
Your device may know you better than you know yourself -- continuous authentication on novel dataset using machine learning
Source: arXiv:2403.03832 · Published 2024-03-06 · By Pedro Gomes do Nascimento, Pidge Witiak, Tucker MacCallum, Zachary Winterfeldt, Rushit Dave
TL;DR
This paper studies continuous authentication from touchscreen behavior rather than passwords or one-time unlocks. The authors collected a new public dataset from 15 volunteers, each playing Minecraft on a Samsung Galaxy Tab A8 for 15 minutes, and extracted touch-dynamics features from Android ADB logs. They then trained three standard binary classifiers — KNN, SVC, and Random Forest — in a per-user evaluation setup where each user’s own data was split 70/30 into train/test.
The main result is that SVC was the strongest non-pathological model, with about 90% accuracy, 0.94 precision, 0.94 recall, 0.95 F1, and roughly 0.969 AUC. KNN was weaker at 78% accuracy, while Random Forest produced near-perfect scores (99% accuracy, 0.998 AUC) that the authors themselves treat as suspiciously overfit and therefore discard. The paper’s real contribution is less about a new algorithm than about a new dataset and a straightforward empirical baseline showing that touch dynamics from a game-like task can separate users reasonably well, though the study is small and not yet deployment-ready.
Key findings
- Dataset: 15 users × 15 minutes each on a Samsung A8 tablet, with raw touch metrics captured via ADB from Minecraft gameplay.
- Feature set included X/Y speed, speed magnitude, X/Y acceleration, acceleration magnitude, jerk, path tangent, and angular velocity after standardization with StandardScaler.
- Per-user 70/30 train-test split: the model is trained on 70% of each user’s samples and evaluated on the remaining 30% of that same user’s data.
- SVC was the best credible model, reaching 0.90 accuracy, 0.94 precision, 0.94 recall, 0.95 F1, and ~0.9693 AUC.
- KNN reached 0.78 accuracy, 0.88 precision, 0.88 recall, 0.88 F1, and 0.934 AUC.
- Random Forest achieved 0.99 accuracy and 0.998 AUC, but the authors explicitly judge these results likely overfit and say they will disregard them.
- For the sampled users shown in Table 3, SVC ranged from 80% to 96% accuracy (users 5, 7, 8, 15, and 1), while KNN ranged from 70% to 86%.
- The authors compare their SVC result against prior touchscreen-authentication work and note that it is in the same broad range as prior SVM-based studies, but not clearly state-of-the-art across all metrics.
Threat model
The adversary is implicitly an unauthorized person using the same touchscreen device and generating touch behavior during normal interaction, while the system assumes the genuine user’s touch dynamics are learnable from a short enrollment segment. The paper does not model a white-box attacker, a mimicry attacker, a replay attacker, or an attacker with access to training data; it also does not specify whether impostor data come from other users’ sessions or from a separate attack session. The system’s job is to distinguish authenticated-user touch segments from non-authenticated ones using behavioral patterns rather than secrets.
Methodology — deep read
The threat model is implicit rather than formally specified: an impostor has access to the same device and generates touch inputs during normal Minecraft play, and the system tries to decide whether a given touch-action segment belongs to the genuine enrolled user. The paper does not model a sophisticated adaptive attacker who tries to imitate touch timing, nor does it describe replay attacks, session transfer, or cross-device transfer. The authentication problem is framed as continuous behavioral authentication, but the actual experimental setup is closer to user-specific binary classification on touch segments.
Data collection was performed on a Samsung A8 tablet using a Python script that called Android Debug Bridge (ADB) to read touch-screen metrics. The dataset contains 15 volunteers, each recorded for 15 minutes while playing Minecraft. The raw variables listed in Table 1 are timestamp, X, Y, BTN_TOUCH state (down/held/up), TOUCH_MAJOR, TOUCH_MINOR, TRACKING_ID, PRESSURE, and a FINGER flag for a second finger. The authors say they removed rows where X or Y had the sentinel value -420, sorted by finger ID and timestamp, converted string values to numeric form, dropped NaNs, and standardized numerical columns using sklearn’s StandardScaler. The paper is public-data oriented and gives a GitHub link for the dataset and collection script, but it does not provide the exact file counts, sample counts after cleaning, or a train/test split by subject or session beyond the 70/30 within-user split.
