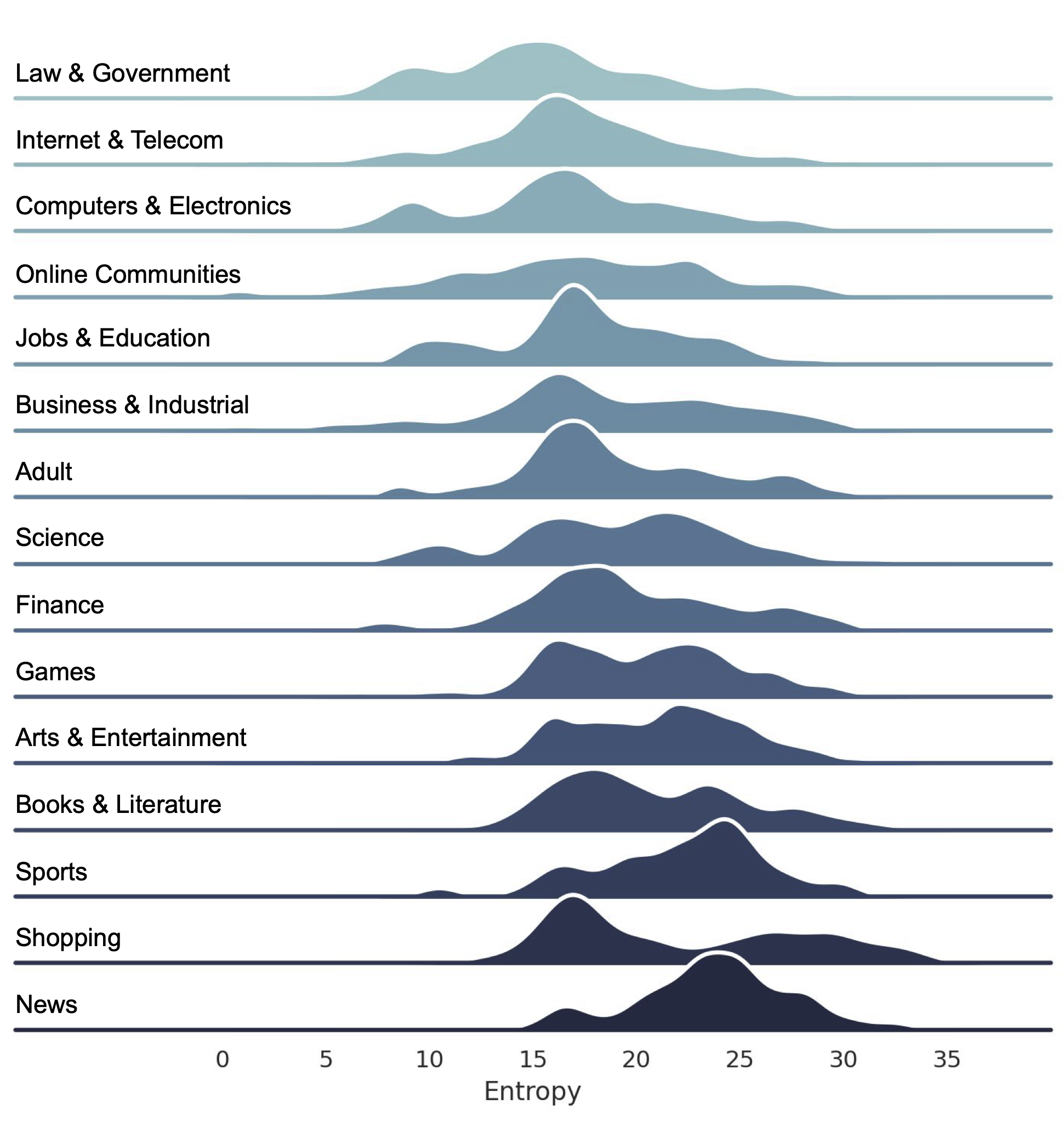
Fig 6: Per-vertical distributions of session entropy, sorted in increasing order
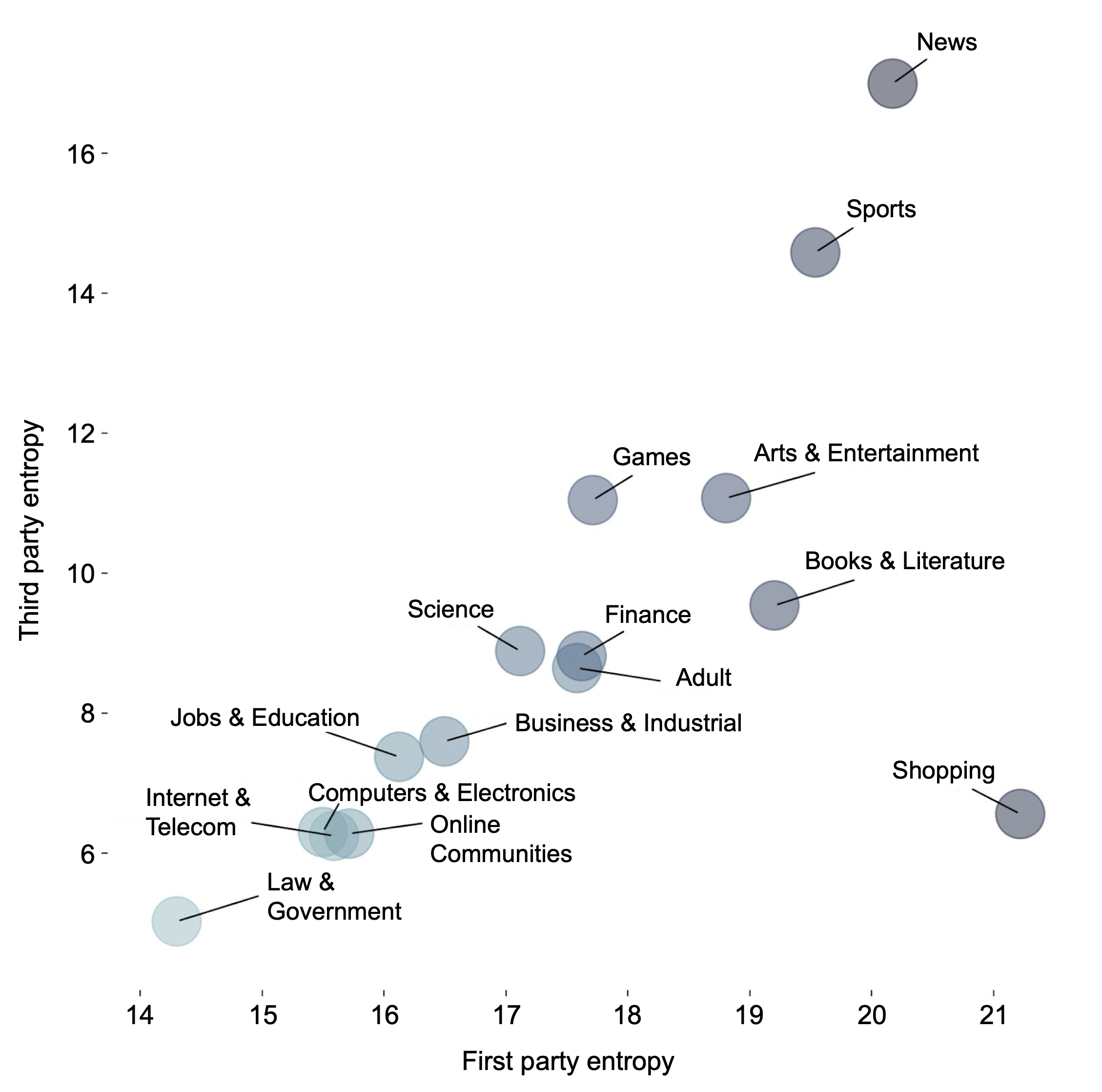
Fig 7: Average third-party versus first-party entropy
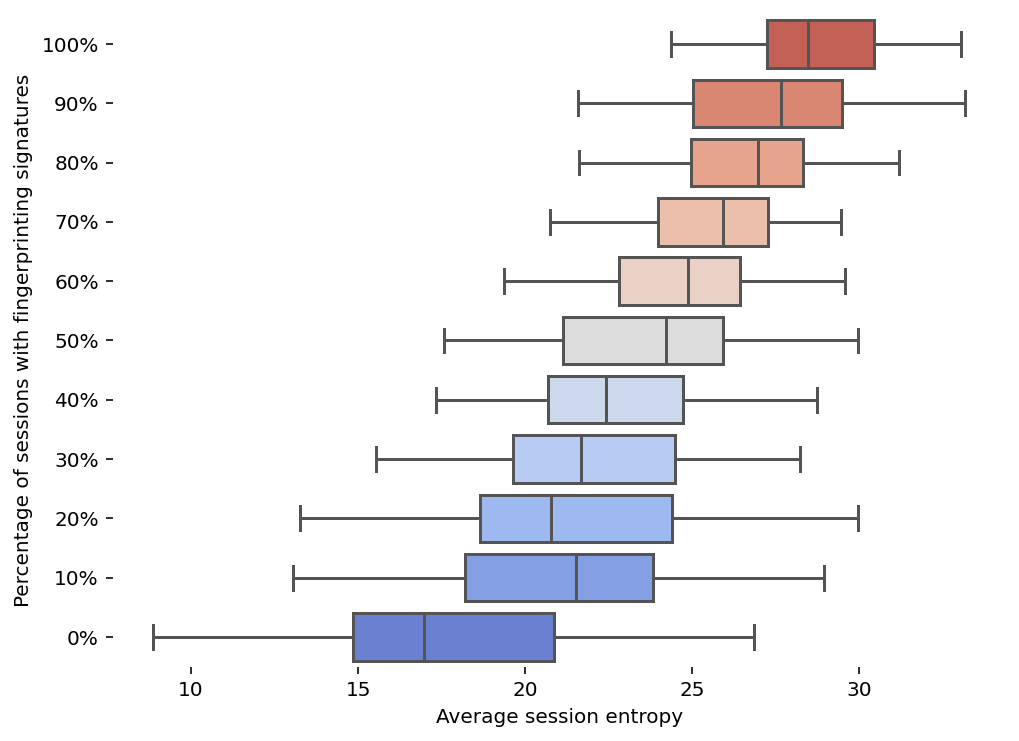
Fig 8: Fingerprinting signatures versus entropy
Limitations
- Privacy constraints limited collection to partial views of surface sets per client, potentially missing rare higher-order correlations beyond pairs.
- Study excludes some fingerprinting vectors not exposed via JavaScript/CSS or hidden behind permissions, including Chrome extensions.
- Only pairwise correlations were modeled (Chow-Liu tree), higher-order attribute correlations were not estimated potentially leading to loose upper bounds.
- No adversarial attacker simulations were run; robustness against deliberate fingerprint obfuscation or evasion was not evaluated.
- Simulated mitigation impact used crawler data rather than real client telemetry for per-script entropy estimations.
- Entropy values correspond to static snapshots; dynamics over time and cross-session linkability beyond 4-week aggregation were not analyzed.