Feature engineering is the core transformation step. From the cleaned touch stream, the authors derive instantaneous motion features: X_Speed, Y_Speed, total Speed, X_Acceleration, Y_Acceleration, total Acceleration, Jerk, Path_Tangent, and Ang_V (angular velocity). The paper does not spell out the exact finite-difference formulae, window size, or how segments are formed from raw event sequences, so one must infer that features were computed from successive touch points within a user’s recorded interactions. A concrete example end-to-end is: a touch sequence from a Minecraft session is captured via ADB, rows with invalid coordinates are removed, numeric columns are standardized, motion-derived features are computed from the ordered touch stream, and then the resulting feature vectors are labeled by user identity for binary classification against that user’s test samples.
Modeling uses three classical ML classifiers implemented in scikit-learn: K-Nearest Neighbors, Support Vector Classifier, and Random Forest. For KNN, the authors used an elbow method to choose k and settled on k=2 as best for the most users. For Random Forest, they tried normalization/scaling, feature experiments, and grid search over max_depth, max_features, min_samples_leaf, and min_samples_split; the final reported parameters were min_samples_leaf=3 and max_depth=6. For SVC, they used sklearn’s SVC with no reported hyperparameter tuning; they mention C and gamma as possible tunables but say tuning was unnecessary. Training was user-by-user rather than a single global model: they say they trained each model on all 15 users and tested each user’s data individually, with 70% of each user’s data used for training and 30% for testing. The paper does not report batch sizes, epochs, random seeds, or hardware used, which is consistent with the use of off-the-shelf sklearn models rather than neural training.
Evaluation uses confusion-matrix-derived metrics: accuracy, precision, recall, F1, and AUC. The paper defines TP as authentic user classified as self, TN as impostor correctly rejected, FP as impostor accepted, and FN as genuine user rejected. Table 3 reports per-user accuracy for users 1, 5, 7, 8, and 15, while Table 4 reports aggregate metrics: KNN at 0.78 accuracy / 0.934 AUC, SVC at 0.90 accuracy / ~0.9693 AUC, and RF at 0.99 accuracy / 0.998 AUC. The authors explicitly question the RF result as too good to be true and suggest overfitting, but they do not provide a formal overfitting diagnostic, cross-validation, held-out attacker evaluation, or significance testing. In the discussion (Table 5), they compare their methods against prior papers that report accuracy, EER, FRR, FAR, or AUC, but these comparisons are descriptive rather than apples-to-apples because the datasets and evaluation protocols differ.
Reproducibility is partial. The dataset and collection script are public on GitHub, which is a strong positive, but the paper leaves several important implementation details unspecified: exact feature formulas, sample counts after cleaning, exact user-wise class balance, the precise segmentation strategy, whether model tuning was nested or not, and the random-state handling for splits and classifiers. Because the data come from a single institution, a single device model, and one game scenario, the published dataset should be reproducible only in a narrow sense; generalization to other devices or apps remains untested.
Technical innovations
- Introduces a public touch-dynamics dataset collected from 15 users playing Minecraft on a Samsung A8 tablet, rather than using generic swipe or unlock-pattern data.
- Uses a user-centric evaluation setup that tests each enrolled user separately instead of only the more common user-versus-impostor pooled benchmark.
- Applies motion-derived touch features such as jerk, path tangent, and angular velocity to a continuous-authentication setting built from raw Android touch logs.
- Benchmarks three classical classifiers — KNN, SVC, and Random Forest — on the same dataset to establish a practical baseline for later work.
Datasets
- AuthenTech Minecraft Touch Dataset — 15 users × 15 minutes each; raw touch-event logs after cleaning not specified — public GitHub repository: https://github.com/AuthenTech2023/authentech-repo
Baselines vs proposed
- K-Nearest Neighbors: accuracy = 0.78 vs proposed SVC = 0.90
- K-Nearest Neighbors: AUC = 0.934 vs proposed SVC = ~0.9693
- Random Forest: accuracy = 0.99 vs proposed SVC = 0.90, but authors judge RF likely overfit and exclude it from their main conclusion
- Random Forest: AUC = 0.998 vs proposed SVC = ~0.9693, but authors caution the RF result is probably not trustworthy
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2403.03832.