Open questions / follow-ons
- How to estimate and incorporate higher-order (beyond pairwise) correlations among Web APIs to tighten fingerprinting risk bounds?
- Can adaptive sampling or differential privacy improve entropy estimation accuracy while maintaining strict user privacy?
- What is the longitudinal stability of these fingerprinting entropy values over longer timespans and how does fingerprint uniqueness evolve?
- How effective are these entropy-based metrics under active adversarial attempts to evade or poison fingerprinting signals?
Why it matters for bot defense
For practitioners working on bot defense and CAPTCHA design, this paper provides a rigorous, large-scale quantification of browser fingerprinting risk that goes beyond simple attribute entropy counts by realistically accounting for attribute correlations and real user behavior. Understanding these entropy distributions and surface correlations can inform decisions about which API attributes to monitor or block to detect or hinder automated bots while balancing legitimate user experience. The experimental methodology and entropy metrics here enable more fine-grained evaluation of anti-fingerprinting features in browsers or client-side defenses used by CAPTCHAs.
This work also highlights significant variability in fingerprinting richness across site types and the interaction between first- and third-party script behaviors. Those designing CAPTCHA or bot defenses that leverage fingerprinting signals should consider these heterogeneities and correlations to avoid over- or underestimating bot uniqueness. Furthermore, the results on script-blocking mitigation strategies provide practical insights into how fingerprinting-based bot detection might be affected or mitigated by browser privacy features or user script blockers, which are relevant for deploying robust bot defenses.
Cite
@article{arxiv2403_15607,
title={ Assessing Web Fingerprinting Risk },
author={ Enrico Bacis and Igor Bilogrevic and Robert Busa-Fekete and Asanka Herath and Antonio Sartori and Umar Syed },
journal={arXiv preprint arXiv:2403.15607},
year={ 2024 },
url={https://arxiv.org/abs/2403.15607}
}