Fig 1: Volunteer in data collection session.

Fig 2: User 9's touch features
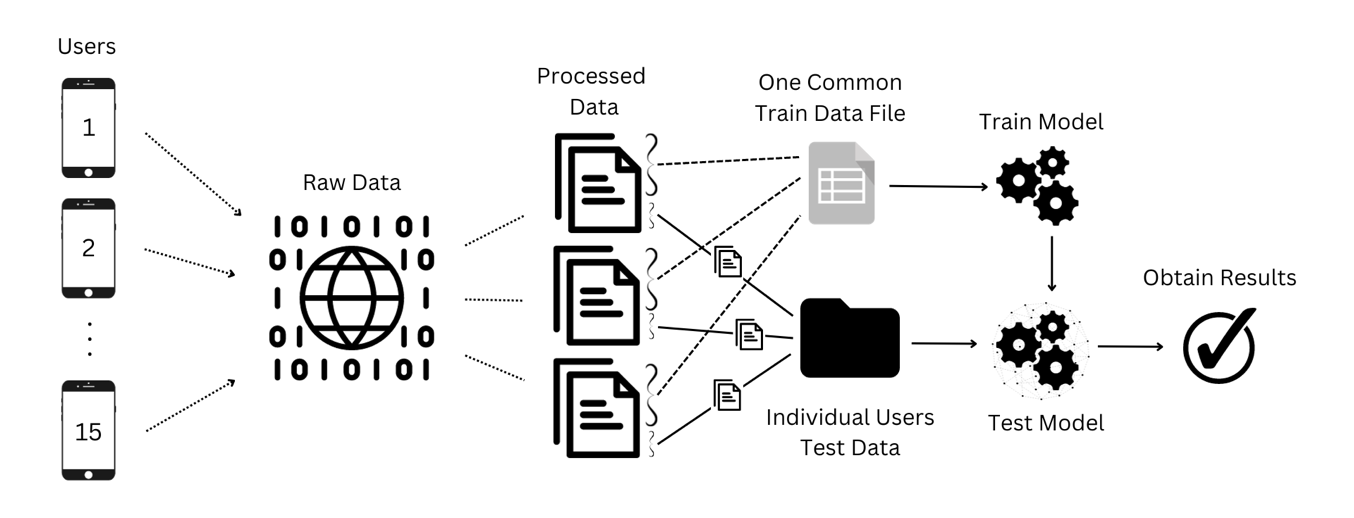
Fig 3: – End-to-end process of the experiment.
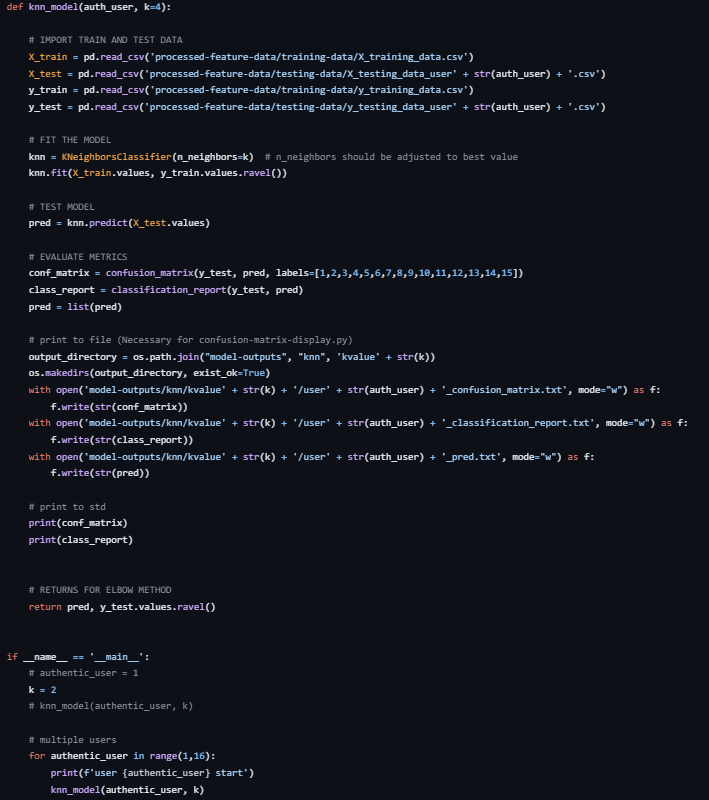
Fig 4: – kNN Python code
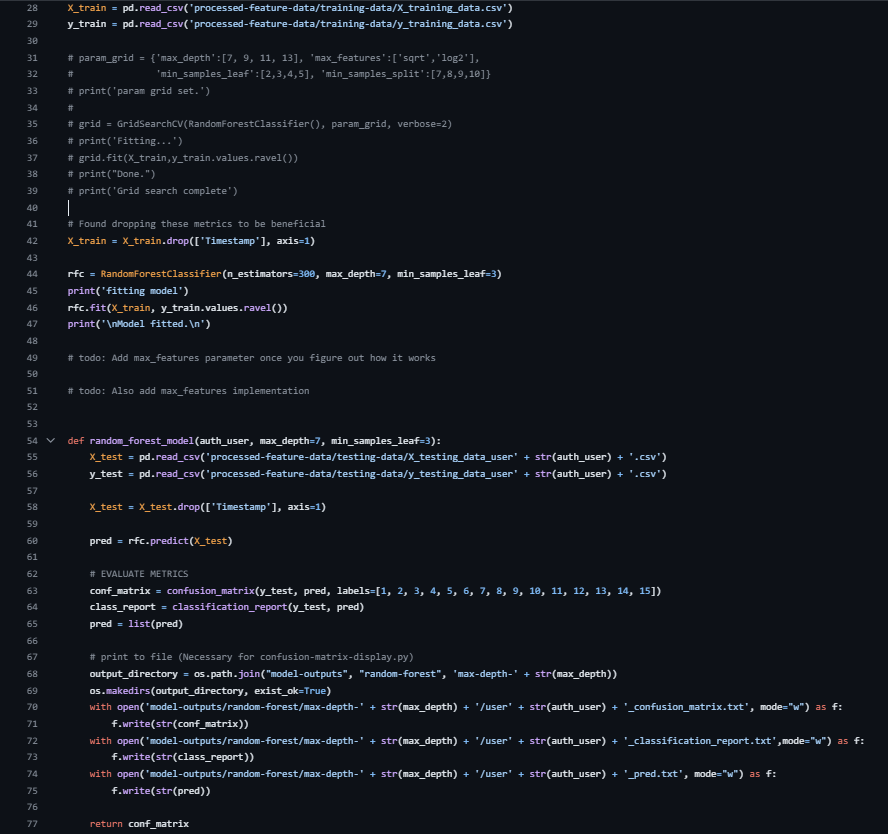
Fig 5: – Random Forest Python code
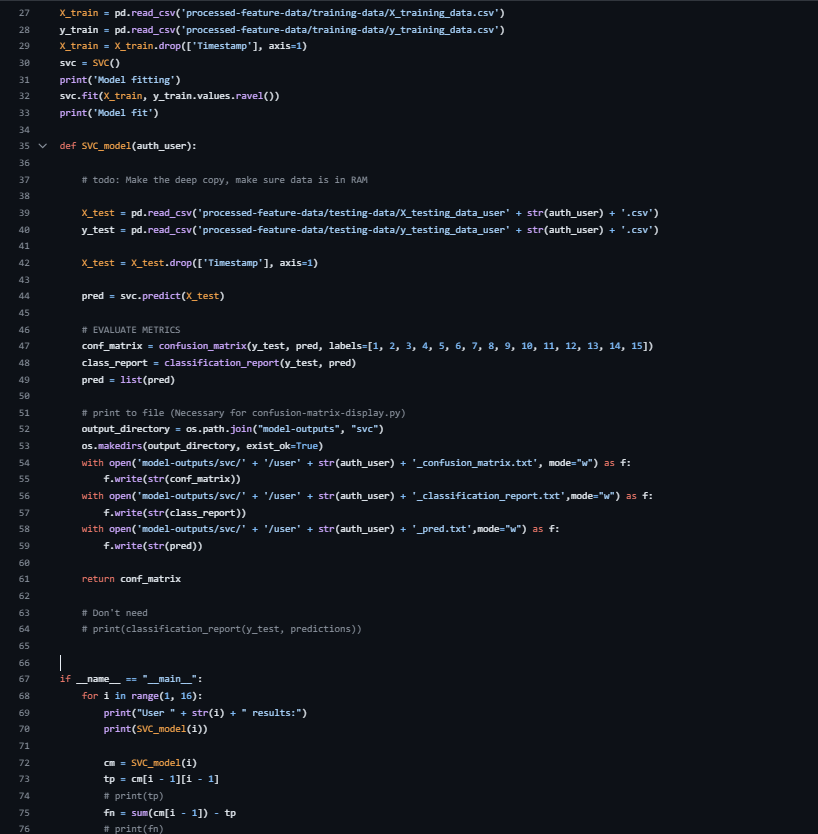
Fig 6: – SVC Python code
Fig 8: – Confusion matrices for k-NN, SVC, and RF models respectively
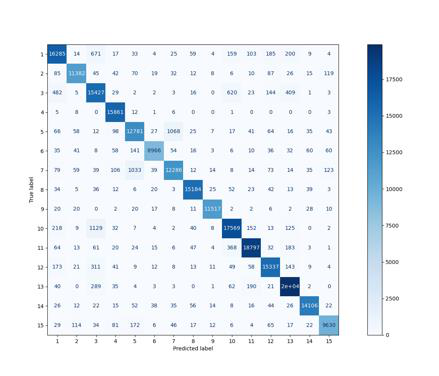
Fig 8 (page 10).
Limitations
- Very small and homogeneous sample: 15 users, all students from the same university.
- Single device and single application context: Samsung A8 tablet and Minecraft only.
- The paper does not report sample counts after cleaning, exact feature formulas, or detailed segmentation/windowing, which weakens reproducibility.
- No formal cross-validation, held-out attacker, cross-device, or cross-app evaluation.
- Random Forest results look implausibly strong, and the authors themselves suspect overfitting but do not provide a rigorous diagnostic.
- The evaluation protocol is user-centric but still based on the same user’s data being split 70/30, which may overstate performance for real-world deployment across sessions.
Open questions / follow-ons
- Would the learned touch signatures survive across different apps, different tablet models, or longer time gaps between enrollment and verification?
- How much of the reported accuracy comes from user identity versus task-specific context inside Minecraft, such as menu navigation or combat actions?
- Would a stricter evaluation with cross-session splits or unseen-session impostors materially reduce SVC performance?
- Could a sequence model over raw event streams outperform hand-engineered speed/acceleration features without overfitting on such a small dataset?
Why it matters for bot defense
For bot-defense or CAPTCHA practitioners, the paper is mainly a reminder that touch dynamics can carry usable identity signal even in ordinary gameplay-like interaction. That suggests a possible signal for risk scoring, step-up authentication, or passive verification on mobile devices, especially when the interaction stream is rich enough to extract timing, pressure, and motion features. But the study is too small and too context-bound to justify production claims; the same features may degrade quickly across devices, app contexts, accessibility settings, or user fatigue.
A practitioner should read this as a baseline, not a deployment recipe. The most useful lesson is methodological: a seemingly strong result can come from a narrow task and a lenient evaluation split, while a too-perfect model like the reported Random Forest can be a red flag for leakage or overfitting. If you build on this, you would want cross-session validation, device transfer tests, and an explicit attacker model before using touch dynamics as a CAPTCHA-adjacent signal.
Cite
@article{arxiv2403_03832,
title={ Your device may know you better than you know yourself -- continuous authentication on novel dataset using machine learning },
author={ Pedro Gomes do Nascimento and Pidge Witiak and Tucker MacCallum and Zachary Winterfeldt and Rushit Dave },
journal={arXiv preprint arXiv:2403.03832},
year={ 2024 },
url={https://arxiv.org/abs/2403.03832}
}